[논문 리뷰] Robust anomaly detection for multivariate time series through temporal GCNs and attention-based VAE
2023 하계 Paper Review

본 Paper Review는 고려대학교 스마트생산시스템 연구실 2023년 하계 논문 세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다.
Abstract
-
다변량 시계열 이상탐지 모델들은 많았으나, (1) 서로 다른 변수간의 상관관계를 반영하지 못함 (2) 각 시점에서의 변수 중요도를 고려하지 못함 과 같은 두 가지 문제점이 존재했음
-
본 논문은 MUltivariate Time series ANomaly deTection framework (MUTANT) 모델을 제시
-
해당 모델은 각 time window 별로 feature graph를 만들고 graph convolutional network (GCN)을 통해 변수간의 embedding을 학습하여 시간에 따라 달라지는 변수간의 관계를 효과적으로 포착해냄
-
추가로 attention-based reconstruction model을 사용하여 MTS의 normal pattern에 대한 robust한 표현을 잘 학습해냄
-
4가지의 real-life datasets에서 F1-score 기준 SOTA 성능을 달성함
1. Introduction
다변량 시계열 이상 탐지는 제조 산업 현장에서 장치의 상태를 모니터링하기 위해 연구되며 많은 관심을 받는 연구 주제이다.
단변량 시계열에서 metric-level로 이상을 탐지하기 보다는 다변량 시계열에서 entity-level로 이상을 탐지하는 것이 훨씬 어렵고 중요한 Task이다.
어려운 이유로는
(1) Labeled anomalies가 부족하고, 예측 불가능하며 가변적인 특성 때문에 지도 학습 방법을 사용하기 어려움
(2) 각각의 metric (변수) 끼리 관련이 높기 때문에 어떠한 문제가 생겼을 때 여러 metric에서 동시에 이상이 탐지될 수 있음. 단변량 시계열 이상 탐지는 global한 특징을 포착할 수 없음.
(3) MTS 데이터에는 강한 temporal dependencies가 존재해서, 기존의 distance/density-based 방법과 density estimation 방법은 제대로 작동하지 못할 수 있음.
등이 있다.
MTS 이상 탐지에서 여러 모델들이 제시되었다.
- [RNN] 기반
Prediction error를 기반으로 이상을 탐지하기 위해 LSTM 사용
OmniAnomaly : stochastic latent variables을 통해 MTS의 정상 패턴을 포착
DAEMON : autoencoder와 adversarial training을 결합하여 reconstruction error를 사용해서 이상 탐지
InterFusion : MTS의 inter-metric과 temporal dependency를 고려하고, hierarchical VAE를 통해 MTS의 정상패턴 학습 - [Graph] 기반
GDN : attention-based graph neural network (GNN)을 사용해서 서로 다른 센서간의 관계를 학습
RNN 기반 방법론들은 변수간의 inter-relationships을 고려하지 못하고, GNN 기반 방법론은 각 time period에서 어떤 변수들이 중요한지에 대한 정보를 고려하지 못한다.
따라서 본 연구는 변수간의 관계와 temporal dependency를 고려한 각 시점별 변수 중요도 모두를 고려하고자 한다.
두가지 고려사항을 모두 반영하기 위해 저자는 MUltivariate Time series ANomaly deTection framework (MUTANT) 모델을 제시했는데 흐름은 다음과 같다.
먼저 time window별로 각 변수들 간의 feature graph를 생성한다.
다음으로 Graph Convolutional Network (GCN)을 사용해서 변수들간의 embedding vectors를 학습하게 되고 이를 통해 time-varying correlations를 포착한다.
추가로 LSTM 기반 attention module로 되어 있는 attention-based reconstruction model을 고안하여 각 time window별 변수 중요도를 추출한다. 이 과정에서 time dependency를 고려하게 된다.
모든 학습 과정은 end-to-end로 진행된다.
본 연구의 주요 contributions은 다음과 같다.
(1) 변수간의 time-varying correlations와 temporal dependency를 기반으로 각 time period 별 변수 중요도를 모두 고려한 reconstruction-based MTS anomaly detection 모델
(2) Attention-based reconstruction model을 제안하여, LSTM 기반 attention module을 통해 변수 중요도를 학습하고 VAE를 통해 MTS의 normal pattern을 학습
(3) 4가지의 데이터셋에서 성능을 검증하였으며 F1-score 기준 SOTA 성능을 달성함
2. Related work
