
본 게시물은 고려대학교 스마트생산시스템 연구실 2023년 동계 신입생 세미나 활동입니다.
Michigan 대학의 Justin Johnson 교수님의 강의를 공부하는 형식입니다.
관련 유튜브 영상은 여기에서 확인 가능합니다.
Lecture 12: Recurrent Networks 강의에서는 배울 수 있는 내용은 다음과 같습니다.
- Recurrent Neural Networks
- RNN Computational Graph
- Truncated Backpropagation Through Time
- Searching for Interpretable Hidden Units
- Image Captioning
- Long Short Term Memory(LSTM)
Recurrent Neural Networks
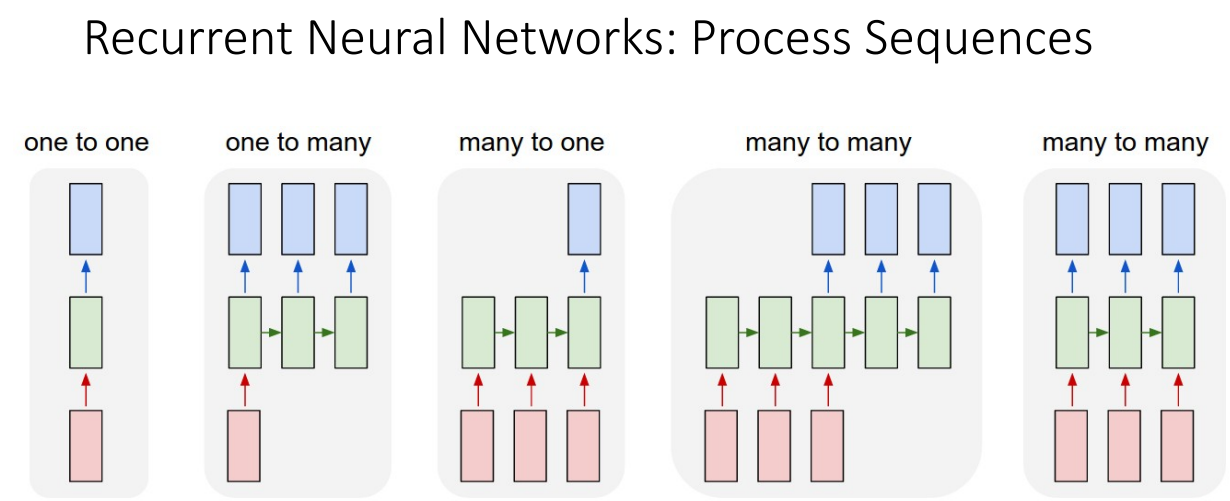
Recurrent Neural Networks(RNN)은 시계열적인 데이터를 처리할 때 유용한 네트워크 입니다.
Input과 Output 종류에 따라 5가지 정도로 나눌 수 있습니다.
- one to one: 이건 RNN은 아니고, 하나의 input이 들어가서 하나의 output이 나오는 경우입니다. 대표적으로 Image classification이 있습니다.
- one to many: 하나의 input이 들어가서 여러개의 output이 나오는 경우입니다. 대표적으로 Image Captioning이 있습니다.
- many to one: 여러개의 input이 들어가서 하나의 output이 나오는 경우입니다. 대표적으로 Video classification이 있습니다.
- many to many(1): 여러개의 input이 들어가서 여러개의 output이 나오는 경우 중 첫번째입니다. 이 경우는 여러 input들이 인코딩된 후 여러 output들이 디코딩되는 경우입니다. 대표적으로 Machine Translation이 있습니다.
- many to many(2): 여러개의 input이 들어가서 여러개의 output이 나오는 경우 중 두번째입니다. 이 경우는 여러개의 input이 들어갈때 각각의 input에 해당하는 output이 나오는 경우입니다. 대표적으로 Per-frame video classification이 있습니다.
RNN은 대표적인 Sequence를 다루는 네트워크지만, 해당 아이디어만 유지한다면 Non-Sequential한 데이터도 다룰 수 있습니다.
Image classification
이미지를 glimpse의 집합으로 생각해서 분류하는 작업입니다.여기서 glimpse는 잠깐 본다는 의미로 이미지의 각 부분을 보고 sequence처럼 분류하는 것입니다.
이미지를 painting little sequence 개념으로 그려나가며 분류하는 경우에도 sequence처럼 볼 수 있기 때문에 RNN을 활용할 수 있습니다.
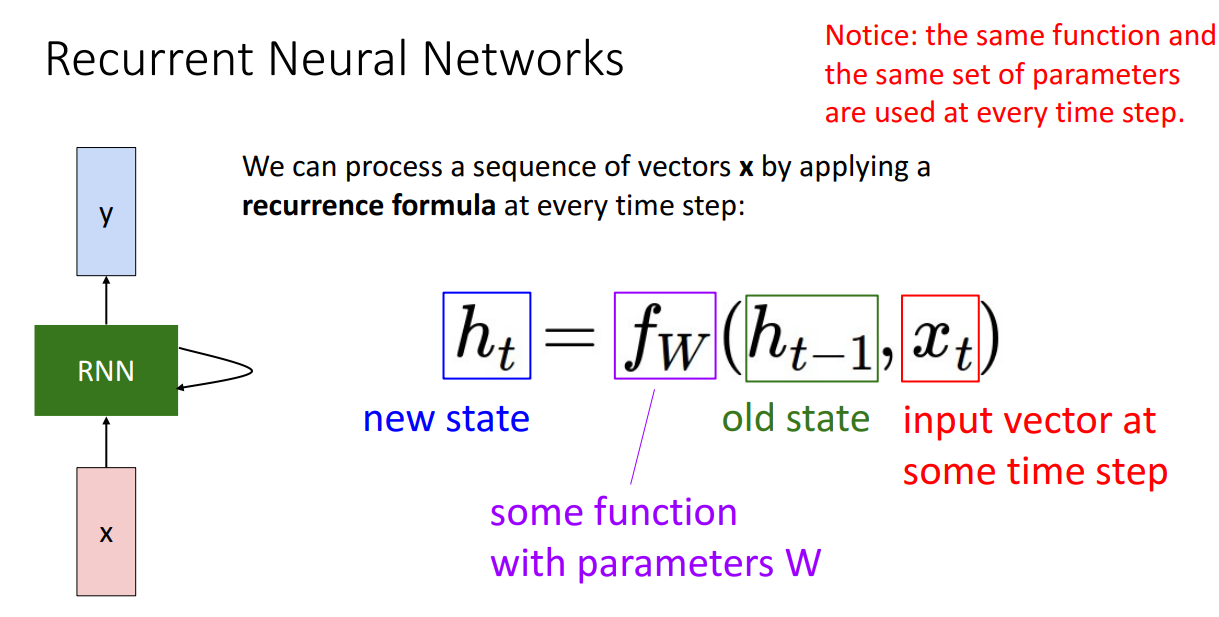
RNN이 무엇인지 자세하게 살펴보겠습니다.
RNN 네트워크 구조를 보시면 중간에 internal state가 있는데 sequence가 진행되면서 update됩니다.
다음으로 수식을 보시면 로 hidden state가 이전의 hidden state와 현재 시점의 input vector에 의해 결정되는 것을 알 수 있습니다.
그리고 특정한 함수를 사용하는데 해당 함수는 learnable weights인 W를 가지고 있습니다.
여기서 주목할 점은 해당 함수가 사용하는 W는 t에 무관하다는 점입니다.
즉 모든 time step에서 동일한 Weight을 Sharing하게 됩니다.
