Physical I/O
1. Conventional Path I/O
- 데이터 버퍼 캐시를 경유하여 블록을 읽는 작업
single block I/O
- 한번에 하나의 블록만 읽어오는 I/O 작업
- rowid scan
- by user rowid scan
- by index rowid scan
- row chained(입력시점에 행의 크기가 블록 크기 보다 클 경우)
- row migration(기존 행이 존재하는 블록안에서 증가하려고 할때 프리공간이 없으면 다른 블록으로 이전)
db file sequential readwait event 발생
multi block I/O
- 한번에 여러개의 연속된 블록을 읽어 오는 I/O작업
- db_file_multiblock_read_count(mbrc)파라미터에 설정되어있는 값 만큼 읽어온다.
- full table scan, index fast full scan시 발생
db file scattered readwait event 발생
2. Direct Path I/O
- 오라클 I/O는 기본적으로 SGA영역에 database buffer cache를 경유한다.
- 어떤 상황에서는 PGA영역에 데이터를 올리는 경우가 있다. 즉 데이터를 공유할 필요가 없을 경우에는 데이터베이스 버퍼 캐시에 적재하는 과정에서 발생하는 오버헤드를 피함으로써 성능을 개성하는 것이 가능하다.
- Direct Path I/O가 발생하게 되면 I/O 작업이 발생되기 전에 버퍼 캐시내의 변경된 블록을 데이터파일에 기록하는 partial 체크포인트가 발생한다.
Direct Path I/O 발생하는 경우
-
정렬 작업을 위해 정렬 세그먼트(sort segment)를 읽고 쓰는 경우
대기이벤트 : direct path read temp, direct path write temp -
parallel query를 위해 데이터파일을 읽는 경우
대기이벤트 : direct path read
select /*+ full(e) paralle(e 2) */ count(*) from hr.emp e;-
parallel dbm, CTAS를 위해 데이터 파일을 쓰는 경우
대기이벤트 : direct path write -
serial direct read
_small_table_threshold설정되어 있는 블록의 수 보다 많은 블록을 가지고 있는 테이블을 full table scan이 발생하면 direct path read 방식으로 디스크에 블록들을 PGA영역으로 바로 읽어 오는 기능이 11g 부터 지원이 된다. -
insert /+ append / .. select ..
대기이벤트 : direct path write -
SQL*Loader(sqlldr) direct 옵션을 지정해서 데이터 로드 작업
대기이벤트 : direct path write -
export 작업시에 direct 옵션을 지정해서 데이터 로드 작업
대기이벤트 : direct path write -
data pump 작업은 direct path i/o 방식으로 수행된다.
SGA(System Global Area)
- 오라클 데이터베이스 instance의 데이터 및 제어 정보를 포함하는 공유(shared) 메모리 구조
PGA(Program[private,process] Global Area)
- 서버 또는 백그라운드 프로세스의 데이터 및 제어정보를 포함하는 private 메모리 영역
- PGA는 stack space, uga(user global area) 영역으로 구분된다.
- stack space : 변수들이 생성되는 영역
- UGA(user global area)
- cursor 영역
- 세션에 대한 제어정보를 위한 유저 세션 데이터 저장영역(session_privs 조회되는 영역)
- SQL문 처리를 위한 SQL 작업영역
- 정렬 영역
- 해시 영역
- 비트맵 생성 영역
- 비트맵 병합 영역
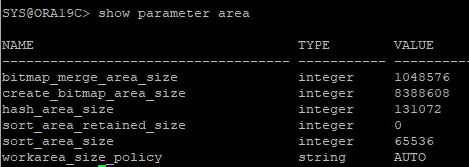
자동 PGA 메모리 관리
show parameter pga_aggregate_target(9i new feature)

show parameter sga_target(10g new feature)

show parameter memory_target(11g new feature)

-
pga_aggregate_target은 instance에 연결된 모든 서버 프로세스에 사용할 수 있는 모든 PGA메모리 집계의 대상을 지정한다.
-
pga_aggregate_target 파라미터를 기반으로 작업영역에 할당되는 PGA메모리 양이 동적으로 조정된다.
