[논문 리뷰] Data augmentation based on diffusion probabilistic model for remaining useful life estimation of aero-engines
2025 동계 Paper Review

본 Paper Review는 고려대학교 스마트생산시스템 연구실 2025년 동계 논문 세미나 활동입니다. 논문의 전문은 여기에서 확인 가능합니다.
Abstract
- RUL 예측에서 run-to-failure 모니터링 데이터를 획득하는 것이 어렵고 비용이 많이 들기 때문에 기존 딥러닝 기술을 바로 접목하기 힘들었음
- 이에 따라 본 연구는 다변량 엔진 모니터링 데이터를 증강하고, 실제 열화 경향을 모방하는 고품질 샘플을 생성하는 DiffRUL 방법을 제안
- 열화 트렌드에 특화된 인코더를 사용해서 열화 트렌드 표현을 추출하여 생성 조건으로 활용
- 그 후 Diffusion 모델을 사용하여 다변량 모니터링 데이터를 생성하는데, 기존의 가우시안 노이즈 적용 및 복원 과정을 따름
- 추가로 데이터의 spatio-temporal 상관관계를 포착하기 위해 인코더에서 추출된 열화 트렌드 패턴 조건을 denoising 네트워크에 통합시킴
- 실험은 C-MAPSS와 N-CMAPSS 데이터셋에서 진행되었으며, 새롭게 생성된 샘플을 포함한 RUL 예측 성능 향상을 입증함
1. Introduction
항공기 엔진에서 신뢰성이 매우 중요하기 때문에 PHM 분야의 연구가 활발하게 이루어진다. PHM은 센서 모니터링, 데이터 분석, 고장 진단, 잔여 수명 예측 (RUL estimation)을 포함한다. 그 중에서도 사전 예방적인 유지 보수를 위해서는 RUL 예측이 가장 중요한 역할이다.
딥러닝 방법들이 주로 RUL 예측을 위해 활용되었으며, CNN 계열의 모델들, RNN, LSTM 계열의 네트워크들, Transformer 기반 모델들이 주로 활용되었다. 해당 모델들을 사용해서 열화 패턴을 포착하고 특징들을 추출했으며 비선형 Health index 개발하는 연구가 진행되었다.
상당한 발전이 있었으나 해당 방법들에 있어서 가장 큰 문제는 run-to-failure 데이터셋에 크게 의존한다는 것이다. 데이터 수집이 더 쉬워진 세상이 온 것은 맞지만 전체 lifecycle 데이터를 얻는 것은 여전히 너무 어렵다. 이를 극복하고자 GAN 기반 모델들을 통해 데이터를 생성해내는 연구들이 이루어졌다.
하지만 GAN 방법론은 생성자와 판별자 사이에서의 수렴이 잘 이루어지지 않는 문제로 인한 불안정성 문제가 존재했다. 이에 따라 mode collapse가 발생해서 다양한 생성을 하지 못하게 되었으며 심각한 경우 동일한 생성물이 반복적으로 생성되어 다양성을 해치는 문제가 발생했다. 그리고 시스템 모니터링 데이터는 일반적으로 다변량이며 넓은 스펙트럼의 센서로 이루어져있는데 예를 들어 온도, 압력, 진동 센서값들이 존재한다. 이러한 다변량 데이터를 생성할 때는 복잡한 spatio-temporal 상관관계를 잘 처리해서 데이터 품질을 보존하는 것이 중요하다. GAN 기반 모델들은 복잡한 패턴을 정확하게 포착하기 어렵고 다양한 조건에서 작동하는 여러 고장 모드들을 반영하지 못한다.
위에서 언급한 문제점들을 해결하고자 본 연구는 DiffRUL 모델을 제안한다. 해당 모델은 생성모델 분야에서 핫한 디퓨전 생성기법을 활용한다. 일반적으로 디퓨전 모델이라 함은 원본 데이터셋에 노이즈를 통합하는 방식으로 부수고, 해당 통합 방식을 역으로 모델링하여 데이터를 합성하도록 학습된다. GAN과 비교했을 때 학습 안정성이 뛰어나 mode collapse 문제가 적고 전체 데이터 분포를 더 잘 모방할 수 있다.
이전 연구들에서 디퓨전 모델을 활용해서 HI를 정의하거나 RUL 예측을 수행한 경우는 존재했다. 하지만 데이터를 생성해서 RUL 예측 성능을 향상시키고자 하는 연구는 많이 이뤄지지 않았다.
본 연구의 주요 기여점은 다음과 같다.
-
먼저 degradation trend encoder (DTE)를 사용하여 다양한 운영환경에서의 데이터와 여러 고장 모드에 따른 데이터를 반영할 수 있도록 하였다. 시스템 모니터링 데이터의 열화 트렌드에 대한 정확한 표현을 포착할 수 있었다. 이렇게 구별된 표현들은 생성 조건으로서 활용되어 생성 모델이 더 효과적으로 복잡한 패턴과 분포를 학습할 수 있도록 하였다.
-
DiffRUL이라는 혁신적인 방법을 도입하여 다변량 모니터링 데이터를 생성하는 디퓨전 모델을 채택하였다. 해당 방법이 데이터를 생성하는 과정은 기존의 디퓨전 모델과 유사하지만 여러 노이즈 정도를 사용한다는 차이가 있다. 이렇게 생성된 데이터는 실제 데이터와 분포적으로 유사하고 실제 시스템에서 볼 수 있는 열화 패턴을 잘 반영한다는 장점이 있다.
-
DiffNet이라는 denoising 네트워크를 개발해서 다변량 시스템 모니터링 데이터에 존재하는 spatio-temporal 상관관게를 잘 포착하도록 하였다. 각 디퓨전 timestep에서 노이즈 정도를 정확하게 예측하도록 하여, DiffNet이 DiffRUL 프레임워크를 보조하였다.
