이어서 작성해보자.
함수
칼럼값을 읽어서 계산 결과를 반환한다.
- 단일행 함수 : N개의 값을 읽어서 N개의 결과를 리턴한다.
(매 행 함수 실행 -> 결과 반환)- 그룹 함수 : N개의 값을 읽어서 1개의 결과를 리턴한다.
(하나의 그룹별로 함수 실행 -> 결과 반환)
SELECT 절에 단일행 함수와 그룹 함수를 함께 사용하지 못한다.
(결과 행의 개수가 다르기 때문에)
함수를 기술할 수 있는 위치는 SELECT, WHERE, ORDER BY, GROUP BY, HAVING
절에 기술할 수 있다.
<단일행 함수>----------------------------------------------------------------------------------------------
문자 관련 함수
1) LENGTH / LENGTHB
- LENGTH(칼럼|'문자값') : 글자 수 반환
- LENGTHB(칼럼|'문자값') : 글자의 바이트 수 반환
한글 한 글자 -> 3BYTE
영문자, 숫자, 특수문자 한 글자 -> 1BYTE*DUAL 테이블
- SYS 사용자가 소유하는 테이블
- SYS 사용자가 소유하지만 모든 사용자가 접근이 가능하다.
- 한 행, 한 칼럼을 가지고 있는 더미(DUMMY) 테이블이다.
- 사용자가 함수(계산)를 사용할 때 임시로 사용하는 테이블이다.
Ex)

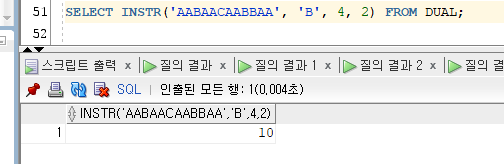
2) INSTR
- INSTR(칼럼|'문자값', '문자'[, POSITION[, OCCURRENCE]])
- 지정한 위치부터 지정된 숫자 번째로 나타나는 문자의 시작 위치를 반환한다.
Ex)
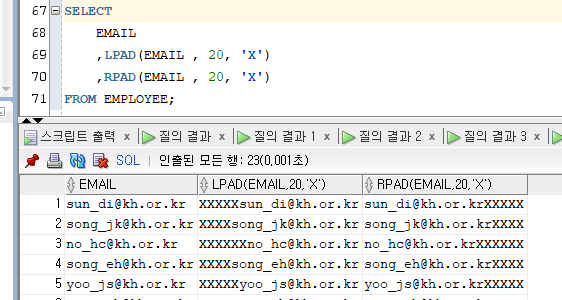
3) LPAD / RPAD
- LPAD/RPAD(칼럼|'문자값', 길이(바이트)[, '덧붙이려고 하는 문자'])
- 제시된 칼럼|'문자값'에 임의의 문자를 왼쪽 또는 오른쪽에 덧붙여 최종
N 길이 만큼의 문자열을 반환한다.- 문자에 대해 통일감 있게 표시하고자 할 때 사용한다.
Ex)
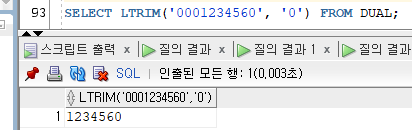
4) LTRIM / RTRIM
- LTRIM/RTRIM(칼럼|'문자값'[, '제거하고자 하는 문자'])
- 문자열의 왼쪽 혹은 오른쪽에서 제거하고자 하는 문자들을 찾아서 제거한 결과를 반환한다.
- 제거하고자 하는 문자값을 생략 시 기본값으로 공백을 제거한다.
Ex)
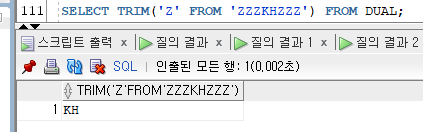
5) TRIM
- TRIM([[LEADING|TRAILING|BOTH] '제거하고자 하는 문자값' FROM] 칼럼|'문자값')
- 문자값 앞/뒤/양쪽에 있는 지정한 문자를 제거한 나머지를 반환한다.
- 제거하고자 하는 문자값을 생략 시 기본적으로 양쪽에 있는 공백을 제거한다.
Ex)
6) SUBSTR
- SUBSTR(칼럼|'문자값', POSITION[, LENGTH])
- 문자데이터에서 지정한 위치부터 지정한 개수만큼의 문자열을 추출해서 반환한다.
Ex)
7) LOWER / UPPER / INITCAP
LOWER/UPPER/INITCAP(컬럼|'문자값')
- LOWER : 모두 소문자로 변경한다.
- UPPER : 모두 대문자로 변경한다.
- INITCAP : 단어 앞 글자마다 대문자로 변경한다.
Ex)
8) CONCAT
- CONCAT(칼럼|'문자값', 칼럼|'문자값')
- 문자데이터 두 개를 전달받아서 하나로 합친 후 결과를 반환한다.
Ex)
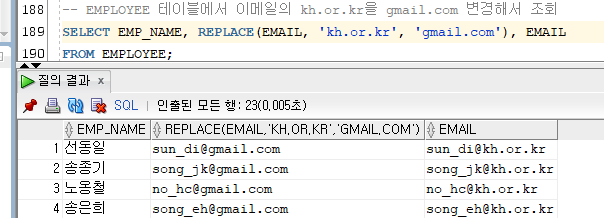
9) REPLACE
- REPLACE(칼럼|'문자값', 변경하려고 하는 문자, 변경하고자 하는 문자)
- 칼럼 또는 문자값에서 "변경하려고 하는 문자"를 "변경하고자 하는 문자"로 변경해서 반환한다.