Anomaly detection on univariate time series
- Yahoo EGADS: anomaly filtering layer를 사용한 forecaseted module과 anomaly detection을 결합해서 large-scale time series anomaly를 탐지
- Twitter Seasonal Hybrid Extreme Study Deviation test (S-H-ESD) : local, global anomaly를 전부 탐지 가능
- Google : DNN, RNN, LSTM 등 여러 anomaly detection 모델들을 본인들의 데이터셋에 적용
- DSPOT : extreme value theory를 사용해서 수동으로 threshold를 정하고 이를 통해 univariate time series anomaly detection 수행
- LAKE & ADAF : 전자는 VAE, 후자는 autoregressive flow model을 사용해서 고차원 데이터에서의 anomaly를 탐지
- Donut : VAE 기반 비지도 이상탐지 모델로 seasonal KPI에서의 anomaly 탐지
- SR-CNN : Spectral Residual과 CNN을 결합
Anomaly detection on multivariate time series
- LSTM-NDT : spacecraaft anomalies를 탐지하기 위해 LSTM을 사용해서 MTS prediction을 수행하고 prediction error에 따라 anomalies 탐지
- EncDnc-AE : 정상 데이터를 복원하도록 하여 multi-sensor time series의 latent 패턴을 얻어내는 LSTM-based encoder-decoder 구조. Reconstruction error 기반으로 이상 탐지
- DAGMM : deep AE와 Gaussian Mixture Model (GMM)을 결합. 하지만 time dependency는 고려 못하고, 다변량에만 적합
- USAD : 하나의 encoder와 두개의 decoder 구조로 되어있으며, adversarial training을 수행하여 정상과 이상의 gap을 증가시킴
- DAEMON : autoencoder와 adversarial training을 결합. MTS의 정상 패턴을 얻어내기 위해 생성자와 판별자를 사용하였고 그 후 reconstruction error를 사용해서 이상을 탐지
- USAD와 DAEMON 모두 time dependence를 잘 고려했다고 보기는 힘듦
- LSTM-VAE : VAE의 feed-forward network를 LSTM으로 대체해서 temporal dependency를 고려함
- OmniAnomaly : GRU와 VAE를 결합하고, stochastic variable connection과 planar normalizing flow를 사용해서 모델 성능 높임. recontruction 확률로 이상 탐지 수행
- MSCRED : multi-scale representation matrix를 사용해서 multiple level에서의 상태를 포착하고 attention-based ConvLSTM을 사용해서 temporal한 관계를 학습
- MAD-GAN : LSTM-RNN을 사용해서 temporal dependency를 포착하고 GAN의 생성자, 판별자를 이용해서 이상을 탐지
- 위 방법들은 시계열의 특성은 반영하였으나, 각 변수간의 관계나 서로 다른 변수들의 중요도는 고려하지 못함
- InterFusion : 두 개의 stochastic latent variables로 이루어진 hierarchical VAE를 사용하여 MTS의 정상 패턴을 얻어냄
- AMSL : self-supervised MTS 이상 탐지 모델로, Convolutional autoencoder를 통해 generalization 성능을 향상시킴
- TimeAutoAD : self-supervised MTS 이상 탐지 모델로, pseudo-negative time series를 생성하고 original data로부터 distinguish해서 모델의 성능을 높임
- ELM-AD : cluster 기반 이상탐지 방법론. multivariate ELM-MI 프레임워크와 dynamic kernel selection 방법을 합침
- 위 방법들은 time-varying correlation을 고려하지 못함
Graph Neural Networks
GNN의 기본 아이디어는 현재의 노드는 주변 노드로부터 영향을 받는 다는 것이다.
- GCN : one-step neighbors간의 관계를 종합하여 노드의 표현을 얻어냄
- GATs : attention function을 사용해서 각기 다른 neighbors들에게 각기 다른 weight을 할당해서 서로 다른 영향을 반영하는 방식
- GDN : graph attention neural network 기반으로 서로 다른 센서들간의 관계를 얻어내고 관계들에서 벗어난다면 이상으로 판단함
- GNN-DTAN : graph contruction module을 사용해서 feature간의 관계를 학습. 학습된 모델은 데이터를 예측하는데 사용되고 예측된 값과 실제값 사이의 차이를 anomaly score로 계산하게 됨.