-
제안하는 방법의 효과성을 실험적으로 잘 증명하였다.
2. Problem formulation
2.1 Data preparation
시스템 모니터링 데이터는 일반적으로 다변량이고, 여러 엔진으로부터 나온다고 가정한다. 이를 수식화하면 다음과 같다.
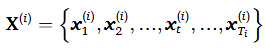
해당 수식을 보면 t가 시점이기 때문에, 시계열 데이터임을 알 수 있고 이에 따른 RUL 값은 다음과 같이 표현된다.
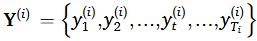
이는 t시점에서의 RUL 값을 의미하며 다음과 같이 표현하면 이해하기가 더 쉽다.
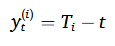
실용적인 측면에서, 초기 운영 동안의 시스템 열화는 일반적으로 무시할 수 있을 정도로 미미해서 위와 같은 linear RUL 타겟함수 보다는 아래와 같은 piecewise linear RUL 타겟함수를 사용하게 된다.
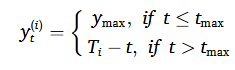
가 cutoff threshold로 초기 운영 상태에서는 constant 값으로 유지하는 것이다.
추가적으로 다양한 센서들에서 수집된 데이터의 범위도 크게 다르기 때문에 정규화 과정이 필요하다. 그래서 저자들은 min-max 정규화를 적용하였다.
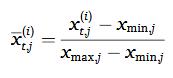
2.2 Data segmentataion
저자들은 시간 방향으로 sliding window를 사용해서 정규화된 다변량 모니터링 데이터를 window size , step size 1로 하여 시계열을 나누었다.
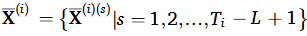
이렇게 잘려진 데이터에 대해 RUL 라벨은 간단하게 마지막 time step에서의 RUL 값을 예측하는 것으로 문제를 설정한다.
3. Methodology
3.1 Degradation trend encoder
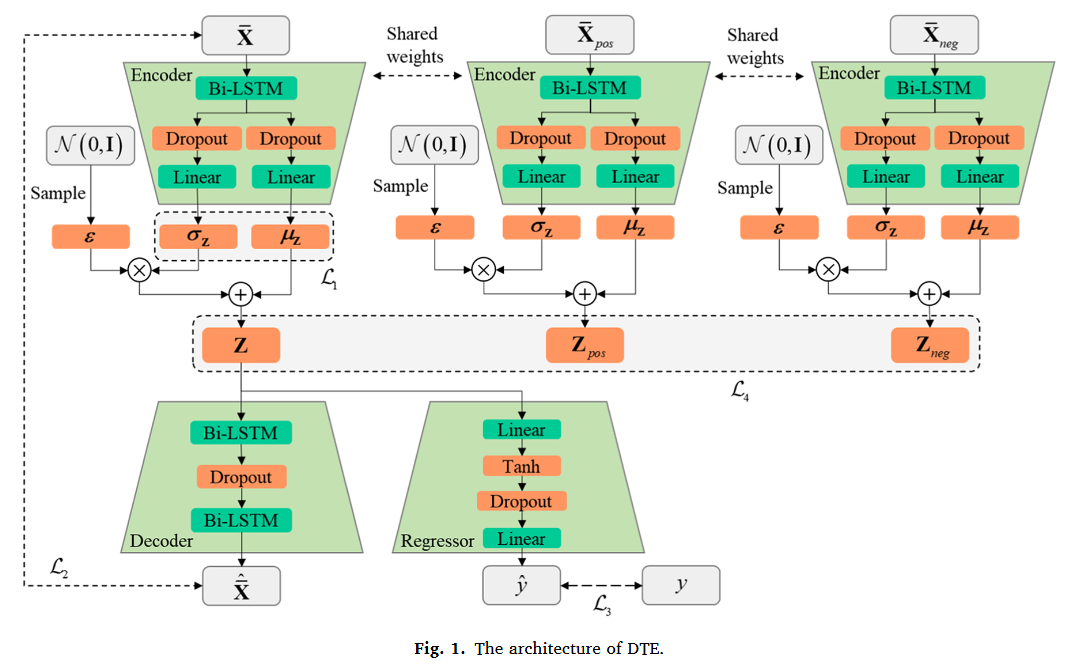
시스템 모니터링 데이터에서의 열화 트렌드 표현을 효과적으로 포착하기 위해 DTE를 도입했는데, 이는 VAE를 기반으로 하고 있다. DTE의 핵심 아이디어는 모니터링 데이터를 저차원의 잠재 변수 로 압축하는 것이다. 해당 구조는 위 Fig. 1에서 볼 수 있듯 Decoder, Regressor, 3개의 Encoder로 구성되어 있으며 각각을 가중치를 공유한다. 모델 최적화를 위해 총 4개의 손실함수가 사용되었다. 먼저 시스템 모니터링 데이터의 실제 분포를 parametric 분포와 fitting 시킨다.
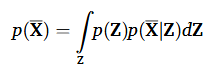
위 과정은 VAE에서 가우시안 분포로 fitting 하는 그 과정이다. MLE 방법을 사용하여 아래 가능도 함수를 최대화한다.
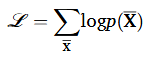
다음으로 새로운 분포를 도입해서 잠재변수의 분포를 알려진 시스템 모니터링 데이터를 사용해서 표현하는 과정은 아래와 같다.
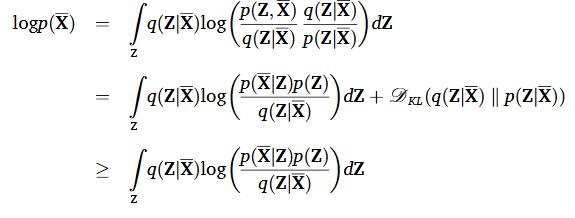
그 후 위 함수의 evidence lower bound를 아래와 같이 설정한다.
