
본 게시물은 고려대학교 스마트생산시스템 연구실 2023년 동계 신입생 세미나 활동입니다.
Michigan 대학의 Justin Johnson 교수님의 강의를 공부하는 형식입니다.
관련 유튜브 영상은 여기에서 확인 가능합니다.
Lecture 11: Training Neural Networks II 강의에서는 배울 수 있는 내용은 다음과 같습니다.
- Learning Rate Schedules
- Choosing Hyperparameters
- Learning Curves
- Model Ensembles
- Transfer Learning
- Distributed Learning
Learning Rate Schedules
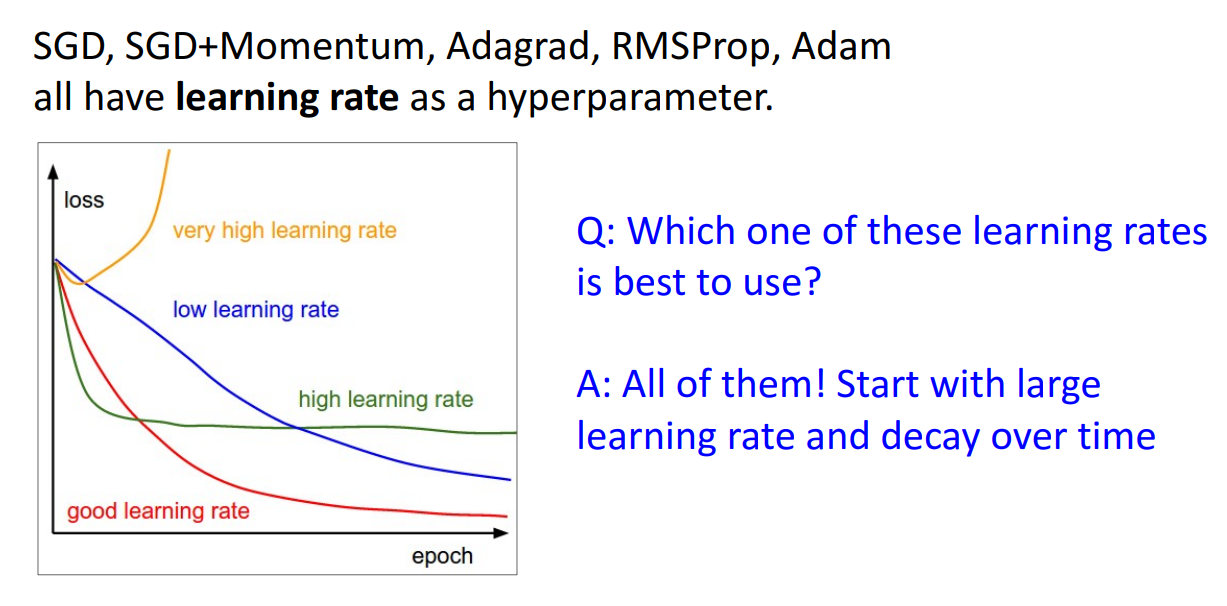
학습률은 대부분의 최적화 방법론에서 하이퍼파라미터입니다.
그렇다면 사용자가 직접 지정해줘야하는 값인데 위 표를 보시면 어떤 크기로 설정할지 고민해야합니다.
만약에 학습률이 너무 크다면 gradient가 폭발해버려서 loss가 치솟게 됩니다.
학습률이 낮다면 학습이 너무 느려집니다. 학습률이 적당히 높으면 빠르게 수렴할 수는 있지만 Global minimum으로 가지는 못합니다.
적절한 숫자로 학습률을 잘 정한다면 빠르면서 수렴도 잘합니다.
그렇다면 적절한 숫자를 잘 고르면 될까요?
교수님은 사실 그럴 필요가 있나? 지적해주시면서 High → Low 학습률로 사용해서
빠르게 수렴하고 적절하게 수렴도 잘하자는 식으로
장점만 다 가져다가 쓰면 된다는 전략을 보여주십니다.
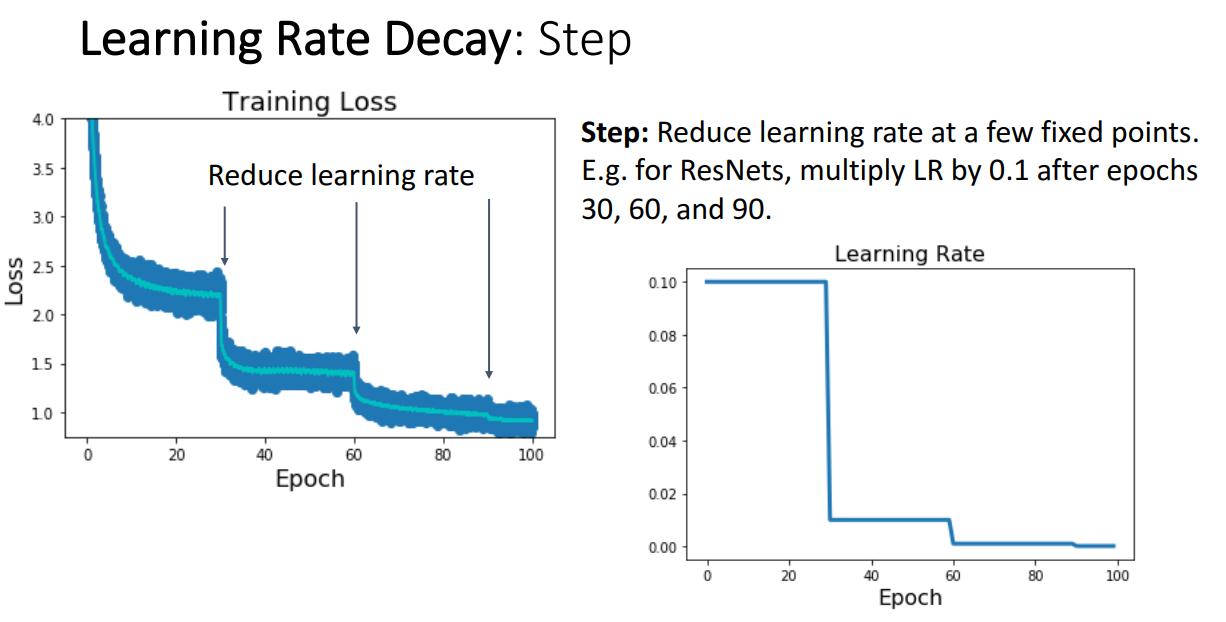
높은 학습률을 차근차근 줄여나가면서 학습을 진행하는 첫번째 방식으로 Step Learning rate Decay 입니다.
위 그래프 예시는 30 epoch 이 지날 때마다 LR에 0.1씩 곱해서 작게 만듭니다.
이러한 학습률 전략을 택한다면 Epoch 이 흐를수록 Loss 값이 계단처럼 줄어드는걸 볼 수 있습니다.
교수님께서는 학습 진행에 따라 Loss가 줄어드는 그래프를 산점도를 통해서 보여주고,
해당 산점도에서 Moving average를 line 그래프로 그려서 전체적인 추세를 보여줍니다.