Ex)
숫자 관련 함수
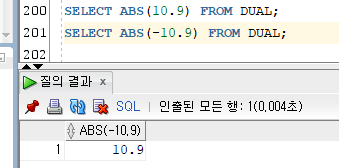
1) ABS
- ABS(NUBER)
- 절대값을 구하는 함수
Ex)
2) MOD
- MOD(NUMBER, NUMBER)
- 두 수를 나눈 나머지를 반환해 주는 함수 (자바의 % 연산과 동일하다.)
Ex)

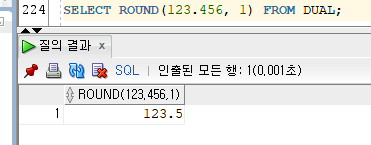
3) ROUND
- ROUND(NUMBER[, 위치])
- 위치를 지정하여 반올림해주는 함수
- 위치 : 기본값 0(.), 양수(소수점 기준으로 오른쪽)와 음수(소수점 기준으로 왼쪽)로 입력가능
Ex)
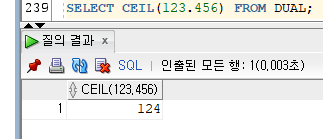
4) CEIL
- CEIL(NUMBER)
- 소수점 기준으로 올림해주는 함수
Ex)
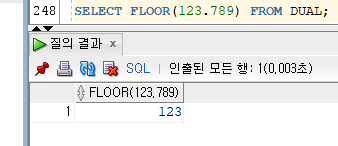
5) FLOOR
- FLOOR(NUMBER)
- 소수점 기준으로 버림하는 함수
Ex)
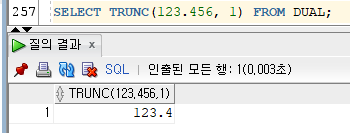
6) TRUNC
- TRUNC(NUMBER[, 위치])
- 위치를 지정하여 버림이 가능한 함수
- 위치 : 기본값 0(.), 양수(소수점 기준으로 오른쪽)와 음수(소수점 기준으로 왼쪽)로 입력가능
Ex)
날짜 관련 함수
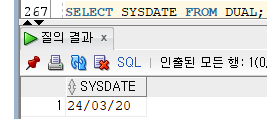
1) SYSDATE
시스템의 현재 날짜와 시간을 반환한다.Ex)
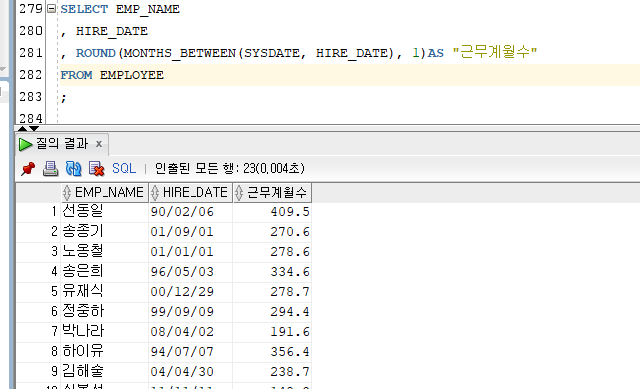
2) MONTHS_BETWEEN
[문법]
MONTHS_BETWEEN(DATE1, DATE2)
- 입력받은 두 날짜 사이의 개월 수를 반환한다.
- 결과값은 NUMBER 타입이다.
Ex)
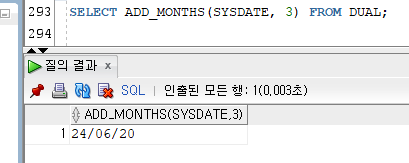
3) ADD_MONTHS
[문법]
ADD_MONTHS(DATE, NUMBER)
- 특정 날짜에 입력받는 숫자만큼의 개월 수를 더한 날짜를 리턴한다.
- 결과값은 DATE 타입이다.
Ex)
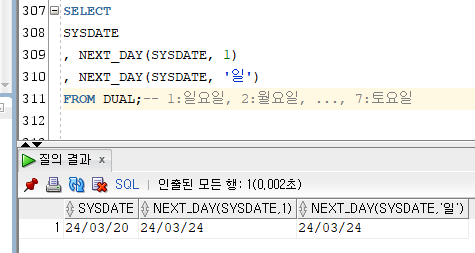
4) NEXT_DAY
[문법]
NEXT_DAY(DATE, 요일(문자|숫자))
- 특정 날짜에서 구하려는 요일의 가장 가까운 날짜를 리턴한다.
- 결과값은 DATE 타입이다.
Ex)
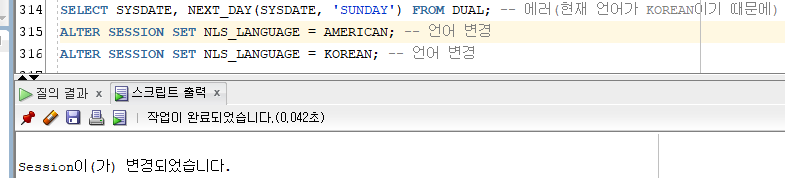
- 두 번째 인덱스에 다른 언어를 사용했을 경우 언어를 바꿔주어야 함.
