[논문 리뷰] Be Your Own Teacher; Improve the Performance of Convolutional Neural Networks via Self Distillation
2024 동계 Paper Review

본 Paper Review는 고려대학교 스마트생산시스템 연구실 2024년 동계 논문 세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다.
Abstract
- CNN은 다양한 분야에서 사용되고 있으며, 정확도가 중요한 분야에서는 더욱 깊고 더욱 넓게 짜여지고 있는데, 이는 계산 비용과 저장 비용을 높이며, 반응 시간을 늦추는 단점이 있음
- 본 논문은 Self distillation 방법을 사용하여 네트워크의 크기를 오히려 줄이면서 CNN의 성능을 높임
- 해당 방법은 사전학습된 teacher 네트워크의 softmax 결과를 student 네트워크가 근사하도록하여 지식을 증류하는 이전 방법들과는 다르게 네트워크 그 자체 안에서 지식을 증류함
- 먼저 네트워크는 몇 가지 부분으로 나뉘고, 네트워크의 깊은 부분의 지식은 얕은 부분으로 squeeze됨
- 실험을 통해 다른 무거운 모델들보다 뛰어난 성능을 증명했으며, edge device에서도 사용할 수 있을만큼 flexible한 구조도 제안함
1. Introduction
CNN 덕분에 이미지 분류, 객체 탐지, 세그멘테이션 등의 분야에서 엄청 발전했다.
하지만 여전히 자율주행이나 의료 분야에서는 정확도와 짧은 반응 시간을 요구한다.
기존 방법들은 정확도 or 짧은 반응 시간에 집중해서 발달되었고, 지식 증류(Knowledge distillation)도 유사하게 모델 압축 기술 중 하나이다.
지식 증류 기법은 teacher로부터 students로 지식을 전이하는 기법이다. 정확히는 굉장히 많은 파라미터를 가진 teacher 네트워크를 컴팩트한 student network가 근사하는 것이다.
이렇게 한다면 student 네트워크는 성능 향상을 거둘 수 있고, 가끔은 teacher 네트워크보다 뛰어날 수도 있다.
하지만 단점도 존재하는데, 첫 번째는 지식 전이의 낮은 효율성이다. 즉, student 모델이 teacher 모델의 모든 지식을 활용하지 못한다는 것이다. 두 번째는 teacher 모델을 적절하게 설계 및 학습시키기 어렵다는 점이다. 가장 좋은 구조를 찾아내기 위해 많은 노력과 실험이 필요하며 해당 작업이 훨씬 많은 시간이 든다.
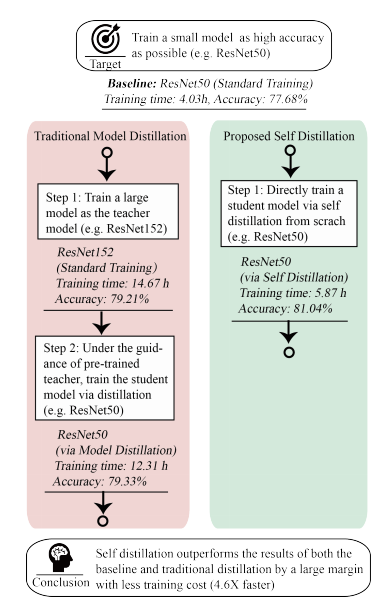
위 그림에서도 알 수 있듯, 본 논문은 새로운 self distillation 프레임워크를 진행하는데, 이는 전통적인 model distillation이 two-step으로 진행되는데에 반해 one-step으로 진행된다.
전통적인 방법은 먼저 거대한 teacher 모델을 학습시키고 다음으로 student 모델에 지식을 전이하는 two-step이다. 제안하는 방법은 student 모델에 직접적으로 집중하여 진행된다.
이렇게 함으로써 더 적은 학습 시간을 요하게 되며, 더 높은 정확도를 성취할 수 있게 된다.
Contribution은 다음과 같다.
1) Self distillation은 CNN 모델의 성능을 큰 폭으로 향상시키며 추가적인 반응 시간이 필요없어진다.
2) Self distillation은 하나의 신경망에 서로 다른 깊이를 적용할 수 있기 때문에 리소스가 제한적인 edge device에서 정확도-효율성 trade-off를 챙길 수 있다.