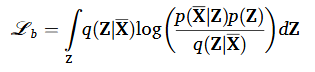
그럼 다음과 같이 다시 표현할 수 있다.
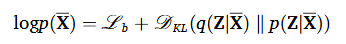
이렇게 한다면 최적 목표함수는 & 찾아서 아래 수식을 최대화하는 과정으로 바꿀 수 있다.
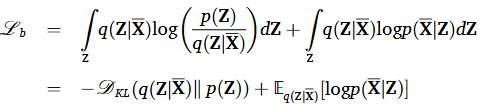
는 DTE의 Encoder로 는 Decoder로 모델링이 되는 것이다.
인코더는 입력데이터를 받아 잠재 공간에 매핑한다. 이 때 입력에 대해 평균과 분산을 산출하게 되고 이들은 잠재 공간상에 확률 분포의 파라미터들이다. Bi-LSTM 이 시계열 데이터 처리에 적합하기 때문에 이를 Encoder 구성에 활용하였다.
Bi-LSTM의 출력 값은 두 개의 분리되 FC-layer를 거치게 되고 각각 사전 분포의 평균과 분산을 추정하게 된다. 분포로부터 직접적으로 잠재 변수를 샘플링하면 randomness와 non-differentiability에 의해서 역전파를 어렵게 한다는 단점을 막고자 reparametrization trick을 사용해서 샘플링 과정을 규정한 것이다. 해당 방법은 표준정규분포로 부터 을 샘플링하고 이를 추정된 평균과 분산을 활용하여 잠재변수를 생성하는 방식이다.
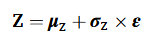
Decoder에 있어서도 Bi-LSTM을 사용했고 DTE의 두 개의 손실함수를 규정했다.
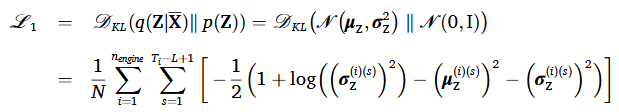
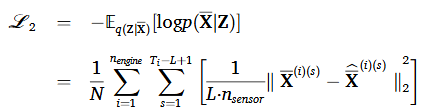
첫 번째 손실함수는 regularization loss로 Encoder로부터 학습된 잠재 변수 분포가 사전 분포에 가깝도록 align하여 과적합을 방지한다. 두 번째 손실함수는 reconstruction loss로 Decoder의 출력값이 실제 입력 데이터와 유사하도록 매칭하여 데이터 무결성을 보존하였다. 두 손실함수들은 DTE가 잠재 공간 상의 유용한 표현들을 학습하여 입력 데이터의 주요 특징을 표현할 수 있도록한다.
잠재 표현이 시스템 모니터링 데이터의 열화 패턴을 포함할 수 있도록 하기 위해, 시스템의 RUL을 예측하는 Regressor를 통합하였다. 잠재 변수 를 사용하여 RUL을 예측하고 이에 따른 손실함수를 추가하였다.
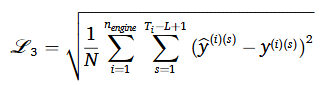
Regressor의 구조는 직관적인데, FC-layer와 Tanh 활성화 함수 한 층으로만 구성되어 있다. 위 세 번째 손실함수는 DTE에 추가적인 제약을 부과하는 역할로 모델이 잠재 공간 상에서 입력 데이터의 표현을 학습할 뿐만 아니라 변화하는 RUL 값을 정확하게 구별할 수 있도록 한다.
더 나아가 잠재 공간상의 변화하는 열화 트렌드에 대한 표현의 구별성을 향상시키기 위해 대조학습을 통합했다. 주요 아이디어는 잠재 공간상에서 비슷한 열화 트렌드를 지닌 데이터끼리 공간적으로 가깝게 align 하겠다는 것이며 다른 트렌드를 지녔으면 멀게 만들겠다는 것이다. 이렇게 하면 모델이 다양한 열화 트렌드 사이에서 잘 구분할 수 있는 능력이 강화된다는 것이다.
대조학습에서 가장 중요한 파트는 positive negative 샘플을 만드는 것이다. 본 연구에서는 RUL 값을 기준으로 positive pair와 negative pair를 나눠서 사용했다. 추가적으로 두 개의 Encoder를 사용해서 positive & negative 샘플을 잠재 공간 상에 매핑했다. 대조 학습을 위해 triplet 손실함수를 아래와 같이 사용했다.
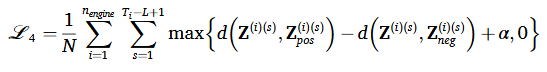
해당 최적 목표함수는 anchor sample의 표현과 positive sample의 표현을 잠재 공간상에서 거리를 가깝게 하고 반대로 negative sample의 표현과는 멀게 한다. 함수를 보면 를 마진으로 추가하는 것을 볼 수 있는데 이는 덜 비슷한 샘플은 해당 마진 만큼은 떨어뜨려놓는 역할로 샘플 표현간의 분별력을 향상시키는 효과가 있다. 또한 양의 쌍과 음의 쌍 간의 최소 거리로 훈련 데이터를 완벽하게 구별하는 것을 방지하여 일반화 성능을 높이는 효과도 존재한다. 이러한 접근 방법을 통해 잠재 공간이 비슷한 열화 트렌드 군집은 가깝게 아닌 군집은 멀게 학습하게 한다.
그래서 드디어 최종적으로 앞서 설명한 네 개의 손실함수를 합치면 다음과 같은 최종 손실함수가 구성된다.
3.2 DiffRUL framework
DiffRUL은 두개의 메인 파트로 나뉘는데 forward diffusion 과정과 reverse generation 과정이다. 기존의 디퓨전 모델을 차용하고 있기 때문에 유사하게 전처리된 시스템 모니터링 데이터는 이에 따른 분포는 로 표현한다.