Ex)
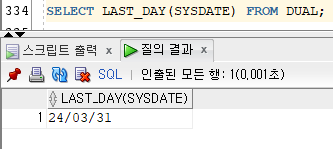
5) LAST_DAY
[문법]
LAST_DAY(DATE)
- 해당 월의 마지막 날짜를 반환한다.
- 결과값은 DATE 타입이다.
Ex)
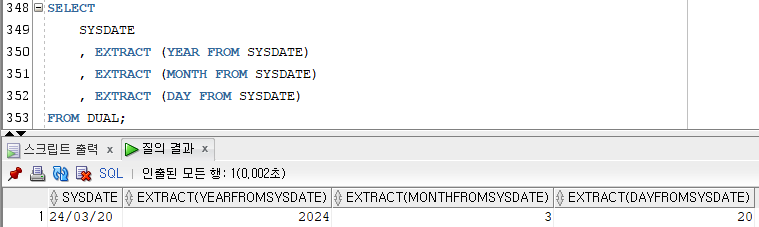
6) EXTRACT
[문법]
EXTRACT(YEAR|MONTH|DAY FROM DATE);
- 특정 날짜에서 연도, 월, 일 정보를 추출해서 반환한다.
YEAR : 연도만 추출
MONTH : 월만 추출
DAY : 일만 추출- 결과값은 NUMBER 타입이다.
Ex)
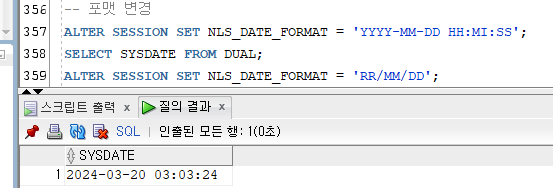
- 포맷 변경
Ex)
형변환 함수
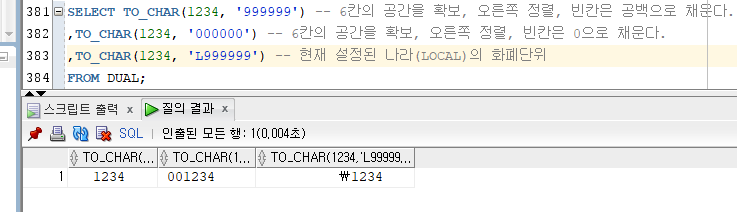
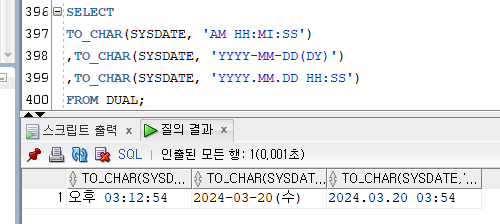
> 1) TO_CHAR
[문법]
TO_CHAR(날짜|숫자[, 포멧])
- 날짜 또는 숫자 타입의 데이터를 문자 타입으로 변환해서 반환한다.
- 결과값은 CHARACTER 타입이다.
숫자 Ex)
날짜 Ex)
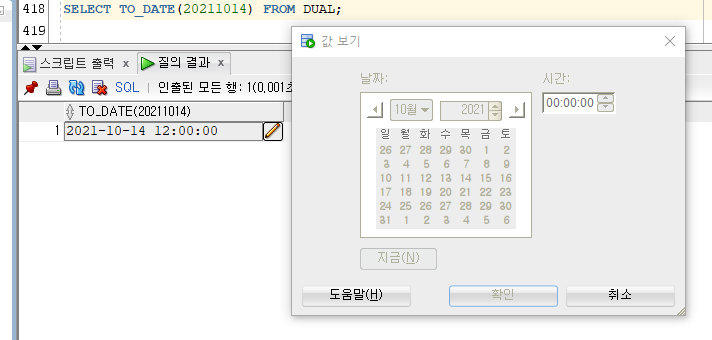
2) TO_DATE
[문법]
TO_DATE(숫자|문자[, 포멧])
- 숫자 또는 문자형 데이터를 날짜 타입으로 변환해서 반환한다.
- 결과값은 DATE 타입이다.
숫자 Ex)
문자 Ex)

3) TO_NUMBER
[문법]
TO_NUMBER('문자값'[, 포멧])
- 문자 타입의 데이터를 숫자 타입의 데이터로 변환해서 반환한다.
- 결과값은 NUMBER 타입이다.
- format의 값은 '문자값' 구문을 분석하는 데 사용됨
Ex)

NULL 처리 함수
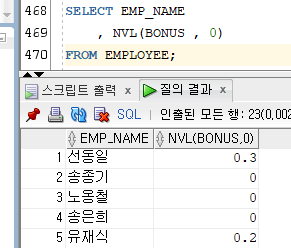
1) NVL
[문법]
NVL(컬럼, 컬럼값이 NULL일 경우 반환할 값)
- NULL로 되어있는 컬럼의 값을 인자로 지정한 값으로 변경하여 반환한다.
Ex)
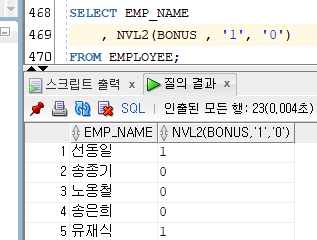
> 2) NVL2
[문법]
NVL2(컬럼, 변경할 값 1, 변경할 값 2)
- 컬럼 값이 NULL이 아니면 변경할 값 1, 컬럼 값이 NULL이면 변경할 값 2로 변경하여 반환한다.
