Hadoop
하둡 분산 파일 시스템(Hadoop Distributed File System,HDFS)
-
하둡은 대용량 데이터를 분산 처리할 수 있는 자바기반의 오픈 소스 프레임워크입니다.
-
구글에 쌓여있는 수많은 빅데이터(웹페이지, 로그 데이터들을 오라클)에 입력하고 데이터를 저장하고 처리하려고 시도를 했으나 데이터가 너무 많아서 실패를 하고 자체적으로 빅데이터를 저장할 기술을 개발하고 대외적으로 논문을 발표 했다.
-
구글의 논문을 야후에 있는 더그커팅이 읽고 자바로 구현했다.
RDBMS(오라클) ---------------------------- 하둡
실시간 데이터처리 배치처리, 분산처리
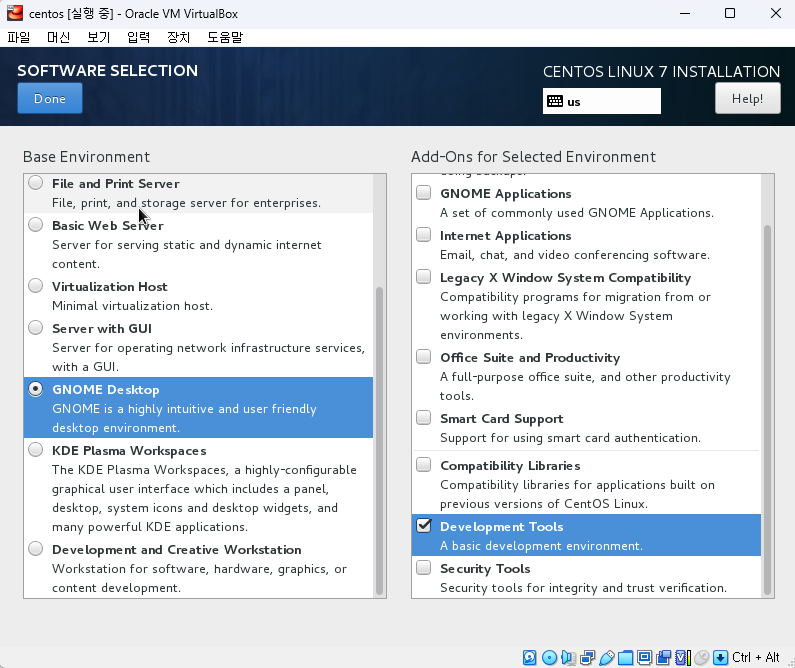
centos 설치
1. host이름 ip랑 매핑
/etc/hosts
192.168.56.101 centos
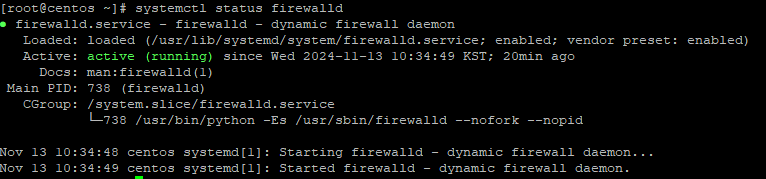
2. 방화벽 확인
systemctl status firewalld
3. 방화벽 중지
systemctl stop firewalld
4. 방화벽 비활성화(os reboot시 방화벽 off설정)
systemctl disable firewalld
5. 자바 버전 확인
java -version

6. JDK 설정
-
디렉터리 생성
mkdir -p /usr/java -
다운받은 jdk파일 이동
cp /media/sf_hadoop/jdk-8u131-linux-x64\ (1).tar.gz /usr/java/ -
압축풀기
tar xvfz jdk-8u131-linux-x64\ (1).tar.gz -
압축파일 확인
cd jdk1.8.0_131/

7. 환경설정
vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_131
export PATH=$PATH:$JAVA_HOME/bin
export CLASS_PATH="."8. 변경값 적용
source /etc/profile
9. 기본 JDK 변경
-
java 디렉터리 위치 확인
which java

-
기본 jdk을 설치한 jdk로 등록
update-alternatives --install "/usr/bin/java" "java" "/usr/java/jdk1.8.0_131/bin/java" 1
update-alternatives --config java