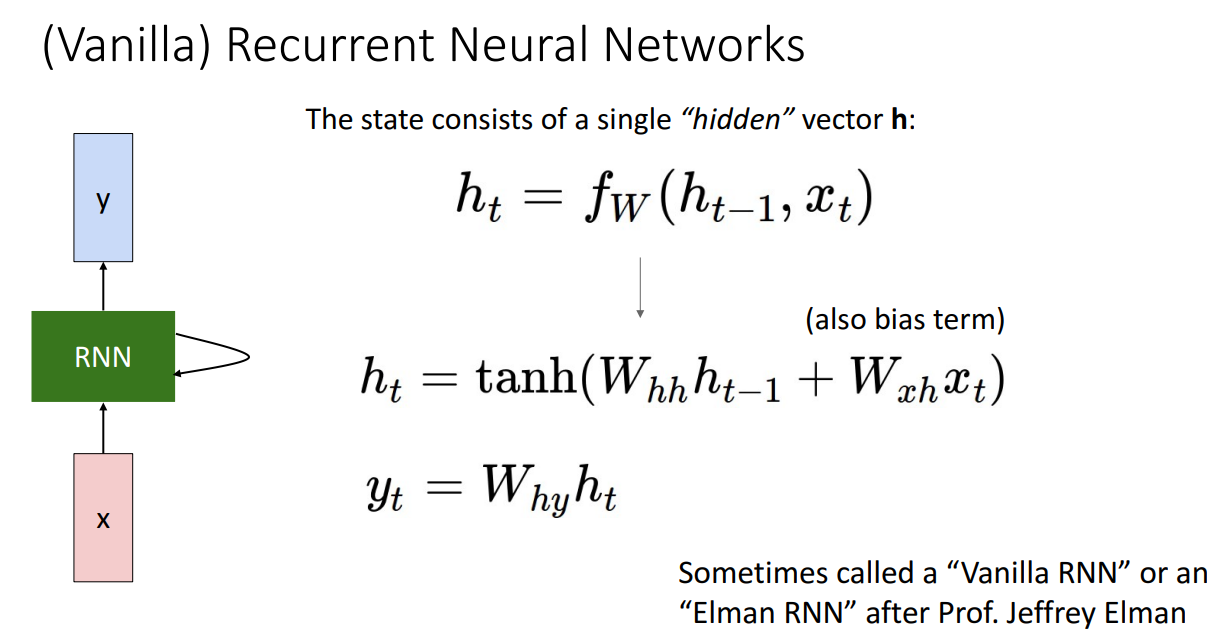
해당 수식에서 특정한 함수를 를 곱한후 더하여 tanh 거치는 수식으로 정해준다면 끝입니다.
해당 구조를 Vanilla RNN 혹은 Elman RNN이라고 부릅니다.
RNN Computational Graph
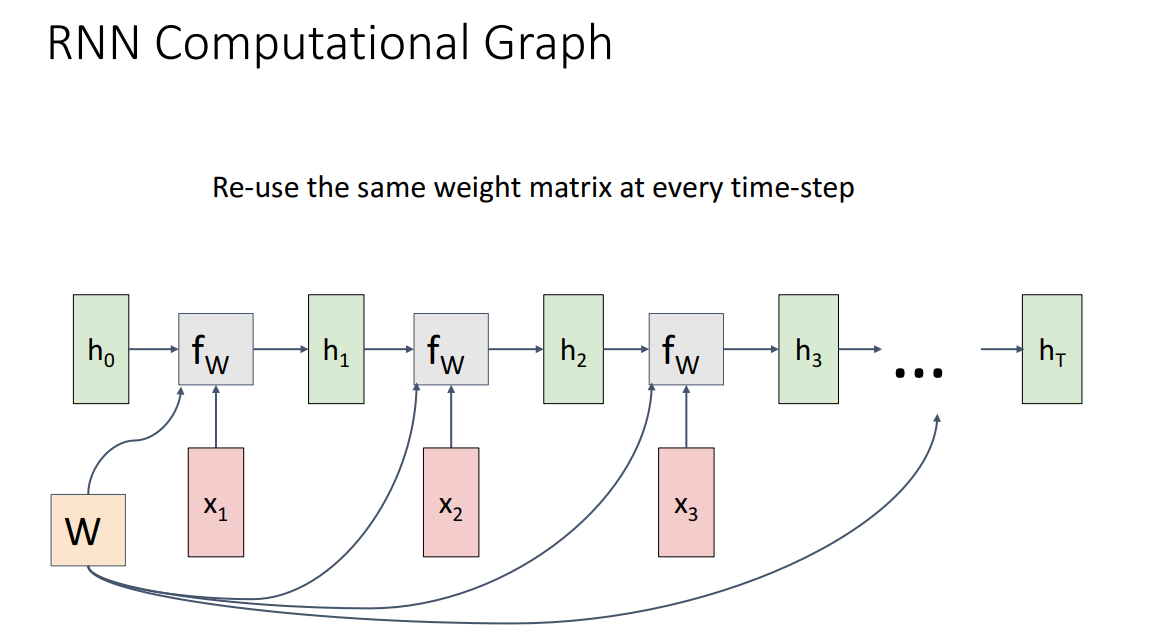
RNN 구조를 Computational Graph를 통해서 살펴보면 위와 같습니다.
initial hidden state를 0으로 두거나 학습의 대상으로 둬서 셋팅해놓습니다.
앞서 봤듯이 Weight matrix는 모든 time-step에서 공유하게 됩니다.
즉 Weight을 copy해서 사용하는 모습이 되고, 역전파 시 gradient를 sum해주는 방식으로 간단하게 계산 가능합니다.
이렇게 위와 같이 만들어진 구조를 해결하고자 하는 downstream task에 맞게 output을 산출하도록 하면 끝입니다.
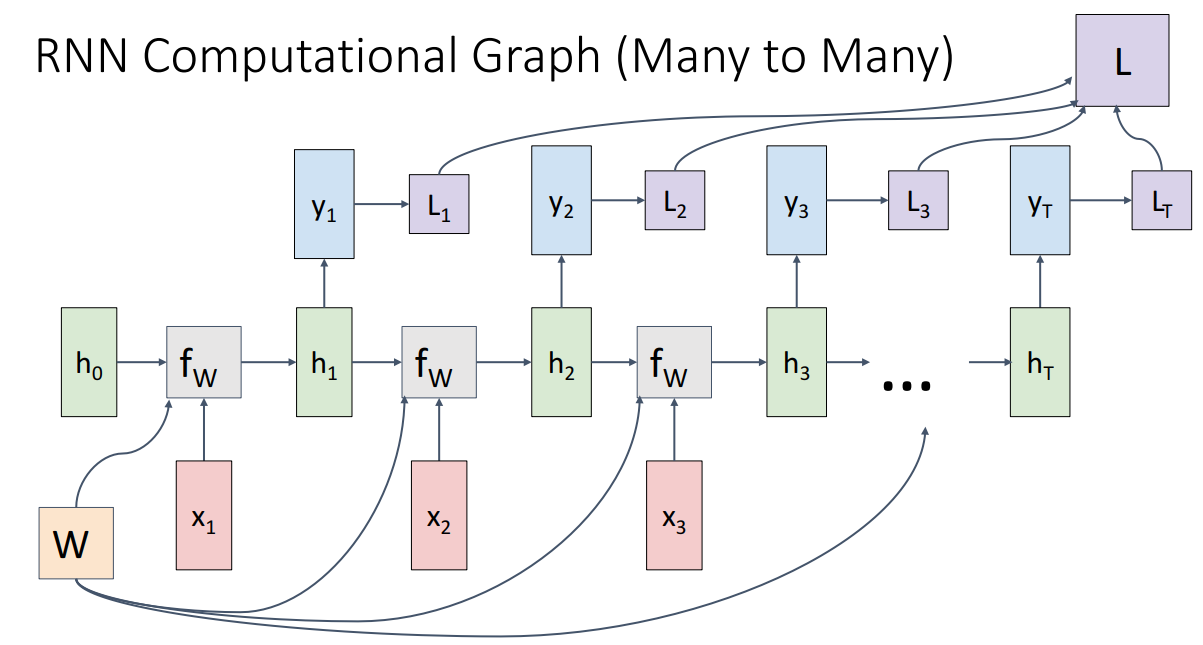
Per-frame Video Classification의 경우 하나의 input에 따라 하나의 output이 산출되었어야합니다.
해당 아이디어에 따라서 네트워크를 구성하면 위와 같습니다.
하나의 output에 해당하는 Loss가 구해지고 모든 time-step에서의 Loss를 합하여 최종 Loss를 산출하게 됩니다.