Step 방식으로 학습률을 줄여나가면 몇 가지 정해야할 하이퍼파라미터가 있습니다.
처음 시작할 때 LR, 얼마나 곱해서 줄일건지, 언제마다 줄일건지.
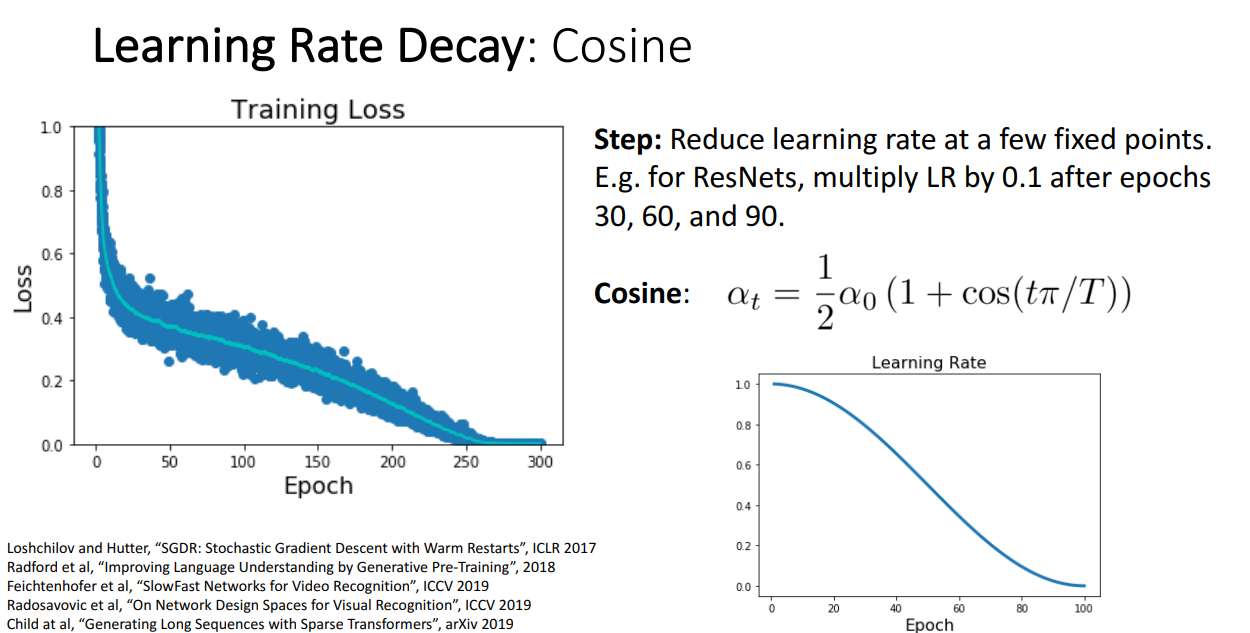
다음으로 교수님께서 추천하시는 방식은 Cosine 함수식에 따라서 학습률을 줄여나가는 방식입니다.
한동안 인기있는 방법이었고, Step 방식보다 하이퍼파라미터가 적어서 튜닝하기도 쉽고 성능도 괜찮다고 합니다.
정해줄 하이퍼파라미터는 와 입니다.
Computer Vision에서 많이 사용하는 방식입니다.
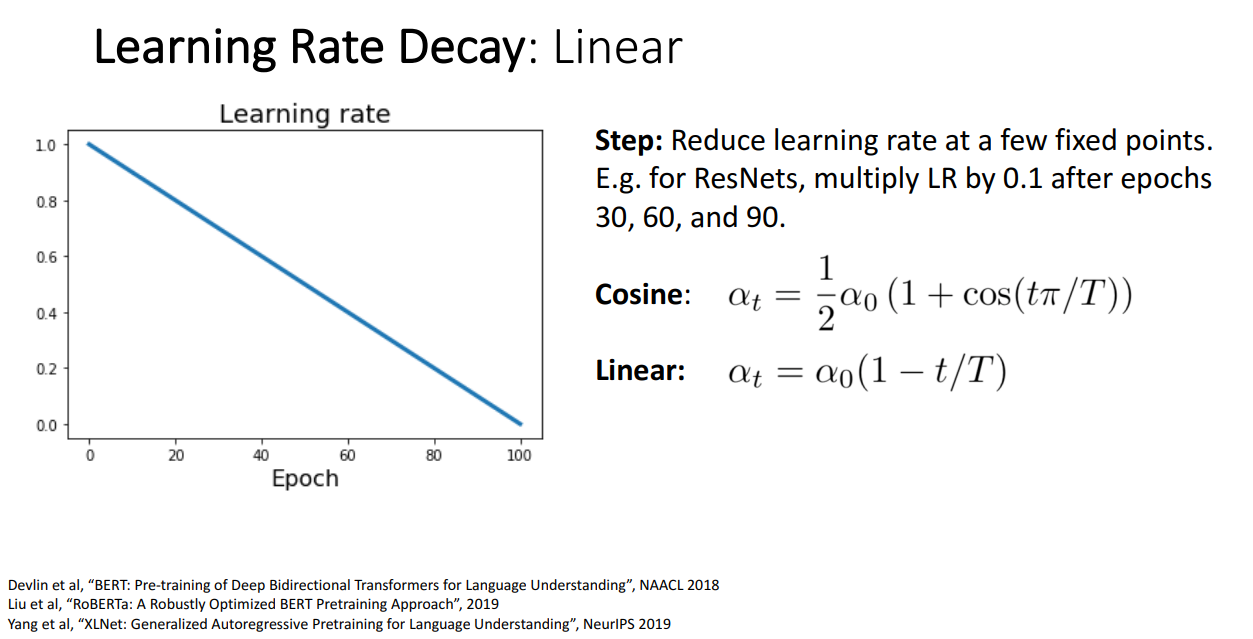
Cosine 함수식에 따라서 학습률을 줄이는 방식과 유사하지만, 훨씬훨씬 쉬운 방식은
그냥 Linear하게 학습률을 줄여나가는 것입니다.
정해줘야할 하이퍼파라미터도 Cosine 함수식과 같고 성능도 유사해서 누가 더 좋은지는 모릅니다.
다만 상당히 Simple 합니다.
NLP에서 많이 사용하는 방식입니다.
