
본 Paper Review는 고려대학교 스마트생산시스템 연구실 2024년 하계 논문 세미나 활동입니다. 논문의 전문은 여기에서 확인 가능합니다.
Abstract
- 기존의 비전 이상 분류 및 Segmentation 분야는 task-specific한 이미지와 annotation이 필요했음
- 본 연구는 zero-shot 혹은 few-normal-shot 이상 분류 및 Segmentation 모델을 제시함
- Vision-language 모델로 유명한 CLIP을 활용하는데, 이는 이상 분류 및 Segmentation 분야에서 잘 활용되지 않았기에 부족한 점이 있어서 window-based CLIP (WinCLIP)을 제시
- 해당 모델은 state words와 prompt templates을 적절하게 앙상블했으며, window/patch/image 단위의 feature를 text와 적절하게 align될 수 있도록 효과적인 extraction & aggregation함
- 정상 이미지로부터 추가적인 정보를 활용하는 WinCLIP+도 함께 제시함
1. Introduction
비전 이상 분류 및 segmentation은 산업 제조에서의 결함을 분류하고 localize하는 long-tail 문제이다. 색상, 질감, 크기가 산업 도메인에 걸쳐서 다 다르기 때문에 해당 Task들은 쉽지 않다.
첫 번째로 결함은 다양한 variation이 있지만, 그 자체가 흔하지 않다는 점이다. 따라서 one-class 혹은 비지도 방식으로 이상을 탐지한다. 하지만 정상 이미지가 적다면 이마저도 쉽지 않다.
두 번째로 이전 연구들은 각각의 visual inspection task 맞춤 모델에 집중했고, 이는 long-tail에서 scalable하지 못하다. 그래서 저자들은 zero-shot 이상 분류 및 segmentation 모델을 연구하고자 했다. 하지만 많은 결함들은 정상 이미지의 관점에서 정의되는데, 예를 들어 circuit board에서의 missing component가 가장 쉽게 발생하는 이상이다. 따라서 이러한 경우 최소한 몇 장의 정상 이미지가 필요하고, few-normal-shot 이상 분류 및 segmentation도 같이 연구한 이유가 그 때문이다.
Vision-language 모델은 zero-shot 분류 Task에서 상당히 좋은 평가를 받고 있다. 그 중 저자들은 CLIP을 활용하는데 이유는 해당 모델이 몇 없는 오픈 소스 Vision-language 모델이기 때문이다.
저자들은 zero-shot 그리고 few-normal-shot(1~4) 상황을 따랐고, 언어가 해당 상황에서 중요하다는 가정을 기반으로 진행했다. 해당 가정의 첫 번째 이유는 "정상"과 "이상"은 context-dependent하고 언어가 해당 상태를 명확히해줄 수 있다는 것이다. 맥락에 의존한다는 말은, 예를 들어 옷에 구멍이 났다고 했을 때 원래 그런 디자인의 옷이라면 정상, 평범한 옷이라면 이상일 수 있다는 것이다. 두 번째 이유는 언어가 추가정인 정보를 제시할 수 있다는 것이다.
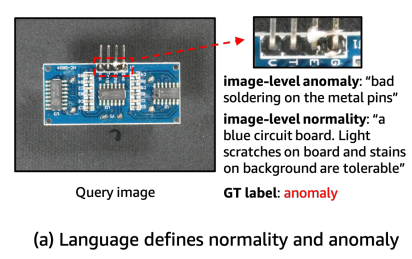
예를 들어, 위 그림처럼 정상의 경우 blue circuit board인데 약간의 스크래치는 허용한다는 정보를 추가할 수 있다. 그 경우 soldering defect을 더 쉽게 찾아낼 수 있다.
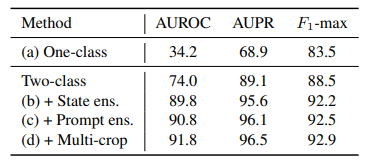
CLIP이 오픈소스 vision-language 모델이어서 이를 기반으로 활용했다. 이는 원래 zero-shot 분류에서 활용되었는데, text prompt를 "정상", "이상"으로 준다면 이상 분류에도 활용할 수 있다. 하지만 아래 표에서도 알 수 있듯 naive한 baseline을 그대로 활용한다면 성능이 별로여서 저자는 정상과 이상 상태를 더 잘 묘사할 수 있는 word ensemble을 활용한다.