3) 2개의 데이터셋에 5가지의 CNN 모델에 대한 실험을 통해 일반화 성능도 검증하였다.
2. Related Work
Knowledge distillation
모델 압축 기술 중 하나.
FitNet : student와 teacher 모델의 feature map간의 거리를 줄이는 hint learning 제안
Agoruyko : attention region의 feature들을 align하는 attention 매커니즘
적대적 생성 문제에서도 활용됨.
Furlanello : student model --> teacher model, 더 나은 일반화 성능 거둠
Bagherinezhad : 데이터 증강에서 사용하여 더 높은 엔트로피를 갖는 라벨 값 생성
Papernot : adversarial attack 막는데에 사용
Gupta : 서로 다른 모달의 데이터 간 지식 전이에 사용
위 방법들과 달리 본 논문에서 제안하는 방법은 teacher와 student 모델이 같은 CNN 구조에서 나온다.
Adaptive Computation
이전 연구에서 중복성을 제거하기 위해 여러 계산 절차를 선택적으로 건너뛰는 경향이 존재했다.
- layers 건너뛰기 : layer-wise dropout, early-exiting prediction
- channels 건너뛰기 : switchable batch normalization
- 덜 중요한 pixels 건너뛰기 : CNN 모델에 input 이미지를 보내기 전에 강화학습이나 딥러닝 모델을 통해 어떤 픽셀이 중요한지를 미리 계산하는 방법
Deep Supervision
변별력이 높은 feature에 대해 훈련된 classifier가 추론 성능을 향상시킬 수 있다는 관점.
기울기 소실 문제를 해결하기 위해 hidden layer를 직접적으로 학습시키는 추가적인 supervision.
제안하는 방법은 Deep supervision과 유사하게 multi-classifier 구조를 채택했다.
3. Self Distillation
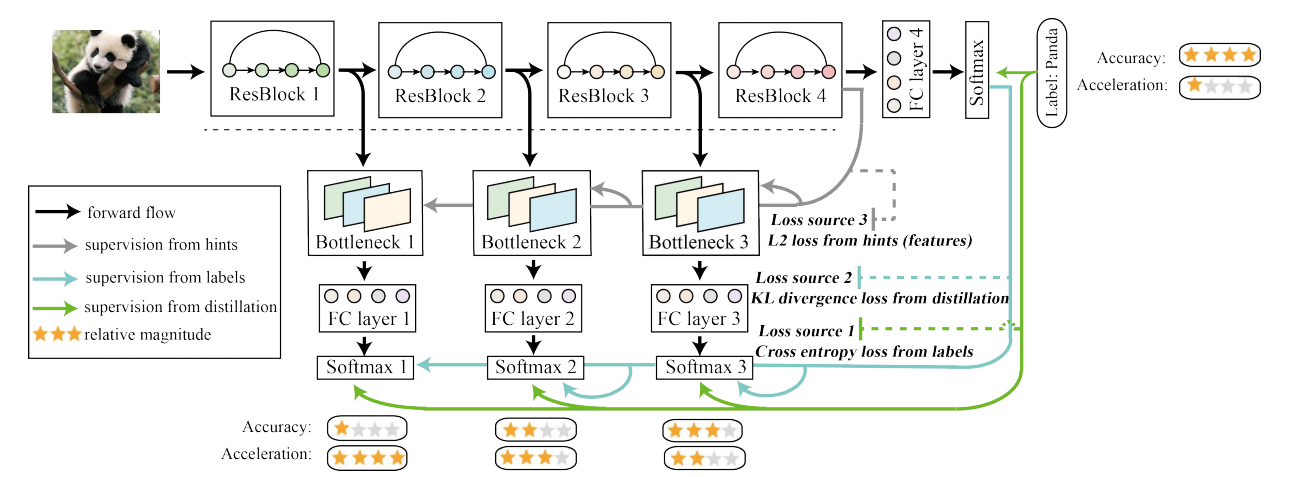
위 그림이 모델 구조이다. 복잡해보이기는 하지만 뜯어놓고 보면 간단하다.
먼저 본 논문에서 설명해서 사용한 모델은 ResNet50, 아마 실험에서는 ResNet18을 썼을 것이다.