-
기본값 : 10mb 또는 SGA크기의 20%중에 더 큰값으로 설정
-
OLTP
pga_aggregate_target = (물리적 메모리(OS) 80%(오라클이 사용할 수 있는 메모리 총 비율)) 20% -
DSS(의사결정시스템)
pga_aggregate_target = (물리적 메모리(OS) 80%(오라클이 사용할 수 있는 메모리 총 비율)) 50%
예) 10GB 물리적 메모리를 갖는다면 OS를 위해 2GB를 남겨 두고 나머지 8GB를 오라클에 할당한다. OLTP 환경에서 6.4GB(80%)는 SGA에 할당하고 남은 1.6GB(20%)를 PGA영역에 할당한다.
DSS 환경에서는 4GB(50%)는 SGA에 할당하고 남은 4GB는 PGA(50%)영역에 할당한다.
_smm_max_size: 각 서버프로세스가 사용가능한 work area 최대크기(kb단위)
select a.ksppinm as parameter,b.ksppstvl as session_value, c.ksppstvl as instance_value
from x$ksppi a, x$ksppcv b, x$ksppsv c
where a.indx = b.indx
and a.indx = c.indx
and a.ksppinm = '_smm_max_size';
테스트
- 대용량 테이블 생성
create table hr.emp_temp
nologging
as
select * from hr.employees,
(select rownum no
from dual
connect by level <= 1000);- 정렬 작업시 사용되는 메모리 크기 확인
select /*+ gather_plan_statistics*/ *
from (select rownum as id, employee_id
from hr.emp_temp
order by employee_id)
where id = 1;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));
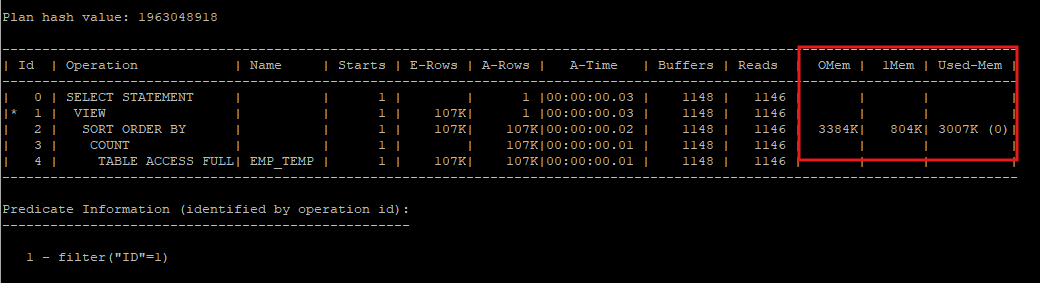
OMem : optimal sort에 필요한 예상 정렬 작업 영역의 크기
1Mem : one pass sort에 필요한 예상 정렬 작업 영역의 크기
Used-Mem : 실제로 사용된 정렬 작업 영역의 크기
Used-Temp : 메모리가 부족하여 temporary space를 사용한 공간 크기(kb 단위)
-
sort area 내에서 데이터 정렬을 마무리하는 것이 최적이나(optimal) 양이 많을때는 정렬된 중간 결과 집합(sort run)을 temporary tablepsace의 temp segment에 임시로 저장한다.
-
optimal sort: sort 작업이 PGA의 sort_area_size안에서 이루어지는 것 -
onepass sort: sort 대상 집합(sort run)이 디스크에 한번만 쓰여지는 것 -
mulipass sort: sort 대상 집합(sort run)이 디스크에 여러번 쓰여지는 것
- pga memory 공간을 수동설정으로 변경 후 sort_area_size를 1mb로 설정
- sort_area_size는 1mb만 사용하고 temp tablespace에서 2mb를 사용한다.