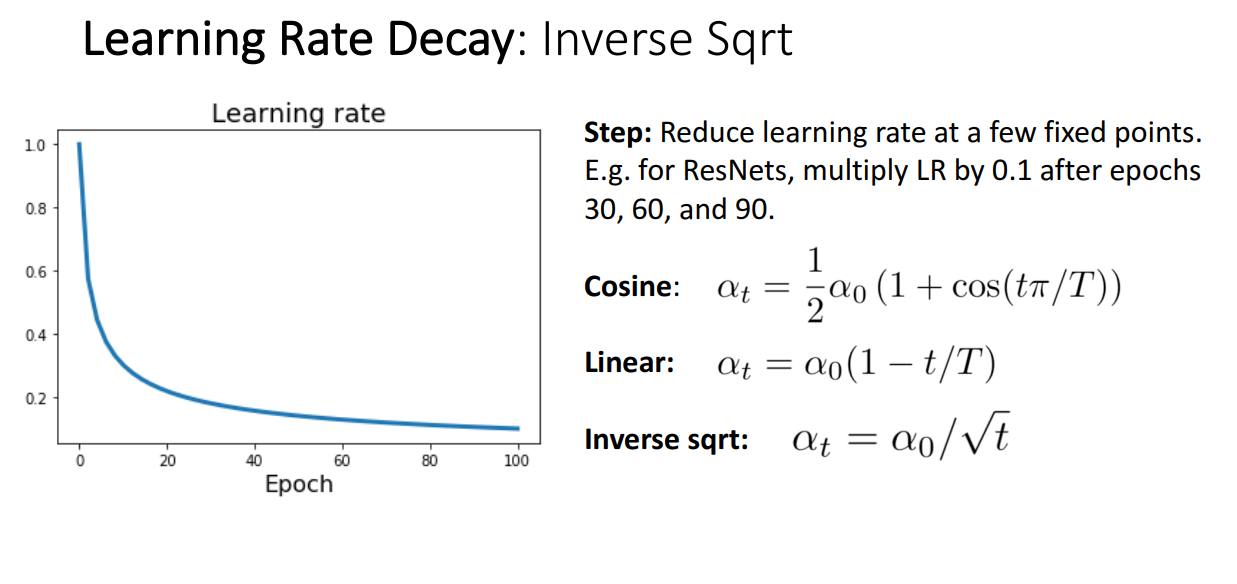
Inverse Sqrt를 곱해주면서 줄이는 방식도 있고 정해줘야할 하이퍼파라미터는 입니다.
보시면 초반에 굉장히 빠르게 학습률을 줄이고 뒤로 갈수록 천천히 줄여가는걸 볼 수 있습니다.
Transformer에서 많이 사용한다곤 합니다.
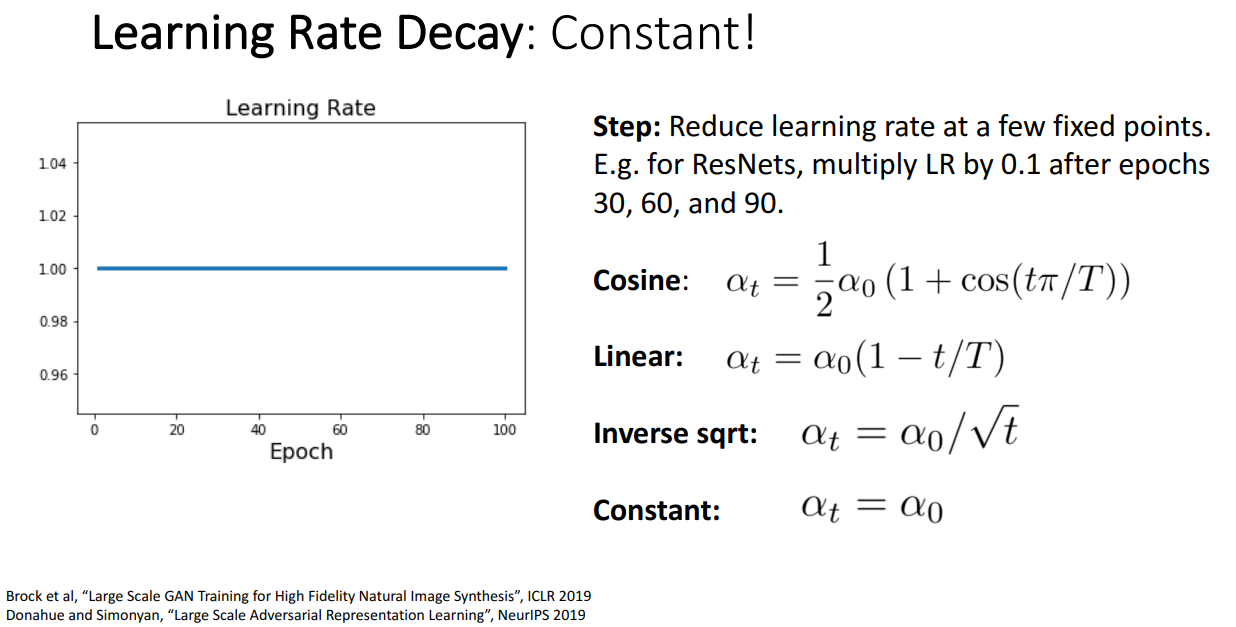
사실 그냥 Constant 값을 써도 성능이 그리 나쁘지는 않다고 합니다.
Adaptive하게 LR를 정해주는 것도 틀릴 때가 있기 때문에 그냥 줄이지 않고 해도 괜찮을 때가 있답니다.
Momentum을 사용하는 최적화 방법은 Learning Rate Decay 방식을 쓰고,
RMSProp이나 Adam 처럼 더 복잡한 최적화 방법은 그냥 Constant LR 써도 무방합니다.
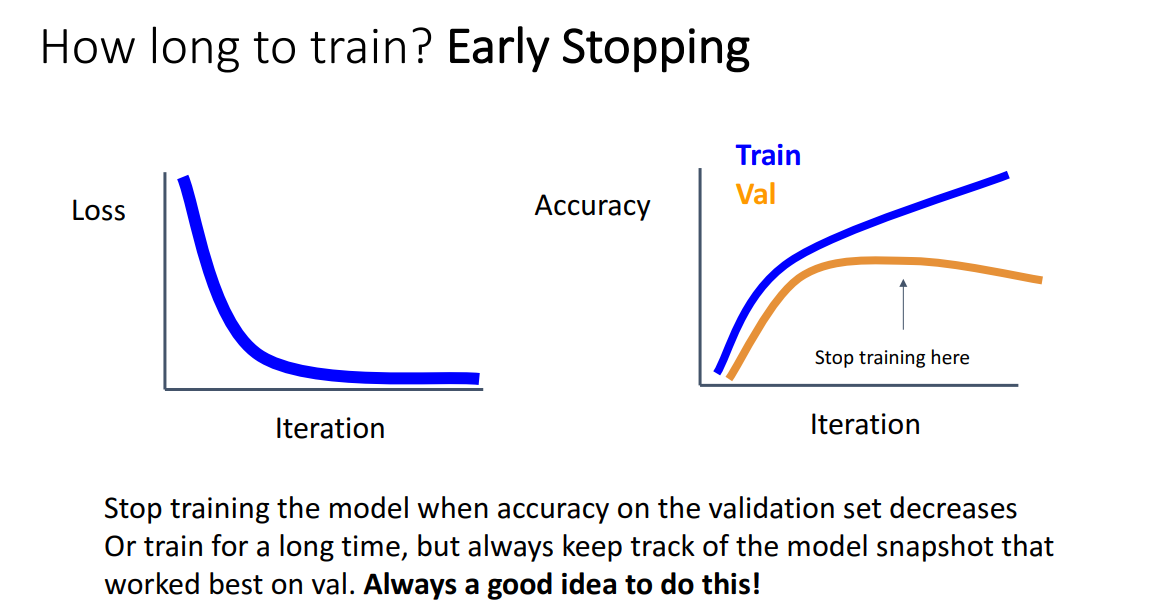
교수님이 꼭 추천해주시는 방법은 Early Stopping입니다.