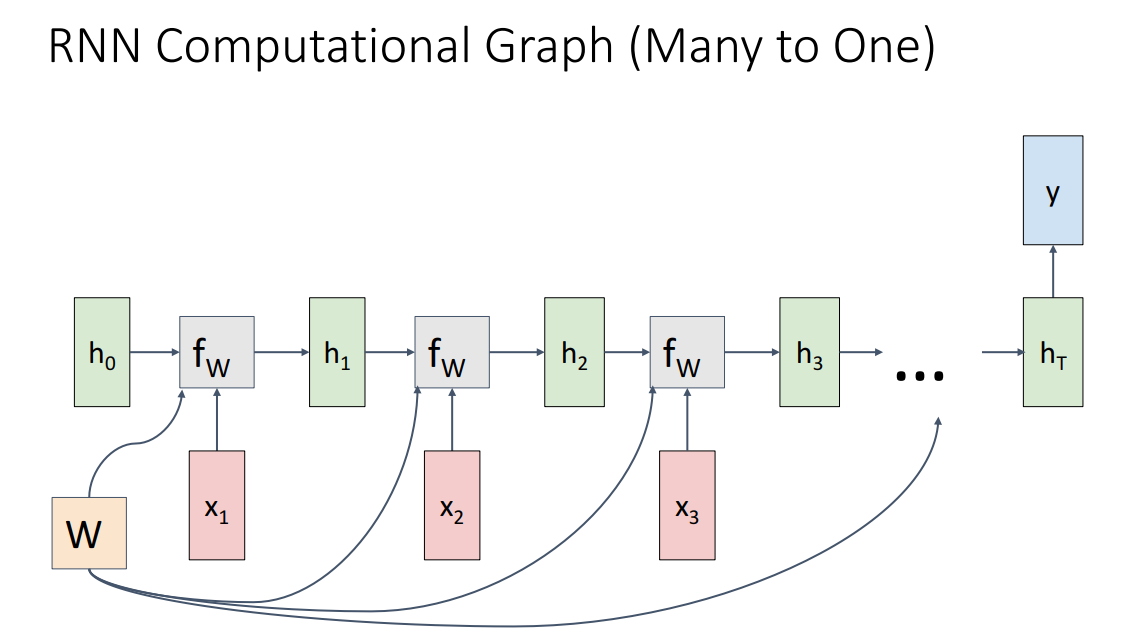
여러개의 input이 들어가서 하나의 output이 나오게되는 경우입니다. 이 경우는 대표적으로 Video classification이 있습니다.
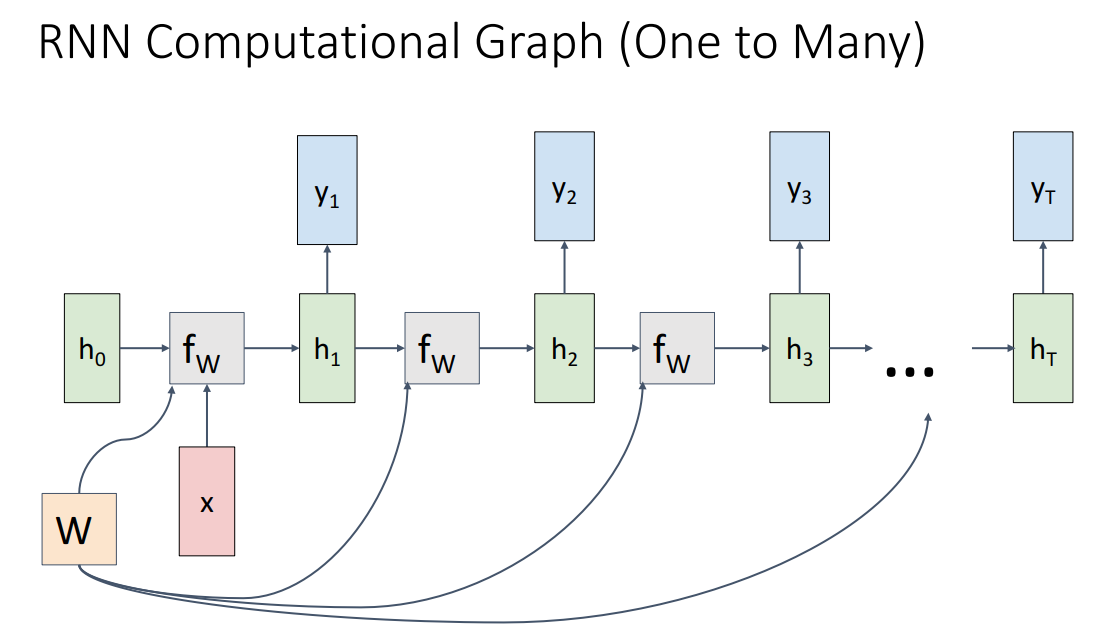
하나의 input이 들어가고 여러개의 input이 나오는 구조입니다. 대표적으로 Image Captioning이 있습니다.
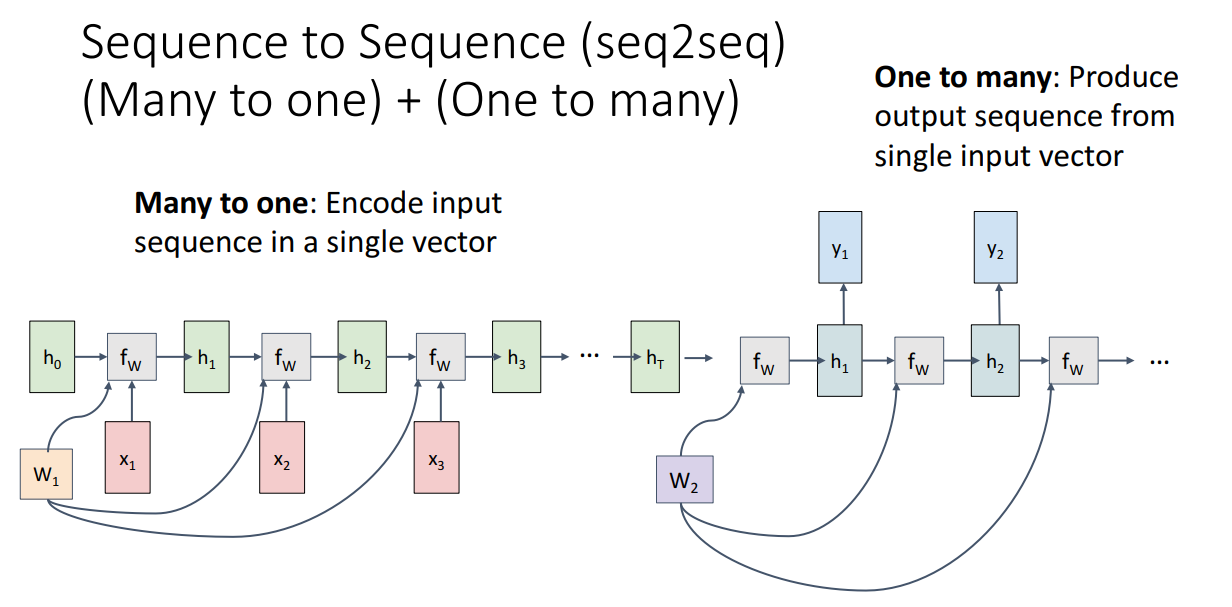
앞서 설명드렸는 Many to many는 두 가지 상황이 있습니다. 그 중에서 여러개의 input이 들어가서 인코딩된 다음 여러개의 output을 디코딩하는 상황이 즉 Machine Translation 상황이 있습니다.
해당 경우에 특별히 Sequence to Sequence (seq2seq)로 불립니다.
여러개의 input이 들어가서 하나의 vector인 로 summarize됩니다.
Summarize된 로부터 여러개의 output들이 나옵니다.
Encoder-Decoder 구조로 설정한 이유는 input token의 개수와 output token의 개수가 다를 수도 있기 때문입니다.