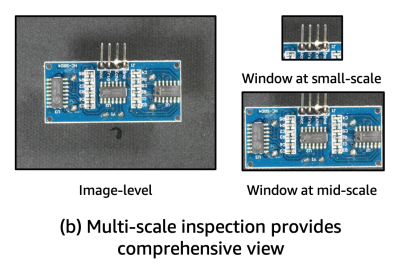
또 다른 어려움은 CLIP은 cross-modal alignment를 오직 이미지와 텍스트의 global embeddings에 집중하도록 학습되었다는 것이다. 하지만 이상 segmentation의 경우 pixel-level 분류이기 때문에 적합하지가 않다. 그래서 저자는 Window-based CLIP (WinCLIP)을 제시하는데 이는 multi-scale features를 추출하고 결합하여 vision-langugage alignment에 활용하는 방법이다. multi-sclae feature의 예시는 아래와 같다.
그리고 저자들이 추가로 제시하는 few-normal-shot 상황에서 사용하는 WinCLIP+의 경우 아래 그림과 같이 reference 이미지를 극소수로 추가 활용하는 방법이다.

결론적으로 zero-shot 모델의 경우 각각의 상황에 대해 어떠한 튜닝도 필요없고, few-normal-shot 모델의 경우 어떠한 segmentation annotation이 필요없다.
2. Related work
Vision-language modeling
최근 사전학습된 VLM 모델들이 성공을 거두고 있는데, CLIP이 처음으로 web-scale image-text 데이터로 사전학습하여 상당히 많은 분야에서 높은 일반화 성능을 보이는 모델이다. 오픈 소스 모델이며 prompt engineering & tuning만 잘 한다면 language guided 탐지 및 segmentation에서도 좋은 성능을 거둘 수 있다.
Anomaly classification and segmentation
이상이 부족한 탓에, 많은 연구들이 많은 정상 이미지에 의존하는 모습을 보였다. 지금은 탐지 성능이 saturated 되어 버린 MvTec-AD 벤치마크 데이터셋의 경우 하지만 정상 이미지가 그리 많지 않다. 따라서 RegAD와 같은 모델들은 model-reusing 하는 방법으로 보지 못한 객체에 대한 정상성을 학습하여 정상이 부족한 상황에서도 활용할 수 있도록 하였다. 한편 학계와 산업계의 격차를 줄이고자 Visual Anomaly (VisA) 데이터셋도 제시되었는데 훨씬 탐지하기 어려운 데이터셋이고, 이에 대해서는 ViT 모델들이 성능을 거두고 있다.
State classification
이상 분류는 어떻게 본다면 state 분류와도 연결될 수 있다. CV에서 object, scene, matrial 인식에 집중하고 있는 한편, state 분류는 세분화된 하위 개체의 속성을 구별하는 걸 목표로 한다. 몇몇 연구는 속성과 객체의 관계를 그래프로 표현하여 GNN을 통해 해결하려고도 한다.
3. Background
Anomaly classification and segmentation
Anomaly classification은 입력된 이미지 x가 {+,-} 중 무엇인지 분류하는 문제이며, 논문에서는 +를 이상이라고 규정한다. Anomaly segmentation은 입력된 이미지 x의 픽셀들이 {+,-} 중 무엇인지 분류하는 문제다.
Zero-shot classification with CLIP
Contrastive Language-Image Pre-training (CLIP) 모델은 vision-language 표현을 제공하는 대규모 사전학습 방법론이다. Image encoder f와 text encoder g가 대조학습을 통해 코사인 유사도를 최대화하는 방향으로 학습되게 된다.
"a photo of a [c]" 와 같은 문장이 prompt template이며 여기서 c가 label word가 된다. Prompt template이 있고 없고는 성능 차이가 크다. 추가로 "a cropped photo of a [c]" 문장과 같은 multiple template를 함께 prompt embedding 한다면 성능을 더욱 향상시킬 수 있다.