그래서 ResBlock을 4개로 나누고 시작한다. ResBlock 1, 2, 3으로 쪼개진 부분은 shallow section이라고 부르고 ResBlock 4까지 거친 부분을 deepest classifier로 표현한다.
다음으로 shallow section 부분에는 Bottleneck layer와 FC layer를 결합한 classifier를 새롭게 세팅한다.
이건 학습시에만 쓰이고 추론 시에는 빠진다.
Bottleneck layer를 추가한 이유는 shallow classifier 간의 영향을 완화하고 힌트로 인한 L2 loss를 추가하기 위함이다.
저자가 해당 모델을 self distillation이라고 부르는 이유는 deepest classifer 부분이 teacher 모델 shallow classifier 부분이 student model로 생각하면 유사하게 지식 증류 효과를 얻을 수 있다는 것이다.
모델 구조에서 사용된 loss는 총 3가지이다.
(1) Loss Source 1 : 실제 라벨과 deepest classifier의 결과 & shallow classifier의 결과에 대한 Cross entropy. 해당 손실함수를 통해 데이터셋에 내재된 지식을 모든 classifier에 주입할 수 있게 됨. 총 4개의 loss가 사용됨.
(2) Loss Source 2 : Teacher guidance 하에서의 KL divergence loss. shallow classifier의 각 softmax 결과물과 deepest classifier의 softmax 결과물 사이의 분포 차이를 줄임으로써, teacher 네트워크의 지식을 증류할 수 있게됨.
(3) Loss Source 3 : 힌트로부터의 L2 Loss. Deepest classifier의 feature map과 각 shallow classifier의 feature map 간의 L2 loss를 계산하여, 각 shallow classifier의 bottleneck layer에 feature map의 지식이 도입되어서 모든 classifier가 Deepest classifier의 feature map에 맞도록 유도된다.
위 그림에서 대쉬 모양의 선들은 추론시에는 사용되지 않는다.
즉 추론시에는 Loss source 1만 사용되는 것이다.
추론시에 해당 부분들을 사용할지는 또 다른 옵션으로 줄 수 있다.
Formulation
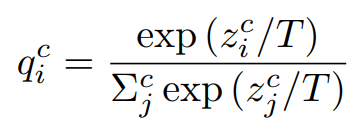
여느 지식 증류 기법들과 동일하게 formulation 된다.
c는 어떤 classifier인지를 나타내고, i는 i번째 class이다.
q는 확률이다.
Training Methods
해당 파트는 앞서 제시한 3가지 loss에 관한 부분이다.
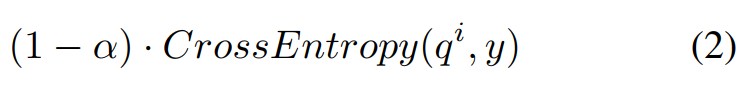
labels 와 각 classifier의 softmax layer output인 간의 cross entropy loss이다.

각 classifier의 softmax layer output인 와 deepest classifier의 softmax layer output인 간의 KL divergence loss이다.

Deepest classifier의 hint로부터 L2 loss를 정의한 것이다.
shallow classifier의 feature map들이 deepest classifier의 feature map과 유사하게 된다.
여기서 주의할 점은 서로 다른 깊이의 feature map들은 크기가 다르다는 것인데, 일반적으로 CNN을 통해 크기를 맞춰주지만 저자는 모델 성능에 긍정적인 영향을 보여주는 bottleneck 구조를 사용했다.
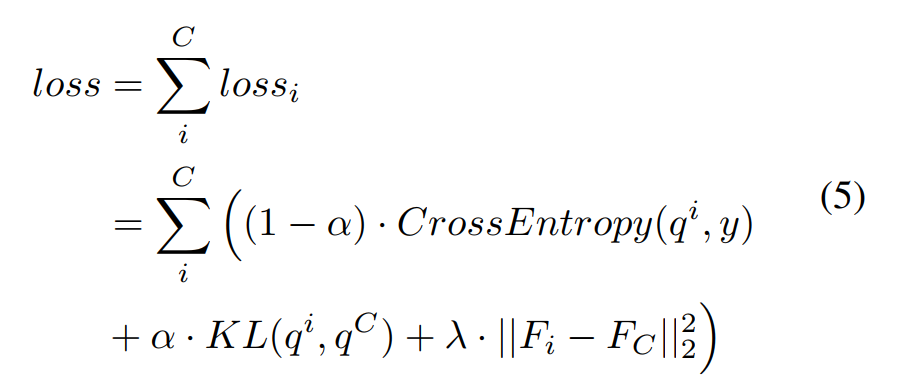
최종으로 합친 loss function은 위와 같다.