매 Epoch마다 파라미터 값을 저장하는데, Var Acc가 가장 높을 때 학습을 멈추자는 아이디어입니다.
즉 학습이 Blow up 하기 전에 체크포인트를 만들고 exploding 막는 방법입니다.
Choosing Hyperparameters

하이퍼파라미터는 사용자가 정해야하는 값이기 때문에 적절하게 잘 고르는 것이 중요합니다.
유명한 방법 중 하나는 Grid Search입니다.
해당 방법은 하이퍼파라미터 값들의 후보 Set를 미리 정해놓고 모든 조합을 살펴보는 것입니다.
단점이 있다면 GPU가 충분해야 다 살펴볼 수 있겠죠?!

두 번째 방법은 하이퍼파라미터의 range를 정해놓고 그 안에서 random value로 설정하는 방식입니다.
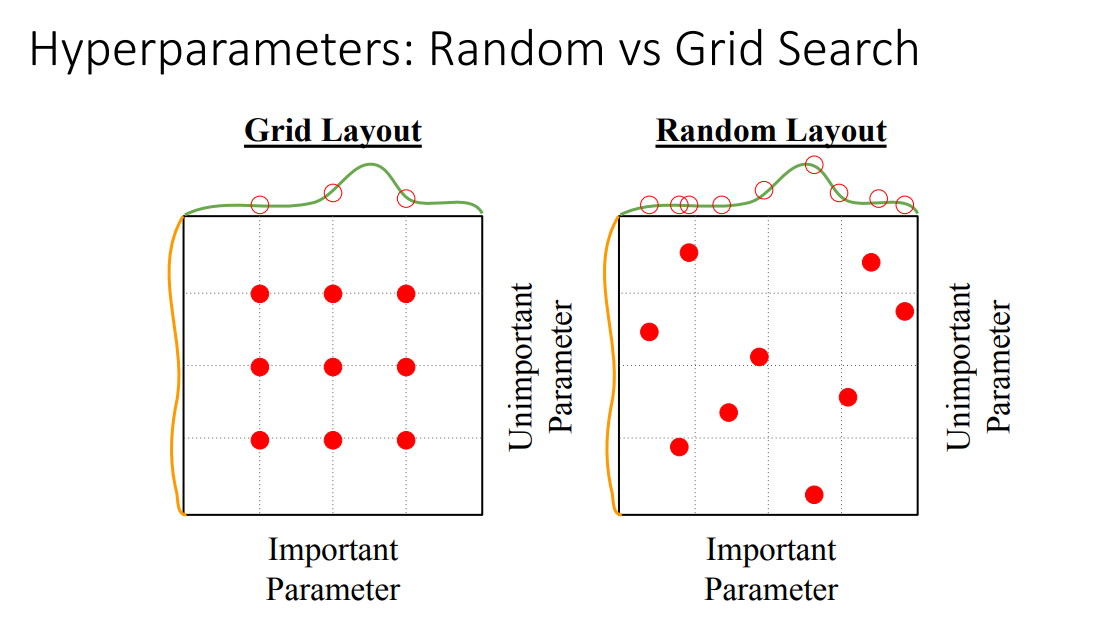
비슷해보이지만 Random Search 방법이 훨씬 좋다고 합니다.
위 그림은 극단적 예시긴 하지만
안 중요한 파라미터와 중요한 파라미터가 있을때 Grid Search의 경우 두 파라미터의 격자에 해당하는 조합만 사용할 수 있기 때문에 중요한 파라미터의 최적 값을 사용할 수 없을 수도 있습니다.
하지만 Random Search는 굳이 격자에 해당하는 값 아니어도 설정할 수 있기 때문에 확률적으로 중요한 하이퍼파라미터의 최적값을 찾아낼 수 있습니다.
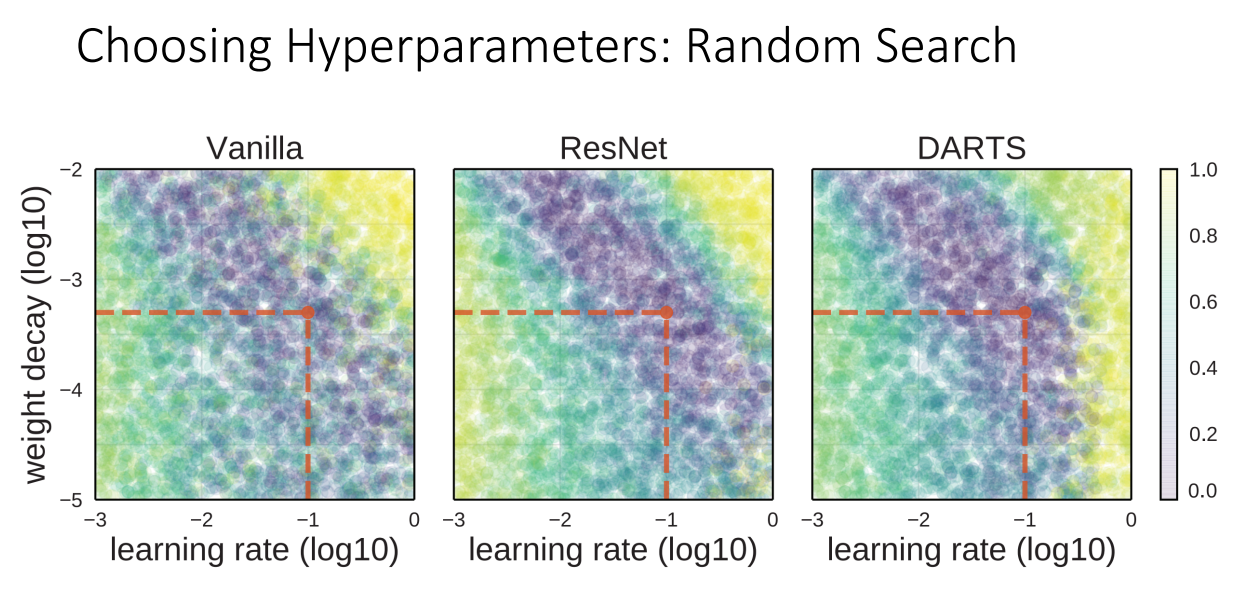
위 그림에서는 보라색 부분이 적절한 하이퍼파라미터 값인데 Random Search로 잘 찾아내는 것을 볼 수 있습니다.

위 Step은 GPU가 충분하지 못할 때 하이퍼파라미터를 잘 고르는 방법입니다.
Step 1
Weight decay를 끄고, loss가 적절하게 잘 설정되어있는지 확인합니다.
Step 2
적은 양의 학습 데이터셋으로 100% 정확도를 도출해봅니다.
이 때는 Regularization을 끄고 Overfitting 되도록 학습합니다.
만약 Step 2도 잘 안된다면 전체 Dataset 학습은 가망이 없을 지도 모릅니다.
Step 2는 적은 양의 학습 데이터셋만 쓰기 때문에 상당히 빠를 것입니다.
Step 3
Loss가 잘 줄어들 수 있게 하는 LR을 찾아봅니다.
Step 3에서는 모든 학습데이터셋을 사용하고, 약간의 Weight decay도 해봅니다.