-
변경작업 확인
java -version

10. hadoop 그룹 생성
groupadd hadoop
tail /etc/group

11. hadoop 유저 생성
useradd -g hadoop -G vboxsf hadoop
tail /etc/passwd

12. hadoop 유저 패스워드 설정
passwd hadoop (hadoop으로 설정)
13. hadoop 유저로 접속
su - hadoop
- 공유폴더의 파일 확인
ls /media/sf_hadoop/hadoop-3.2.4.tar.gz (공유폴더에 접근 가능한 이유는 vboxsf그룹에 속해있기 때문이다) - 홈 디렉터리에 복사
cp /media/sf_hadoop/hadoop-3.2.4.tar.gz .
14. 압축 풀기
tar xvzf hadoop-3.2.4.tar.gz
- 경로 확인
/home/hadoop/hadoop-3.2.4
15. hadoop 유저의 환경설정
vi .bashrc
export JAVA_HOME=/usr/java/jdk1.8.0_131
export HADOOP_HOME=/home/hadoop/hadoop-3.2.4
export HADOOP_CONFIG_HOME=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin16. 환경변수 적용
source .bashrc
17. hadoop 버전 확인
hadoop version

18. 공개키 설정
-
설치하기 전 혹시 이미 있을 수도 있으니 삭제 작업
rm -rf .ssh -
설정 작업할때 계속 enter로 넘어가기
ssh-keygen
-
공개키 안에 패스워드 등록
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@192.168.56.101
-
설정이 잘 되었는지 확인
ssh hadoop@192.168.56.101

19. 하둡 환경설정
-
해당 위치로 이동
cd $HADOOP_HOME/etc/hadoop -
환경변수 추가
vi hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_131
export HADOOP_HOME=/home/hadoop/hadoop-3.2.4 -
네임노드 실행 서버
vi masters
192.168.56.101 -
데이터노드 실행 서버
vi workers
기존에 작성되어있는거 삭제 후 ip 주소 입력
192.168.56.101 -
하둡 파일시스템, 맵리듀스 공통적으로 사용할 환경정보 설정
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://centos:9010</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-3.2.4/tmp</value>
</property>
</configuration>- 하둡 파일시스템 환경설정
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/dfs/namenode</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/home/hadoop/data/dfs/namesecondary</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/dfs/datanode</value>
</property>
<property>
<name>dfs.http.address</name>
<value>centos:50070</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>centos:50090</value>
</property>
</configuration>- 맵리듀스 환경설정
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>- yarn 환경설정
vi yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_suffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/hadoop/data/yarn/nm-local-dir</value>
</property>
<property>
<name>yarn.resourcemanager.fs.state-store.uri</name>
<value>/home/hadoop/data/yarn/system/rmstore</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>centos</value>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>0.0.0.0:8089</value>
</property>yes
</configuration>20. name node 포맷작업(한번만 하면 된다)
- name node는 rac의 마스터노드 같은 역할이다.
hdfs namenode -format
21. 하둡 데몬(프로세스) 시작
start-all.sh
22. 데몬 확인
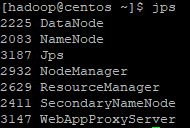
jps
- 하둡 데몬(프로세스) 종료
stop-all.sh
23. 하둡 파일시스템에 디렉토리 생성
hdfs dfs -ls /
hdfs dfs -mkdir /user
hdfs dfs -ls /

24. 로컬 파일시스템의 파일을 hdfs에 복사
- put 사용
hdfs dfs -put /media/sf_hadoop/obama.txt /user
25. hdfs로 올려진 파일 확인
hdfs dfs -ls /user

26. 파일 내용 미리보기
hdfs dfs -cat /user/obama.txt
27. 파일의 단어갯수 구하기
-
맵리듀스 디렉터리로 이동
cd $HADOOP_HOME/share/hadoop/mapreduce

-
java 프로그램으로 실행
yarn jar hadoop-mapreduce-examples-3.2.4.jar wordcount /user/obama.txt output -
wordcount를 작업하기 위해 temp 공간이 생성되었다.
hdfs dfs -ls /

-
새로운 디렉터리가 생성되어있다.
hdfs dfs -ls /user

-
wordcount 작업 내용이 담겨있다.
hdfs dfs -ls output

28. hdfs 저장된 파일을 로컬 파일시스템으로 복사
- get 사용
hdfs dfs -get output/part-r-00000 /home/hadoop/wc_output - 확인
ls