주목할 점은 hyperparameter가 와 두 개 있다는 것이다.
Deepest classifier의 hyperparameter는 전부 0으로 설정해서, deepest classifier의 학습은 오직 label로부터 이뤄지도록 한다.
4. Experiments
실험에 사용된 모델은 ResNet, WideResNet, Pyramid ResNet, ResNext, VGG 총 5개.
실험에 사용된 데이터셋은 CIFAR100, ImageNet 총 2개.
학습 시에 learning rate decay나 간단한 데이터 증강 기법이 사용되었다.
Benchmark Datasets
CIFAR 100 : 32x32 pixel 크기의 RGB 이미지 데이터셋. 100개의 클래스가 존재하며 학습 set에 50K, test set에 10K 존재한다.
ImageNet : ImageNet2012 분류 데이터셋이며, 1000개의 클래스가 존재함. 크기는 256x256 pixel 크기의 RGB 이미지.
Compared with Standard Training
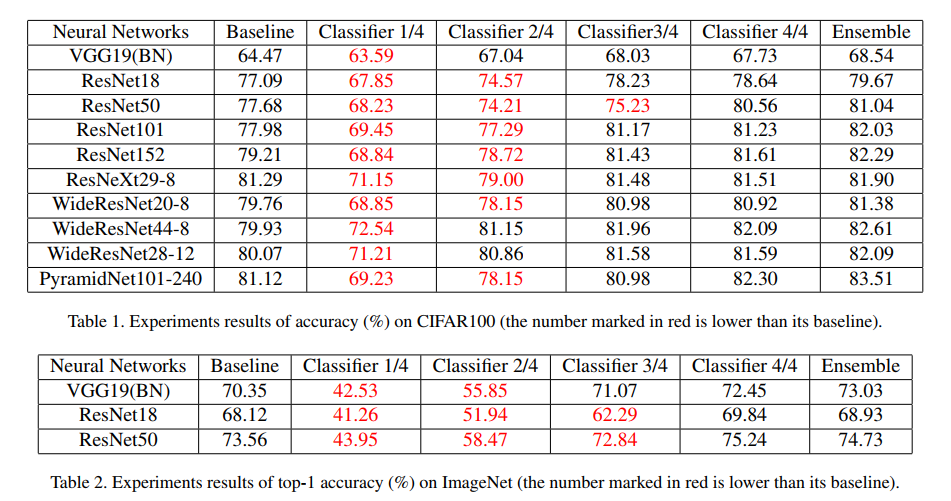
먼저각각의 shallow classifier와 deepest classifier 그리고 그들을 앙상블했을 시에 성능 차이가 어느 정도 나는지 확인하는 실험.
확실히 더 얕은 classifier 들은 baseline보다 성능이 쫌 떨어지고, ImageNet 같은 거대한 데이터셋에서는 성능 차이가 더 큰 것을 알 수 있다.
Compared with Distillation

먼저 Table 3는 5개의 다른 지식 증류 기법과의 비교이다.
확인해보면 Baseline 보다 Student model들의 성능이 전부 뛰어나다.
그리고 제안하는 방법은 다른 지식 증류 기법들이 거대한 Teacher model을 필요로 하는데 반해,
추가적인 Teacher model 없이 Self distillation이 가능하여 효율적이고 성능 또한 더 뛰어난 것을 확인할 수 있다.
앞서 처음 제시한 그림에서 알 수 있듯, self distillation 프레임워크는 추가적인 Teacher model이 필요하지 않으며 이는 다른 지식 증류 기법들에 비해 4.6X 더 빠른 학습 속도를 얻을 수 있다.