Ex)
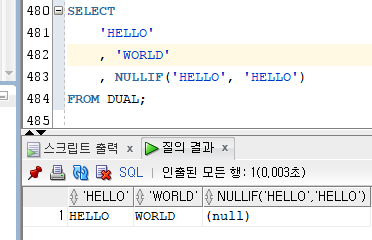
> 3) NULLIF
[문법]
NULLIF(비교대상 1, 비교대상 2)
- 두 개의 값이 동일하면 NULL 반환, 두 개의 값이 동일하지 않으면 비교대상 1을 반환한다.
Ex)
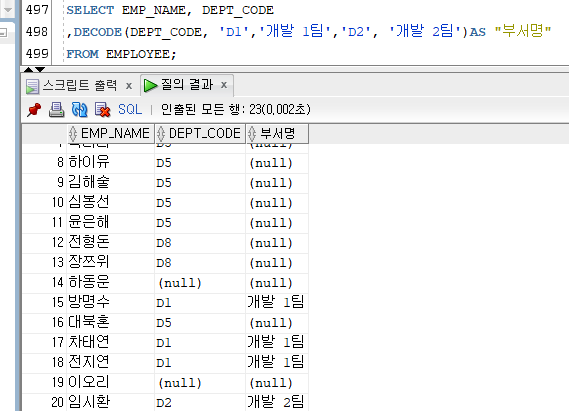
선택함수
여러 가지 경우에 선택을 할 수 있는 기능을 제공하는 함수이다.
1) DECODE
[문법]
DECODE(칼럼|계산식, 조건값 1, 결과값 1, 조건값 2, 결과값 2, ..., 결과값)
- 비교하고자 하는 값이 조건값과 일치할 경우 그에 해당하는 결과값을 반환해 주는 함수이다.
Ex)
2) CASE
[문법]
CASE WHEN 조건식 1 THEN 결과값 1
WHEN 조건식 2 THEN 결과값 2
...
ELSE 결과값 N
ENDEx)
그룹 함수
- 대량의 데이터들로 집계나 통계 같은 작업을 처리해야 하는 경우 사용되는 함수들이다.
- 모든 그룹 함수는 NULL 값을 자동으로 제외하고 값이 있는 것들만 계산을 한다.
- 따라서 AVG 함수를 사용할 때는 반드시 NVL() 함수와 함께 사용하는 것을 권장한다.
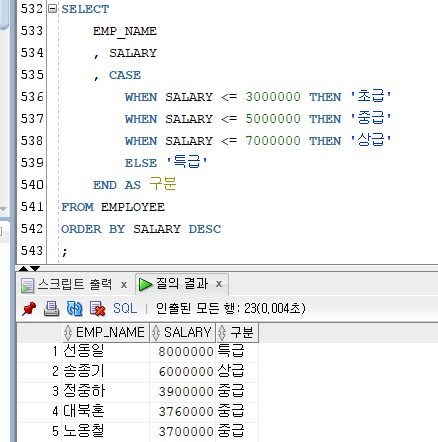
1) SUM
[문법]
SUM(NUMBER)
- 해당 칼럼 값들의 총 합계를 반환한다.
Ex)
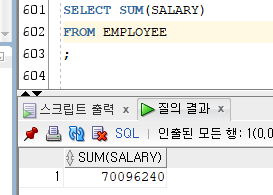
2) AVG
[문법]
AVG(NUMBER)
- 해당 컬럼 값들의 평균을 구해서 반환한다.
Ex)
3) MIN / MAX
[문법]
MIN/MAX(모든 타입 컬럼)
- MIN : 해당 컬럼 값들 중에 가장 작은 값을 반환한다.
- MAX : 해당 컬럼 값들 중에 가장 큰 값을 반환한다.
Ex)
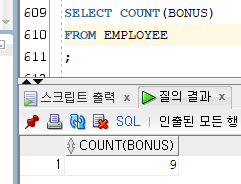
4) COUNT
[문법]
COUNT(*|컬럼명|DISTINCT 컬럼명)
- 컬럼 또는 행의 개수를 세서 반환하는 함수이다.
- COUNT(*) : 조회 결과에 해당하는 모든 행의 개수를 반환한다.
- COUNT(컬럼명) : 제시한 컬럼 값이 NULL이 아닌 행의 개수를 반환한다.
- COUNT(DISTINCT 컬럼명) 해당 컬럼 값의 중복을 제거한 행의 개수를 반환한다.
