
본 Paper Review는 고려대학교 스마트생산시스템 연구실 2024년 하계 논문 세미나 활동입니다. 논문의 전문은 여기에서 확인 가능합니다.
Abstract
- 반도체 제조 공정에서 결함은 점점 다양해지고 control하기 어려워짐
- 각 공정에서 다양한 특성을 띈 반도체 제조 공정 데이터로부터 최종 품질을 예측하고자 함
- 생산성을 높이기 위해, 결함 발생 환경과 데이터 특성이 고려되어야하고 결함이 종종 다른 원인에 의해 발생하지만 같은 현상으로 발생하기 때문에 특성에 따라 결함 유형을 나누고 k-means나 SOM과 같은 비지도 학습 방식으로 품질을 예측했음
1. 서론
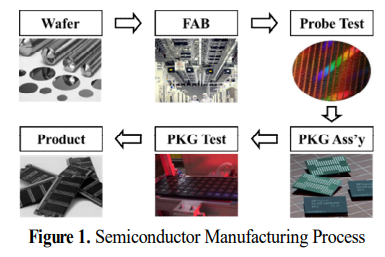
반도체는 수백 가지 세부 공정을 통해 생산되지만 제조공정 순서를 간단히 나타내면 위와 같다.
실리콘 잉곳(Ingot)에서 얻은 원형의 웨이퍼(Wafer)에서 시작해, FAB(Fabrication) 공정에서 반도체 회로를 형성한다. 그 후 프로브 테스트(Probe test) 및 패키지 테스트(Package test) 공정에서 특성을 테스트하여 정상인지 파악한다. 패키지 조립(Package Assembly)은 프로브 테스트를 통과한 웨이퍼에서 칩(Chip) 단위로 외곽 표면을 형성하는 공정이며, 패키지 테스트는 조립이 완료된 제품에 대해 조립 불량 및 잠재 불량을 최종 판정한다.
비 휘발성 낸드 플래시(NAND Flas) 메모리의 3차원 적층 구조 변화 등 다양한 기술을 통해 반도체 생산성을 높이려고 하는데 제품의 신뢰성 문제와 같은 다양한 특성의 불량이 발생하고 생산 제품 다양화 역시 품질관리의 중요성을 높이고 있다.
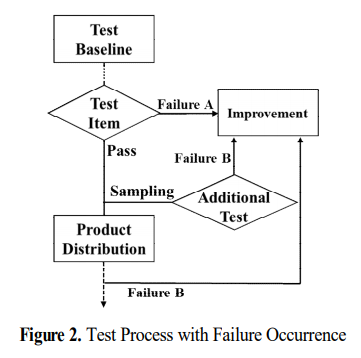
불량의 발생을 반도체 테스트 관점에서 나타내면 위와 같다. Test Baseline이 프로브 테스트 및 패키지 테스트를 포함하는 일련의 테스트 진행을 의미한다. 여기서 주목할 점은 Failure B 같은 경우는 전량 테스트되는 테스트 베이스라인에서는 정상으로 분류되었으나 샘플링되어 추가 테스트를 진행한 결과 불량으로 판단된다는 점이다. 이를 잘 파악하기 위해 테스트 항목에서 계측된 데이터 등을 독립 변수로 하고, 테스트 진행 후에 발생한 불량 여부를 종속변수로 하는 데이터 셋을 구성하여 품질 예측을 진행한다.
이전 연구들을 살펴보면 테스트 데이터를 통해 품질을 예측하고 향상시키고자 했는데 보통 프로브 테스트 결과인 웨이퍼 빈 맵(Bin Map)을 사용해서 제조 결함을 밝혀내고자 하는게 주를 이룬다. 이 경우 칩 단위 품질 예측에 적합하지 않고, 2진 데이터 빈 맵만 처리할 수 있다는 한계가 존재한다. 추가로 반도체의 FBC(Fail Bit Count)정보를 통해 품질을 예측하고자 하는 연구들도 존재했는데 이 경우 FBC 특성을 따르는 품질 문제에만 이용할 수 있다는 한계가 존재했다.
해당 연구들은 칩 단위에서 불량의 종류를 식별할 수 없으며, 사용된 예측 변수도 셀의 결점 수인 FBC 혹은 비교적 단순한 2진 빈 맵이 전부였다. 또한 성능 평가에는 주로 정확도를 사용했는데 이는 불균형이 극심한 반도체 데이터에서 왜곡을 불러일으킬 수 있었으며 민감도를 사용한 경우에도 특이도를 고려하지 않고 민감도만 높인 경우가 많았다.