4. WinCLIP and WinCLIP+
4.1 Language-driven zero-shot AC
Two-class design
저자들이 제안하는 이진 zero-shot 이상 분류 프레임워크 CLIP-AC는 두 클래스 프롬프트 [c]를 사용한다. "normal [o]" vs "anomalous [o]". 여기서 [o]는 object-level 라벨이다. 예를 들어 "bottle"일 수도 있겠고 간단하게 "object"일 수도 있다.
추가로 저자들은 정상 프롬프트만 사용하는 one-class 디자인도 실험했는데 이는 s := "normal [o]"로 표현되고 anomaly score는 "-<f(x),g(s)>"로 표현된다.
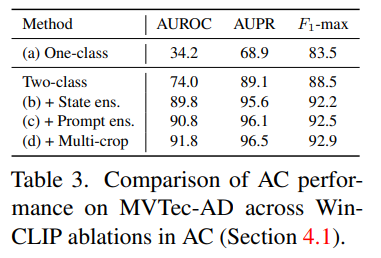
실험 결과로도 알 수 있듯, Two-class 디자인이 One-class 디자인에 비해 성능이 월등히 높기 때문에 저자들은 Two-class 디자인을 채택한다. 이에 대한 이유로 이상에 대한 특정한 정의가 좋은 성능에 필수적임을 밝혀냈다.
Compositional prompt ensemble (CPE)
물체 단위의 분류와 달리, CLIP-AC는 주어진 물체의 상태를 분류해야한다. 이는 task에 의존하여 다양하게 정의되며 주관적이다. 예를 들어 "missing transistor"는 circuit board에서 이상이지만, "cracked"는 wood에서 이상이다.
물체의 모호한 두가지 상태를 더 잘 정의하기 위해서 저자는 Compositional Prompt Ensemble을 제시하는데 이는 사전에 정의된 라벨마다의 state words와 text templates의 조합을 생성한다. 예를들어 정상에는 "flawless" / 이상에는 "damaged" 이런 식이다. 또한 task-specific한 state words를 결함에 대한 사전 지식을 기반으로 추가했다. 예를 들어 PCB에 "bad soldring" 결함이 있다.
추가로, 이상 작업을 위해 template list를 작성하기도 했는데 예시는 "a photo of a [c] for visual inspection"이다.
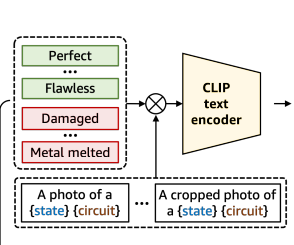
state와 template의 모든 조합을 얻은 후 정상과 이상 클래스를 표현하기 위해 라벨별 text embedding 평균을 계산한다. 이로서 zero-shot scoring model with CPE를 제안할 수 있었고 ascore0는 0에서 1 사이로 주어진다.
Remark
저자는 two-class design with CPE가 새로운 접근이라고 주장한다. 보통의 이상 탐지의 경우 정상 데이터로 학습하고, 새롭게 들어온 데이터가 이로부터 얼마나 떨어져있는지 여부를 통해 이상을 판별한다. 하지만 그렇게 된다면 실제 이상과 정상으로부터 허용 가능한 오차와의 구별이 어렵게 된다. 그치만 이러한 한계를 language를 통해 정확한 단어로서 상태 정의해줌으로 해결할 수 있다고 한다.
4.2 WinCLIP for zero-shot AS
CPE로부터 language guided anomaly scoring model이 주어지고, WinCLIP을 zero-shot anomaly segmentation에도 활용할 수 있다. 이 때 feature를 추출하는 부분은 아래와 같이 진행된다.
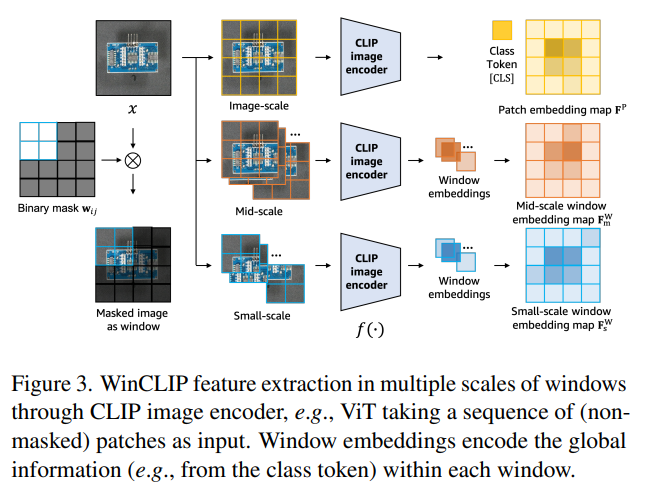
1단계로 sliding windows를 생성하는데 이는 kxk kernel이 지나가면서 해당 패치를 사용할지 말지를 0, 1로 나타낸다.