- onepass sort가 발생되었다.
alter session set workarea_size_policy = manual;
alter session set sort_area_size = 1048576;
select /*+ gather_plan_statistics*/ *
from (select rownum as id, employee_id
from hr.emp_temp
order by employee_id)
where id = 1;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));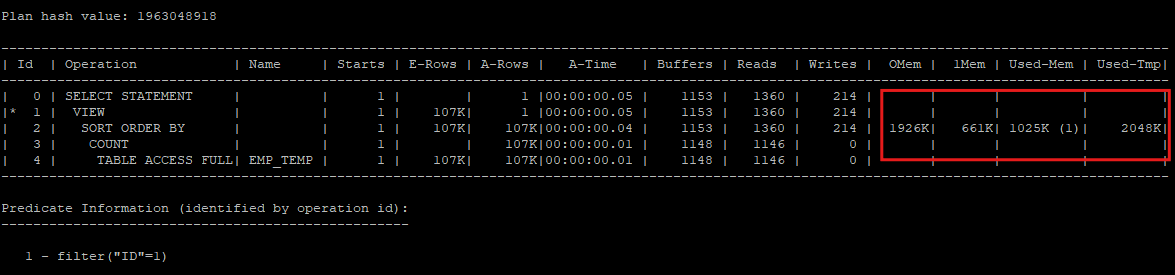
- 메모리 사이즈를 0으로 설정하였어도 194kb정도는 사용하였고 3mb를 temp tablespace에서 사용하였다.
- multipass sort는 2번 발생하였다.
alter session set sort_area_size = 0;
select /*+ gather_plan_statistics*/ *
from (select rownum as id, employee_id
from hr.emp_temp
order by employee_id)
where id = 1;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));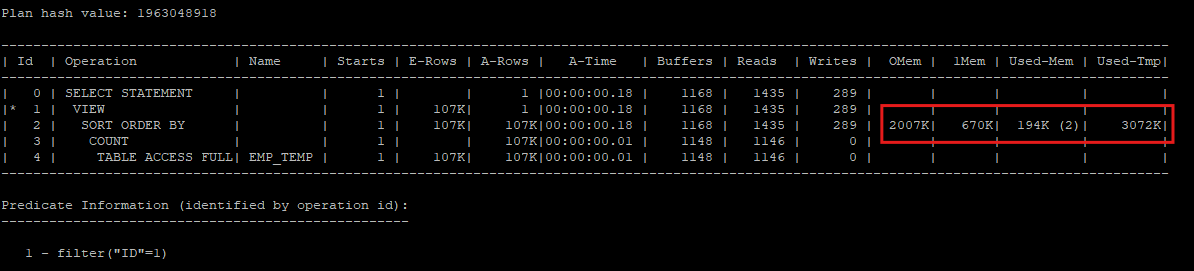
- 동일한 sql이더라도 sort_area_size에 따라 child cursor로 만들어 진다.
select sql_id, child_number, sql_text
from v$sql
where sql_text like '%gather_plan_statistics%'
and sql_text not like '%v$sql%';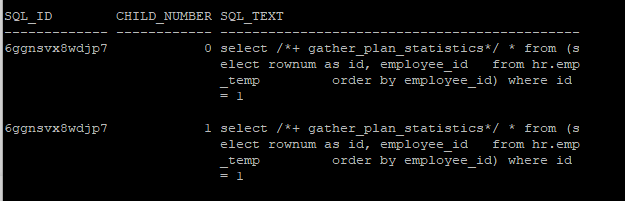
- sql id별로 sql 작업영역을 확인
- last_execution이 pass는 onepass sort가 발생
- last_execution이 passes는 multipass sort가 발생
select child_number, last_execution, last_memory_used, last_tempseg_size
from v$sql_workarea
where sql_id = '6ggnsvx8wdjp7';
test2(wait event 확인)
- wait event도 같이 보기 위해서 10046 events로 설정한다.