Ex)
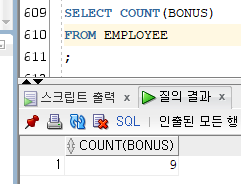
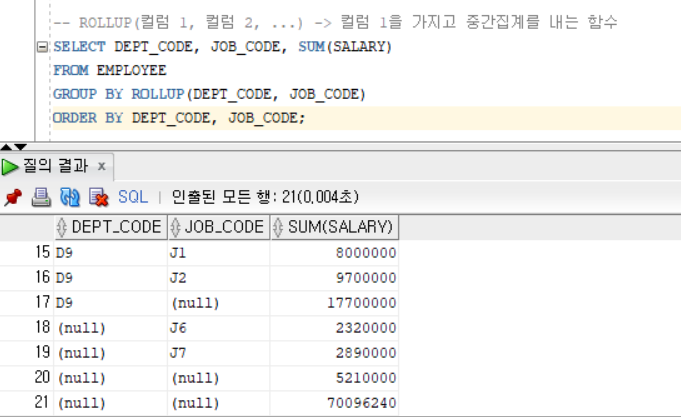
집계 함수
그룹별 산출한 결과 값의 중간 집계를 계산 해주는 함수Ex1 - ROLLUP)
Ex2 - CUBE)
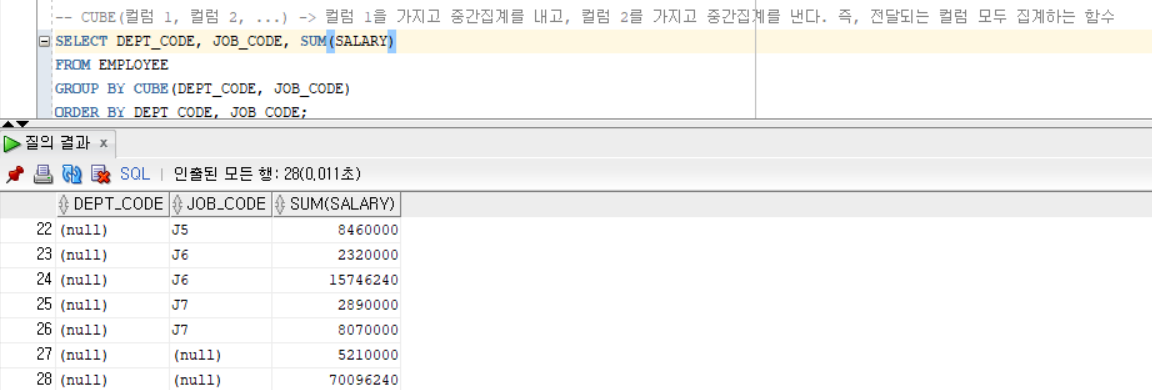
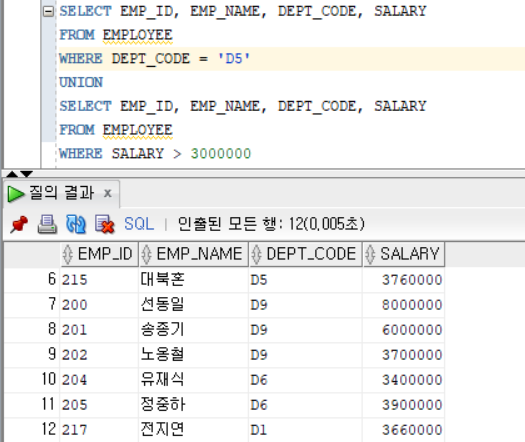
집합 연산자
- 여러 개의 쿼리문을 가지고 하나의 쿼리문으로 만드는 연산자이다.
UNION : 두 쿼리문을 수행한 결과값을 더한 후 중복되는 행은 제거한다. (합집합)
Ex)
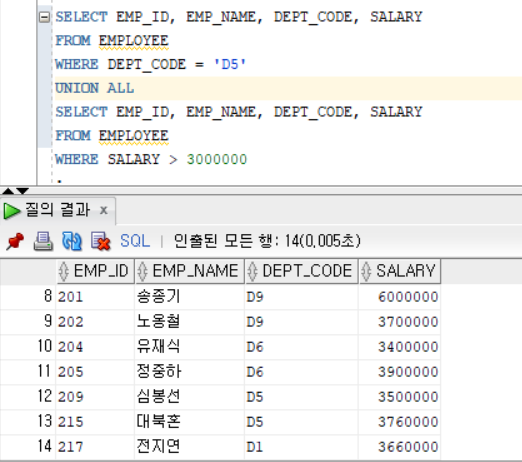
UNION ALL : UNION과 동일하게 두 쿼리문을 수행한 결과값을 더하고 중복은 허용한다. (합집합)
Ex)
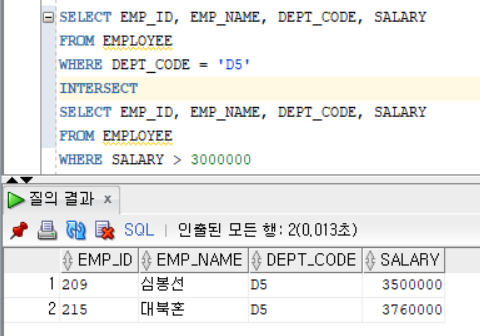
INTERSECT : 두 쿼리문을 수행한 결과값에 중복된 결과값만 추출한다. (교집합)
Ex)
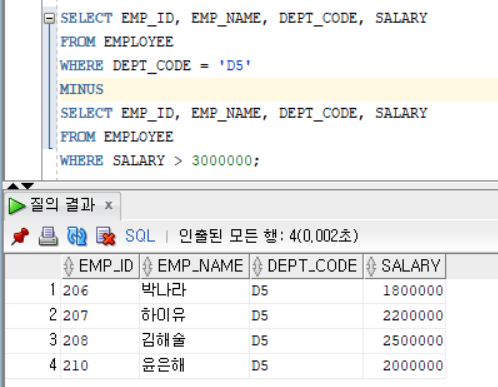
MINUS : 선행 쿼리의 결과값에서 후행 쿼리의 결과값을 뺀 나머지 결과값만 추출한다. (차집합)
Ex)
JOIN
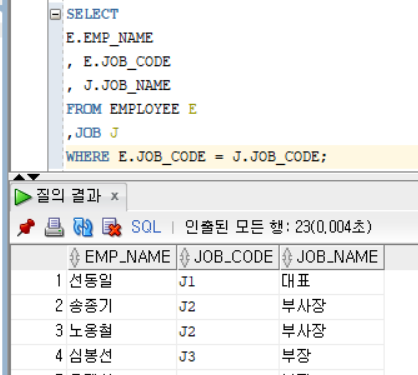
두 개의 이상의 테이블에서 데이터를 조회하고자 할 때 사용하는 구문이다.
