[논문 리뷰] Fully Convolutional Cross-Scale-Flows for Image-based Defect Detection
2023 하계 Paper Review

본 Paper Review는 고려대학교 스마트생산시스템 연구실 2023년 하계 논문 세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다.
Abstract
- 산업 제조 현장에서, 결함은 예상치 못하게 일어나서 데이터를 얻기 힘듦
- 최근 연구들은 defective parts 없이 정상 이미지의 분포를 모델링하는 방식을 택함
- 기존 연구와는 다르게 본 연구는 밀도를 flexible하게 추정하면서 이미지의 global & local context를 통합할 수 있는 fine-grained 표현을 다룸
- CS-Flow라는 이름의 모델을 제안하였고 서로 다른 스케일의 multiple feature map을 처리함
- 해당 모델은 Normalizing flow를 사용해서 image-level defect detection을 수행하였고, interpretable하다는 장점이 있음
- MVTec AD와 MTD에서 SOTA 성능을 달성함
1. Introduction
Defect은 safety와 product quality 측면에서 반드시 탐지되어야 하는 부분이다.
수동으로 탐지하는 방법은 costly하며 error-prone하다.
문제는 defect에 대한 예시가 적으며, 있다할지언정 새로운 defect이 발생했을 시에
기존에 학습했던 분류 모델이 제대로 작동하지 못한다.
따라서 정상 이미지만을 사용해서 defect을 탐지하는 semi-supervised anomaly detection 혹은 one-class classification 방법론들이 연구되고 있다.
해당 방법은 정상 데이터의 분포를 찾아서 해당 분포에 속할 likelihood가 낮은 데이터를
결함으로 탐지하는 방법이다.
이러한 과정은 out-of-distribution (OOD) detection 이라고도 한다.
저자는 feature level에서 분포를 모델링하는 방법에 Normalizing flow를 접목하였다.
대부분의 AD 이미지 데이터셋은 High intra-class & High inter-class-variance를 띈다.
하지만 Defect detection은 Small intra-class & Small inter-class-variance를 띈다.
즉 클래스끼리도 유사하게 생겼으며, 정상과 이상도 유사하게 생겼다.
따라서 Autoencoder나 GAN 기반 방법들은 적합하지 않다.
그래서 최근 연구들은 density estimation 방법을 선택한다.
이는 Pretrained 된 모델로부터 학습한 image feature를 사용하게 된다.
그러나 해당 방법들은 averaging of feature maps 혹은 strong statistical prior 때문에
정보들을 잃을 위험이 있다.
이러한 위험을 극복하기 위해서 Normalizing Flow (NF)를 사용한다.
NF는 predefined distribution을 사용해서 training set 분포를 latent space로 변환하는 생성모델이다.
VAE나 GAN과 다르게 latent space vectors의 likelihood가 곧바로 input data의 likelihood로 해석될 수 있다는 장점이 있다.
기존에는 NF를 이미지 OOD detection에 사용하는 데에는 한계가 있었다.
Local pixel correlations에만 집중한 나머지 semantic 정보를 포착하지 못해서 분포를 학습하지 못했기 때문.
저자는 CS-Flow를 통해 compressed semantic 정보를 제공할 수 있도록 했다.
해당 방법은 이미지 feature를 처리할 때 서로 다른 scale로 나눠서 서로 interacting 할 수 있도록 처리하는 방식을 사용했다.
이렇게 함으로써 defective 예시를 정확하게 식별할 수 있는 분포를 local과 global context간의 correlations을 파악하여 구성할 수 있도록 했다.
본 연구의 Contribution은 다음과 같다.
(1) CS-Flow는 다양한 스케일의 feature maps에 대한 likelihoods를 추적하여 defect을 탐지한다.
(2) 정확한 defect detection을 가능하게 하는 설명 가능한 latent space를 얻기 위한 이미지 구조를 유지하도록 한다.
(3) MVTec AD와 MTD 데이터셋에서 SOTA를 달성했다.