- graph 기반 방법들은 변수간의 관계는 고려할 수 있지만, anomalydetection을 위한 서로 다른 변수들의 영향력은 고려하지 못하는 경향이 있음
3. Problem statement
Definition 1.
MTS는 연속된 관측치들의 집합이며 m개의 변수, n개의 시계열 길이를 갖는다.
MTS X가 주어졌을 때, 특정 time stamp인 현재의 unseen x_t 가 이상인지 아닌지를 알고 싶은 상황이다. 이를 위해서 과거의 데이터를 기반으로 현재의 데이터를 판단하게 되는데, 때문에 몇 시점 앞을 바라볼 것인지도 정해져야한다.
Problem 1 (MTS Anomaly Detection).
MTS X가 주어졌을 때 anomaly detection의 목표는 본 적 없는 관측치 x_t의 anomaly score를 계산해서 특정 Threshold를 기준으로 0(정상), 1(이상)인지 label을 부여하는 것이다.
4. Methodology
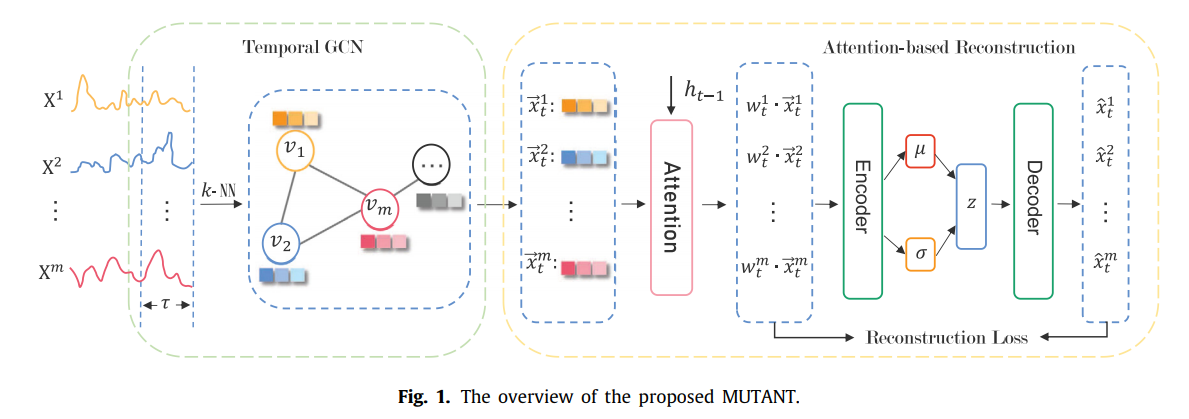
자세하게 살펴보기 전에 MUTANT의 전체적인 프레임워크를 보면 두 개의 구성요소로 되어있는 것을 알 수 있다. 첫번째는 Temporal GCN이고, 두번째는 Attention-based reconstruction module이다.
전자는 각 time window 별로 서로 다른 변수간의 관계로부터 representation 벡터를 얻어내는 것을 목적으로 한다. 후자는 LSTM 기반 attention과 VAE를 사용하여 robust한 latent representation을 학습하여 MTS의 normal 패턴을 포착하고, reconstruction error를 사용해서 이상을 탐지하는 역할을 수행한다.
GCN, LSTM, VAE는 이상탐지에 자주 쓰였던 모듈들이지만 이들을 한 번에 통합하고자 하는 시도는 없었으며, 이들을 한 번에 통합함으로써 time dependence, 변수간의 관계, 변수들에 서로 다른 가중치를 주는 것이 가능해졌다.
4.1 Temporal graph convolutional network
MTS는 여러 센서들로부터 같은 시간대에 수집되는 데이터이며 서로 관련되어 있다. 따라서 특정 상황이 발생했을 시 여러 센서들로부터 동시에 문제가 생기게 된다. 이들의 관계가 표현될 수 있고, 이상탐지에 사용된다면 당연히 도움이 될 것이다.
여러 변수들의 관계를 표현하는 방법으로 본 연구는 GCN을 사용했다. 이 때 GCN은 각 time window마다 적용되어 representation을 학습할 수 있도록 된다.
먼저 k-NN 방법론을 사용해서 각 time window 마다 feature graph ={} 만들 수 있는데 이는 각각의 변수가 가장 관련있는 k개의 변수와 연결되도록 한다.
현재 time window에서 각 변수 값들은 feature처럼 표현되는데 다음과 같이 표현된다.
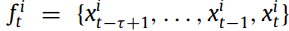
이제 feature space에서 m 변수들 사이의 correlation matrix 를 계산한다. 논문에서는 Pearson correlation coefficient를 사용했다.
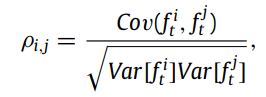
그리고 graph 를 표현하기 위해 adjacency matrix 를 사용하고 값이 1을 가지면 노드간에 관계가 있는 것이다.
변수간의 inter-relationship을 포착하기 위해서 이웃 변수들로부터 변수들의 feature를 aggregate할 수 있도록 각 graph 별로 graph convolution 연산을 이용한다.
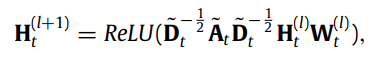
위 식에서 는 layer-specific trainable weight matrix, , , , 이런 수식들이 나오는데 정확하게 이해하기는 어렵다. 는 embedding dimension이다.
temporal GCN의 final output은 각 time window 마다의 time-varying embedding 벡터이다.
4.2 Attention-based reconstruction module
각 변수에서 embedding vector를 얻어낸 후에는, 이상탐지를 위해서 MTS의 필요한 특성을 더 잘 얻어낼 수 있는 reconstruction model을 사용한다. 해당 모듈은 LSTM-based attention과 VAE-based reconstruction module로 나뉜다.
4.2.1 LSTM-based attention
MTS가 여러 변수들을 포함하고 있지만, 이상탐지를 위한 변수별 중요도는 분명하게 다르고, time window별로 중요한 변수 또한 다르다. 게다가 time dependencies도 고려되어야 한다.
이러한 것들을 모두 고려하기 위해서 LSTM-based attention이 사용되는 것이다.
이유는 LSTM은 그동안 시계열에서 time dependence를 얻어내는데 성공적이었기 때문이다.
다른 attention model들에 비해, LSTM 기반 attention 매커니즘은 더 간단하고 효율적이다.