alter session set sort_area_size = 0;
alter session set tracefile_identifier = 'sort';
alter session set events '10046 trace name context forever, level 8';
select /*+ gather_plan_statistics*/ *
from (select rownum as id, employee_id
from hr.emp_temp
order by employee_id)
where id = 1;
alter session set events '10046 trace name context off';- trace파일이 저장되는 위치 확인
select name, value from v$diag_info;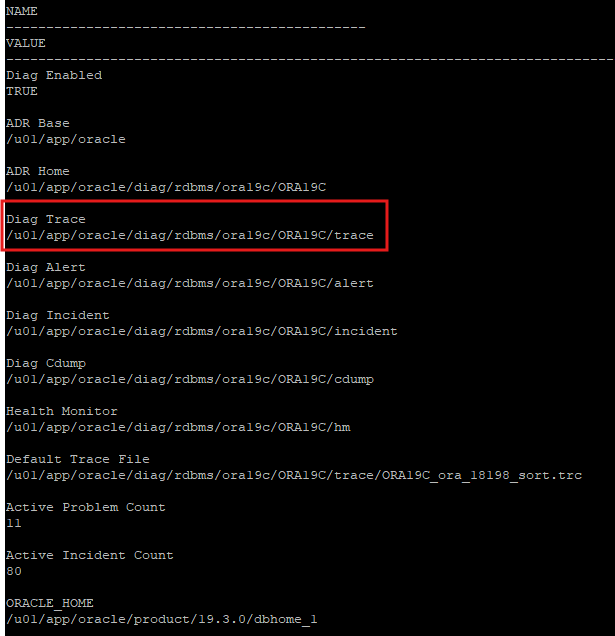
- 저장 위치로 이동
cd /u01/app/oracle/diag/rdbms/ora19c/ORA19C/trace
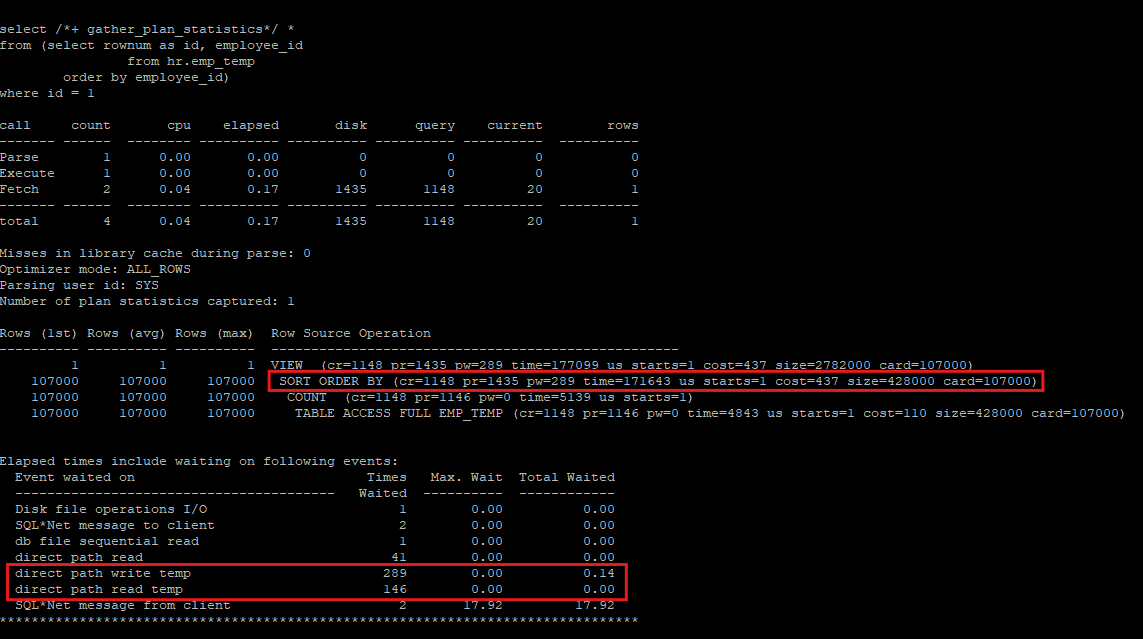
- trc파일은 보기 어려우니 txt 파일로 변환
tkprof ORA19C_ora_18198_sort.trc sort.txt
- sort시 메모리에서 정렬할 공간이 없어 temp datafile로 내려서(physical write) 정렬 처리 후 다시 읽어와야 한다(physical read), 이때 direct path 방식이 사용된다.
vi sort.txt
병렬 처리
- sql문이 수행해야할 작업 범위를 여러개의 작은 단위로 나누어 여러 프로세스가 동시에 처리하는 작업을 의미한다.