일반적으로 좋다고 알려진 LR은 1e-1, 1e-2, 1e-3, 1e-4
Step 4
LR와 Weight decay을 Step 3에서 찾은 값 근처에서 몇 개씩 조합해서 모델을 조금만 돌려봅니다.
일반적으로 괜찮은 weight decay는 1e-4, 1e-5, 0 정도입니다.
Step 5
LR decay 없이 더 긴 학습을 해서 최선의 모델을 찾아봅니다.
Step 6
Learning curves를 봅니다.
이건 중요합니다.
Learning Curves
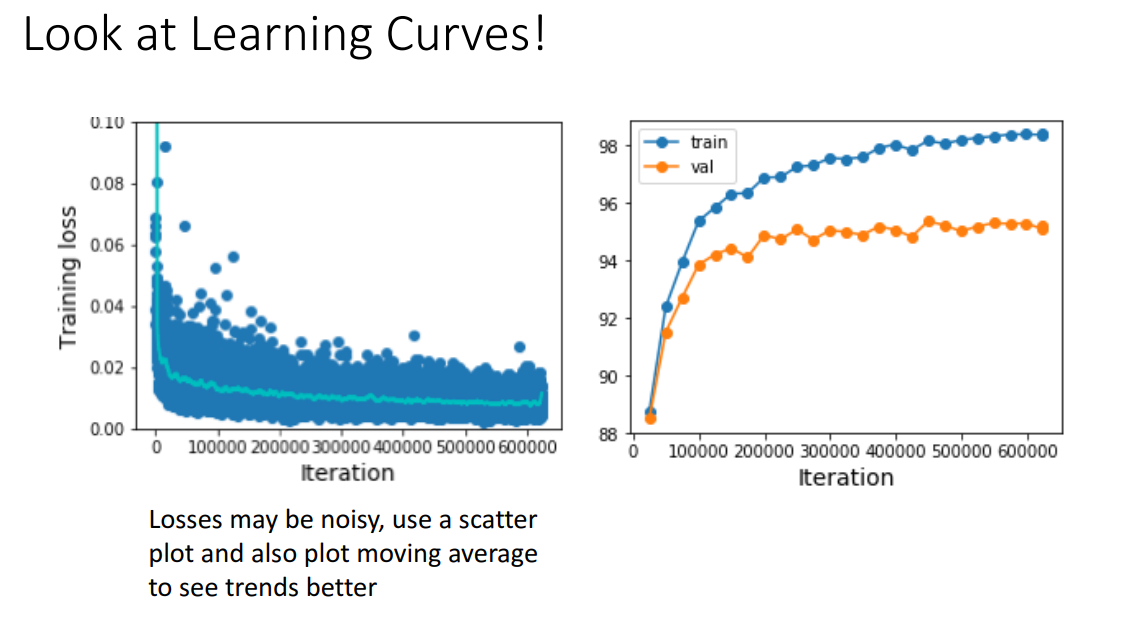
앞서서 첨부했듯이, Loss는 상당히 Noisy할 수 있기 때문에, 각 학습별로 산점도를 그립니다.
그 후에 Trend를 알 수 있는 Moving average를 뽑아볼 수 있습니다.
Learning curve를 잘 보면 무엇이 잘못 되었는지를 알 수 있습니다.
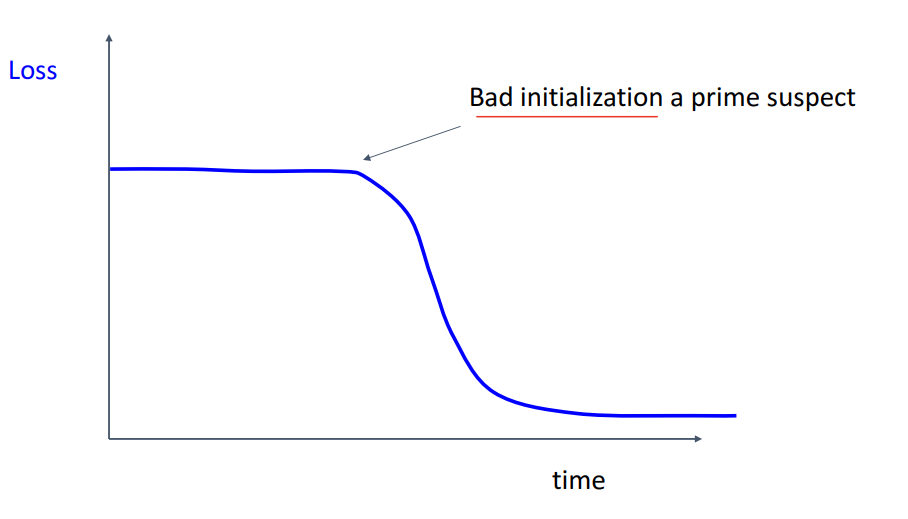
이렇게 Loss가 flat하다가 갑자기 떨어지면
애초에 Initialization이 잘못 됐을 수 있습니다.
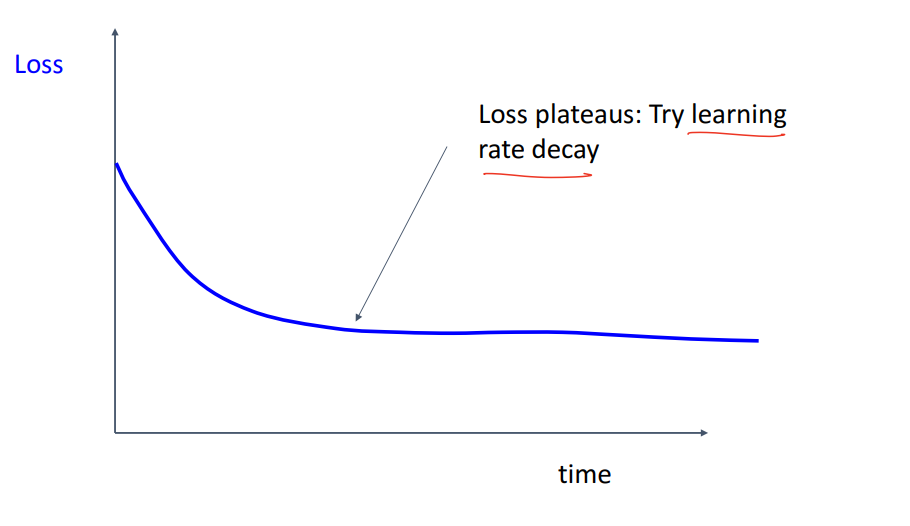
Loss가 이렇게 고원(?) 평평해지면 Learning rate decay를 고려해봐야합니다.