위 그림에서 볼 수 있듯, 각 time window에서의 embedding vector들이 input이 되며,
linear layer와 softmax layer를 통해 현재 time window의 변수들의 가중치를 얻게 된다.
그 후, weighted embedding vector를 LSTM unit의 input으로 사용하여 다음 time window에서의 변수들의 weight을 얻어낸다.
LSTM 구조는 여타 다른 모델들과 유사하다.
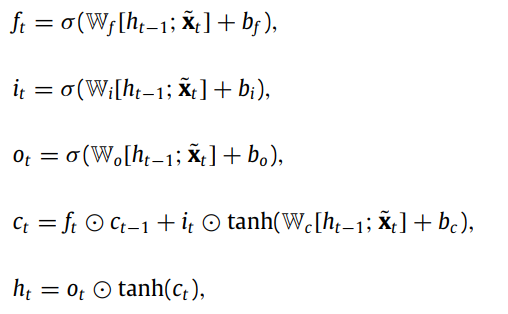
Weight을 얻어내는 수식은 다음과 같다.
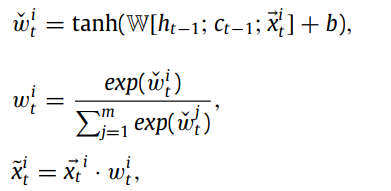
LSTM unit의 input은 연속적인 time windows의 embedding vectors이기 때문에
MTS의 time dependencies를 포착 가능하며, dependencies를 서로 다른 time window에서 변수들의 가중치로 사용할 수 있게 되고,
해당 가중치들로 인해 변수들이 이상 탐지에서 서로 다른 역할을 할 수 있도록 강제할 수 있다.
4.2.2 VAE-based reconstruction module
temporal GCN이 각 window 별로 embeddings을 얻어냈고,
LSTM-based attention이 time dependencies를 포착했으나,
정상 샘플과 비정상 샘플의 차이를 측정하여 비지도로 이상 탐지하는 작업은 아직 수행되지 않았다.
VAE는 MTS 이상탐지에서 주로 사용되었는데, 그 이유는 고차원 데이터의 latent 패턴을 얻어내는 능력 때문이다.
여기서 VAE는 reconstruction module을 학습시키기 위해 사용하면서 동시에 LSTM-based attention에서의 가중치를 학습하는데 도움을 줄 수 있도록 한다.
VAE 작동방식은 설명이 잘되어있는 정리글들이 많기 때문에 생략한다.
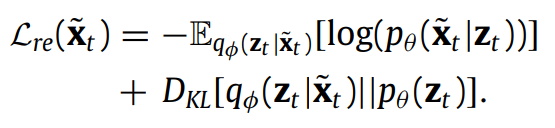
대부분의 VAE 학습 방식처럼, Stochastic Gradient Variational Bayes (SGVB)를 사용해서 ELBO를 maximize 하는 방식으로 VAE의 파라미터를 학습한다.
Fig 1에서 볼 수 있듯, 를 VAE의 input으로 사용하여 variable embeddings의 차원을 축소한다. 인코더에서 차원 축소하여 latent representation인 를 얻어내고, 디코더를 통해 reconstructed value 를 얻어낸다.
이제 와 의 차이를 줄이는 방식으로 VAE 모델을 학습시킨다.
4.3 Offline model training
최고의 탐지 성능을 도달하기 위해, joint learning objective function을 통해 end-to-end로 학습하는 방법을 택했다.
먼저, 비지도 학습 방식으로 temporal GCN model을 최적화하기 위해 negative sampling을 통해 binary cross-entropy loss function을 사용한다.