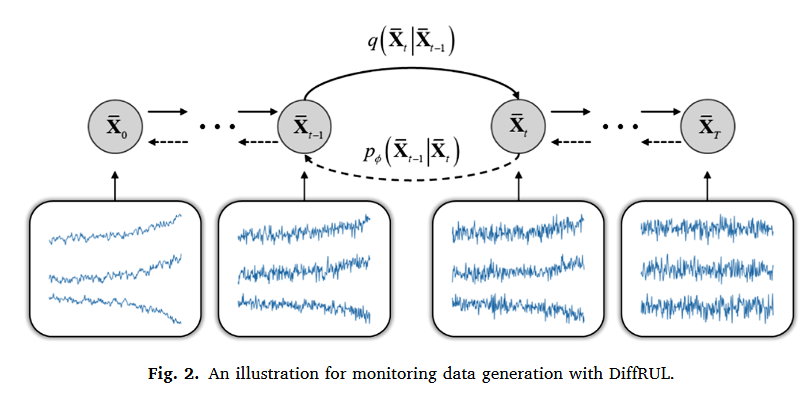
3.2.1. Forward diffusion process
forward 디퓨전 과정은 T time step의 반복적인 마코브 체인으로 구성되어 있다. 조절 가능한 양의 가우시안 노이즈를 반복적으로 도입한다. 해당 과정은 다음과 같이 표현 가능하고 여기서 가 가우시안 노이즈의 분산 즉 강도를 의미한다.
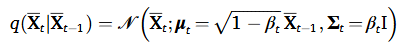
위 조건부 확률 분포도 여전히 가우시안 분포이기 때문에 평균과 분산을 정의할 수 있고 이는 를 사용해서 계산 가능하다. 여기서 는 variance schedule로 조절 가능한 하이퍼파라미터이다. 저자는 linear schedule를 채택해서 선형적으로 증가하게 하였다. T 스텝이 지난 후에는 간단한 가우시안 분포로 변화하게 되고 이를 수식적으로 나타내면 다음과 같다.
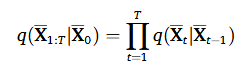
이렇게만 표현하면 확률 변수의 미분을 못하는 문제로 인해 파라미터 업데이트를 위한 역전파를 방해한다. 따라서 reparametrization trick을 사용한다. 이는 확률 변수를 deterministic한 변수 함수로 변형하여 확률 변수와 모델 파라미터 간의 관계를 반영하여 미분 가능하도록 만든다. 라고 했을 때 아래와 같이 표현 가능하다.
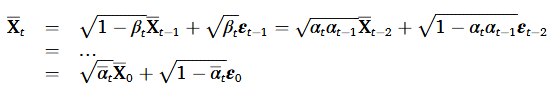
그 결과 t 시점에서의 데이터의 분포는 다음과 같이 도출된다.
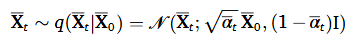
3.2.2. Reverse generation process
T 스텝 동안 diffusion 과정을 완료하였고, T가 충분히 크다면 는 간단한 가우시안 분포가 되어있을 것이다. 그러므로 를 얻기 위해서는 간단한 가우시안 분포로부터 샘플링해서 로 복원하는 과정을 거치면 될 것이다. 이 때 복원하는 과정을 통해 새로운 데이터 포인트를 생성할 수 있게 된다.
하지만 직접적으로 를 계산하는 것은 어렵기 때문에 parameterized neural network 를 사용해서 근사하게 된다. 는 forward 과정에서의 가우시안 분포 형태를 공유하기 때문에 해야할 것은 평균과 분산을 아래와 같이 근사해서 paramerize하는 것이다.
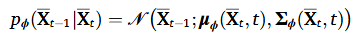
reverse generation 과정을 최종적으로 아래와 같이 표현된다.
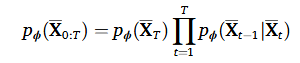
3.2.3. Training and sampling
학습과 샘플링 과정은 일반적인 디퓨전 방법을 채택하기 때문에 수식적으로 복잡해보이지만 동일한 방법을 설명하고 있다. 따라서 해당 정리에서는 생략하도록 하겠다.
3.3 Detailed designs for DiffRUL
3.3.1. Denoising network
다변량 모니터링 데이터의 복잡한 spatio-temporal 상관관계를 효과적으로 포착하고 각 스텝에서 노이즈 정도를 정확하게 예측하기 위해, denoising network 구조를 정교하게 디자인해서 DiffNet을 개발하였다. 해당 네트워크는 inverted bottleneck 구조와 유사한 구성을 채택하고 아래 Fig. 3.과 같다.
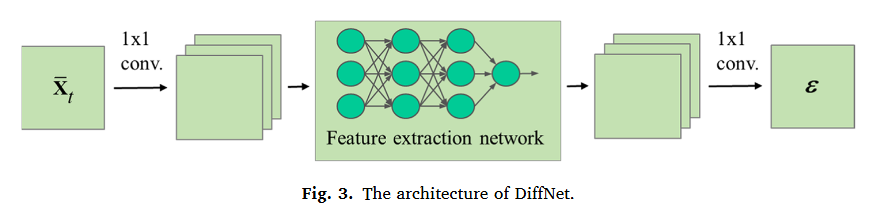
먼저 1x1 컨볼루션 층을 통해 입력 데이터의 채널 수를 확장한다. 다음으로 표현 추출 네트워크를 통해 고차원 공간에서의 spatio-temporal 상관관계를 포착하고 최종적으로 다시 다른 1x1 컨볼루션 층을 거쳐서 채널 수를 압축한다. 해당 전략의 장점은 입력 데이터의 채널 수를 늘림으로서 다양하고 복잡한 특징들을 효과적으로 포착하고 학습할 수 있다는 것이다. 각 채널이 입력 데이터의 서로 다른 패턴과 관점에 집중하도록 해서 특징 셋을 더욱 풍부하게 만들어 준다.