- 대용량 테이블을 생성 시 쓸대없는 redo entry로 인해 스토리지 낭비를 막기 위해 nologging 모드로 생성
drop table hr.emp purge;
create table hr.emp
nologging
as
select rownum as employee_id, last_name, first_name, hire_date, job_id,salary,manager_id, department_id
from hr.employees e, (select level as id from dual connect by level <= 1000);- 생성 테이블의 통계정보 확인(CTAS로 생성하였기 때문에 초기 통계정보 존재)
select num_rows, blocks, avg_row_len, logging
from dba_tables
where owner='HR'
and table_name = 'EMP';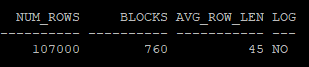
- nologging으로 대용량 테이블 생성 후에는 logging 모드로 변경하여 후에 백업에 필요한 redo 정보를 생성해야 한다.
alter table hr.emp logging;set arraysize 1000
show arraysize
- serial full table scan : 프로세스 1개가 처리
alter session set statistics_level = all;
select /*+ full(e) */ count(*) from hr.emp e;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));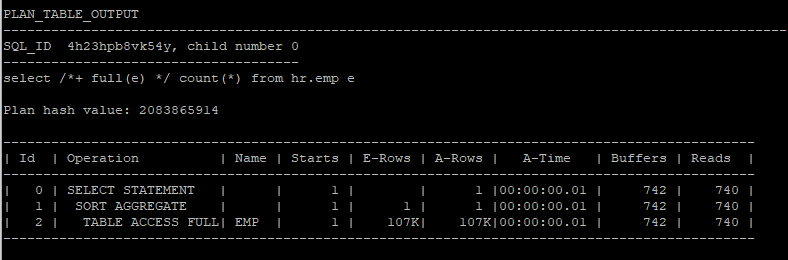
- parallel full table scan, direct path read 방식
select /*+ full(e) parallel(e 2) */ count(*) from hr.emp e;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last parallel'));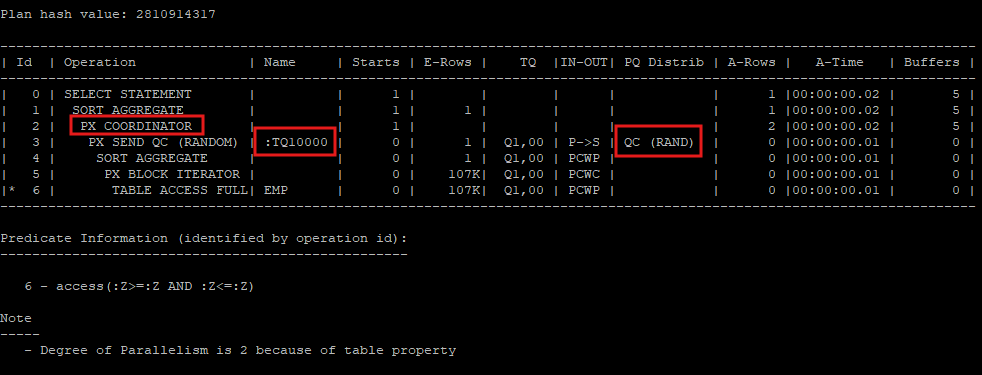
Query Coordinator(QC)
Query Coordinator(QC)는 Oracle 병렬 쿼리(Parallel Query) 실행에서 중요한 역할을 하는 프로세스로, SQL 문이 병렬로 수행될 때 전체 작업을 조정하고 감독하는 역할을 맡습니다. QC는 병렬 처리가 필요한 SQL 문이 제출된 세션에 의해 생성되며, 다음과 같은 기능을 수행합니다.
-
1. 작업 관리 및 감독: QC는 병렬로 나누어진 각 작업을 병렬 실행 서버에 할당하고, 작업이 잘 진행되는지 확인하며 관리합니다. 작업 상태를 모니터링하고 오류가 발생하면 이를 처리하며, 모든 병렬 작업이 완료되면 QC가 최종 결과를 취합하여 사용자에게 전달합니다.
-
2. 직접 처리 기능: 병렬 처리가 지정되지 않은 테이블이나 SQL 요소에 대해서는 QC가 직접 처리합니다. 예를 들어, 특정 테이블이 병렬로 처리되지 않도록 지정되어 있을 때, QC가 해당 테이블의 데이터를 직접 다루게 됩니다.
-
3. 집계 함수 수행: QC는 SQL문 내에서 집계 함수가 사용될 경우, 병렬 쿼리로 부분 집계를 수행한 후 최종 집계 작업을 진행합니다. 병렬 실행 서버들이 각각 처리한 결과를 모아서 QC가 최종 결과를 계산하며, 이후 이 집계된 결과를 사용자에게 반환합니다.
