[논문 리뷰] Unsupervised Deep Anomaly Detection for Multi-Sensor Time-Series Signals
2022 하계 Paper Review

본 Paper Review는 고려대학교 스마트생산시스템 연구실 2022년 하계 논문 세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다.
Abstract
- Multi-sensor 기술이 널리 쓰이면서, multivariate time-series data가 수집됨.
(e.g. Health Care, Human Activity Recognition, Inustrial Control System) - 이에 대해 Unsupervised Anomaly Detection 하는 것이 중요해졌지만 어려움이 있음.
- 1st 어려움 : Multi-sensor 데이터가 담고 있는 spatial-temporal 한 정보로부터 normal pattern을 찾기.
- 2nd 어려움 : Noisy한 데이터가 training 데이터셋에 섞인 상황에서 normal, abnormal, noisy data 구별.
- 본 논문은 Deep Convolutional Autoencoding Memory network (CAE-M) 네트워크 구조를 통해 위 2가지 어려움을 해결하고자 함.
- (1) Maximum Mean Discrepancy (MMD)를 가지고 multi-sensor data의 spatial dependence를 찾는 Deep Convoluutional Autoencoder
- (2) Linear (Autoregressive Model) | Non-linear (Bidirectional LSTM with Attention) 예측을 포함한 Memory Network를 통해 temporal dependence를 찾음
- CAE-M 모델은 위 두개의 네트워크 구조를 결합하고 최적화하여 앞서 말한 어려움들을 해결함.
- HAR, HC 데이터셋을 통해 실험하고 SOTA 기법들과 비교하여 모델의 뛰어난 성능 증명.
1. Introduction
Anomaly Detection 이란? 단순히 normal과 abnormal 분류? X
그렇다기에는 두 가지 Challenge가 존재.
- Imbalance (불균형) : 기존 분류기들은 accuracy를 높이고자 함. 따라서 긴가민가하면 Normal로 분류해버림.
- Hard of manual labeling : 특히 anomalous 행동들을 규정하고 라벨링하는 것은 어려움.
두 가지 challenge 때문에 Unsupervised anomaly detection 연구가 활발.
최근에는 Multi-Sensor가 다양한 분야에서 사용되면서, multivariate time-series 데이터가 많아짐.
이들을 다루기 위해서는 spatial-temporal dependency 문제를 고려해야하고 기존 방법론을 그대로 사용하기에는 몇 가지 Challenge가 존재.
- 1st : spatial-temporal data 에 대한 anomaly detection은 시간을 다루기 때문에 상당히 복잡.
- 2nd : reconstruction error 기반으로 anomaly detection을 하는 모델들이 많은데, 모델의 복잡성과 데이터의 noise 때문에 abnormal input 도 잘 복원해버리는 문제 존재.
- 3rd : dimensionality 를 줄이기 위해서 모델을 joint해서 사용하곤 하는데, local optima에 빠져서 제대로 학습되지 못하는 문제 존재.
위에서 말한 세 가지 문제점들을 해결하기 위해서 본 저자가 제시하는 방법론.
Deep Convolutional Autoencoding Memory network (CAE-M)
① Characterization network & ② Memory network 로 구성
- 두 가지 네트워크는 각각 feature extraction module (convolutional autoencoder) 과
forecasting module (attention-based Bidirectional LSTMs & Autoregressive model) 로서 기능- 따라서 reconstruction error 와 prediction error 를 동시에 minimizing 해야하는데 CAE-M 모델은 jointly optimized 될 수 있음.
- Training phase에서는, normal pattern을 학습하고자 함.
- Detection phase에서는, compound 된 objective function 을 계산해서 anomaly score로 사용함.
해당 방법론의 Contribution은 총 4 개
- Reconstruction과 Prediction analysis를 수행하며 spatial-temporal한 pattern을 규정할 수 있음.