2단계로 원본 이미지에 Binary mask를 곱하여 Masked image를 만든다.
입력에 사용할 데이터가 완성되었다면, feature를 추출하는 과정을 거치게 되고 이를 위해서 ViT를 활용했다. 물론 CNN도 활용할 수 있다.
또한 natural dense representation 후보로, 풀링 전 마지막 feature map인 penultimate feature map을 활용했다.
가장 위의 그림처럼, class token [CLS] 대신 ViT-based CLIP의 patch embedding map F^p의 경우, segmentation을 위해 패치별로 ascore_0를 적용했다.
그러나 patch-level features가 language 공간에서 align이 잘 안되어 dense 예측에 별로라는 것을 발견했는데, 이는 해당 feature가 CLIP에서 language 신호와 직접적으로 연결되지 않기 때문이기도 하고 이미 patch feature가 self-attention에 의해 global context와 합쳐져서 segmentation을 위한 local detail 포착을 방해하기 때문이라고도 한다.
그래서 penultimate feature F^p보다는 WinCLIP으로부터의 dense feature인 F^W가 CLIP 사전학습에서의 text와 더 직접적으로 할당되기 때문에 local detail에 더 잘 집중한다. 아 그리고 이미지에 마스크 씌워서 해당 작업을 수행하면 masked autoencoder와 비슷한 효과를 본다.
Harmonic aggregation of windows
각각의 local window에서 zero-shot anomaly score 는 window feature 와 CPE로 부터의 text embeddings 사이의 유사도로 계산된다. 해당 score는 local window의 모든 pixel에 부여되는데 수식은 아래와 같다.
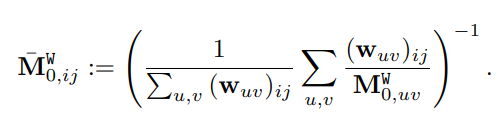
Multi-scale aggregation
kernel size 는 각 위치의 둘러쌓인 맥락의 양으로 생각하면 된다.
이걸 가지고 local details와 global 정보의 균형을 조절한다.
그리고 multi-scale features로부터 예측을 합체하기 위해서 small-scale(2x2), mid-scale(3x3), image-scale feature를 harmonic averaging을 사용해서 결합하였다.
4.3 WinCLIP+ with few-normal-shots
이상 분류와 segmentation에 있어서 language guided zero-shot 접근이 충분하지 않을 때가 있어서 저자는 K장 정도의 정상 reference 이미지를 활용해서 visual reference를 통해야 잡을 수 있는 결함들도 포착하고자 했다.
예를 들어 "Metal-nut"에서 "flipped upsidedown"이라는 결함은 정상 이미지와 얼마나 다르게 생겼냐로만 잡을 수 있다.
저자는 reference association을 제시하는데 이는 심플하게 reference 이미지로부터의 memory feature를 저장했다가 꺼내오는 방식으로 통합하는데 cosine similarity를 사용한다. 수식은 아래와 같다.