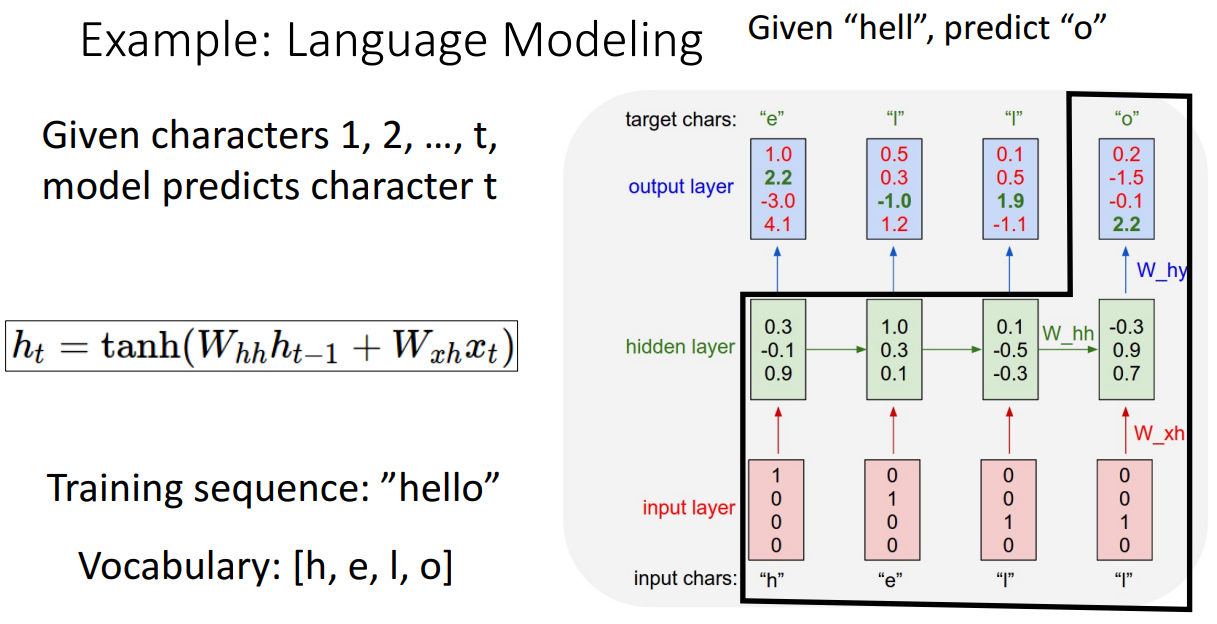
Language Modeling 예시를 보시면 이해가 쉽습니다.
먼저 Vocabulary를 one-hot vecotr로 바꾸어서 input으로 활용합니다.
해당 네트워크는 input이 주어졌을 때 다음에 올 element를 맞히는 Task를 수행하도록 학습됩니다.
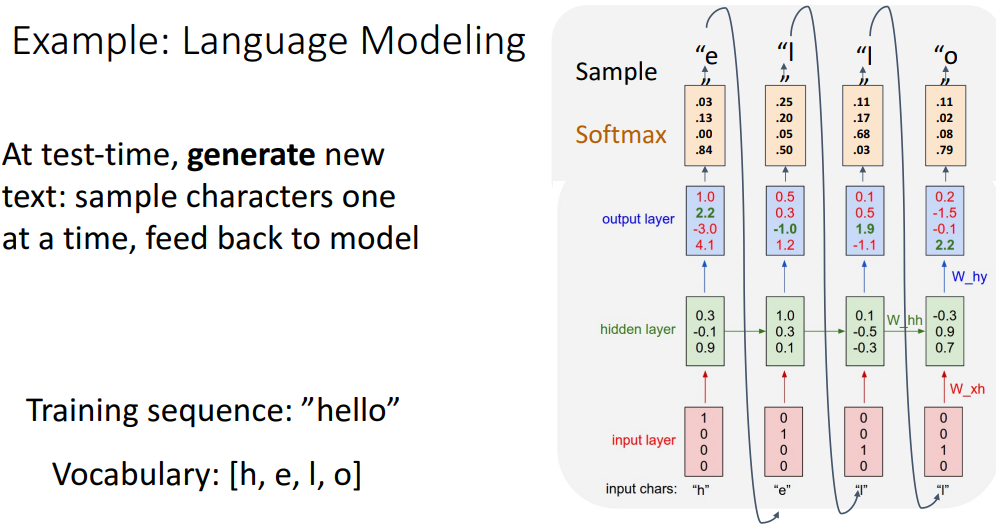
학습이 잘 이루어진다면 seed token으로 "h"만 주어져도 다음 글자인 "e"를 잘 얻어내고,
얻어낸 "e"를 다시 input으로 사용해서 다음 글자를 얻어내고 해당 과정을 반복해서 단어를 생성해낼 수 있게 됩니다.
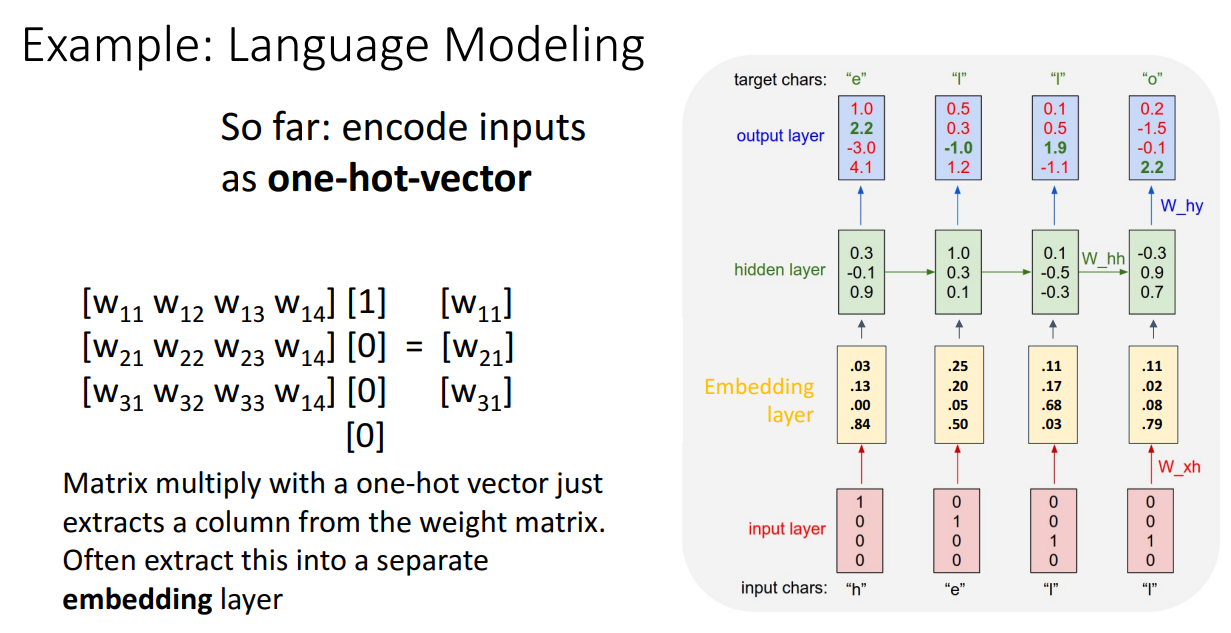
one-hot vector를 행렬곱하는 것은 너무 trivial 합니다.
따라서 행렬곱 대신에 특정 위치 요소 추출하는 방식을 사용하는 것이 좋고,
one-hot vector를 통해 바로 hidden layer를 구하는 것보다는 Embedding layer를 하나 더 도입해서 hidden layer를 구하기도 합니다.