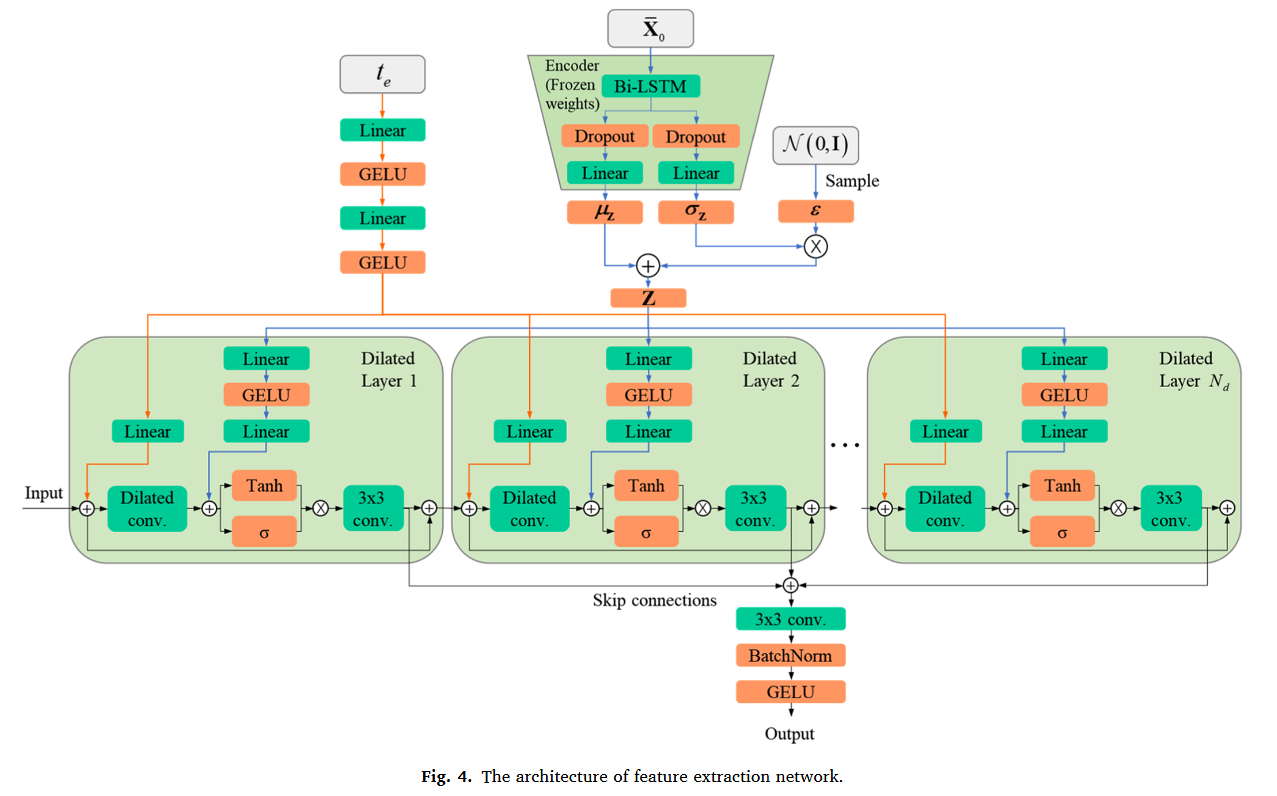
특징 추출 네트워크의 기능은 다변량 시스템 모니터링 데이터를 고차원 공간에서 불변하는 spatio-temporal 상관관계를 인식하도록 하는 것이다. 해당 네트워크의 구조는 stacked dilated convolution을 채택했다. 아래 Fig. 4. 의 구조를 보면 이해가 쉽기 때문에 자세한 설명은 생략하겠다.
3.3.2. Guided generation
DiffRUL로부터 생성된 데이터 샘플들의 열화 트렌트 표현의 정확도를 향상시키기위해, unconditional DiffRUL를 Conditional DiffRUL로 확장한다. 해당 확장은 DTE로부터의 열화 트렌드 표현을 DiffRUL의 reverse 과정 중에 생성 조건으로 통합하는 것이다. 해당 과정은 아래와 같이 표현된다.
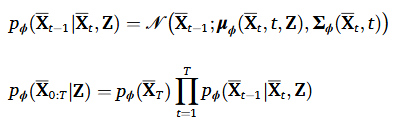
이에 따라 학습을 위한 손실함수도 다음과 같이 개정된다.
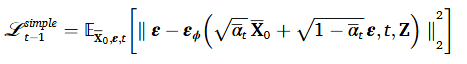
데이터 샘플링 과정 또한 다음과 같이 조절된다.
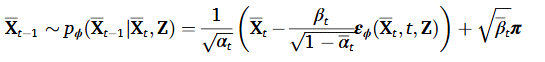
일련의 과정은 아래의 Algorithm 1으로 대체하겠다.

4. Experiments
4.1 Data description
1) C-MAPSS dataset
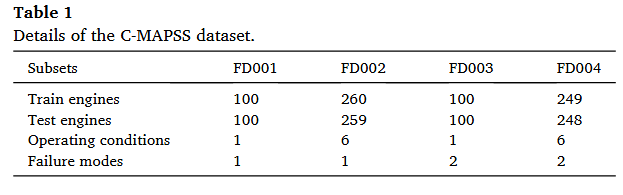
2) N-CMAPSS dataset
4.2 Evaluation metrics
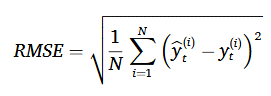
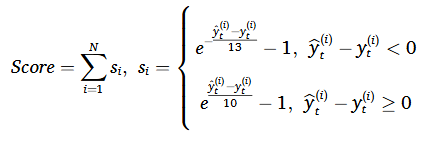
Score의 경우 조기 예측보다 늦은 예측에 더 큰 패널티를 부과하는 함수이다.