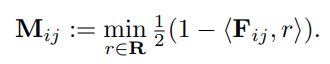
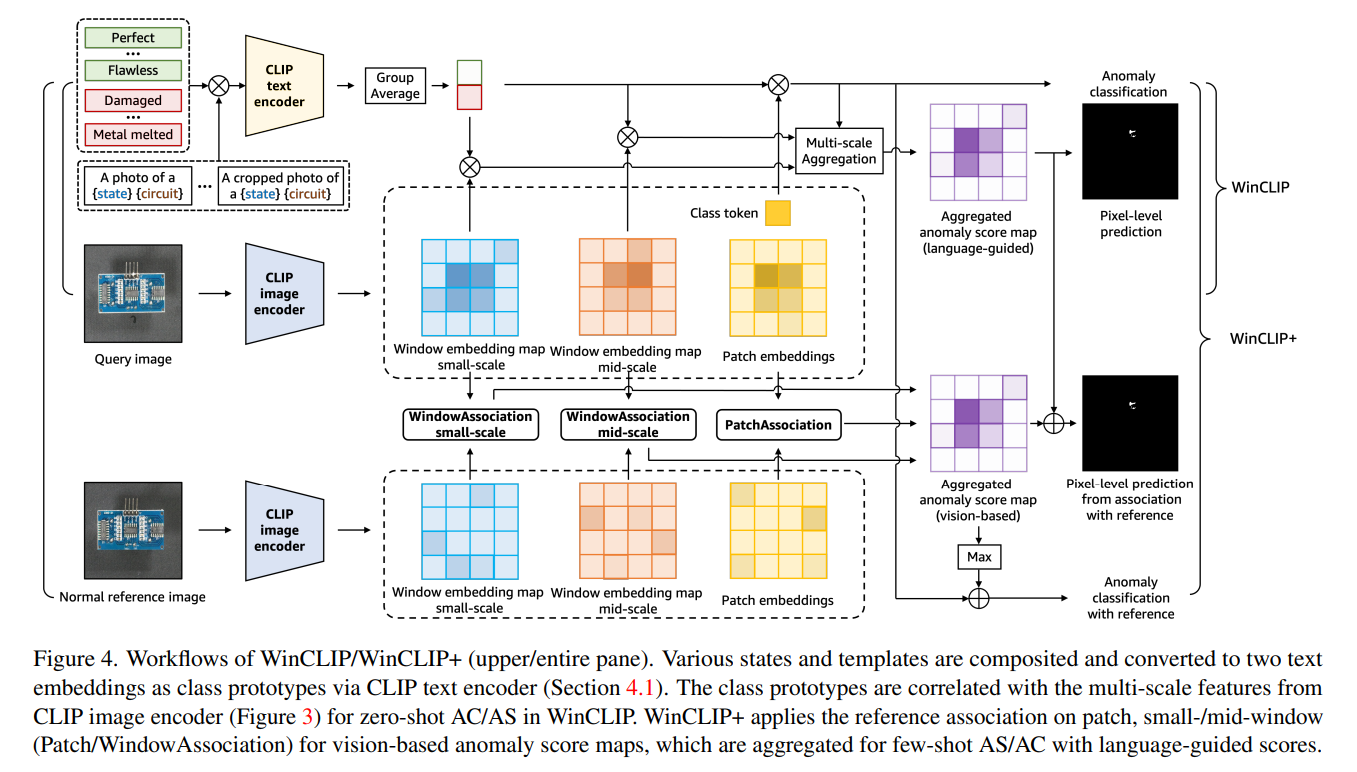
위 그림에서 볼 수 있듯 few-shot 샘플이 주어지면 separate reference memories를 세가지 feature로 만들어내고 유사도를 평가한다. 세 가지 feature는 앞서 제시한 것들이다.
그 결과 WinCLIP+는 multi-scale 예측을 평균내어 이상 segmentation을 수행할 수 있게 된다.
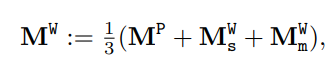
이상 분류를 위해서, 의 최대값과 WinCLIP zero-shot 분류 점수를 결합한다.
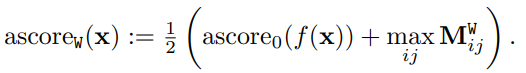
5. Experiments
Datasets
실험에 활용한 데이터셋은 MVTec-AD와 VisA 데이터셋이다.
Evaluation metrics
이상 분류
(a) Area Under the Receiver Operating Characteristic (AUROC)
(b) Area Under the Precision-Recall curve (AUPR)
(c) -score at optimal threshold
이상 segmentation
(a) pixel-wise AUROC (pAUROC)
(b) Per-Region Overlap (PRO)
(c) (pixel-wise) -max
Implementation details
공개된 사전 학습 모델인 OpenCLIP을 활용했다.
정확히는 LAION-400M을 ViT-B/16+ 기반 CLIP으로 사전학습된 걸 사용했다.