Truncated Backpropagation Through Time
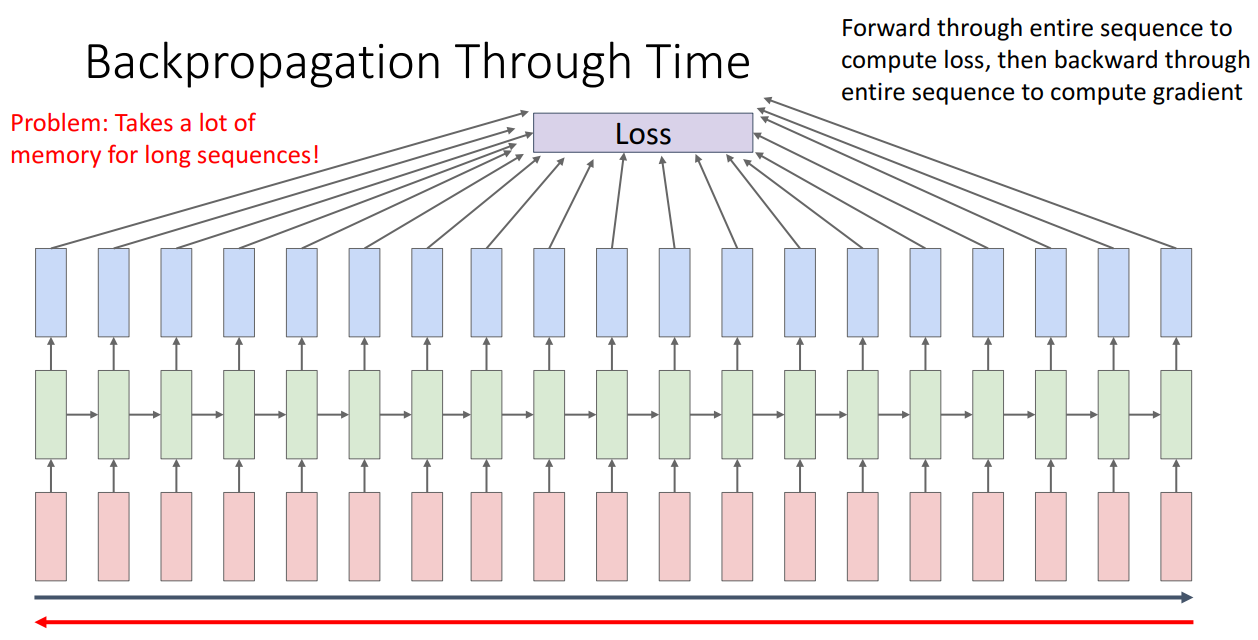
RNN 구조의 단점이 하나 있습니다.
Sequence가 길어질 수록 역전파 시에 너무 많은 메모리를 잡아먹게됩니다.
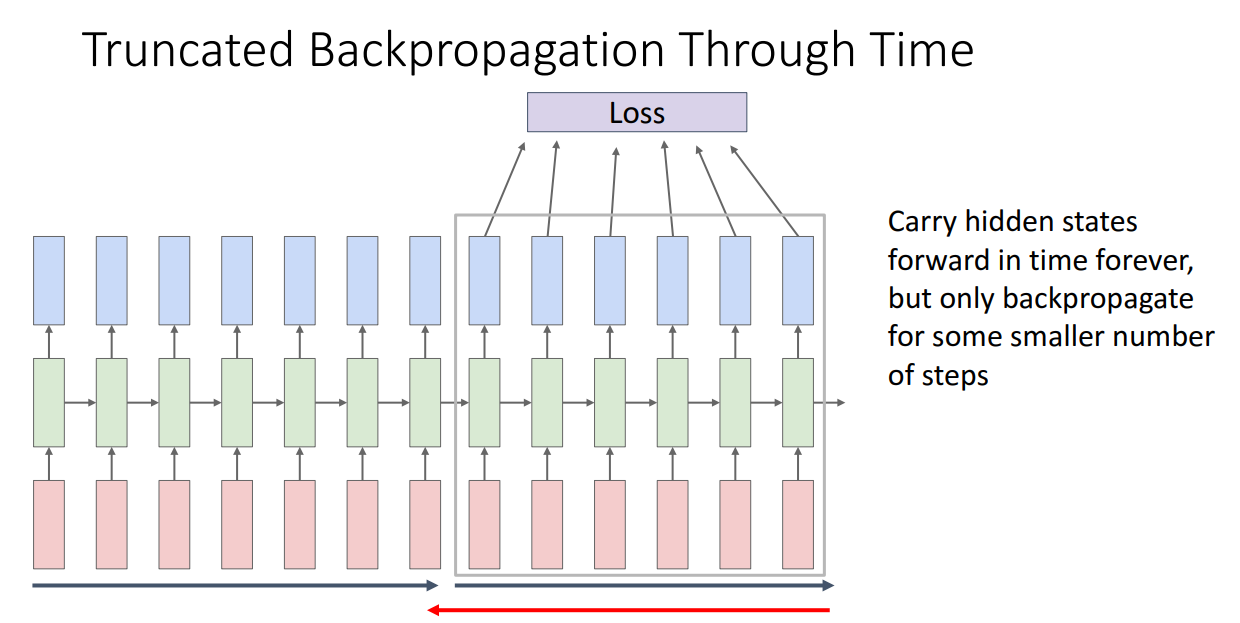
이를 극복하기 위해 도입한 방식이 Truncated Backpropagation Through Time 입니다.
순전파할때는 끊임없이 보내고, 역전파할 때만 chunk로 잘라서 역전파하는 방법입니다.
이렇게 학습을 수행한다면 GPU memory가 한정적이어도 RNN을 돌릴 수 있게 됩니다.
해당 방법에 대한 코드가 강의에서 제시되는데 112 줄로 그렇게 길지는 않습니다.

RNN 모델이 학습이 잘된다면 문장도 잘 만들어낼 수 있습니다.
위 그림은 셰익스피어의 작품을 학습시키고 추론시에 생성해낸 모습입니다.
학습 초기에는 아예 인식할 수도 없는 Random한 값이 생성됩니다.
조금 더 학습을 진행하면 structure in text를 인식할 수 있게 됩니다.
조금 더 학습을 진행하면 거의 문장이 되었고, spelling error만 존재하는 수준입니다.
조금 더 학습을 진행하면 grammarly하게 perfect하지는 않지만 정말 괜찮은 결과가 나옵니다.
이 밖에도 Justin Johnson 교수님께서는 선형기하학 교재의 latex 소스를 학습에 사용해서 정말 수학 교재같은 결과도 뽑아내셨습니다.
Linux kernel의 C source code를 학습에 사용해서 C 코드를 생성해낸 결과도 인상적이었습니다.
Searching for Interpretable Hidden Units
RNN의 재밌는 점이 있습니다.
Next character를 찾기 위한 네트워크를 학습시켜본다면 hidden state 내부에는 다양한 기능을 갖도록 학습이 이루어진다는 것입니다. 다양한 예시를 들어보겠습니다.
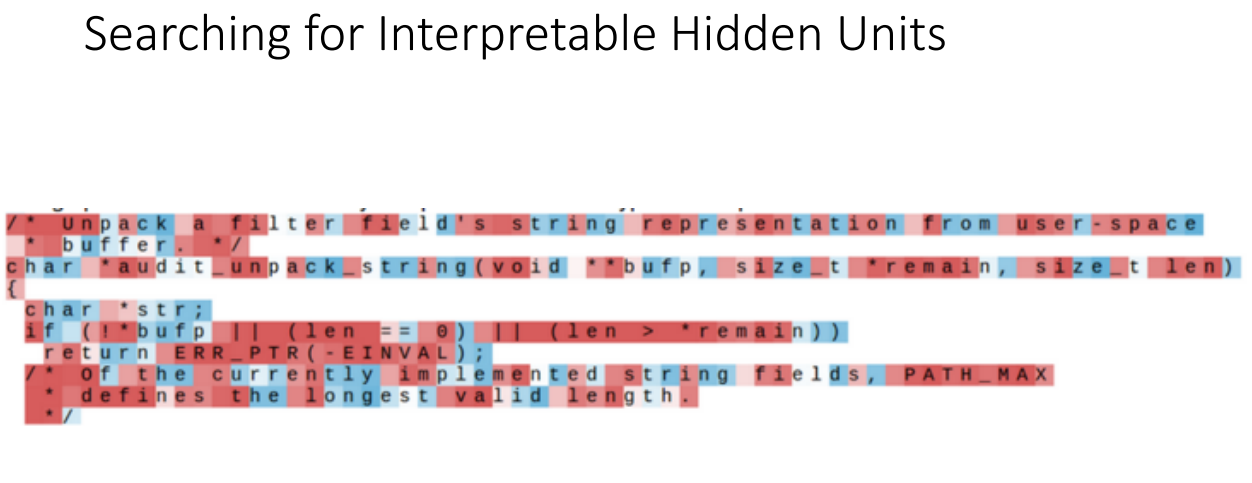
빨간색에 가까워질수록 1, 파란색에 가까워질수록 -1입니다.