- Maximum Mean Discrepancy (MMD) penalty를 사용하여 Deep Convolutional Autoencoder를 발전시켰기 때문에 noisy data의 영향을 줄일 수 있음.
- 두 개의 sub-network로 부터 Compound된 objective function을 동시에 optimize하는 end-to-end 학습 모델임.
- 다른 SOTA 모델들을 능가하는 성능을 보임.
2. Related Work
Anomaly detection 방법론들은 수십년간 연구되어 왔으며, 일반적으로 label 유무에 따라
Supervised, Semi-supervised, Unsupervised 학습 방식으로 구분됨.
그 중 본 논문은 Unsupervised anomaly detection에 초점을 둠.
각 모델별 자세한 설명은 본 논문보다 각 모델별 논문 혹은 Anomaly detection: Survey 논문들을 참고.
2.1 Traditional anomaly detection
| Reconstruction-based | Clustering-based | one-class learning |
|---|---|---|
| PCA | Gaussian Mixture Models (GMM) | One-Class Support Vector Machine (OCSVM) |
| Kernel PCA | k-means | Support Vector Data Description (SVDD) |
| Robust PCA | Kenel Density Estimator (KDE) |
이 밖의 시계열 자료에 관한 전통적인 anomaly detection은 다음과 같은 방법론 존재.
- Autoregression (AR) | Autoregressive Moving Average (ARMA) | Autoregressive Integrated Moving Average (ARIMA)
하지만 AR 기반 시계열 Anomaly detection은 높은 computational cost 때문에 현재는 잘 사용 X.
2.2 Deep anomaly detection
Reconstruction models
-
Autoencoders
Normal data로만 train 한 뒤, test에서 normal과 abnormal을 input으로 넣었을 때 reconstruction error가 높은 data points를 abnormal로 간주. -
LSTM Encoder-Decoder model
Input data의 temporal 정보를 잃지 않고 사용하기 위해 고안. 반면 spatial 정보는 반영 X -
Convolutional Autoencoders (CAEs)
주로 Video anomaly detection에서 사용되며, 2D image 구조를 반영할 수 있음. -
Convolutional long short-term memory (ConvLSTM)
Spatial-temporal 정보를 전부 반영할 수 있으며, 이는 FC layer를 Convolutional layer로 대체한 결과. -
Variational Autoencoders (VAEs)
multivariate gaussian distribution을 따른다고 가정하는 latent z를 계산하여 이로부터 sampling 하여 reconstruction을 진행하는 방법
그 밖에 Denoising AutoEncoders (DAEs) | Deep Belief Network (DBNs) | Robust Deep Autoencoder (RDA) 등이 존재함.
Forecasting models
Forecasting model들은 past sequence가 input으로 주어졌을 때 하나 이상의 continuous values 들을 예측하고자 함.
일반적으로 RNN과 LSTM이 sequence prediction에 사용됨.
추가로, 1D convolutional networks가 사용되기도 함.
이들을 동시에 사용하는 경우도 있는데, 대표적으로 LSTNet 모델의 경우 CNN과 RNN을 함께 사용하여 short-term local dependency와 long-term pattern을 추출하고자 했음.
이밖에도, 생성모델 GAN 기반의 anomaly detection 연구도 이루어지고 있음. 예시로 U-Net을 generator로 사용하여 영상 속 다음 frame을 예측하고 이상을 탐지함.
Composite models
최근에는 Single model들에 비해, Composite model들이 각광받고 있음.
예시로, Deep autoencoder + Gaussian Mixture Model 의 경우 저차원의 representation과 reconstruction error를 생성함과 동시에 다차원의 feature에 대한 density distribution을 학습할 수 있음.
하지만 해당 모델은 spatial-temporal dependency를 고려하지 못했는데 이를 고려한 모델들은 다음과 같음.
-
Composite LSTM model
하나의 Encoder와 여러개의 Decoder를 사용한 네트워크 구조
Input sequence를 복원 + Future sequence를 예측.