2. Related Work
Methods Based on Pretrained Networks
기존에도 Pretrained Network로부터 학습된 Feature를 Target 데이터와 Matching하는 방식의 Anomaly detection 방법들이 존재했고, 이들은 대부분 Mahalanobis 거리를 사용했다.
하지만 해당 방식의 문제점은 정규성을 가정하고 있다는 점이다.
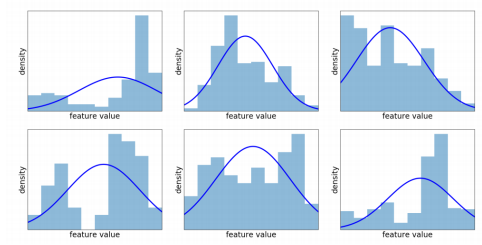
MVTec AD의 클래스들만 봐도 정규성을 만족하지 않음을 알 수 있다.
3. Method
이미지에서 defect을 탐지하기 위해, DifferNet과 유사하게 통계 모델을 학습하게 된다.
추론 시에, Image feature 에 대한 Input image 의 density estimation을 통해 likelihood를 할당하고,
낮은 likelihood가 defect에 대한 정보가 된다.
Density estimation은 feature space 의 알려지지 않은 분포 를 latent space 의 Gaussian 분포 로 bijective mapping을 통해 학습된다.
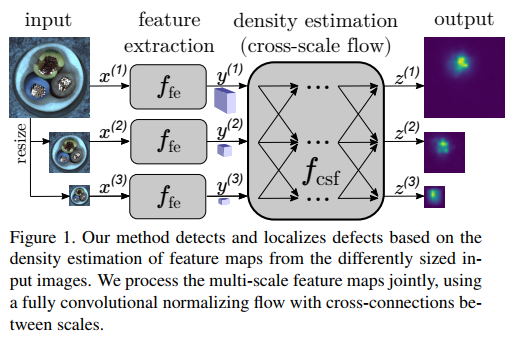
따라서 위 Figure 1에서 볼 수 있듯, feature extraction부분과 density estimation 부분으로 나눌 수 있다.
는 pretrained neural network로 input image 를 feature 로 바꿔주는 함수이다.
Figure 1에서 볼 수 있듯 여러 scale로 resize한 뒤 각각의 feature extraction을 거친다.
Concatenated feature vectors로 만들지 않고 각각 feature extraction을 거친 이유는,
이렇게 함으로써 중요한 fine-grained positional and contextual 정보가 유지되기 때문이다.
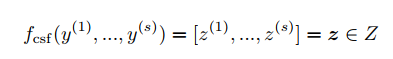
위 함수는 feature tensors를 bijectively하게 변환하는 함수이다.
이를 통해 likelihood 를 구할 수 있게 되며 이를 threshold 와 비교하여 이상을 탐지하게 된다.
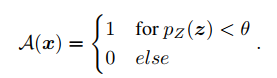
3.1 Cross-Scale Flow
저자는 해당 파트에서 Normalizing Flow 내부 함수를 2d Convolution으로 구성하여 spatial dimensions을 보존했다. 이를 보존했을 때 얻을 수 있는 장점은 anomalies의 위치를 특정지을 수 있다는 점이다.
추가로 training samples를 적게 가져가도 된다는 점이다.
Cross-scale flow는 coupling blocks의 chain으로 되어있는데 이는 Real-NVP에서 차용한 것이다.