즉 빨간색이 해당 hidden state가 집중한 부분입니다.
위 예시는 톨스토이의 작품을 학습시킨 결과이며, 대부분의 hidden state가 보여주는 모습으로 어디에 주목한지는 모르는 상황입니다.

하지만 앞선 상황과 다르게 정말 특정 부분에만 집중해서 예측을 진행하는 cell들이 있습니다.
위 경우는 quote detection cell로 인용하는 파트에만 집중합니다.

위 경우를 보시면 문장의 끝부분에만 집중하는 cell의 모습을 볼 수 있습니다.
해당 cell은 line length tracking cell로 문장이 80자가 넘으면 다음으로 가는 것을 고려하는 cell 입니다.
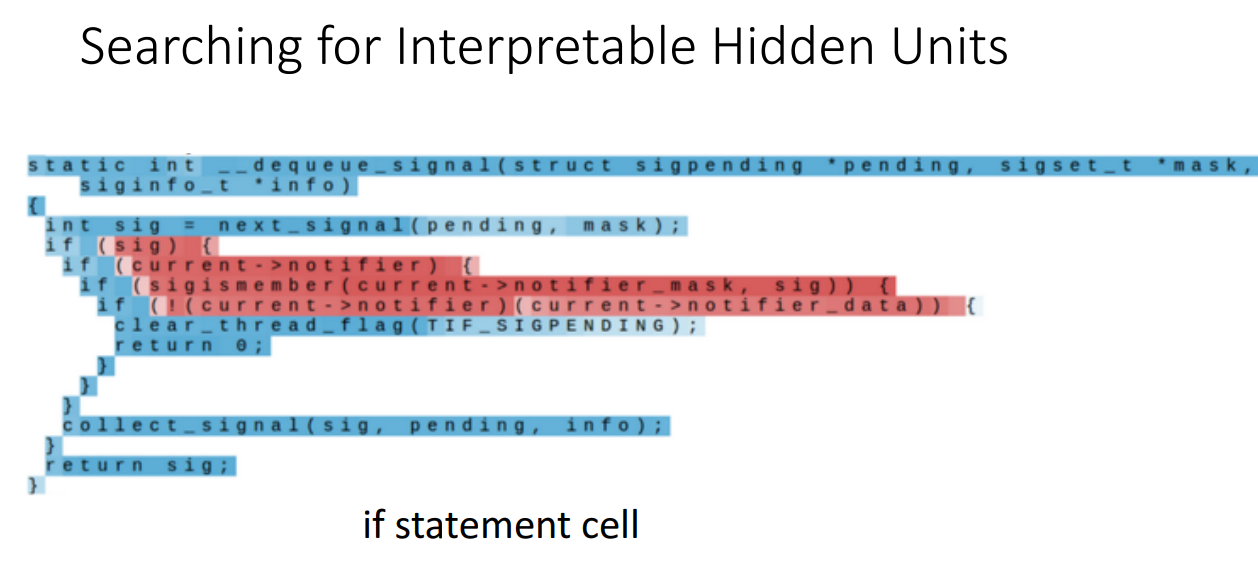
위 경우는 if문에서 들여쓰기 한 부분만을 집중하는 cell입니다.
Image Captioning
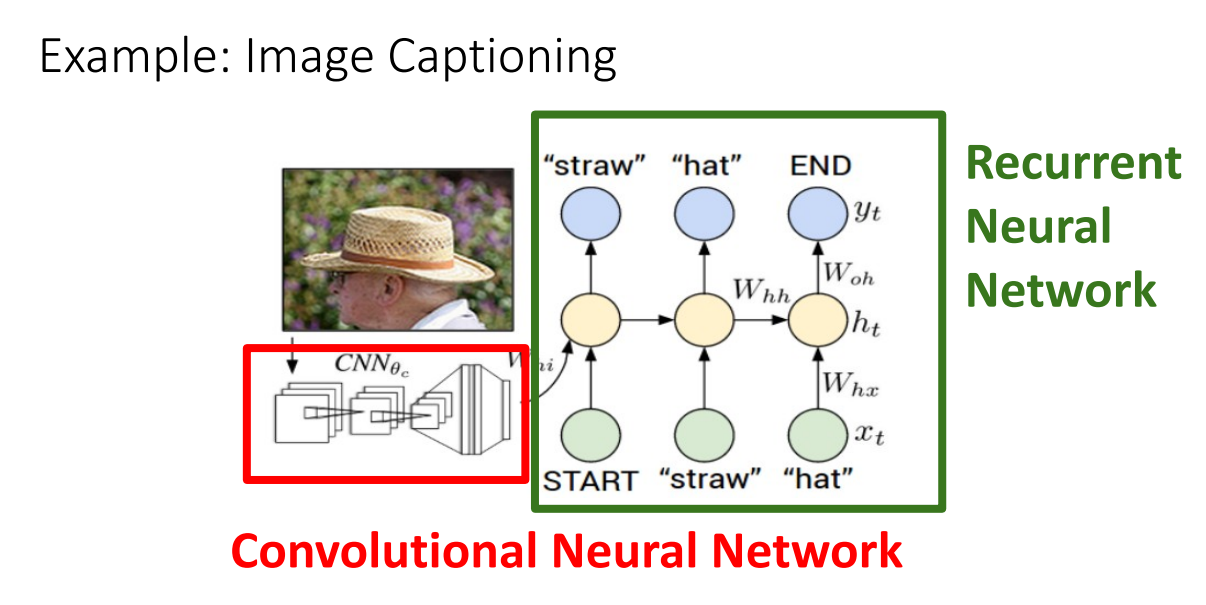
CNN 파트에서 잠깐 나오긴했는데, CNN과 RNN을 함께 사용하여 Image Captioning을 수행할 수 있습니다.
Image Captioning의 경우 다른 RNN 구조들과는 다르게 actual start & actual end 지점을 알아야 합니다.
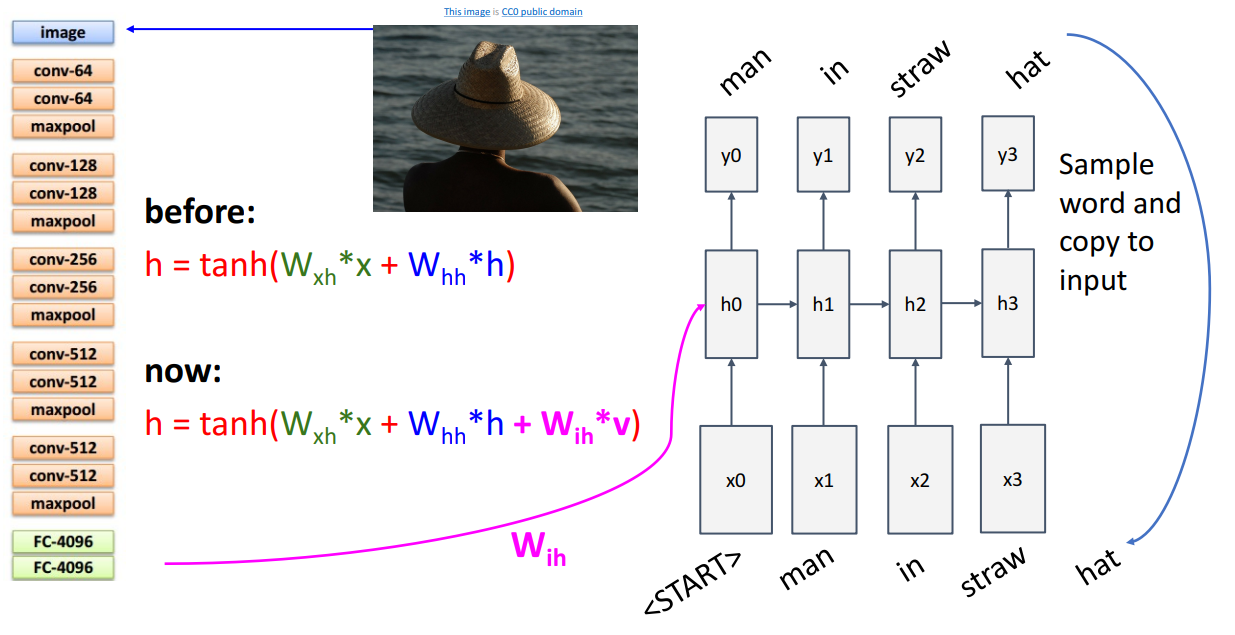
이런 네트워크 구조로 Image Captioning이 진행되는데요.