병렬 서버 프로세스
- 실제 작업을 수행하는 개별 세션
- 병렬서버 = 병렬 프로세스 = 병렬 슬래이브
병렬 서버 풀(parallel execution server pool)
- 병렬 처치시 서버 풀에 있는 프로세스부터 사용
- 부족분에 대해서는 추가 생성(large pool에서 빌림)
- 생성할 수 있는 최대 병렬 서버 개수
show parameter parallel_max_servers

병렬 서버 집합(server set)할당
- 병렬도(DOP(Degree Of Parallelism)와 오퍼레이션 종류에 따라 한개 또는 두개의 병렬 서버 집합 할당
- 서버풀(parallel execution server pool)로 부터 필요한 만큼 서버 프로세스 확보
병렬도
- 병렬도 = 2
- 서버 프로세스 = 병렬도 * 2 = 2 * 2 =4
- 통신 채널 수 = 병렬도 ** 2 = 2 ** 2 = 4
select /*+ full(e) parallel(e 2) */ * from hr.emp e order by last_name;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last parallel'));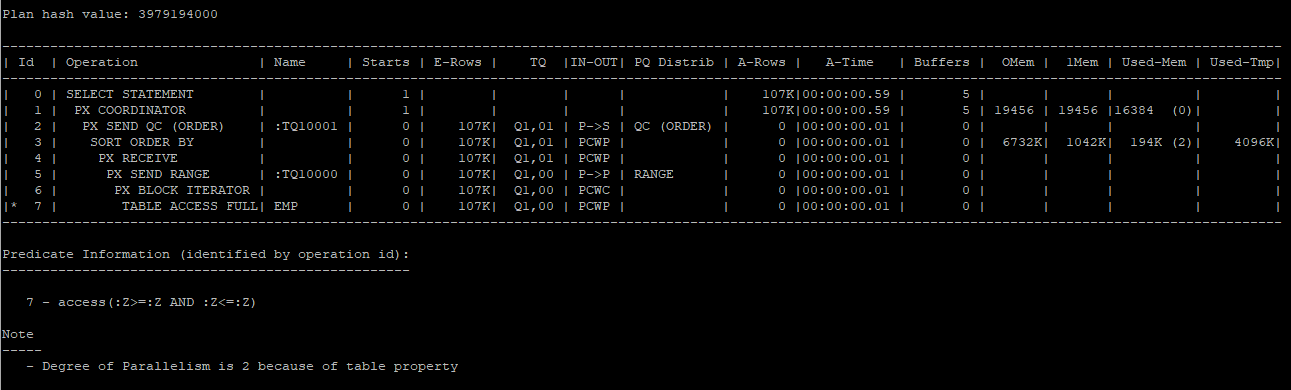

Producer, Consumer
select tq_id, server_type, process, num_rows, bytes, waits
from v$pq_tqstat
order by tq_id, decode(substr(server_type,1,4),'Rang',1,'Prod',2,'Cons',3), process;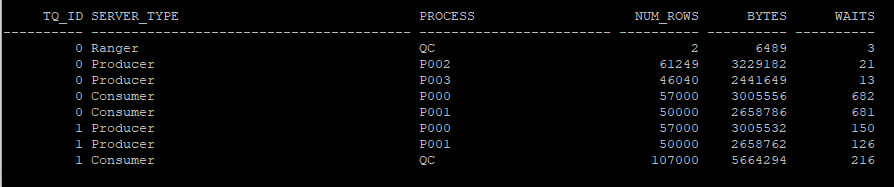
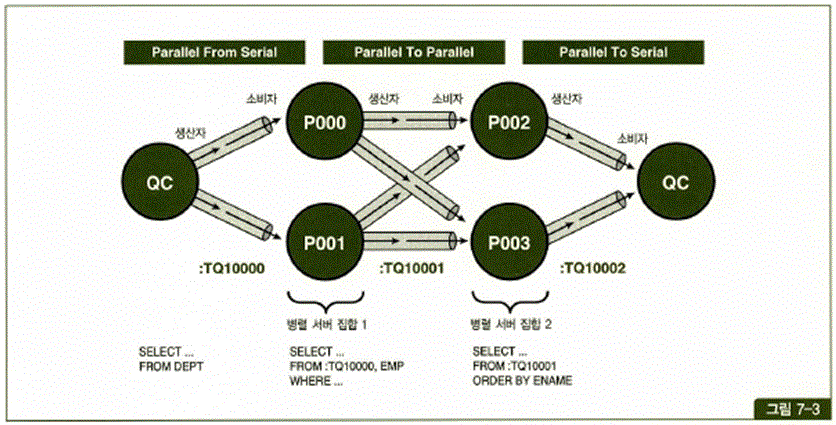
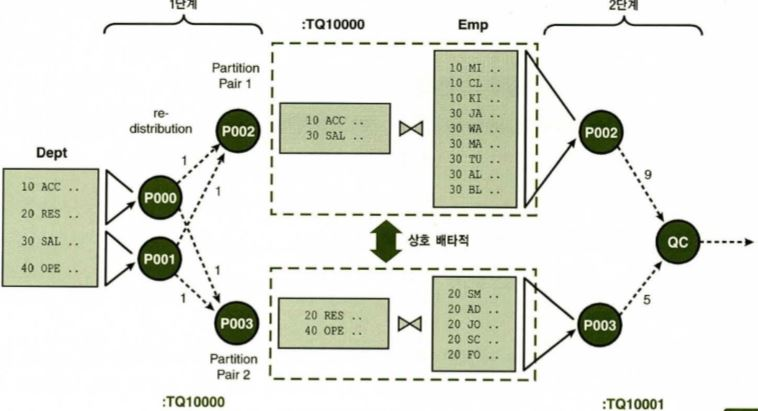
Producer(생산자) Consumer(소비자) Producer(생산자) Consumer(소비자)
P002 P000(A-M) P000(A-M) QC