자세한 설명은 여기 있습니다. -
Spatial-Temporal AutoEncoder (STAE)
3D convolutional 구조를 사용해서 spatial-temporal 변화를 파악함.
이러한 Composite model들이 각광받는 이유는 기존 방식들의 단점들을 극복하고자 했기 때문.
| 기법 | 단점 |
|---|---|
| Traditional anomaly detection | spatial-temporal 패턴을 잘 학습하지 못함 |
| Reconstruction model | 오직 input에 관련된 정보를 저장하고자 함 |
| Forecasting model | 미래를 예측하기 위한 가장 최근의 값들만 저장하고자 함 |
본 논문은 Introduction에서 언급했듯이 4가지의 Contribution을 통해 기존의 Single model이 가지고 있었던 한계를 극복하고자 함.
3. The Proposed Method
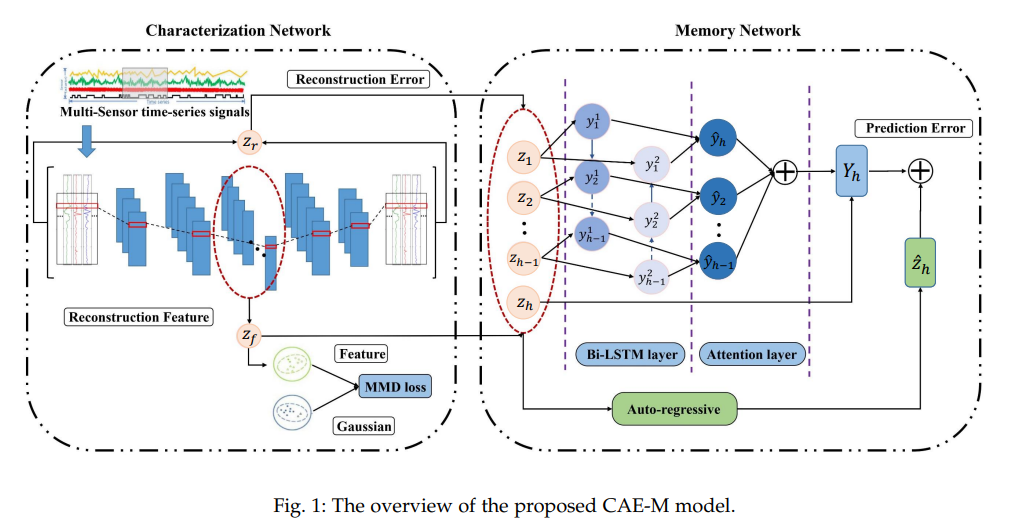
3.2 Overview
네트워크 구조 하나하나 자세하게 설명이 나오기 전, CAE-M 모델의 전체적인 프레임워크를 살펴보면 다음과 같음.
먼저 Characterization Network에서 multi-sensor time-series signals 내 spatial 정보를 Deep Convolutional Autoencoder (CAE)를 통해 저차원 representation으로 인코딩.
일반적으로 noisy data의 영향을 줄이기 위해, Memory module 혹은 Gaussian Mixture Model (GMM)을 사용하는 반면, CAE-M model은 Maximum Mean Discrepancy (MMD) penalty를 부여함.
그렇게 함으로써, train data의 분포를 Gaussian 분포를 따르도록 approximate하여 noise로 인한 overfitting 위험을 줄임.
그렇게 생성된 reconstruction error와 representation을 Memory Network로 전달.
Memory Network에서 Attention mechanism과 Bi-LSTM을 사용한 Layer와 Auto-regressive model을 함께 사용하여 temporal 정보를 모델링하게되어 future feature를 예측하게 됨.
네트워크를 거치면서 구해진 loss들을 모아 compound objective function을 계산하고 이를 바탕으로 anomalies를 detect하게 됨.
정상의 경우 추론하는 과정에서 reconstruct된 값들은 실제값과 유사하며, 비정상의 경우 reconstruct된 값들은 실제값과 멀리 떨어지기 때문에 loss function에 큰 변화가 생길 때 anoamlies를 detect하게 됨.