기존 RNN에 추가된 term은 로 input과 weight 외에도 CNN 네트워크를 통해 추출된 feature을 입력으로 받는 것을 알 수 있습니다.
그리고서는 유사합니다. <"START"> token이 주어지면 다음으로 나올 단어를 예측하고,
예측된 단어는 그 다음 입력으로서 사용되고 최종적으로 <"END"> token이 나오면 문장이 종료됩니다.

학습이 잘되면 위 그림처럼 어마무시한 결과를 얻을 수 있습니다.
Long Short Term Memory(LSTM)
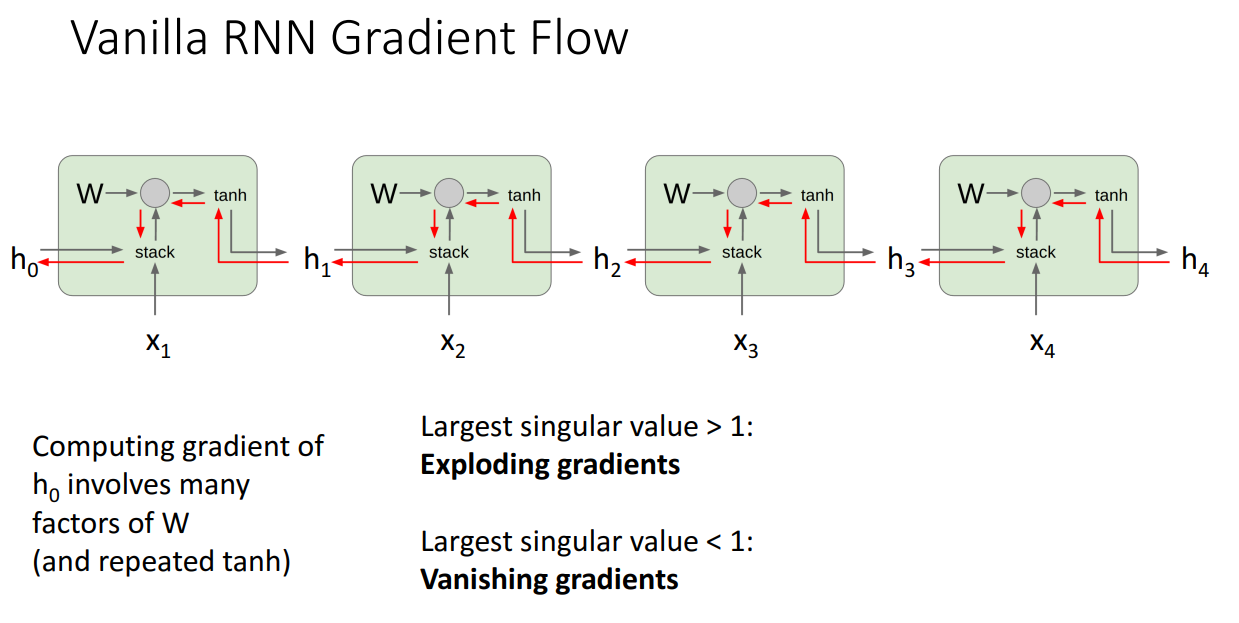
Vanilla RNN은 사실 그렇게 성능이 좋지 않습니다.
이유를 말씀드리면 두 가지 정도 있습니다.
1. tanh 함수가 역전파시에 별로입니다. ReLU를 사용하는 이유가 되겠지요.
2. 역전파시에 동일한 W 행렬을 계속해서 곱해나가야합니다.
두번째 이유가 치명적인데요.
Sequnce의 길이가 길어질수록 즉 hidden state가 길어질수록
똑같은 행렬을 반복해서 곱해나가는 것은 메모리 상으로도 별로지만 성능에 큰 악영향을 미칩니다.
위 그림처럼 계속 곱해나갈때 max(singular value)>1이면 기울기가 폭발합니다.
반대로 max(singular value)<1이며 기울기가 소실되어버립니다.
기울기 폭발 문제는 Gradient clipping으로 해결 가능하긴 합니다.
해당 아이디어는 기울기 폭발 문제를 막기 위해서 일부로 틀린 gradient를 학습에 사용하는 방식입니다.
다음으로 기울기 소실 문제를 해결하기 위해서는 또다른 RNN 구조, 그렇지만 더 많이 사용되는 구조인 LSTM을 사용하면 됩니다.
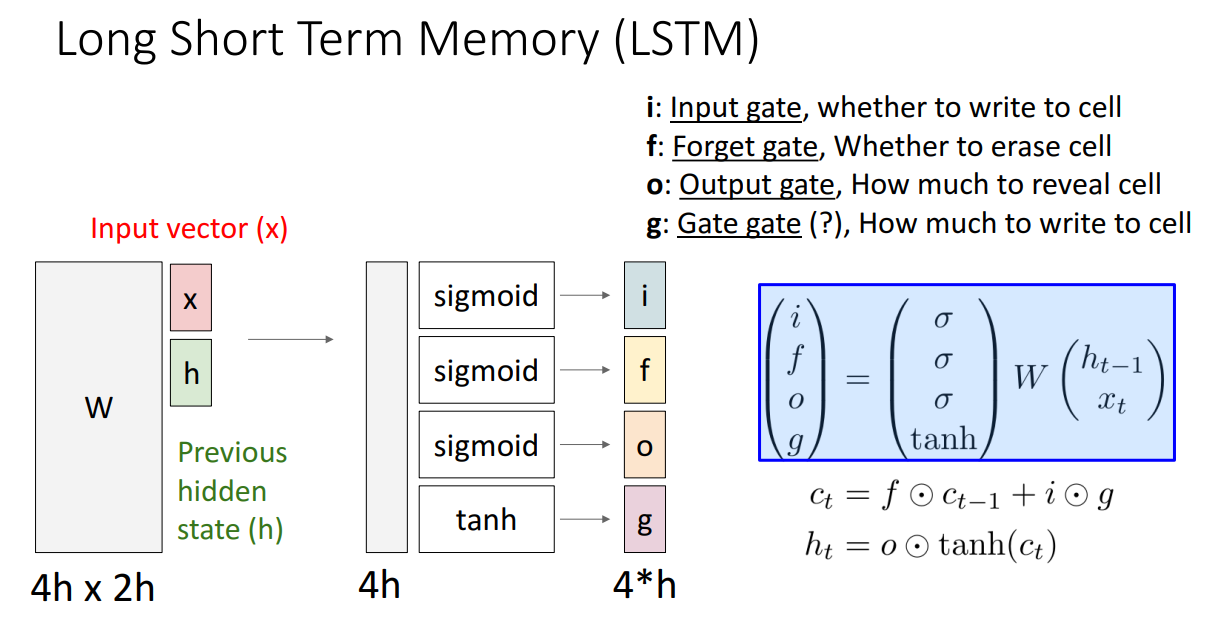
LSTM의 구조는 위와 같습니다.
RNN과 다르게 두 개의 다른 hidden vector를 사용합니다.
Cell state와 Hidden state입니다.
그리고 추가로 4개의 gate를 사용합니다.
각 state의 기능을 살펴보면 다음과 같습니다.