5.1 Zero-/few-shot anomaly classification
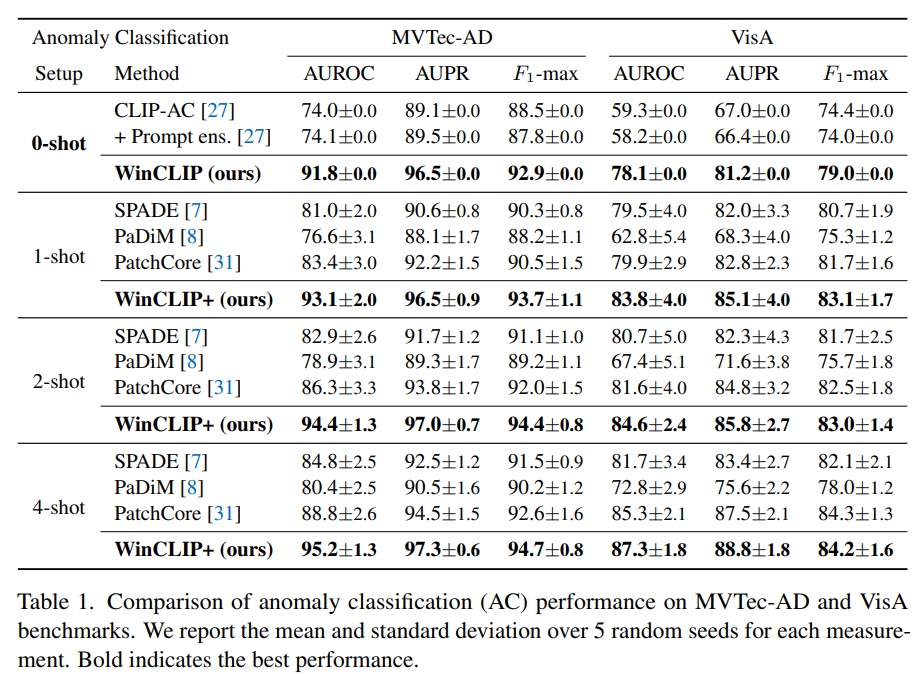
Zero-shot 비교 모델은 이상분류 특화 모델이 없기에 CLIP을 그대로 활용했고 당연히 제안하는 방법이 가장 높은 성능을 거두었다.
Few-shot 비교 모델들 SPADE, PaDiM, PatchCore 들에 비해서도 제안하는 방법이 더 좋았다.
VisA는 상당히 어려운 데이터로 알고 있는데 성능이 꽤나 좋아서 놀랐다.
5.2 Zero-/few-shot anomaly segmentation
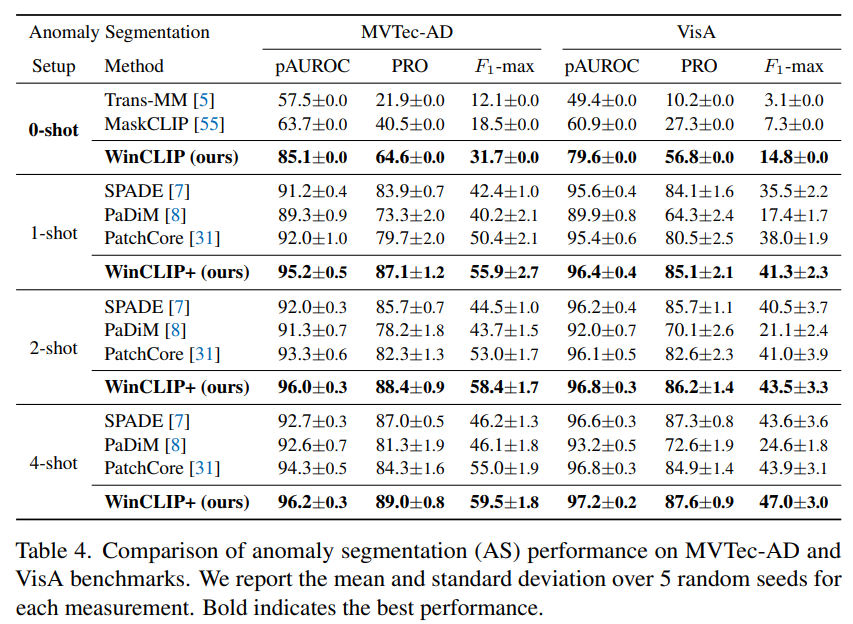
zero-shot anomaly segmentation도 기존 연구가 없지만, zero-shot segmentation 모델들을 활용해서 비교 실험하였다. Trans-MM의 경우 pixel-level mask를 만드는 트랜스포머를 제안하는 모델이고, MaskCLIP의 경우 CLIP 기반의 일반적인 semantic segmentation 모델이다.
