
본 Paper Review는 고려대학교 스마트생산시스템 연구실 2024년 동계 논문 세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다.
Abstract
- Masked Autoencoders (MAE)를 사용하여 비디오로부터 공간-시간적 표현을 학습
- 제안하는 MAE 방법은 공간, 시간에 대한 inductive bias가 거의 없음
- 공간, 시간에 대한 정보 없이 랜덤 마스킹해도 성능이 좋으며, 마스킹 비율은 90% 정도로 높아도 괜찮음
- 정보 중복이 있기 때문에 높은 비율로 마스킹해도 괜찮으며, 이는 빠른 연산 속도로 이어짐
1. Introduction
딥러닝 방법론들은 다양한 방법론들을 통합하는 것이 현재 추세이다.
특히 자기지도 표현학습 분야에서는 denoising/masked autoencoding 방법론을 통합하는 것이 대세이다.
해당 접근법은 시간 표현을 추출하는데 효과적이며, 더 적은 도메인 지식과 더 적은 inductive bias를 보장할 수 있다.
이러한 상황에서 본 연구는 MAE를 확장시켜서 공간-시간 표현학습 문제에 적용하고자 한다.
방법론은 상당히 간단한데, 아래 그림과 같이 비디오에서의 공간, 시간 패치를 임의로 마스킹하고 이를 복원하는 Autoencoder를 학습하는 것이다.
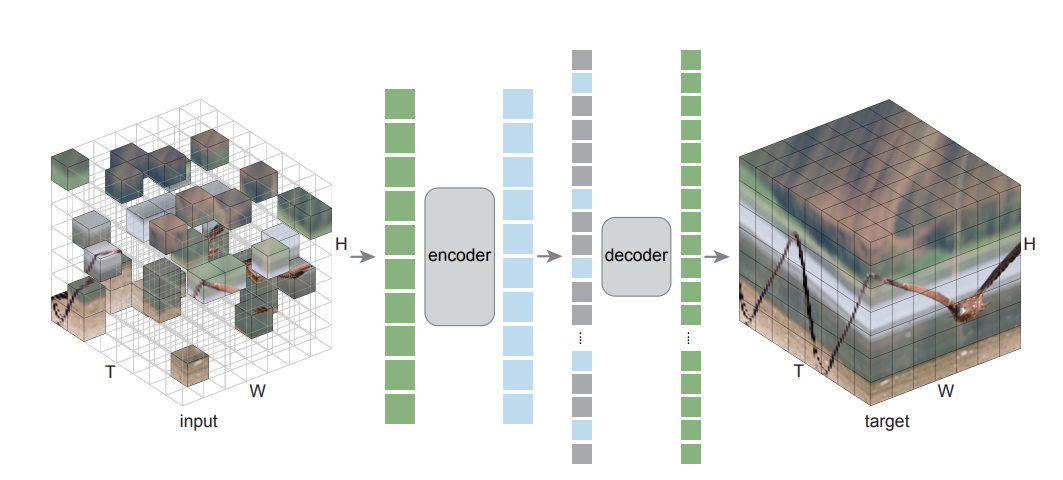
해당 방법은 공간, 시간에 특화된 inductive bias만 패치에 존재하도록 하기에 최소한의 도메인 지식을 가지고 있다.
저자는 기본 ViT에 어떠한 factorization 혹은 hierarchy를 사용하지 않고, 랜덤 마스킹 또한 공간, 시간 구조에 무관하도록 해도 재복원하는데 있어서 우수하다고 주장한다.
즉, 공간-시간 패치에 간단하게 MAE를 적용하는게 본 논문의 핵심이며 이는 유용한 정보는 전부 데이터로부터 학습할 수 있다는 것이다.
마스킹 비율이 데이터의 정보 중복에 비례하게 설정되어야 한다.
예를 들어 자연 이미지가 자연어에 비해 정보 중복이 더 많기에 최적 마스킹 비율도 더 높다.
저자는 이미지에서 최적 마스킹 비율이 75% 정도라면 비디오에서의 최적 마스킹 비율은 90%임을 밝혀냈다.

비디오가 이미지보다 정보 중복이 많은 이유는 이미지의 순서, 즉 시간 정보도 담고 있기 때문이다.
그리고 빠른 장면 전환보다, 느린 장면 전환일 때 더욱 높은 마스킹 비율을 설정해도 괜찮다.