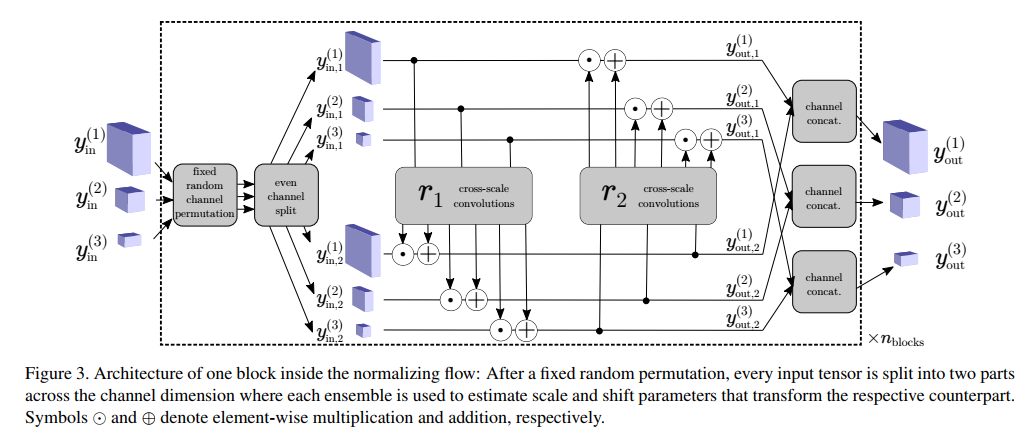
CS-Flow의 Flow 부분 동작 구성을 위와 같다. Figure 중간 즈음에 과 함수를 통해 Multi-scale feature가 Fusion되는 모습을 볼 수 있다.
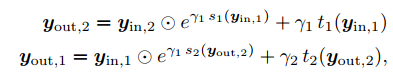
해당 수식은 위와 같다.
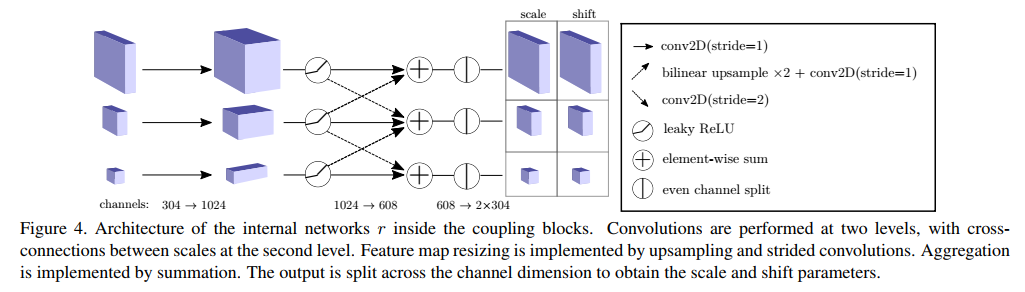
함수들의 구조는 위 그림과 같다. 전부 Convolution block으로 구성된 것을 알 수 있다.
활성화 함수는 leaky ReLU를 사용하였다.
3.2 Learning Objective
학습 시에, cross-scale flow 가 feature tensors 의 likelihood를 최대화하는 방향으로 학습하고자 한다.
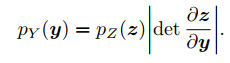
Likelihood는 위 수식과 같이 정의할 수 있다.
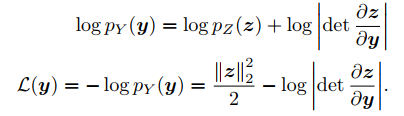
최종적인 Loss function은 위와 같이 설정되었다.
이를 통해 일반적인 Normalzing Flow와 유사하게 를 최대화하는 방향으로 학습한다.
3.3 Localization
앞서 언급했든, feature maps들이 fully-convolutional block을 통해 연산되었기 때문에 positional 정보가 보존되었다.
따라서 각 이미지 region의 likelihood의 관점에서 output의 interpretation이 가능해졌다.
4. Experiments
4.1 Datasets
MVTecAD
10개의 object와 5개의 texture classes로 구성되어 있다.
3629개의 정상 training dataset과 1725개의 섞여있는 testing 이미지로 구성되어 있다.
각 class는 700x700 에서 1024x1024까지 이를 정도로 고화질로 구성되어 있다.
MTD
grayscale 이미지이며 392장의 defect 이미지와 952장의 defect-free image로 구성되어 있다.