4.3 Implementation details
앞서 손실함수를 규정할 때 가중치로 사용했던 하이퍼파라미터 등이 나열되어있다. 실험을 진행할 사람들은 참고해서 진행하면 될 것이다. 이 밖에도 대조학습을 위해 필요했던 RUL threshold 등이 제시되어있다.
4.4 Experiment results on the C-MAPSS dataset
4.4.1. Results of the generated data
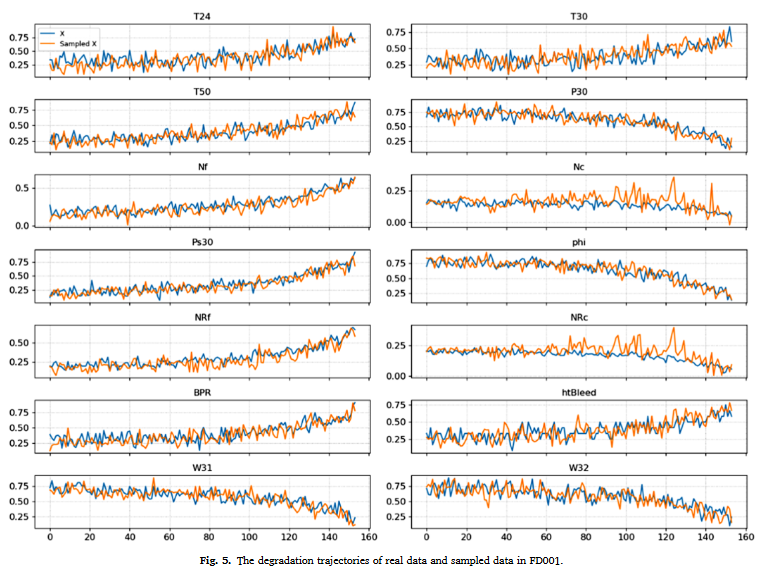
생성을 진행한 뒤 랜덤하게 하나를 샘플링한 결과는 위와 같다. 실제 데이터를 상당히 잘 근사하고 있음을 알 수 있다.
4.4.2. Results of RUL prediction
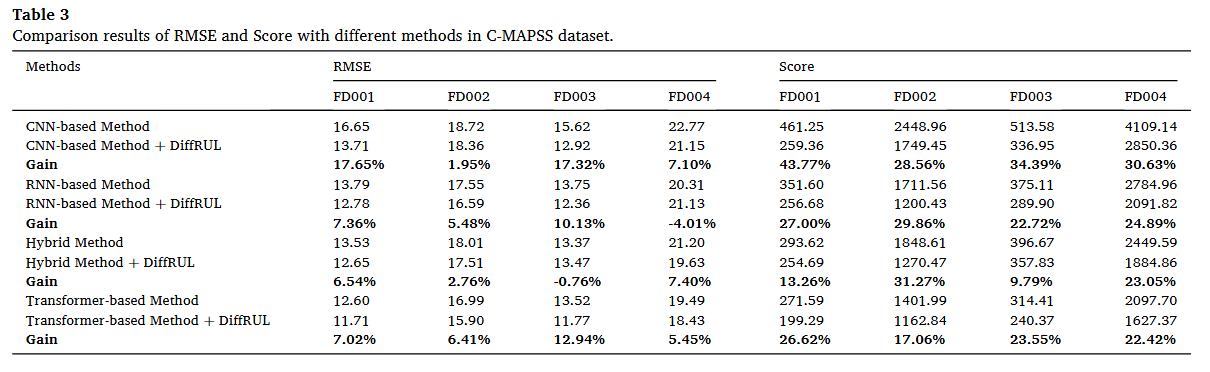
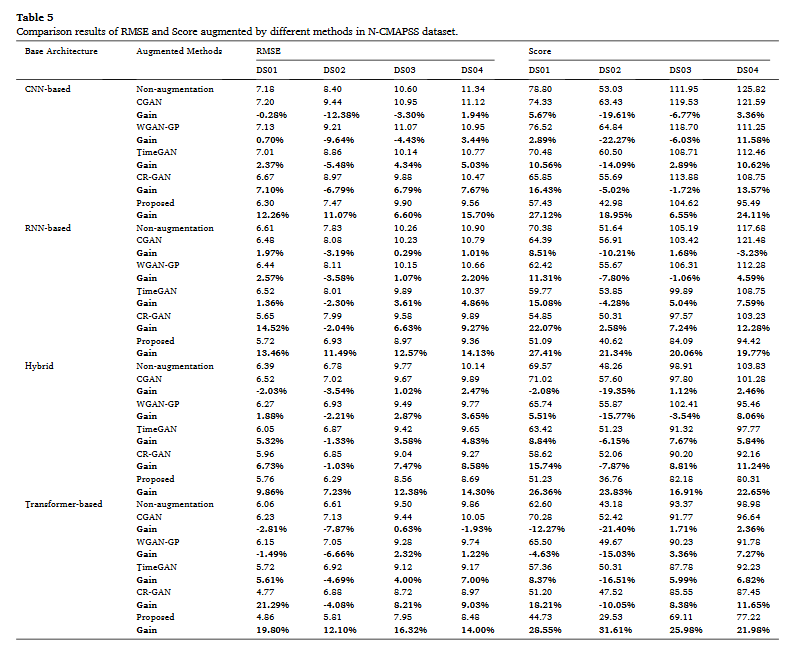
기존의 CNN 기반 방법론, RNN 기반 방법론, Hybrid 방법론, Transformer 기반 방법론들에 DiffRUL을 추가했을 때의 성능 향상을 나타내는 표는 위와 같다. 다양한 방법들에 대해 추가했을 때의 성능 향상이 유의미했으며 이는 그래프로 표현이 되어있는데 너무 많은 그래프를 추가하는 것은 힘들기 때문에 논문을 참고하자