3.3 Characterization Network
해당 네트워크 계층에서는 Representative Learning이 이루어짐.
이를 통해 (1) 요약된 feature (2) reconstruction error 값이 구해짐.
Abnormal input 또한 복원 잘하도록 generalizing 되면 안되기 때문에, optimization function에 reconstruction loss를 결합하여 regularization 해줌.
이를 상세하게 표현하면 다음과 같음.
Deep feature extraction
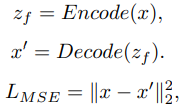
Deep convolutional autoencoder (CAE)는 Encoder와 Decoder로 이루어져 있음.
Encoder의 경우 covolutional과 max-pooling 계층을 거치며 원 데이터로부터 저차원의 feature를 추출.
Decoder의 경우 Encoder에서 거쳤던 계층을 동일하게 거치되 transposed 된 계층을 거침으로써 원 데이터 크기의 데이터로 복원됨.
복원된 데이터와 원 데이터 간의 Mean Squared Error (MSE)를 구함.
Handling noisy data
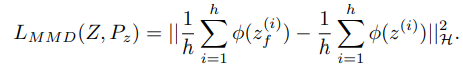
Training 시 정상 데이터에 noisy 데이터가 많이 포함되어 있다면 어떻게 될까?
그 결과로 normal과 abnormal 데이터를 잘 구분하지 못하고 둘 다 복원을 잘하게 됨. (Generalizing)
하지만 anomaly detection은 저차원 공간으로 데이터를 매핑했을 시에도 "숨어있는" anomalies를 잘 찾아내야만 함.
따라서 본 논문의 저자는 regularization term으로 MMD를 사용한 loss function을 제안함.
MMD를 사용한 loss function에 의해서 noisy data를 정상과 가깝게 만들게 하여 overfitting의 위험을 줄이게 됨.
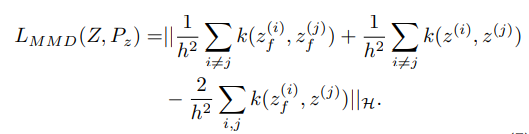
MMD를 사용한 loss function은 어떤 kernel을 사용했는 지에 따라서 수식이 조금씩 바뀌게 됨.
3.4 Memory Network
Complex spatial-temporal patterns를 제대로 찾아내기 위해 reconstruction과 prediction analysis를 수행.
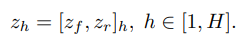
앞서 Characterization network에서는 feature representation을 거치면서 reconstruction error와 low-dimensional features들을 학습.
Memory Network에서는 linear 또는 non-linear한 방식으로 zh를 이전 z들을 가지고 예측.
각각의 방식이 어떻게 다른지 살펴보겠다.
Non-linear prediction
Non-linear prediction 방법으로는 RNN | LSTM | GRU 등을 생각해볼 수 있음.
하지만 RNN은 장기 의존성 문제가 존재.
따라서 본 논문은 Bidirectional LSTM with attention mechanism을 Non-linear prediction 방법으로 채택.
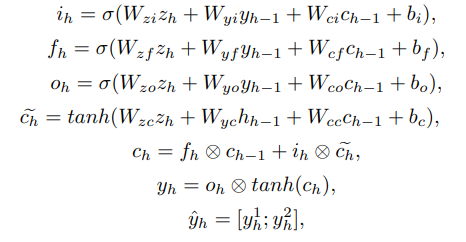
각 gate별 수식은 위와 같음.
수식을 하나씩 설명하기는 복잡하고, Bi-LSTM의 특징을 말하자면 past와 future의 정보를 어느 시점에서든 보존한다는 것.
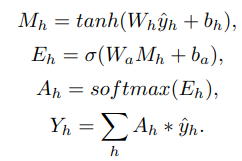
위 수식은 Attention mechanism에 관한 수식.