더 높은 마스킹 비율은 훨씬 효율적이다.
90%의 마스킹 비율은 인코딩 시간을 줄이고 메모리 복잡도도 낮출 수 있다.
2. Related Work
Denoising autoencoders
마스킹을 노이즈의 일종이라고 생각한다면 MAE는 DAE의 부분집합이라고 볼 수 있다.
그리고 가장 성공한 예시가 BERT 모델이다.
Denoising/masked autoencoding 방법이 지속적인 발전을 이루고 있는 이유는 최근들어 비전과 자연어에서의 방법론들이 융합되는 추세이며 Transformer 기반 방법론들이 비전에 성공적으로 안착했기 때문이다.
iGPT는 픽셀을 토큰으로, ViT는 패치를 토큰으로 하여 Transformer 방법론을 적용하게 된다.
MAE는 Autoencoding 개념의 기초로 다시 돌아와 디코딩 부분에 상당히 많은 영향을 준다.
픽셀 자체를 예측하는 방법 대신 예측 타겟의 tokenization에 집중하는 방법들도 있으며, BEiT, dVAE, MaskFeat이 대표적이다.
Self-supervised learning on videos
비디오 데이터에서의 자기지도 학습이 주목하는 것은 시간 차원의 존재이다.
이와 관련된 토픽은 temporal coherence, future prediction, object motion, temporal ordering, spatiotemporal contrast 등이 있다.
그 중에서 본 연구가 주목한 것은 비디오에서의 temporal coherence이다.
Temporal coherence를 활용할 수 있는 가장 주요한 방법은 높은 마스킹 비율을 가져가는 것이다.
3. Method
Patch embedding
ViT와 유사하게 겹치지 않는 패치를 그리드로 잘라서 Flatten하고 linear projection하는 방법이다. Positional embedding도 추가하여 순서를 부여하는 작업도 동일하다
대신 공간-시간 차원에서 진행되는 것이 차이점이다.
Masking
제안하는 마스킹 방법은 비복원추출 방식이며 spacetime 구조에 agnostic 하다. 아래 그림에서 (a)가 agnostic한 방법이다.

앞서서도 계속 언급했듯, 최적 마스킹 비율은 정보 중복과 관련되어 있다.
기존 모델들을 살펴보면 BERT는 자연어에 있어서 15%, MAE는 이미지에 있어서 75%를 최적 마스킹 비율로 제시한다. 본 연구에서는 비디오에 있어서 90%가 최적 마스킹 비율임을 제시한다.
비디오가 자연어와 이미지 보다 더욱 정보 중복이 크다는 것이 이유이며 Temporal coherence가 주된 이유다.
또한 위 그림 (b)부터 (d)는 structure-aware 샘플링 전략들인데, 이는 structure-agnostic 샘플링 방법에 비해 효율이 떨어진다. 특히 space-only, time-only 샘플링 방법들은 정보량이 너무 적어진다.
예를들어 time-only 샘플링을 8프레임에서 87.5% 비율로 마스킹을 수행한다면 오직 한 프레임만이 남게 된다. 오직 한 프레임을 사용해서 과거와 미래를 예측하는 것은 불가능에 가깝다.
Autoencoding
인코더는 기본 ViT를 사용하며, 오직 마스킹되지 않은 embedded patch만을 사용한다.
해당 디자인은 시간과 메모리 복잡성을 줄이고, 더욱 실용적인 해결책을 가능하게 해준다.
마스킹 비율을 90%로 하기에 인코더 복잡성이 1/10로 줄어든다.
디코더는 또 다른 기본 ViT를 사용하는데 encoded patch 세트와 mask 토큰 세트를 결합하여 사용한다. Decoder-specific한 positional encoding도 추가한다.
디코더는 인코더보다 훨신 작게 설계되기 때문에, 디코더에서 full 세트를 처리해도 인코더보다 복잡성이 낮다.
디코더는 pixel 공간에서 patch를 예측한다. 원칙적으로 전체 spacetime patch를 예측해야하지만, 실제로는 patch의 한 time slice만 예측해도 충분하다.
인코더와 디코더는 spacetime 구조에 agnostic하고, 덕분에 hierarchy 혹은 spacetime factorization이 필요 없다. Global self-attenion에 의존하여 유용한 정보를 학습하게 되는 것이다.