- 등가 조인(EQUAL JOIN) / 내부 조인(INNER JOIN)
연결시키는 칼럼의 값이 일치하는 행들만 조인되서 조회한다.(일치하는 값이 없는 행은 조회 X)
1) 오라클 전용 구문
[문법]
SELECT 칼럼, 칼럼, ...
FROM 테이블1, 테이블2
WHERE 테이블1.칼럼명 = 테이블2.칼럼명;
- FROM 절에 조회하고자 하는 테이블들을 콤마(,)로 구분하여 나열한다.
- WHERE 절에 매칭 시킬 칼럼명에 대한 조건을 제시한다.
Ex)
2) ANSI 표준 구문
[문법]
SELECT 칼럼, 칼럼, ...
FROM 테이블1
[INNER] JOIN 테이블2 ON (테이블1.칼럼명 = 테이블2.칼럼명);
- FROM 절에 기준이 되는 테이블을 기술한다.
- JOIN 절에 같이 조회하고자 하는 테이블을 기술 후 매칭 시킬 칼럼에 대한 조건을 기술한다.
- 연결에 사용하려는 칼럼명이 같은 경우 ON 구문 대신에 USING(칼럼명) 구문을 사용한다.
Ex)
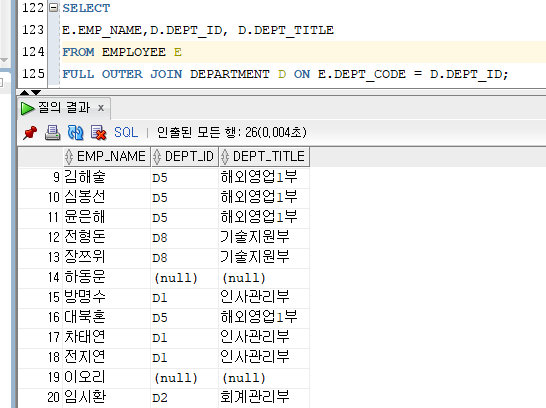
- 외부 조인 (OUTTER JOIN)
테이블 간의 JOIN 시 일치하지 않는 행도 포함시켜서 조회가 가능하다.
단, 반드시 기준이되는 테이블(컬럼)을 지정해야 한다. (LEFT/RIGHT/(+))
+FULLEx)
- 카테시안곱(CARTESIAN PRODUCT) / 교차 조인(CROSS JOIN)
조인되는 모든 테이블의 각 행들이 서로서로 모두 매핑된 데이터가 검색된다.
테이블의 행들이 모두 곱해진 행들의 조합이 출력 -> 과부화의 위험Ex)
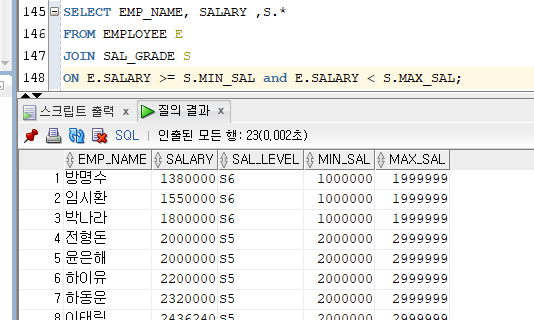
- 비등가 조인(NON EQUAL JOIN)
조인 조건에 등호(=)를 사용하지 않는 조인문을 비등가 조인이라고 한다.
지정한 칼럼 값이 일치하는 경우가 아닌, 값의 범위에 포함되는 행들을 연결하는 방식이다.
( = 이외에 비교 연산자 >, <, >=, <=, BETWEEN AND, IN, NOT IN 등을 사용한다.)
ANSI 구문으로는 JOIN ON 구문으로만 사용이 가능하다. (USING 사용 불가)Ex)
- 자체 조인(SELF JOIN)
같은 테이블을 다시 한번 조인하는 경우에 사용한다.
Ex)



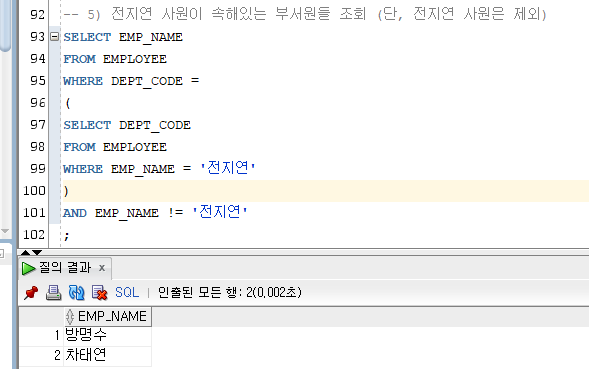
서브쿼리 (SUBQUERY)
하나의 SQL 문 안에 포함된 또 다른 SQL 문을 뜻한다.