Attention에 대한 공부가 아직 부족하여 자세히 설명은 안되지만 이를 통해 temporal feature인 zh를 예측하게 되며 이를 context representation Yh로 표현.
Linear prediction
Linear prediction을 위한 모델로는 Autoregressive (AR) model이 있음.
물론 앞서 제시한 non-linear prediction 방법이 더욱 효과적이고 강력해보이지만.
short term modeling에 있어서는 AR model도 뛰어남.
따라서 non-linear memory network와 parallel하게 AR model도 사용.
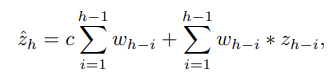
AR model은 위와 같이 정의됨.
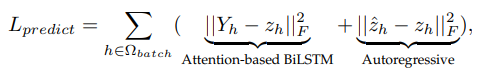
Output layer에서 prediction error를 도출해야하는데 이는 위 수식과 같이 non-linear 방식과 linear 방식을 결합하여 배치별로 계산하게 됨.
3.5 Joint optimization
Multi-step 접근법은 각 모델별로 최적화를 진행하기 때문에 local optima에 빠질 위험이 존재.
따라서 compound objective function을 minimize하는 end-to-end hybrid model을 제안.
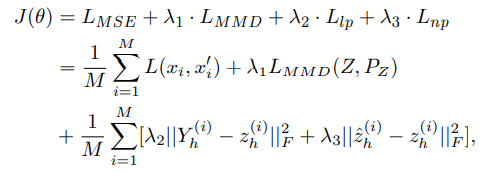
따라서 CAE-M objective는 MSE, MMD, Prediction error (non-linear, linear)로 구성되어 있음.
이는 위 수식에서 확인 가능하며 람다들은 meta parameter로 사용자가 직접 정의하는 것.
3.6 Inference
그렇다면 normal 혹은 abnormal을 추론하는 방법은 무엇일까?
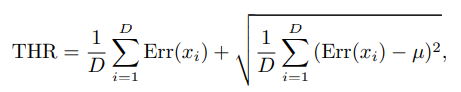
Threshold는 위와 같으며 Err(x) 값이 Threshold를 넘으면 abnormal 그렇지 않으면 normal로 규정.
학습 및 추론에 대한 전체적인 알고리즘은 다음과 같다.

4. Experiments
실험에 사용된 데이터셋은 크게 3가지로 public dataset 2개, private dataset 1개.
4.1 Datasets
- PAMAP2
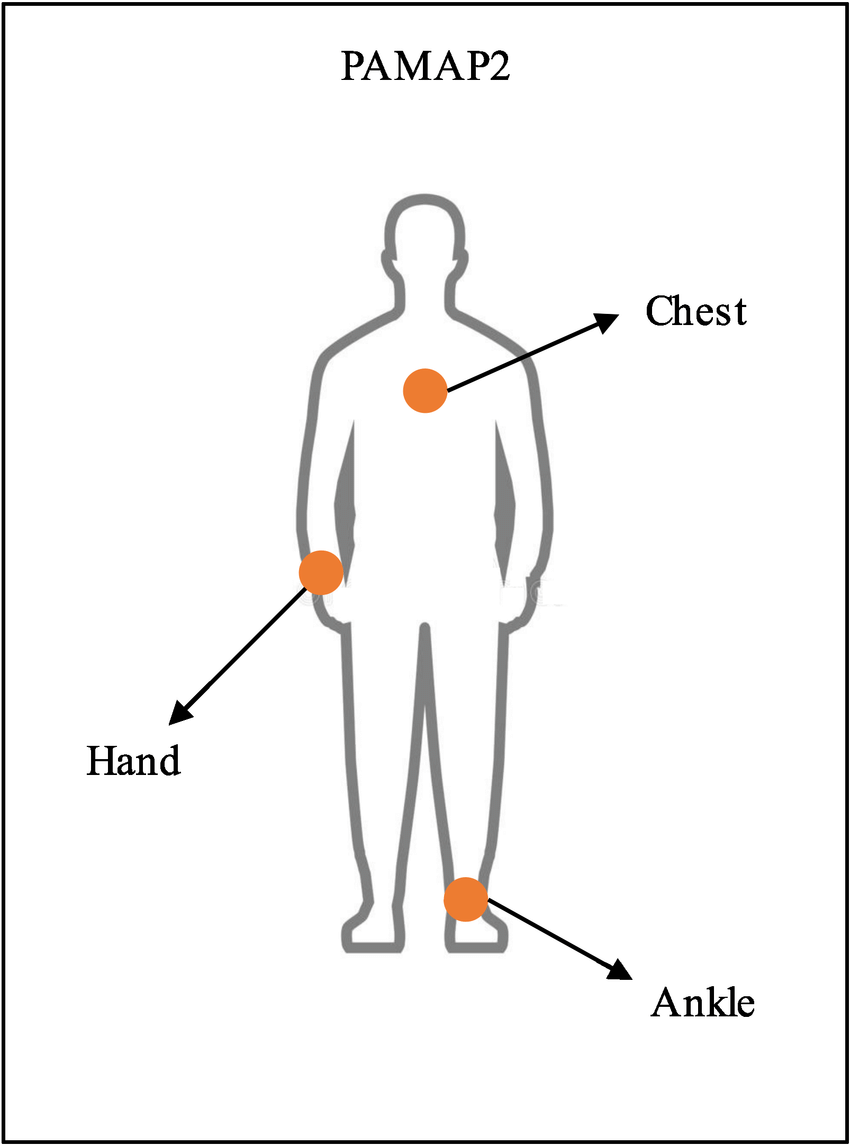