본 연구는 칩 단위의 반도체 품질을 예측하고 예측된 불량의 종류를 특성별로 나누어 식별한 뒤 최종 품질을 예측하고자 했다.
사용된 독립변수는 전압, 전류, BBC (Bad Block Count), FBC, 동작 신초 측정치 등으로 제품의 특성을 나타내는 중요 계측 값들이다.
-
BBC : 낸드 플래시의 경우 지우기와 쓰기 동작이 통상 블록(Block) 단위로 이루어지며 문제 발생 시, 해당 블록을 결점으로 나타낸다
-
FBC : 비트(Bit) 정보를 저장하는 셀(Cell)영역에 결점이 있을 때 그 결점을 빝느 수로 나타낸 값으로, 해당 칩의 특성을 나타내는 계측값
성능 지표는 ROC-AUC를 사용해서 예측 성능의 왜곡을 피하고 전반적인 영역에서 예측 성능을 비교했다.
2. 군집화 적용 및 품질 예측
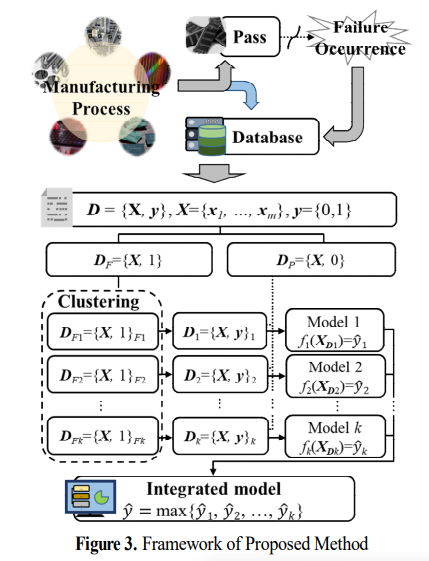
반도체 품질 불량을 특성별로 분류하고 품질 예측을 진행하는 시스템을 구축한 그림은 위와 같다.
제안 방법은 1차적인 데이터 세트 에 대해 먼저 군집화를 선행하여 불량의 특성에 따라 인 데이터셋을 k개의 군집으로 나눈다. 그 후 정상 데이터셋을 k개 군집에 더해서 각각 예측 모델을 통해 k개의 예측치를 얻어낸다. 최종 을 통해 불량 여부를 판단하고 품질 불량이라 판단되면 k개의 군집 중 가장 높계 예측한 군집으로 할당하여 품질 불량 종류에 대해 판단한다.
사용된 데이터는 SMOTE(Synthetic Minority Over-sampling Technique) 기법을 통해 불균형을 해결하였고, AIC(Akaike's entropic Information Criterion)를 척도로 단계적 변수선택 기법을 사용해 로지스틱회귀 예측 모델을 구축하였다. 모든 실험은 10-fold cross-validation 절차를 거쳐 성능을 측정하였다.
2.1 데이터 불균형
불량에 대한 데이터는 불균형이 필연적이기에 언더샘플링과 오버샘플링 방법으로 해결해야한다. 이 때 저자는 소수 범주에 k-최근접 이웃(k-Nearest Neighbor) 기반의 오버샘플링을 적용하는 SMOTE를 사용했다. SMOTE는 초평면(Hyperplane)상 직선 내에 새로운 관측치를 생성하는 것으로, 소수 범주의 결정 경계 확장 효과가 있다. 이를 사용해서 과적합을 줄이고 정보 소실의 위험성을 피할 수 있었다.
2.2 군집화
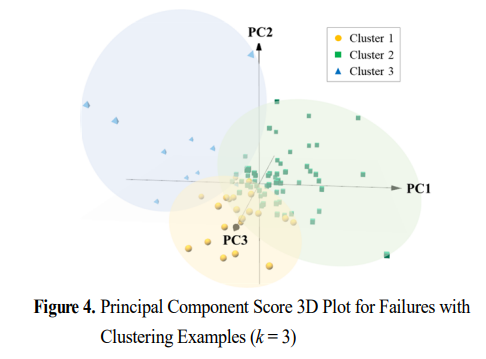
위 그림은 단일 종류의 품질 불량에 대해 PCA를 진행하고 분산 보존 약 20%를 3차원으로 축소하여 나타낸 그래프이다. 이것만 봐도 데이터 특성별로 나뉘는 경향을 가시적으로 확인할 수 있었다.
반도체 불량의 특성상 불량이 같은 항목에서 발생하거나 비슷한 경향을 보이더라도 근본 원인이 상이할 수 있으며, 같은 종류의 불량이지만 주어진 데이터 내에서 특성이 다를 수 있다.