4.4.3. Comparison with existing methods
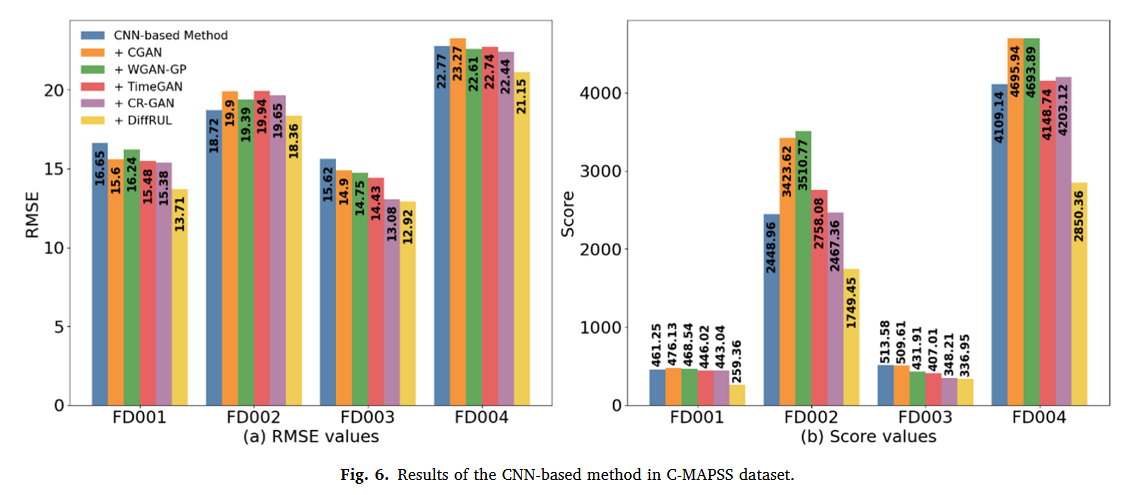
위와 같은 그래프로 기존 방법에 다양한 생성모델들로 생성한 데이터를 추가했을 시의 성능 향상의 폭을 비교해놨다.
Fig. 6. ~ Fig. 11.을 참고하자
4.4.4. Ablation experiments
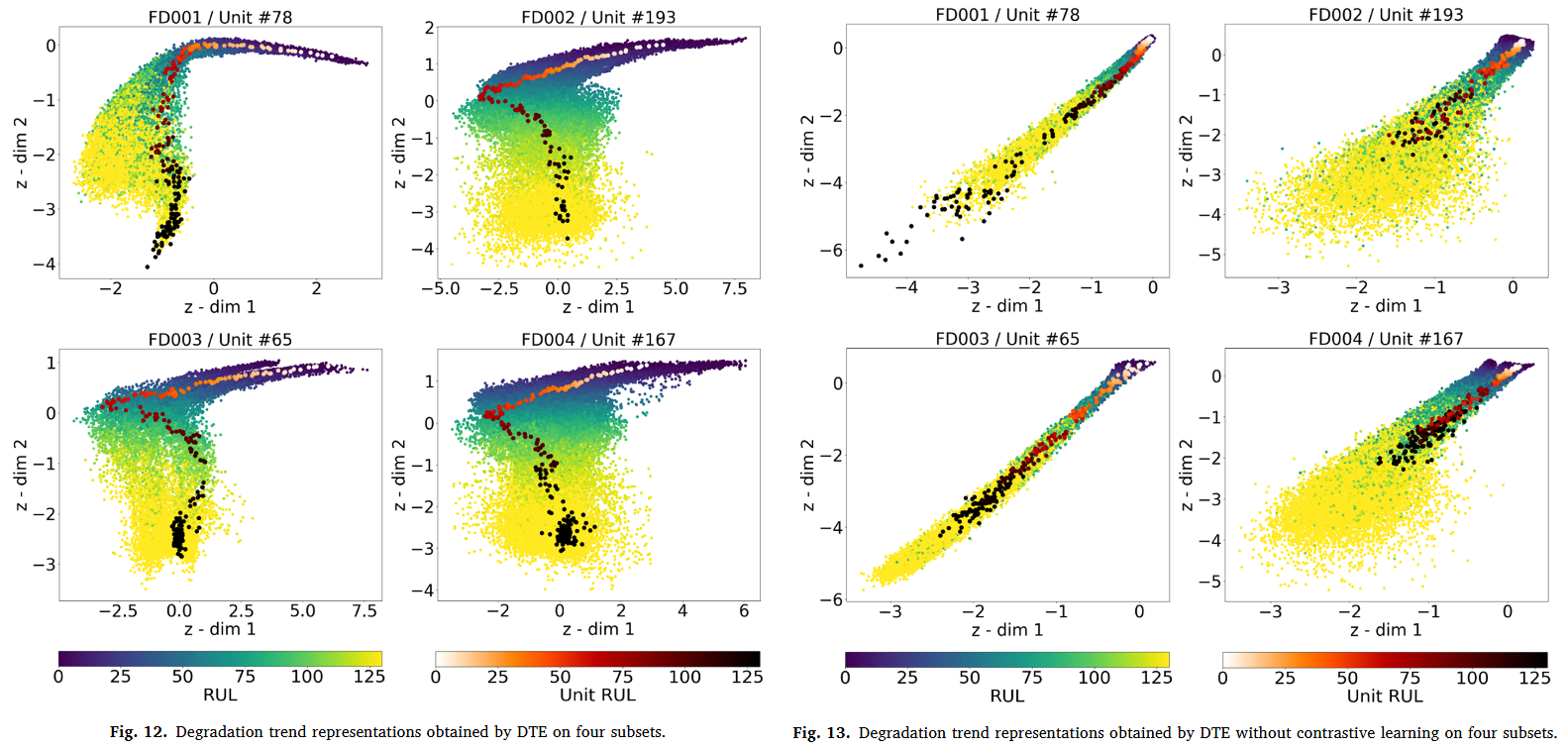
대조학습을 사용했을 때와 사용하지 않았을 때의 차이를 위 그림으로 나타냈다. 위 그림은 열화 트렌드 표현을 DTE를 통해서 추출했을 때인데 대조학습을 사용했을 때는 분별력이 향상된 것을 볼 수 있으며 열화 트렌드 군집이 잠재 공간 상에서 더욱 가깝게 군집되어있는 것을 볼 수 있다. 특히 대조학습을 사용하지 않았을 시에는 실제 RUL이 작을 때는 어느 정도 모여있는 것을 알 수 있으나 RUL이 큰 즉 정상 운영 상태에 가까울 때는 잘 모여있지 않은 것을 알 수 있다.