해당 loss function을 통해 positive samples에서의 node embeddings 간의 similarities를 maximize하고 동시에 negative samples에서의 node embeddings 간의 similarities를 minimize한다.
두 번째로, VAE reconstruction module 학습시키고,
마지막으로 두 loss function을 결합하여 최종 loss function을 만든다.
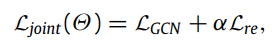
여기서 는 하이퍼파라미터이다.

알고리즘은 위와 같다.
4.4 Online detection
MUTANT 학습 후에는 MTS에서 t 시점의 관측치가 정상인지 아닌지를 판단한다.
MUTANT의 input은 time window 이며, output은 reconstructed input 이다.
Anomaly score는 reconstruction error이며 다음과 같이 표현한다.
다른 anomaly score와 유사하게 값이 낮으면 정상, 높으면 비정상이다.
5. Experiment
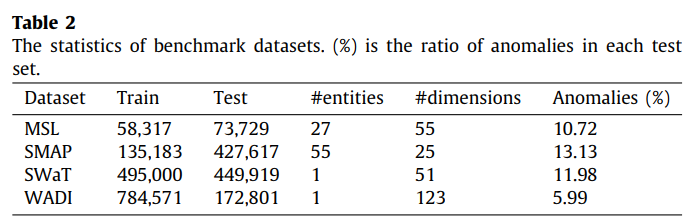
5.1 Datasets
- Mars Science Laboratory (MSL) rover
- Soil Moisture Active Pssive (SMAP) satellite
- Secure Water Treatment (SWaT) dataset
- Water Distribution (WADI) dataset
5.2 Evaluation metrics

Detection performance 측정하기 위해서 point-adjusted 방법을 채택했다.
5.3 Baselines
- LSTM-NDT : prediction error 기반으로 LSTM-based prediction network. pruning 전략이 사용됨.
- LSTM-VAE : VAE의 feed-forward network을 LSTM으로 대체하여 temporal dependence를 포착.
- OmniAnomaly : VAE-based reconstruction model로 GRU를 사용하여 temporal dependencies를 얻어내는 모델, stochastic variable connection과 planar normalizing flow 사용해서 detection accuracy를 높임
- USAD : 하나의 encoder와 두 개의 decoder를 사용하는 unsupervised 프레임워크로 GAN 방식으로 normal data와 abnormal data의 gap을 증가시킴.
- 이 밖의 모델들 : MTAD-GAT / GDN / ELM-AD / DAEMON / InterFusion / AMSL
DAEMON의 소스코드는 오픈되어있지 않음.
InterFusion 코드는 가능하긴 하지만, 학습이 너무 오래 걸림.
그래서 해당 논문에 제시된 성능을 그대로 사용함.
5.5 Overall performance