Compared with Deeply Supervised Net
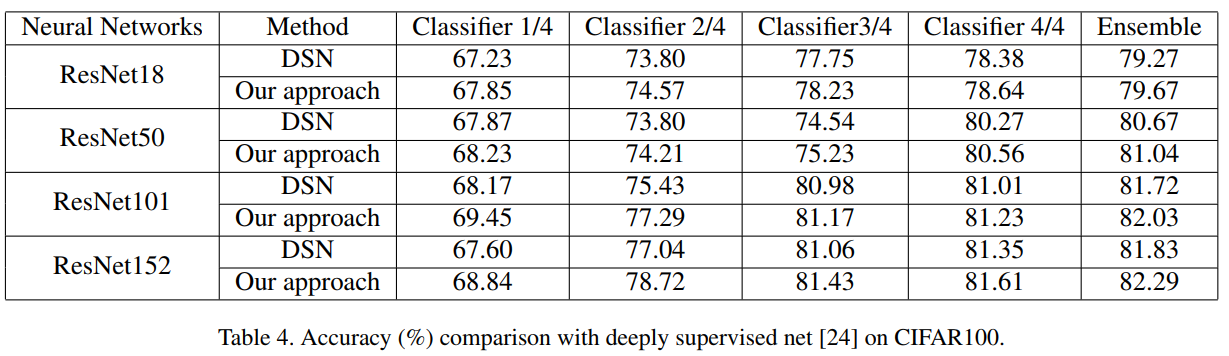
DSN과의 차이점은 shallow classifier를 라벨이 아니라 deepest classifier의 지식 증류로 부터 학습시킨다는 점이다.
해당 방법을 통해 CIFAR100에서 실험한 결과 DSN보다 높은 성능을 거둘 수 있었다.
총 3가지 이유로 좋은 성능을 거뒀을 것이라 설명한다.
1) 추가적으로 사용한 bottleneck layer가 shallow와 deep classifier가 충돌하지 않고 classifier 특화된 feature를 탐지했을 것이다.
2) 증류 기법이 성능을 boost 했을 것이다.
3) Shallow classifier가 더욱 discriminating한 feature를 얻어냈을 것이다.
Scalable Depth for Adapting Inference
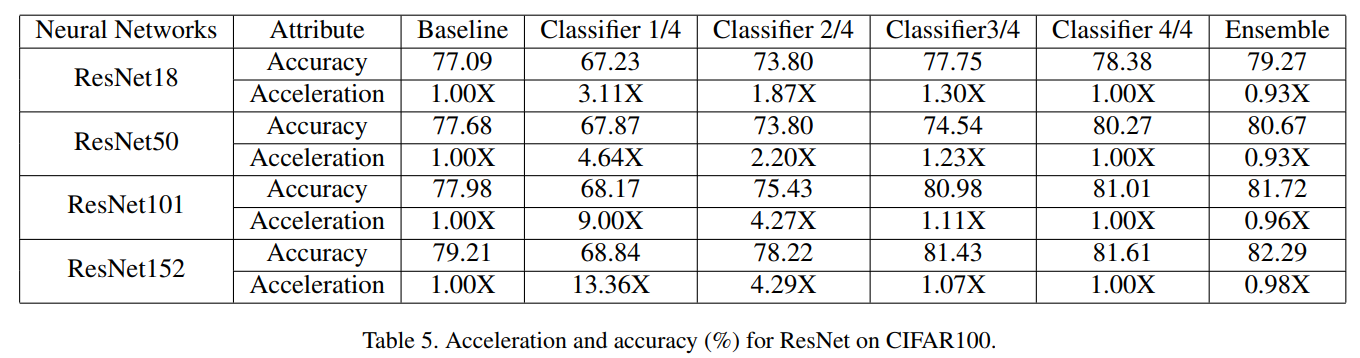
더 shallow한 classifier를 사용하면 성능은 살짝 떨어지겠지만 속도가 많이 상승한다.
5. Discussion and Future Works
Flat minima / 기울기 소실 / Discriminating features의 관점에서
Self distillation이 왜 성능 향상에 도움이 되는지를 설명하는 파트.
Self distillation can help models converge to flat minima which features in generalization inherently.
학습 set에서 shallow 네트워크가 아무리 잘해도, 테스트 set이나 실제 적용할 때는 over-parmeterized 신경망보다 훨씬 못할 때가 많다.
Keskar에 따르면 오버 파라미터인 모델이 flat minima에 더 쉽게 수렴할 수 있으며,
반면 shallow 신경망은 데이터 편향에 민감한 sharp minima에 빠지기 쉽다.