4.3 Detection
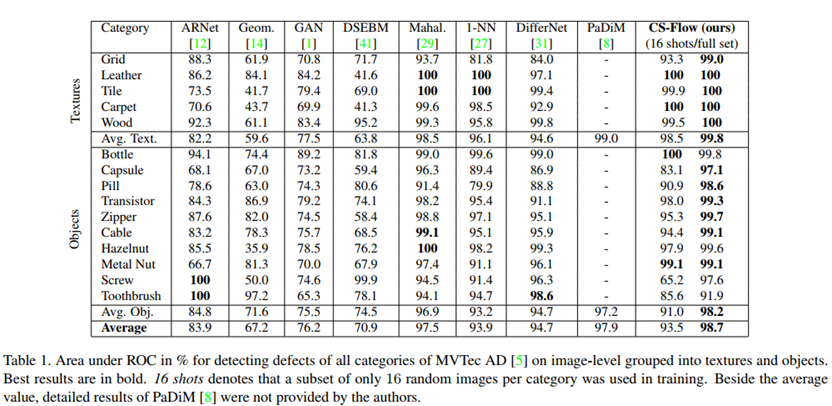
MVTec AD 데이터셋 성능.
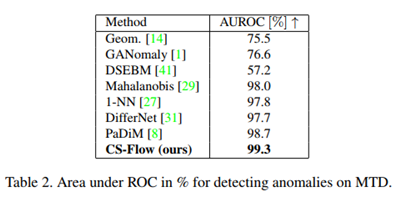
MTD 데이터셋 성능.
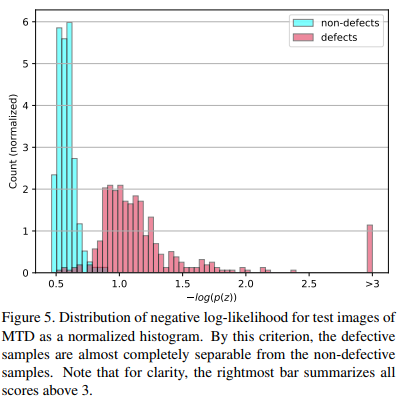
Likelihood가 꽤나 명확하게 나뉘는 것을 볼 수 있다.
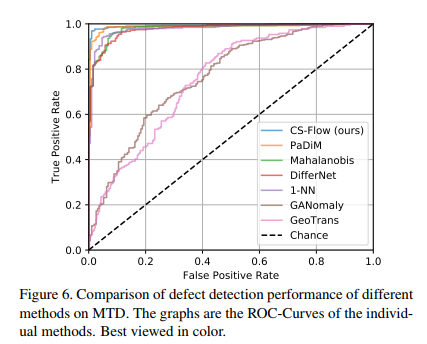
다른 모델들과의 AUROC 비교했을 시에도, 제안하는 방법이 제일 좋다.
4.4 Localization

앞서 언급했듯, CS-Flow는 Localization도 가능하여 해석력을 부여해줄 수 있다.
4.5 Ablation Studies
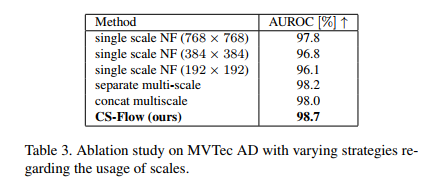
제안하는 다양한 스케일을 모두 사용한 방식의 성능이 가장 높다.
다양한 multi-scale 방식 중에서도 CS-Flow 방식이 성능이 높다.
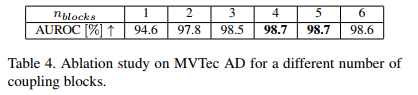
Coupling block의 개수에 따른 성능도 정리가 되어있다.
5. Conclusion
본 연구는 서로 다른 scale의 feature tensors에 Normalizing flow를 접목하여 defect을 효과적으로 탐지 및 localize하는 Semi-supervised 방법론을 제안한다.
Cross-convolution block을 사용해서 multi-scale feature map간의 context를 학습하고 이를 통해 likelihood를 할당해서 defect을 탐지했다.
MVTec AD와 MTD를 통해 SOTA 성능을 검증했다.
Future work는 Video에 적용해보는 것이다.