4개 데이터셋에 대해서 MUTANT가 F1-score 기준 SOTA 성능을 달성함.
5.6 Hypothesis testing
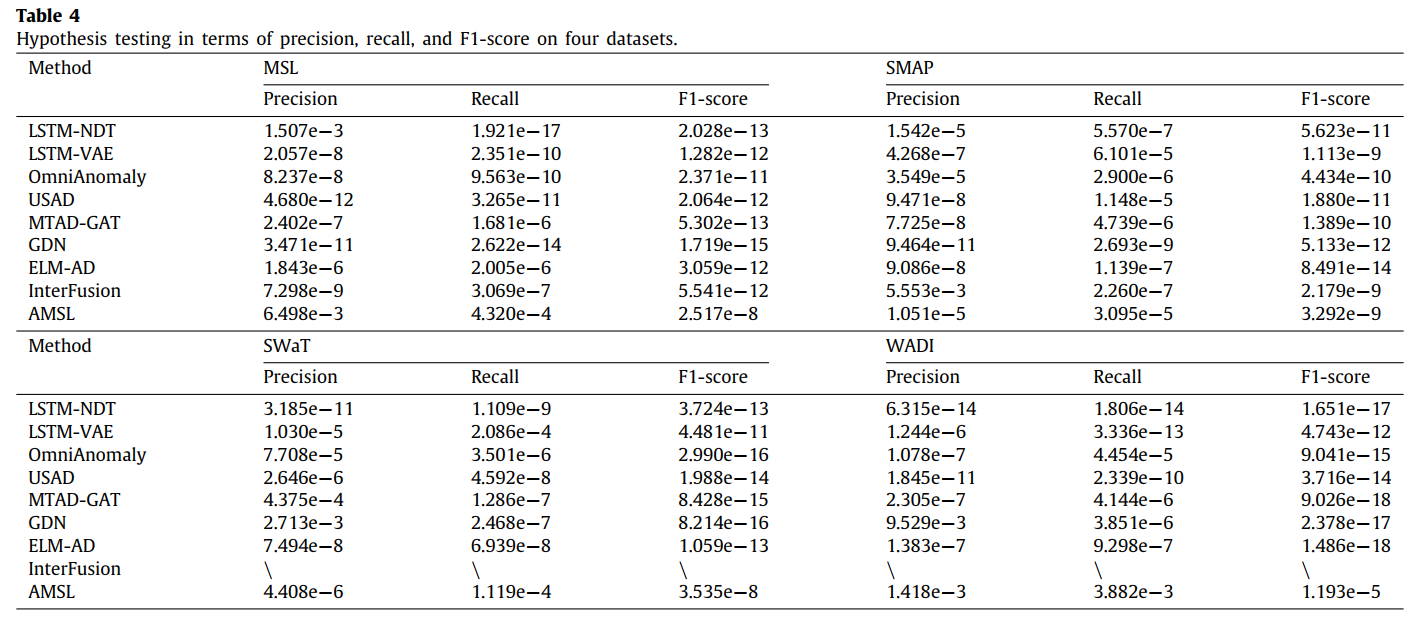
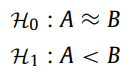
B가 MUTANT의 detection result이며 A는 다른 model들의 detection result이다.
즉 귀무가설을 기각할 수 있다면 다른 모델들의 비해 MUTANT 모델이 우수함을 증명할 수 있다.
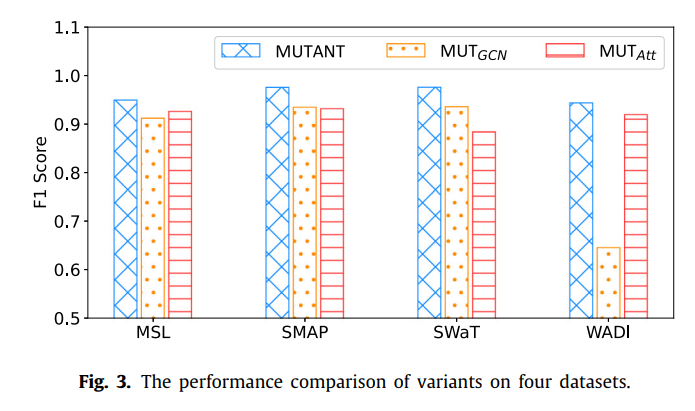
5.7 Ablation study

5.8 Parameter sensitivity

5.9 Robustness evaluation

5.10 Case study

5.11 Convergence of mutant

6. Conclusion
MTS anomaly detection을 수행하기 위해 unsupervised 방법인 MUTANT를 제안하였다.
다시 정리하자면 다음과 같은 흐름이다.
먼저 MTS의 각 time window별 variable features를 기반으로 feature graph를 만들고,
GCN을 사용해서 모든 변수들의 embeddings를 학습한다.
다음으로 embeddings들을 attention-based reconstruction module에 보내는데,
해당 module은 LSTM-based attention module과 VAE module로 구성되어있고,
전자는 각 time window에서의 변수 중요도를, 후자는 MTS의 정상 패턴을 포착할 수 있는 latent representation을 학습하게 된다.
모델은 joint learning objective function을 통해 모델을 최적화하는 end-to-end 학습을 진행하게 된다.
4가지 벤치마크 데이터셋에서 MUTANT는 SOTA 성능을 달성했다.
Future work로는, MTS anomaly detection을 위해 contrastive learning을 사용하는 robust한 self-supervised elarning framework를 생각하고 있다.