메인 쿼리(기존 쿼리)를 보조하는 역할을 하는 쿼리문이다.EX)
서브 쿼리 구분
서브 쿼리는 서브 쿼리를 수행한 결과값의 행과 열의 개수에 따라서 분류할 수 있다.
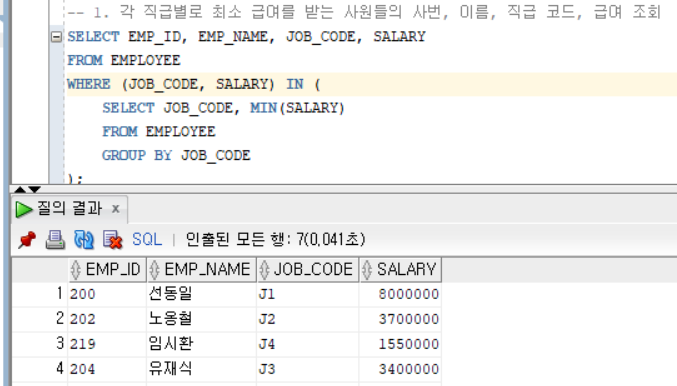
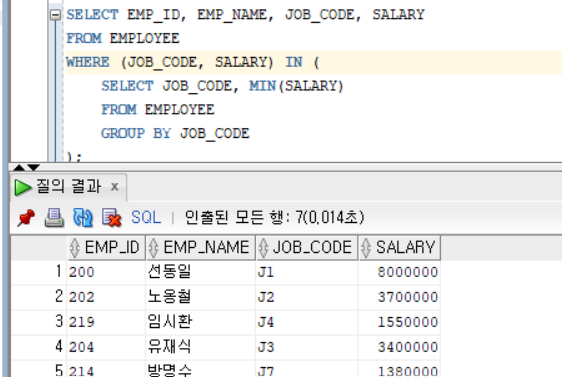
1) 단일행 단일열 서브 쿼리 : 서브 쿼리의 조회 결과 값의 행과 열의 개수가 1개 일 때
2) 다중행 서브 쿼리 : 서브 쿼리의 조회 결과 값의 행의 개수가 여러 행 일 때
3) 다중열 서브 쿼리 : 서브 쿼리의 조회 결과 값이 한 행이지만 칼럼이 여러개 일때
4) 다중행, 다중열 서브 쿼리 : 서브 쿼리의 조회 결과 값이 여러행, 여러열 일 때
- 서브 쿼리의 유형에 따라서 서브 쿼리 앞에 붙는 연산자가 달라진다.
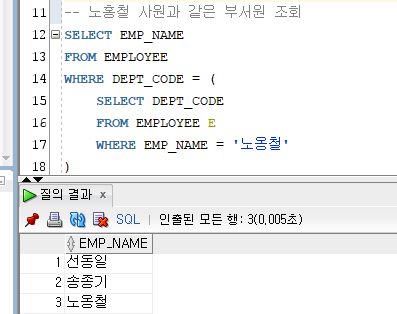
단일행 서브 쿼리
서브 쿼리의 조회 결과 값의 행과 열의 개수가 1개 일 때 (단일행, 단일열)
비교 연산자(단일행 연산자) 사용 가능 (=, !=, <>, ^=, >, <, >=, <=, ...)Ex)
다중행 서브 쿼리
서브 쿼리의 조회 결과 값의 행의 개수가 여러 행 일 때
- IN / NOT IN (서브 쿼리) : 여러 개의 결과값 중에서 한 개라도 일치하는 값이 있다면 혹은 없다면 TRUE를 리턴한다.
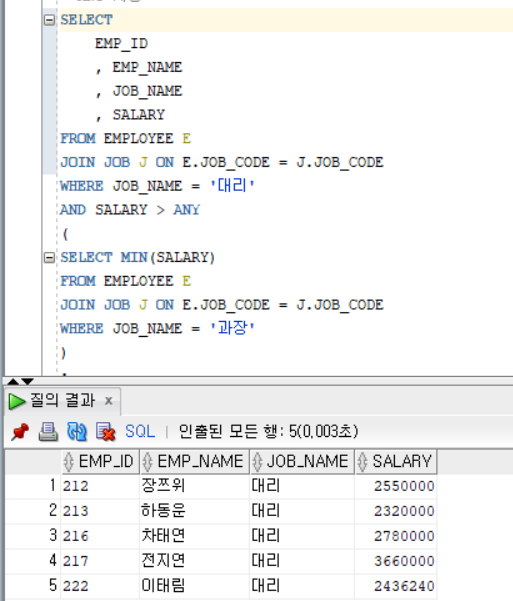
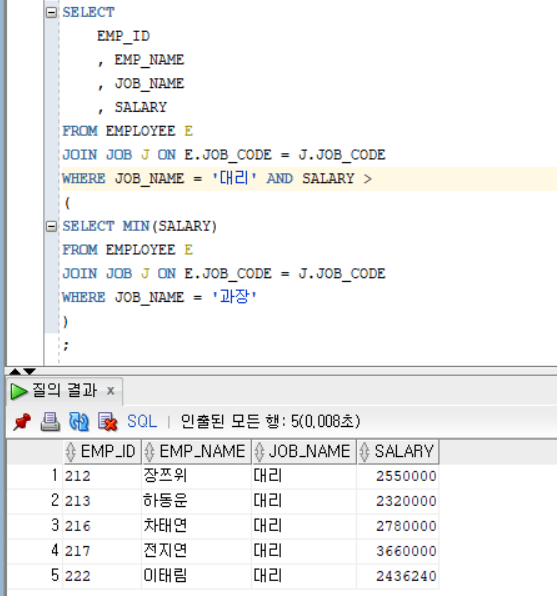
- ANY : 여러 개의 값들 중에서 한 개라도 만족하면 TRUE, IN과 다른 점은 비교 연산자를 함께 사용한다는 점이다.