Accelerator, gyroscope, magnetometer 총 3개의 sensor.
18가지의 다른 행동 카테고리가 존재하며 그 중 적은 sample (running, ascending stairs, etc)들을 anomaly 나머지를 normal로 간주하고 실험.
- CAP Sleep Database

Cyclic Alternating Pattern 데이터셋으로 S1-S4 수면 단계 및 렘수면 카테고리가 존재.
7개의 sensor를 통해 수집.
16명의 건강한 사람들의 수면패턴을 normal, 92명의 환자들의 수면패턴을 abnormal로 간주하고 실험.
- Mental Fatigue Dataset
정신적 피로를 탐지하기 위한 데이터셋으로 실제 현실의 데이터셋이므로 공개 불가.
Non-fatigue한 사람을 normal로 fatigue한 사람을 anomaly로 간주하고 실험.

전체적인 데이터셋 개요는 위와 같음.
4.2 Baseline Methods
CAE-M 모델의 성능을 다른 모델들과 비교하기 위해 준비된 모델들은 총 9가지.
| Model |
|---|
| KPCA (Kernel principal component analysis) |
| ABOD (Angle-based outlier detection) |
| OCSVM (One-class support vector machine) |
| HMM (Hidden Markov Model) |
| CNN-LSTM |
| LSTM-AE (LSTM based autoencoder) |
| ConvLSTM-COMPOSITE |
| UODA (Unsupervised sequential outlier detection with deep architecture) |
| MSCRED (Multi-scale convolutional recurrent encoder-decoder) |
4.3 Implementation details
해당 Section은
- Characterization network에서 Conv2D layer와 Maxpooling layer를 쌓는 방식
- 해당하는 layer에서의 kernel size
- 다른 baseline model들을 실험에 사용할 때 정해줘야하는 Parameter들에 관한 구체적인 정의
를 다루기 때문에 본 리뷰에서 다루기 보다는 앞으로 이들을 활용해서 실제로 모델을 구현하고 실험하기 위해서 논문을 참고하는 것을 추천.