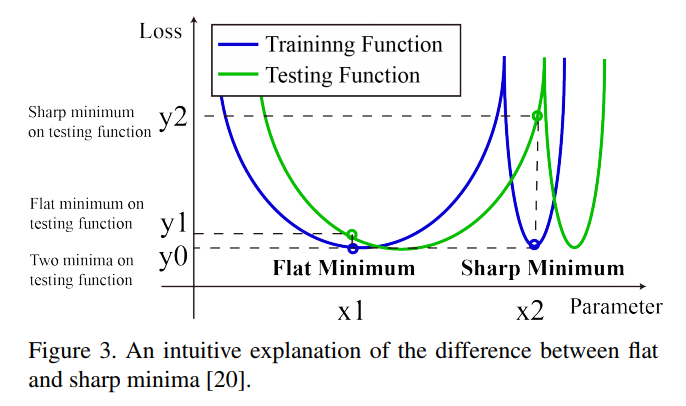
위 그림이 flat minima와 sharp minima의 직관적인 그림이다.
X 축이 파라미터 개수, Y 축이 손실함수 값이다.
가 학습 set이라고 했을 때, Flat minimum 이나 Sharp minimum 모두 작은 손실함수 값을 보인다.
하지만 테스트 set은 학습 set과 iid가 아니다.
그래서 테스트 시에 과 모두 minima 과 를 찾으려 할때, - 가 - 보다 훨씬 커지는 편향이 발생한다.
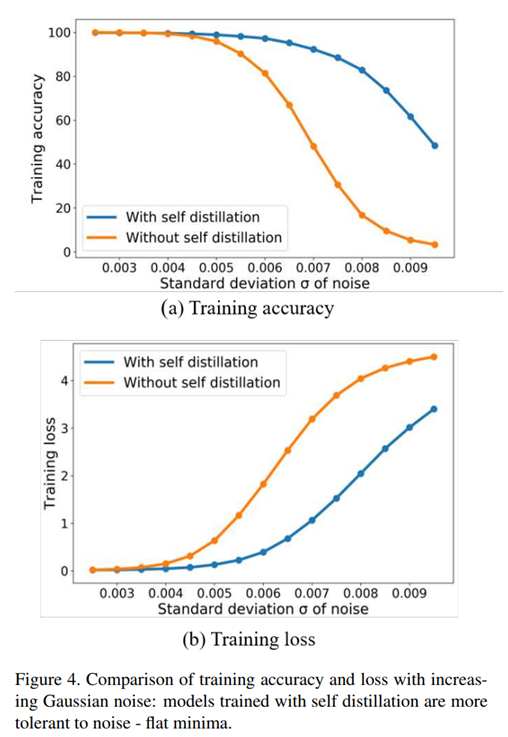
위 실험의 경우 두 개의 ResNet-18 모델을 CIFAR100 데이터셋에서 학습 시킨 결과인데, 한 쪽은 self distillation을 한 쪽은 아무것도 적용시키지 않았다.
그리고 파라미터에 Gaussian noise를 추가한다면, self distillation이 있는 경우에는 noise가 커져도 정확도가 많이 감소하지 않으며 loss도 많이 커지지 않는다.
이를 통해 self distillation을 적용한 쪽의 모델이 더욱 flat 하다고 주장할 수 있다.
결론적으로 훨씬 좋은 일반화 성능을 보장할 수 있다.
Self distillation prevents models from vanishing gradient problem
이번에도 self distillation이 적용된 ResNet-18과 그렇지 않은 ResNet-18을 사용하여 실험했다.
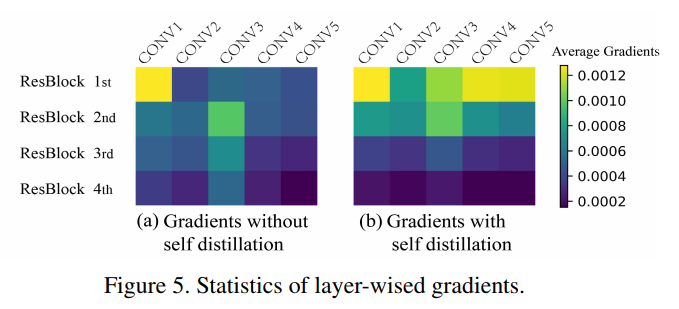
각 ResBlock의 Conv layer 기울기 정도를 살펴보면 위와 같다.