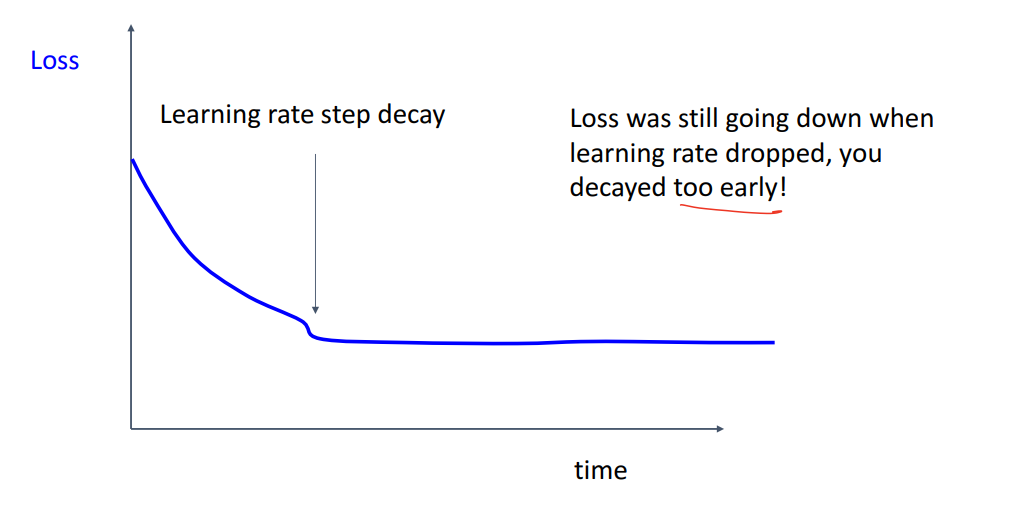
Learning rate decay 후에도 Loss가 더 떨어지는 경향이 있다면
Decay를 너무 빨리 한 겁니다!
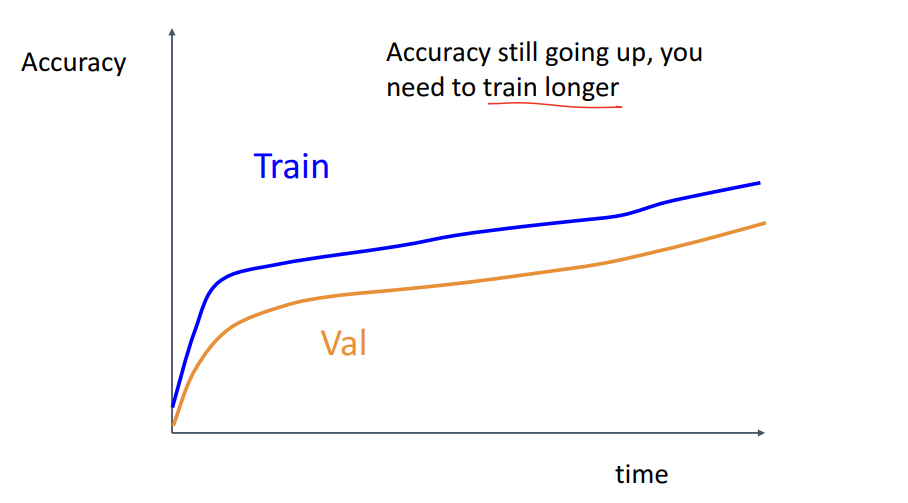
Acc가 계속 올라간다면 Train 더 해봐야합니다.
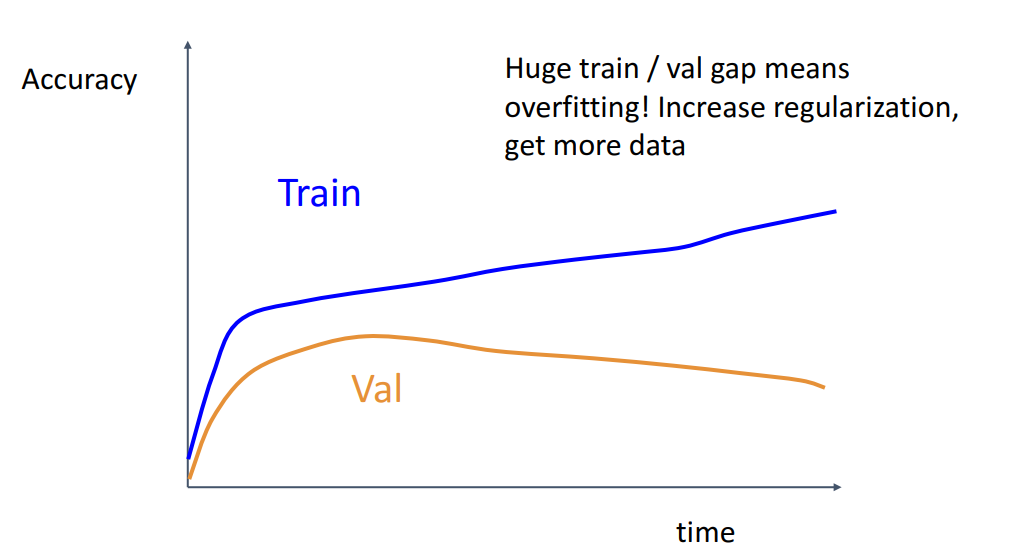
Train과 Val 정확도 gap이 너무 크면
Regularization이나 학습 데이터를 더 확보해서 Overfitting을 막아야 합니다.
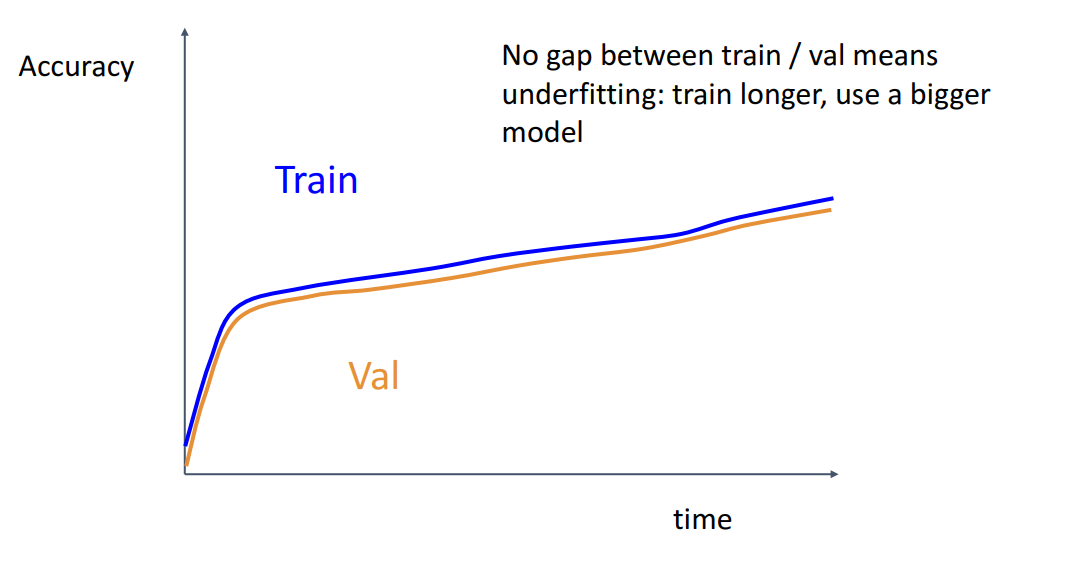
Train과 Val 정확도 gap이 너무 작아서 비슷하다면
Undefitting을 의심해봐야 합니다. 학습을 더 오래하거나, 더 거대한 모델을 써봐야합니다.