P003 P001(N-Z) P001(N-Z)
---------- -------- --------- --------------- ------ ---------------
데이터 추출 테이블큐 정렬 정렬결과셋 테이블큐 생산자로부터 받은 각각의 정렬결과를
병렬서버집합1 :TQ10000 병렬서버집합2 :TQ10001 머지작업후에 유저에게 전달 - Producer(생산자) : 작업을 생성, 데이터추출, 데이터를 추출해서 버퍼에 저장, PX SEND
- Consumer(소비자) : 작업을 처리, 버퍼에 있는 데이터를 꺼내 소비(정렬, 그룹작업수행), PX RECEIVE
- 테이블큐 : 프로세스간 통신 즉 메시지 또는 데이터를 전송하기 위한 통신, 파이프라인(pipeline)
1. 일반적인 producer 단계에서 hash group by를 수행하는 경우
- 이 경우 Oracle이 Producer 단계에서 먼저 hash group by를 수행하여 데이터를 미리 그룹화한 뒤 Consumer에게 전달합니다.
- Producer 단계에서 데이터가 추출될 때 hash group by가 실행되므로, 데이터가 미리 그룹화되어 전송됩니다. 이렇게 하면 Consumer가 처리해야 할 데이터의 양이 줄어들어 전체 I/O 비용이 감소하고 성능이 최적화됩니다.
- 실제 실행 계획에서 버퍼 I/O가 줄어드는 효과를 확인할 수 있으며, 이는 데이터 전송량과 필요한 I/O 작업이 감소한 덕분입니다.
select /*+ full(e) parallel(e 2) */ department_id, count(*) from hr.emp e group by department_id;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last parallel'));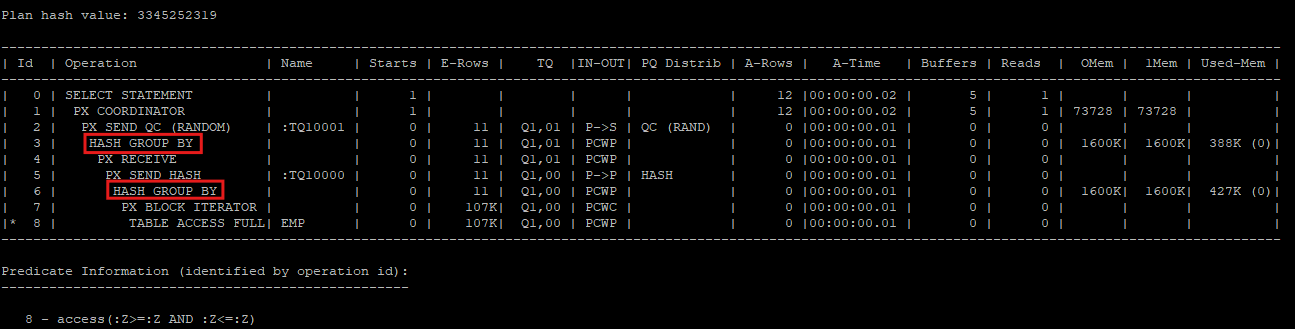
- 통계에서 확인하면 Producer 단계에서 이미 그룹화가 진행된 덕분에 Consumer가 받는 데이터 양이 적어져 대기 시간도 줄어듭니다.