본 연구에서는 이를 구분하여 품질 예측 성능을 향상시키고자 하였고, 사용한 군집화 기법은 k-means 군집화 기법과 Self-Organized Map(SOM)이다.
2.3 품질 예측 모델
반도체 품질 예측에서 제조 공정의 정보는 상호 강한 상관관계를 갖거나, 종속변수에 영향이 없는 독립변수들이 존재하는 경우가 있다.
따라서 독립변수의 선택 없이 예측 모델을 구축한다면 과적합이나 예측 성능의 저하가 있을 수 있다.
저자는 어떤 독립변수의 집합들이 좋은 예측 성능을 보이는지 판단하기 위해 AIC를 사용하였고, 이는 데이터를 가장 잘 나타내는 분포와 모수를 결정하는 방법이다.
좋은 독립변수 집합을 찾기 위해 단계적 선택법(Stepwise Selection)을 사용했으며 이는 단방향 방법 대비 상대적으로 계산 시간이 복잡하나, 좋은 독립변수 집합을 찾을 확률이 보다 높다.
예측 모델은 로지스틱회귀 방법을 사용하여 이진 분류를 수행했으며, 추정된 계수(Coefficient)가 Log odds ratio로 표현 가능하므로 품질 예측에서 불량과 독립변수와의 관계 해석에 직관적인 장점이 있다. 또한 임계치(Threshold)로 조절하여 반도체 물량 환경에 맞춰 조정이 가능하다는 장점이 있다.
3. 데이터 및 성능 척도
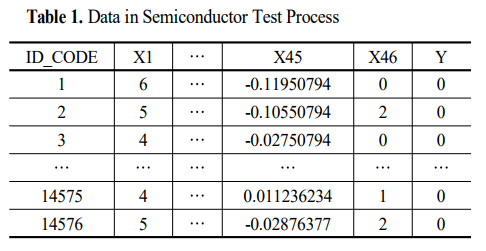
실험에 사용된 데이터는 위와 같이 반도체 테스트 공정의 계측치인 동작 신호 측정치, 전기적 특성치, BBC, FBC 등으로 구성되어, 독립변수 46개, 정상 관측치 14,489개, 비정상 관측치 87개로 되어있다.
성능 평가 척도는 ROC-AUC를 사용했다.
4. 실험 결과
4.1 군집화 결과
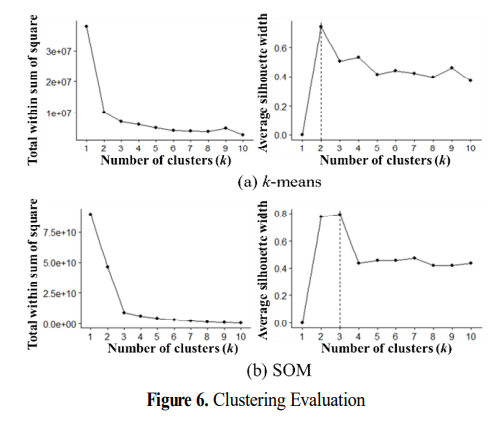
제곱합의 Elbow point와 평균 실루엣을 통해 k-means의 경우 군집수 2, SOM의 경우 군집수 3이 최적임을 찾아냈다.
4.2 품질 예측 성능 비교
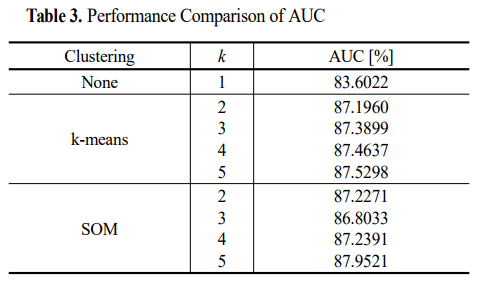
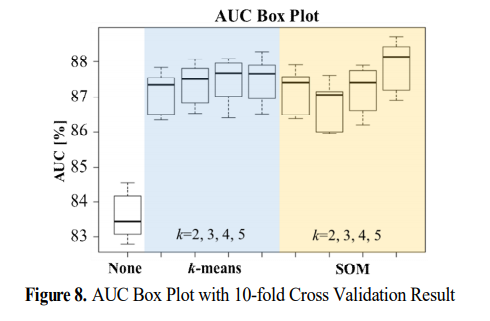
군집화를 활용했을 때가 활용하지 않았을 때에 비해 품질 예측 성능이 향상됨을 확인했다.