4.4 Results and Analysis
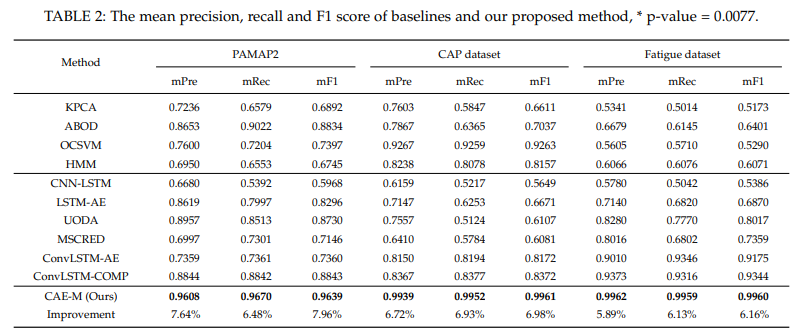
평가 지표로 Mean precision, Mean recall, Mean F1-score를 사용.
3가지 Dataset에서 전부 CAE-M model이 모든 평가지표에서 우수한 성능을 보였음.
특히 주목할 점은 Fatigue dataset의 경우 직접 normal과 abnormal에 대한 라벨링을 해주었기에 많은 noisy data가 포함되었음에도 불구하고 좋은 성능을 보였다는 점. (다른 baseline model들은 안 좋은 성능)
4.5 Fine-grained Analysis
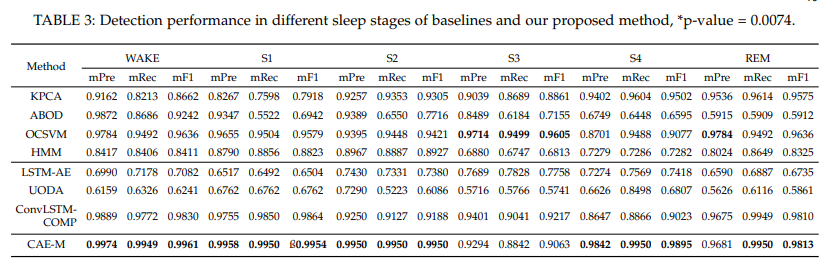
- Fine-grained란 : 하나의 작업을 작은 단위의 프로세스로 나눈 뒤, 다수의 호출을 통해, 작업 결과를 생성해내는 방식
따라서 CAP Sleep Database의 각 수면 유형을 abnormal로 규정하여 anomaly detection 하는 실험을 반복.
S3를 abnormal class로 규정했을 때를 제외하고 대부분의 경우에 가장 좋은 성능을 보임.
즉, CAE-M model은 Robust한 성능을 보임.
4.6 Effectiveness Evaluation
Leave One Subject Out
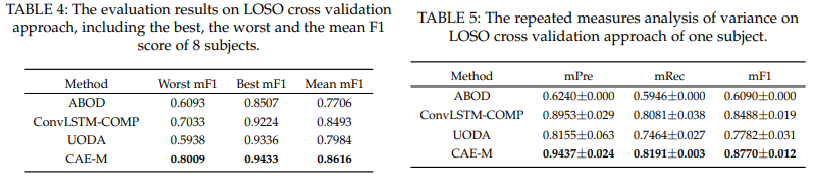
8번의 LOSO을 진행했을 때의 Worst, Best, Mean F1-Score를 비교한 결과 역시나 CAE-M 모델의 성능 우수.
또한, standard deviation도 다른 모델에 비해 더 작은 편으로 Robustness를 띔.