1. i: Input gate, cell에 쓸지 여부
2. f: Forget gate, cell 삭제할지 여부
3. o: Output gate, cell을 표시할 양
4. g: Gate gate, cell에 얼마나 쓸지
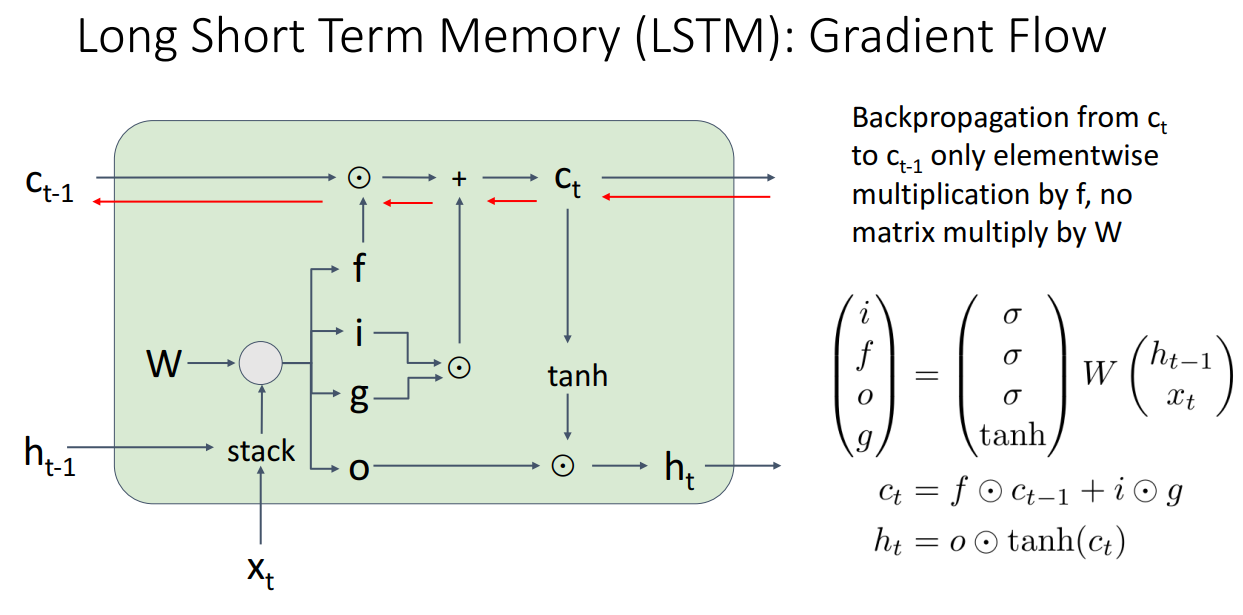
구조가 복잡하게는 생겼으나 에서 로 역전파 하는 과정은 오직 elementwise 곱밖에 존재하지 않아서 행렬곱을 할 필요가 없습니다.
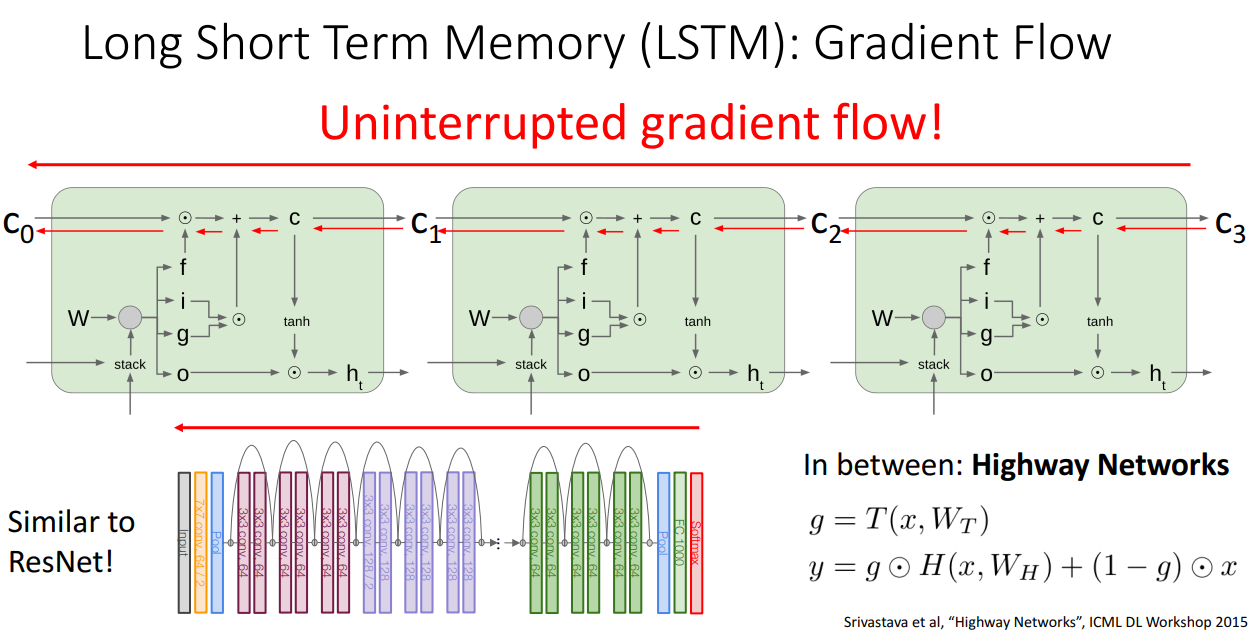
따라서 역전파시에 이처럼 수월하게 넘길 수 있게됩니다.
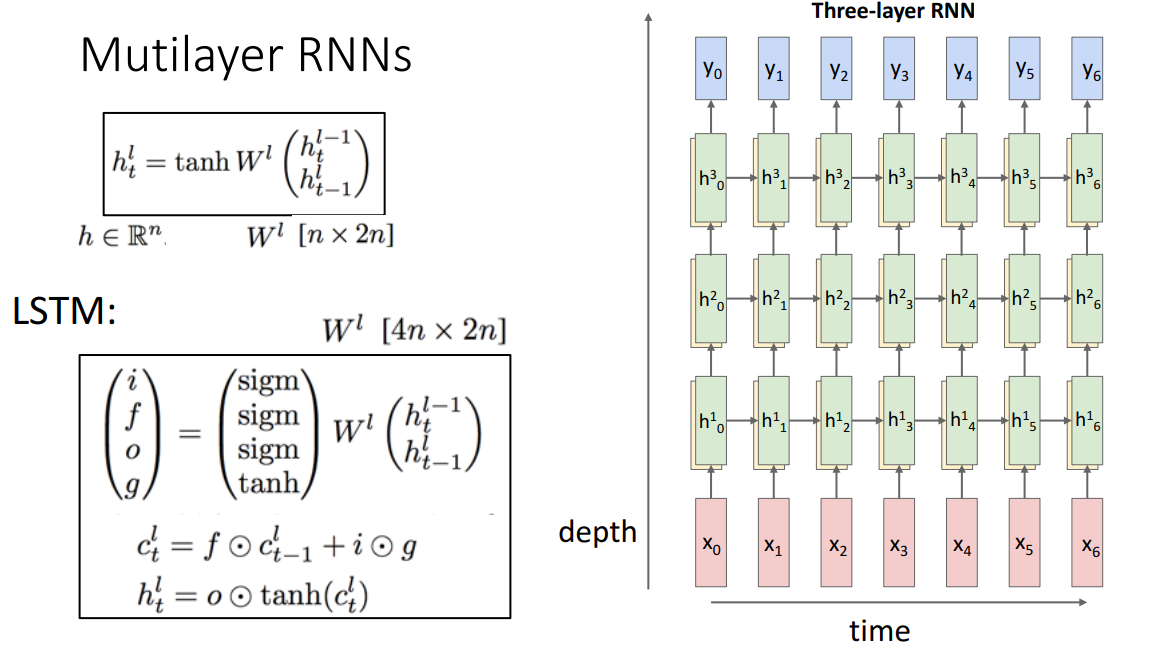
RNN의 경우 hidden state를 깊게 쌓을수도 있는데 교수님께서는 RNN 자체가 deep하게 쌓을만한 모델을 아니라고 설명해주셨습니다.

이밖에도 LSTM의 Simple version인 GRU도 존재합니다.