4. Implementation
Data pre-processing
224x224 픽셀 크기의 16개의 프레임을 temporal stride 4로 원본 비디오로부터 샘플링한다. Data augmentation은 random resized cropping과 random horizontal flipping 정도만 적용한다.
MAE는 계산 속도는 빠르긴 한데, 비디오를 처리하다보니 데이터 로딩 작업이 Bottleneck이다.
이를 완화하고자 Repeated sampling을 사용하는데 이는 원본 비디오를 로드하고 압축 해제할 때마다 여러 샘플을 뽑아오는 방법이다.
이렇게 하면 샘플 숫자는 변하지 않지만 샘플 순서만 변하게 된다.
Architecture
모델 구조는 앞서 언급했듯, 기본 ViT 구조를 사용한다.
Temporal patch 크기는 2, Spatial patch 크기는 16x16이다.
인코더에서는 두 개의 positional embedding을 사용하게 되는데, 하나는 space 다른 하나는 time에 관한 것이다. Spacetime positional embedding은 이 둘을 합한 것이다.
이렇게 함으로써 positional embeddings의 크기가 3차원 상에서 너무 커지는 것을 방지할 수 있다.
Settings
최적화 함수는 AdamW를 사용했고, 배치 사이즈는 512를 사용했다.
Multi-view testing 방법으로 추론 과정을 거쳤는데 이는 K개의 temporal clips 각각에 3개의 sptial views가 존재하도록 하고, 최종 예측은 이들의 평균으로 하는 것이다.
5. Experiments
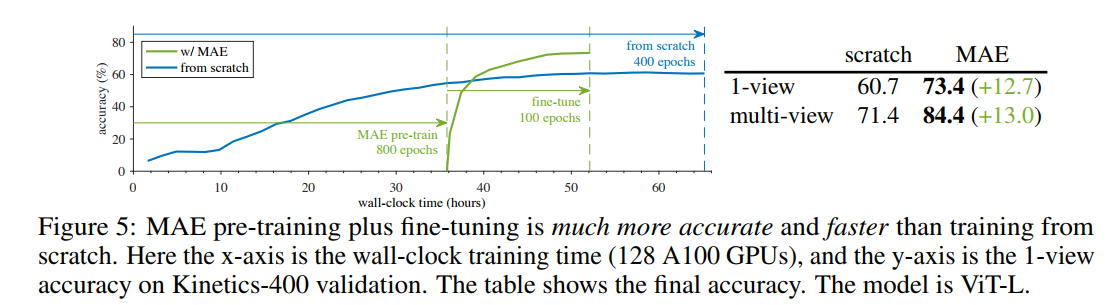
fine-tuning하니까 더욱 정확해지고 빨라진 모습.

Dense encoder 대신 Sparse encoder 즉, 마스킹한 패치는 사용하지 않는 인코더를 썼을 때 성능은 유사하거나 더 좋으면서 처리 속도는 크게 차이가 남.
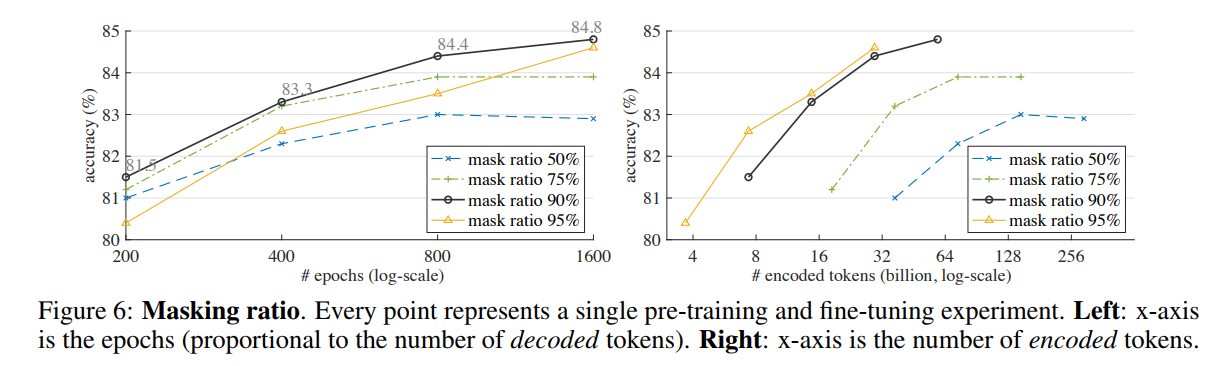
최적 마스킹 비율이 90%라는 것을 알 수 있음.