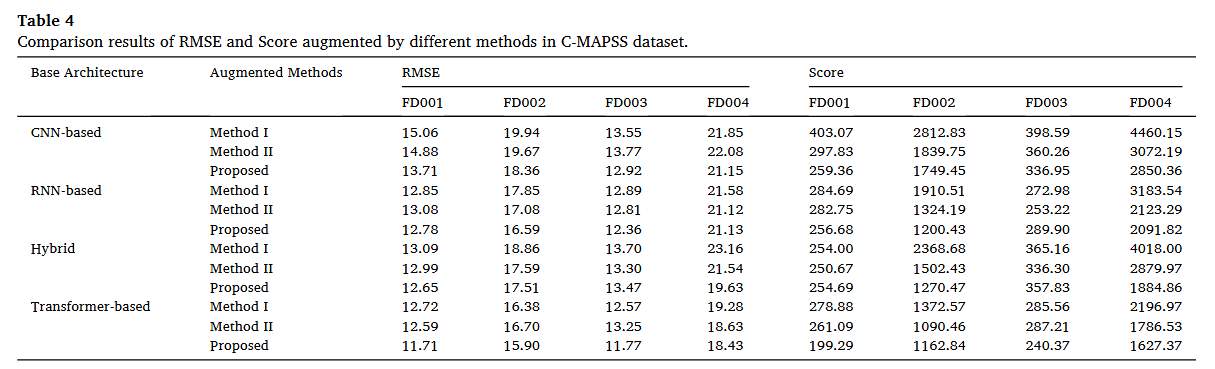
또한 위 Table 4.와 같은 Ablatation study도 진행했는데 Method 1이 실제 RUL 값을 generative condition으로 사용한 DiffRUL이며 Method 2는 triplet loss 함수의 coefficient를 0으로 설정했을 때이다. 이 둘에 비해 제안하는 방법의 RMSE 값이 더욱 낮음을 확인할 수 있다.
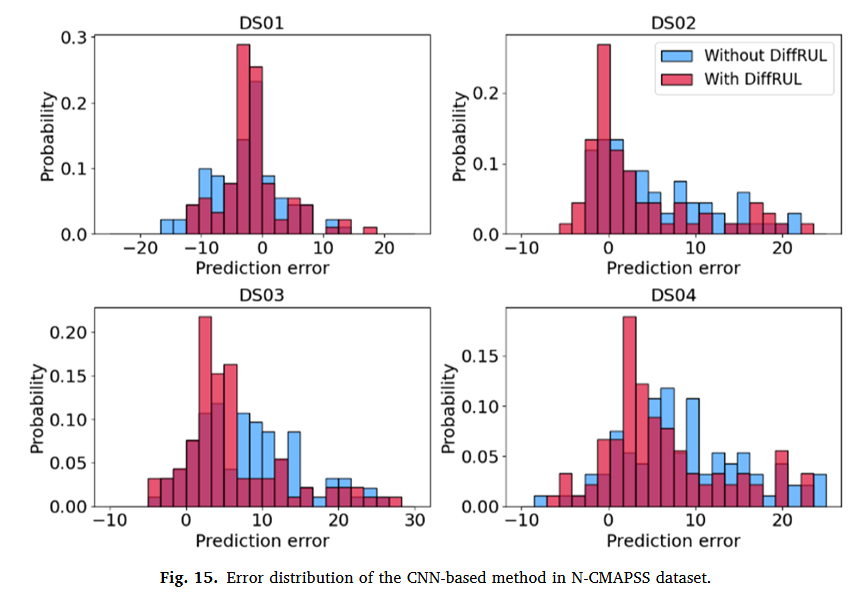
4.5 Experiment results on the N-CMAPSS dataset
C-MAPSS와 유사하기 때문에 주요 Table과 그래프만 나열하게 스킵하겠다.
5. Conclusions
본 논문는 DiffRUL 모델을 제안하여 다변량 엔진 모니터링 데이터를 디퓨전 모델을 통해 증강하였다. 해당 접근법은 실제 모니터링 데이터의 품질과 열화 궤적을 모방하는 샘플 생성 능력을 향상시켰다. 초기에는 DTE를 사용하여 운영부터 고장까지의 열화 과정에 대한 분별력 있는 표현을 추출하였고, 해당 표현들은 복잡한 데이터 패턴을 인식하는 모델의 성능을 향상시켰다. 추가로 다변량 시스템 모니터링을 위해 채택된 디퓨전 모델은 데이터에 내재된 분포에 대한 정확한 포착을 통해 복잡한 생성 과정을 가능하게 하였다. 추가로 DiffNet을 만들어서 생성 조건으로 통합하여 복잡한 spatio-temporal 상관관계를 포착하여 생성 품질을 향상시켰다.
Future work로 두 가지를 제안하였다. 첫번째로, 디퓨전 과정의 너무 느린 학습 과정, 두번째로 오래된 시스템이 예정된 유지보수 전에 자주 교체되는 실제 시나리오에서 흔한 문제인 불완전한 시스템 모니터링 데이터를 증강하는 것에 초점을 맞추는 것이다.