ANY(100, 200, 300)
SALARY = ANY(...) : IN과 같은 결과
SALARY != ANY(...) : NOT IN과 같은 결과
SALARY > ANY(...) : 최소값 보다 크면 TRUE
SALARY < ANY(...) : 최대값 보다 작으면 TRUE
ALL : 여러 개의 값들 모두와 비교하여 만족해야 TRUE, IN과 다른 점은 비교 연산자를 함께 사용한다는 점이다.
ALL(100, 200, 300)
SALARY > ALL(...) : 최대값 보다 크면 TRUE
SALARY < ALL(...) : 최소값 보다 작으면 TRUEEx1 - ANY)
Ex2 -AND
다중열 서브 쿼리
조회 결과 값은 한 행이지만 나열된 칼럼 수가 여러 개일 때
Ex)
다중행 다중열 서브 쿼리서브 쿼리의 조회 결과값이 여러 행, 여러 열일 경우
Ex)
인라인 뷰
FROM 절에 서브 쿼리를 제시하고, 서브 쿼리를 수행한 결과를 테이블 대신 사용한다.
Ex)
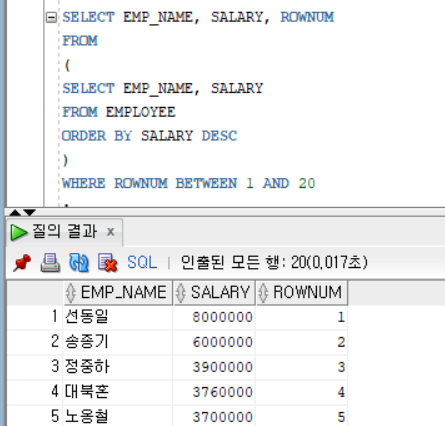
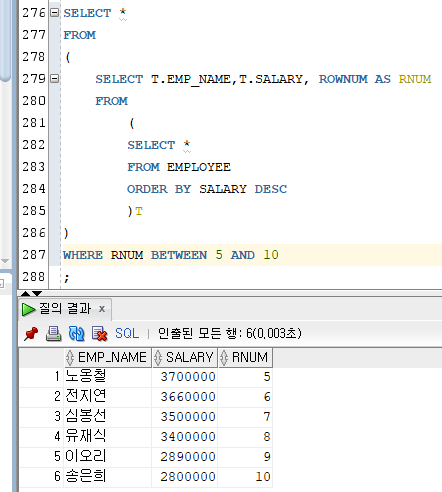
ROWNUM
오라클에서 제공하는 칼럼, 조회된 순서대로 1 부터 순번을 부여하는 칼럼
Ex)
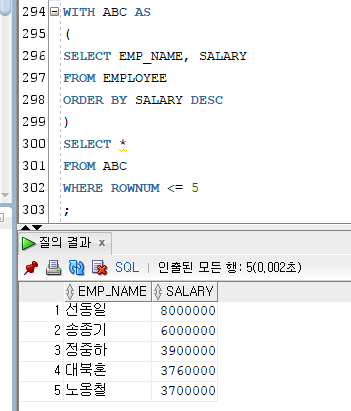
WITH
임시테이블 또는 가상 테이블, 반복되는 서브쿼리 블록을 하나의 WITH절 블록으로 만들어서 사용할 수 있다.
Ex)
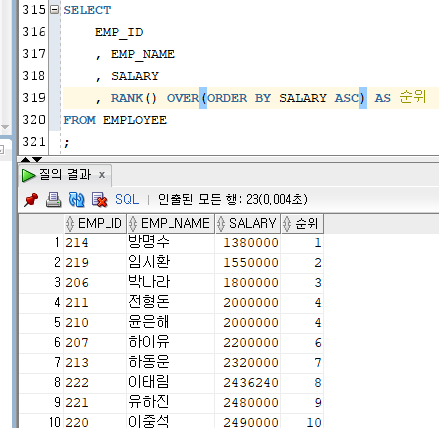
RANK 함수
[문법]
RANK() OVER(정렬 기준) / DENSE_RANK() OVER(정렬 기준)
- RANK() OVER(정렬 기준) : 동일한 순위 이후의 등수를 동일한 인원수만큼 건너뛰고 순위를 계산한다.
Ex)
- DENSE_RANK() OVER(정렬 기준) : 동일한 순위 이후의 등수를 무조건 1씩 증가한다.
Ex)

배운 학습 내용이 많아서 실습 문제를 풀면서 습득하는게 좋을 것 같다.