Ablation Study
- Ablation Study : 모델이나 알고리즘의 “feature”들을 제거해 나가면서 그 행위가 성능에 얼마나 영향을 미치는지를 확인해보는 것
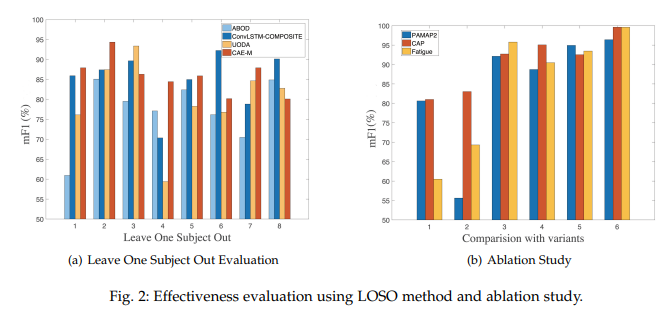
Fig.2(b)에서 하나씩 제거하는 feature들은 차례대로 non-linear & linear prediction, reconstruction error & MMD, attention module, AR, MMD & attention module.
그래프에 따르면 특히 reconstruction error와 MMD를 사용하지 않았을 때 F1-score가 현저하게 낮아지는 것을 확인.
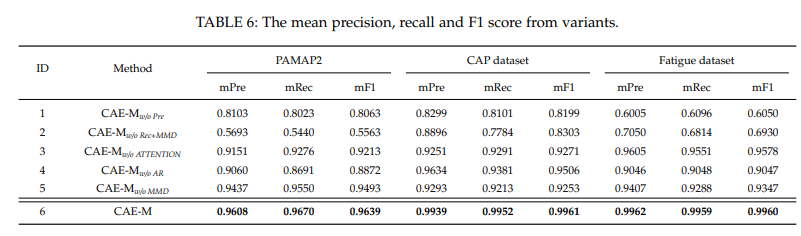
성능이 어느 정도 떨어지는 지는 위 표에서 확인 가능.
4.7 Robustness to Noisy Data
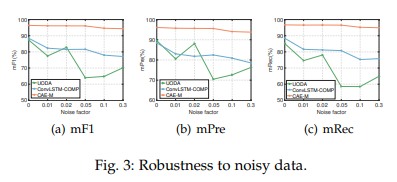
Fig.3 그래프에서 주황색 line이 CAE-M model의 성능.
Noise factor를 변화시켜봐도 크게 성능 차이가 발생하지 않음.
4.8 Further Analysis
Parameter Sensitivity Analysis
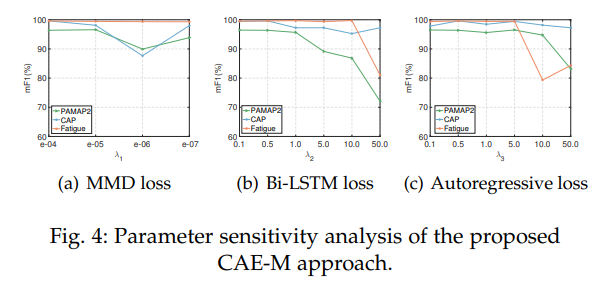
-
앞선 3.5. Section에서 제시된 람다값을 변화시키면서 각 loss 값들의 변화를 확인.
-
극단적인 값을 부여하면 성능이 많이 감소하지만, 적절한 값을 부여했을 시 비슷한 성능을 보임.
Convergence Analysis
- 전체적으로 안정된 학습 성능을 보임.
5. Conclusion and Future Work
-
본 논문은 Deep Convolutional Autoencoding Memory netrok (CAE-M) 네트워크를 제시함으로써 spatial-temporal한 정보를 학습하고 이상을 탐지하는 역할을 수행.
-
MMD penalty를 사용한 Deep Convolutional Autoencoder를 제시하여 noise에 의한 overfitting을 방지.
-
Temporal dependency를 더 잘 반영하기 위해, non-linear Bidirectional LSTM with Attention 모델과 linear Auto-regressive model을 예측에 사용.
-
Future Work : Point-based fine-grained anomaly detection.
함께 읽으면 좋을 논문

안녕하세요😄 논문 리뷰 글 잘 읽고 있습니다👍. Anomaly Detection을 공부하는 학생인데, 인상깊은 paper나 개념들을 notion이나 velog에 따로 작성해서 공부하고 싶은데 그래도 괜찮을까요.? 😅