hive
- 하둡 기반의 DW(Data Warehouse) 솔루션
- SQL과 유사한 HiveQl 쿼리를 통해서 데이터 분석 가능
- 페이스북에서 개발, 오픈소스로 공개
1. 공유폴더에서 로컬로 파일 이동
cp /media/sf_hadoop/apache-hive-3.1.3-bin.tar.gz .
2. 압축 해제
tar xvzf apache-hive-3.1.3-bin.tar.gz
3. 환경변수 설정
vi .bashrc
export JAVA_HOME=/usr/java/jdk1.8.0_131
export HADOOP_HOME=/home/hadoop/hadoop-3.2.4
export HADOOP_CONFIG_HOME=$HADOOP_HOME/etc/hadoop
export HIVE_HOME=/home/hadoop/apache-hive-3.1.3-bin
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin4. 적용하기
source .bashrc
5. 디렉터리 이동
cd $HIVE_HOME/conf
6. 설정
vi hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
</configuration>7. 환경변수 추가(맨 뒤에 추가해준다)
vi $HIVE_HOME/bin/hive-config.sh
export HADOOP_HOME=/home/hadoop/hadoop-3.2.4
8. 충돌문제로 이름 변경
cp $HADOOP_HOME/share/hadoop/common/lib/guava-27.0-jre.jar $HIVE_HOME/lib/guava-27.0-jre.jar
mv $HIVE_HOME/lib/guava-19.0.jar $HIVE_HOME/lib/guava-19.0.jar.bak
9. hdfs에 디렉터리 생성
hdfs dfs -mkdir -p /user/hive/warehouse
10. write 권한 추가
hdfs dfs -chmod g+w /user/hive/warehouse
11. Apache Hive의 메타스토어 데이터베이스에 필요한 스키마를 초기화하는 명령어
schematool -dbType derby -initSchema

12. Apache Hive의 셸(Command Line Interface, CLI)을 실행
hive
13. 다른 세션에서 hadoop의 유저로 csv 파일 hdfs에 올리기
ls /media/sf_hadoop/emp.csv

hdfs dfs -put /media/sf_hadoop/emp.csv /user
hdfs dfs -put /media/sf_hadoop/dept.csv /user
14. hive에서 테이블(뼈대) 생성
create table emp
(empno int,
ename string,
hiredate string,
sal int,
deptno int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE ;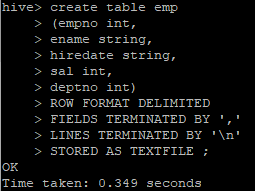
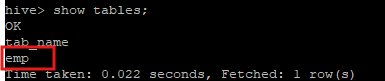
15. 테이블 확인
show tables;
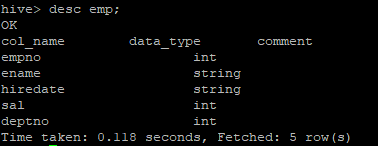
desc emp;
16. 로컬파일 or hdfs 에서 hive로 전송
-
로컬파일 -> hive 전송
hive>load data local inpath '/home/hadoop/emp.csv' into table emp; -
하둡 -> hive 전송
hive>load data inpath 'hdfs://centos:9010/user/emp.csv' into table emp;
17. hive 테이블 삭제
drop table emp;
- 테이블을 삭제하는 순간 hdfs의 emp 디렉터리안의 csv파일까지 같이 삭제된다.

18. hdfs 디렉터리 생성
hdfs dfs -mkdir /user/hive/warehouse/emp
hdfs dfs -put /media/sf_hadoop/emp.csv /user/hive/warehouse/emp/
hdfs dfs -ls -R /user/hive/warehouse/emp
19. external 테이블 생성
create external table if not exists emp
(empno int,
ename string,
hiredate string,
sal int,
deptno int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION '/user/hive/warehouse/emp';20. 테이블 조회
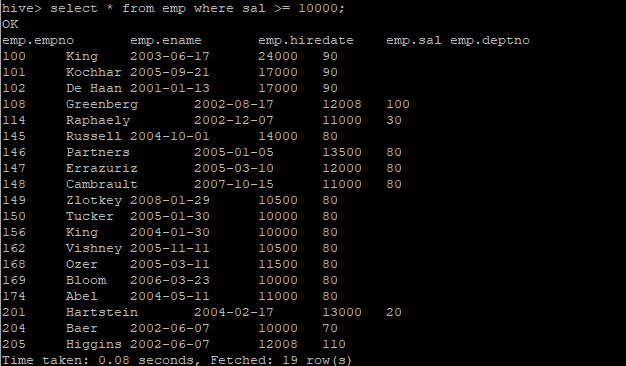
select * from emp where sal >= 10000;
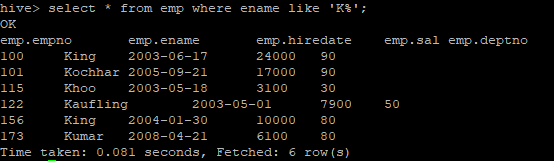
select * from emp where ename like 'K%';
-
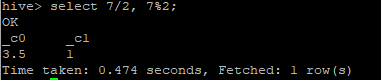
dual을 사용할 필요가 없다.
select 7/2, 7%2;
-
nvl 함수도 지원
select empno, nvl(deptno,0) from emp where deptno is null;