Model Ensembles
학습이 완전히 끝난 후에 정확도를 1~2%라도 더 짜내고 싶다면 앙상블을 고려해볼 수 있습니다.
독립적인 모델들 사용하고, 추론 시에 그들의 Output을 평균내서 쓰는 간단한 방법도 있지만
교수님께서는 다른 특이한 앙상블 방법도 소개해주십니다.
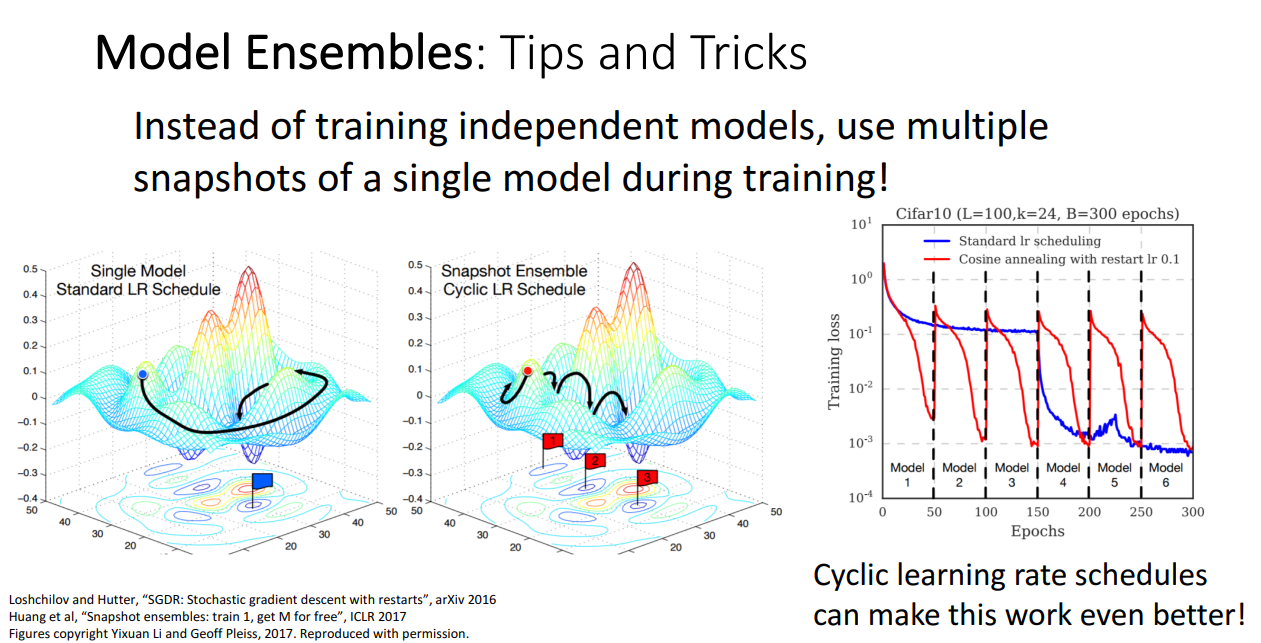
LR 스케쥴에 따라서 하나의 모델을 사용하는 방법보다
Cyclic한 LR 스케쥴에 따라서 여러 모델을 순차적으로 학습시키는 모델인 Snapshot Ensemble을 고려해볼 수 있습니다.

실제 파라미터를 사용하는 대신에 Polyak averaging 방식도 고려해볼 수 있습니다.
Transfer Learning
CNN 같은 모델을 학습하고 사용하려면 무조건 많은 데이터가 필요하다는 전제를 깨부순 학습 방법입니다.

이미지 모델에서 전이학습을 간단하게 표현하자면 위와 같이 ImageNet 데이터셋으로 CNN 구조를 학습시키고 분류 Task를 수행하는 마지막 Layer만 날려서 다른 데이터셋에 사용하는 방법입니다.
그렇게 할 경우 위 성능 비교 그래프를 보시면 그 당시 SOTA 방법이 빨간색 선이라고 할 때,
파란색, 연두색 선을 AlexNet을 Pretrain 시키고 전이학습한 결과입니다.
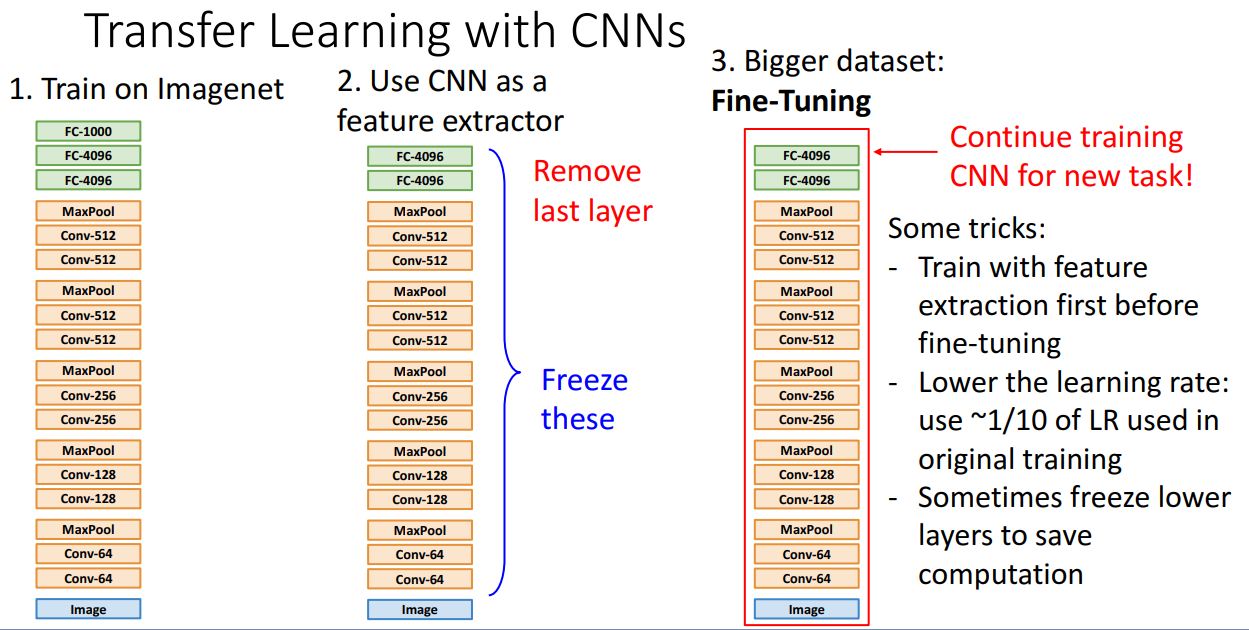
그대로 전이학습 해서 사용해도 좋지만, 그보다는 새로운 Task를 위해서 Fine-tuning 시키는 방식이 성능 향상에 더 도움이 된다고 합니다.