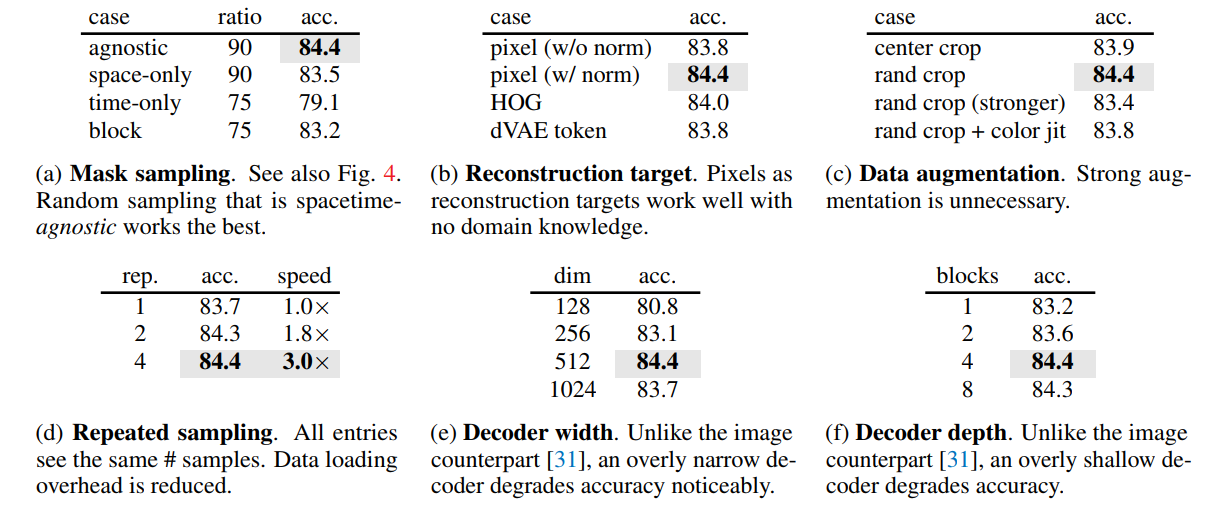
Ablation study 결과
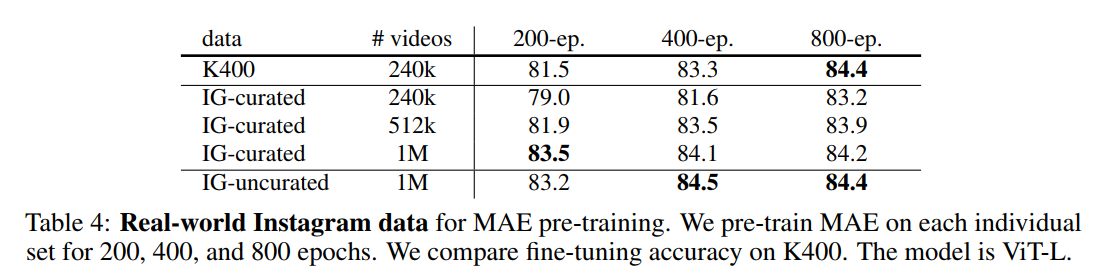
Real-world Instagram 데이터에서 얼마나 좋은지 보여줌.
6. Conclusions
본 논문을 통해 저자들은 몇 가지 인사이트를 발굴해낼 수 있었다.
1) 도메인 지식 혹은 inductive bias를 최소한으로 사용해도 강력한 표현을 학습할 수 있었음
2) 마스킹 비율이 masked autoencoding 방법에서 정말 중요한 요소임. 마스킹 비율은 데이터 특성에 따라 다르게 설정되어야 함.
3) Real-world, uncurated data에 대해 사전 학습이 중요함
본 논문이 아직 해결하지 못한 것은 사용한 비디오 데이터의 스케일이 작다는 것이다.
굉장히 고차원 데이터셋이기 때문에 스케일을 키웠을 때 과연 같은 성능을 보장할 수 있을지는 검증이 추가적으로 필요할 것이다.