Self distillation이 없는 쪽보다 있는 쪽의 기울기가 훨씬 큰 것을 알 수 있다.
특히 ResBlock 1st, 2nd에서 더 큰 것을 볼 수 있다.
따라서 self distillation이 적용되면 기울기 소실 문제가 덜 발생할 것이다.
More discriminating features are extracted with deeper classifiers in self distillation
이번에는 CIFAR100 데이터에 WideResNet 모델을 학습시킨 결과이다.
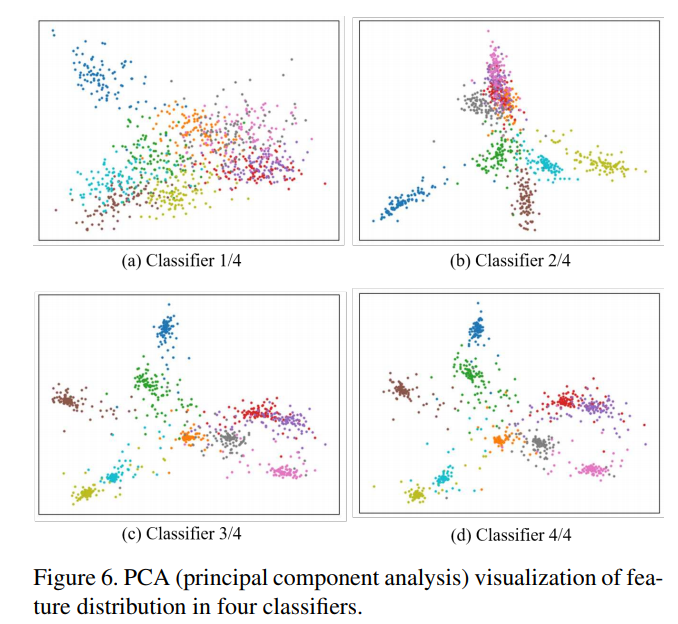
3번째 4번째 classifier에서의 feature 분포에 대한 PCA를 살펴보면 위 그림과 같다.
더 깊은 classifier 일수록 feature가 더 잘 집중되어 있는 것을 볼 수 있다.
또한 shallow classifier에서의 거리 변화는 deep classifier에서의 거리 변화보다 더 심하다.
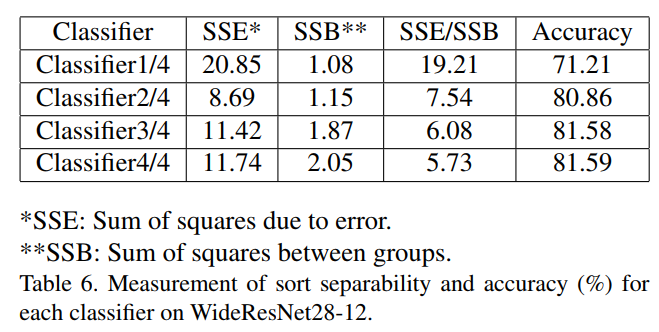
SSE가 작을 수록 cluster가 더 dense 하다는 것이다. SSB가 커질 수록 cluster가 더 discriminating하다.
SSE/SSB를 통해 판별력을 평가했고, 작을 수록 더욱 명확한 것이다.
위 표를 통해 classifier가 더 깊어질수록 SSE/SSB가 감소하는 것을 볼 수 있다.
결론적으로 classifier에 더욱 discriminating한 feature map일수록, 더 높은 정확도를 얻을 수 있다.
Future works
- 새롭게 도입된 파라미터 와 를 자동적으로 조절?
- Self distillation에 의한 flat minima가 이상적인가?
6. Conclusion
DSN과 다른 지식 증류 기법과 비교해봤을 때, 제안하는 self distillation이 훨씬 우수했다.
추가적인 teacher model이 필요 없었고, adaptive하게 시간-정확도 tradeoff에 맞게 classifier를 선정 가능했다.
Flat minima, 기울기 소실, discriminating feature의 관점에서 self distillation이 왜 좋은지 설명했다.