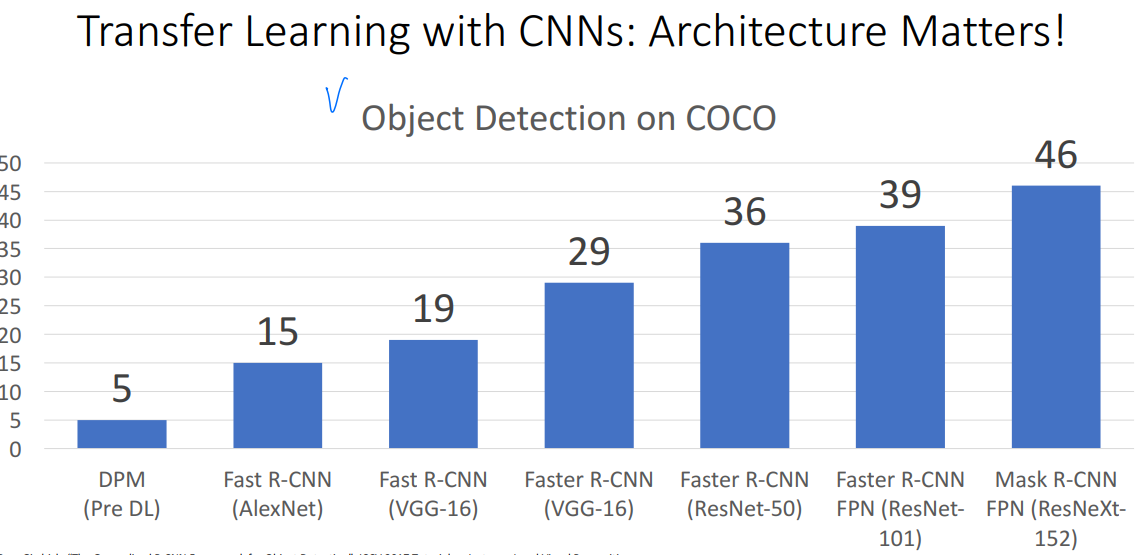
전이학습 테크닉은 Object Detection에서도 성능이 좋습니다.
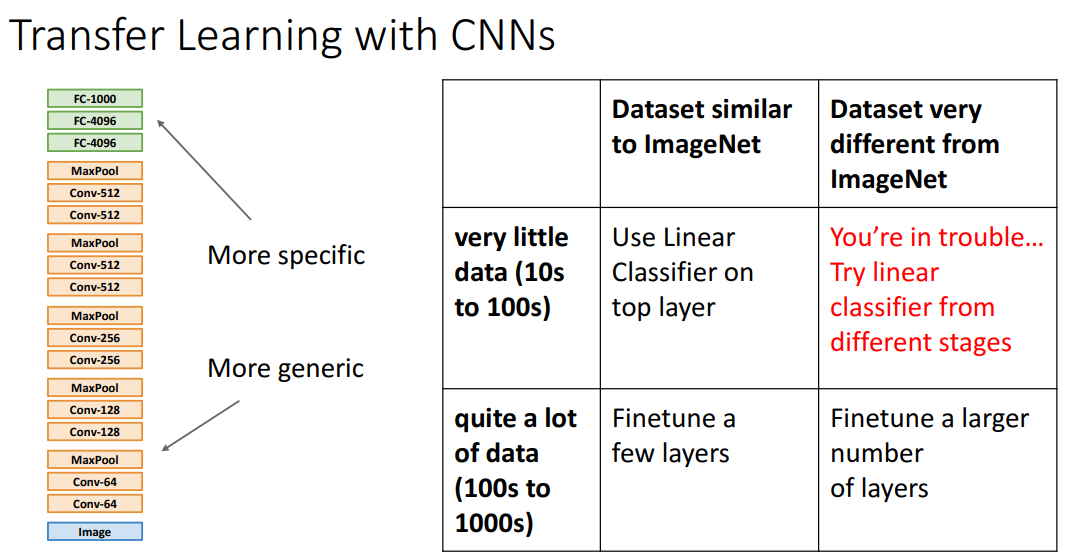
하나 주의할 점은 전이학습해서 해결할 데이터셋이 Pretrain 데이터셋이랑 너무 다른데 게다가 수가 적을 때 입니다. 이때는 상당히 조심하셔야 합니다.
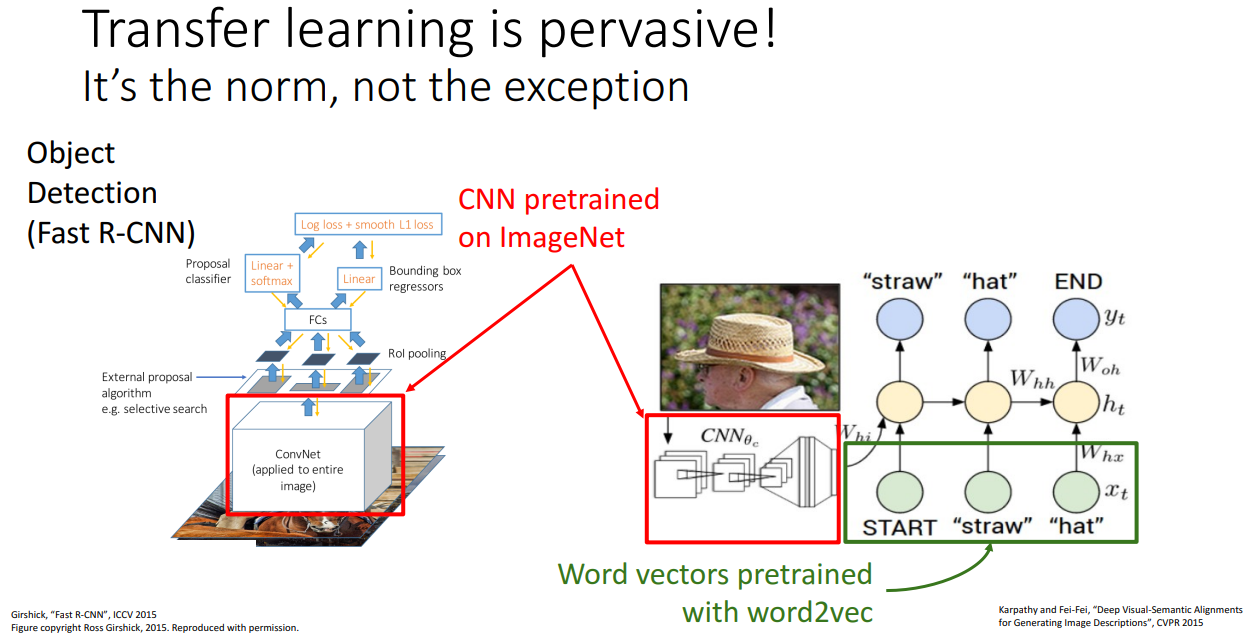
Image Captioning Task에서도 전이학습이 사용될 수 있습니다.
교수님께서는 물론 데이터셋이 충분히 있고 학습을 오래한다면
전이학습이랑 처음부터 학습한 네트워크랑 성능이 비슷하다고 지적해주십니다.
하지만 학습 속도는 중요한 요소입니다.
## Distributed Learning
해당 개념은 모델을 학습시키기 위해서 여러 GPU를 사용하는 방법론들인데,
컴퓨터 공학과 학생의 입장에서 AI를 공부하는 시간을 아니기 때문에 생략하도록 하겠습니다.