역시나 zero-shot이든 few-shot이든 제일 좋은 성능을 보였다.
평가지표로 Dice나 mIoU를 쓰면 어느 정도 나올지 궁금하긴 하다.

5.3 Comparison with many-shot methods
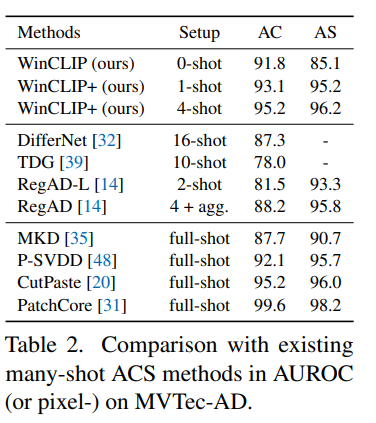
many-shot들 보다도 좋은 성능을 보였으며 full-shot 모델에 근사한 성능을 보였다.
5.4 Ablation study
MVTec-AD 데이터셋을 가지고 Ablation study도 진행했다.
WinCLIP for AC
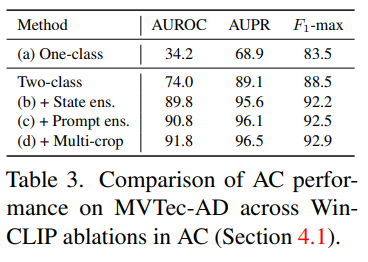
One-class보다 Two-Class가 좋다는걸 증명했고, state-level, prompt-level, Multi-crop 예측 등이 어느 정도 성능 향상에 도움을 주는지를 보여주었다.
WinCLIP for AS
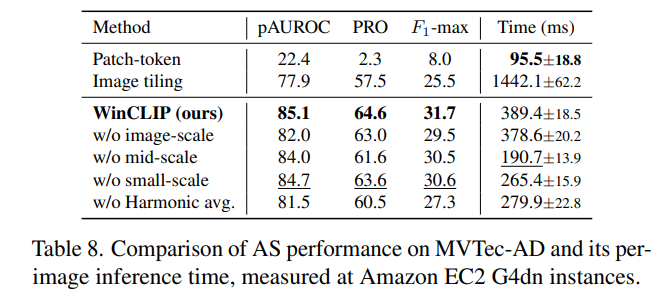
WinCLIP이 zero-shot AS에서 local features 추출에 얼마나 효과적인지에 더해 multi-scale, harmonic averaging이 얼마나 효과적인지 또한 실험으로 보여주었다.
WinCLIP with task-specific defects
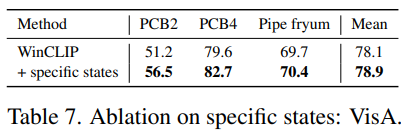
객체 종류에 따라 task-specific한 결함이 발생할 수 있는데 이에 대한 task-specific한 state words를 주고 안주고의 성능 차이도 보여주었다.
6. Conclusion
본 연구를 통해 저자들이 제시한 것을 요약하면 다음과 같다.
(1) 이상 인식 task에 있어서 사전학습된 CLIP이 얼마나 효과적으로 사용될 수 있는지를 증명하였다. 특히 compositional prompt ensemble이 정상과 이상을 text 단에서 어떻게 정의하는지를 보여주었고, 결과적으로 zero-shot 방식에서도 좋은 성능을 거둘 수 있음을 증명하였다.
(2) WinCLIP이 multi-scale feature를 image-text alignment에 일치하게 효과적으로 추출하여 zero-shot segmentation에 얼마나 효과적인지를 증명하였다.
(3) few-shot 기반의 WinCLIP+의 성능도 증명하였다.