select tq_id, server_type, process, num_rows, bytes, waits
from v$pq_tqstat
order by tq_id, decode(substr(server_type,1,4),'Rang',1,'Prod',2,'Cons',3), process;
2. no_gby_pushdown 힌트를 사용하여 consumer 단계에서 group by를 수행하는 경우
- 이 방식에서는 no_gby_pushdown 힌트를 사용하여 Producer가 데이터를 그룹화하지 않고, Consumer 단계에서만 group by를 실행하게 만듭니다.
- Producer는 단순히 데이터를 추출하여 Consumer로 전송하며, hash group by 작업은 Consumer 단계에서 수행됩니다.
- 이 경우 Consumer는 모든 데이터를 처리하고 그룹화해야 하기 때문에 처리해야 할 행(row)의 수가 많아져 전체 성능이 저하될 수 있습니다. 특히, 데이터 양이 많을수록 Consumer 단계의 부담이 커집니다.
select /*+ full(e) parallel(e 2) no_gby_pushdown */ department_id, count(*) from hr.emp e group by department_id;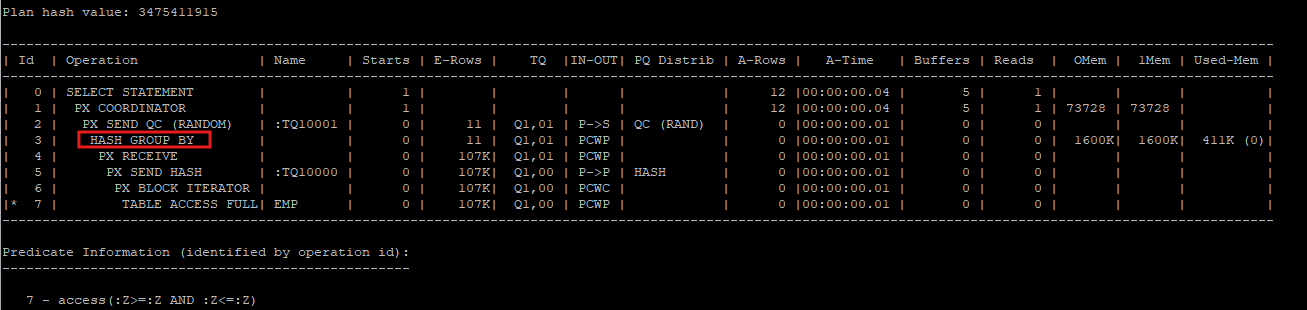
- 결과에서 확인할 수 있듯이, Consumer는 더 많은 행을 처리하게 되어 대기 시간(waits)이 늘어나고 데이터 전송량이 증가합니다.
select tq_id, server_type, process, num_rows, bytes, waits
from v$pq_tqstat
order by tq_id, decode(substr(server_type,1,4),'Rang',1,'Prod',2,'Cons',3), process;
병렬조인
- 병렬프로세스들이 서로 독립적(파티션)으로 조인을 수행할 수 있도록 데이터를 분배하는데 있다.
- 분배작업이 완료되고 나면 프로세스간에 서로 방해 받지 않고 각자 할당받은 범위내에서 조인을 완료한다.
- 병렬 조인에는 두가지 방식있다.
- 파티션 방식 : partition pair 끼리 조인 수행
- broadcast 방식 : 한쪽 테이블을 broadcast하고 나서 조인 수행
full partition wise join
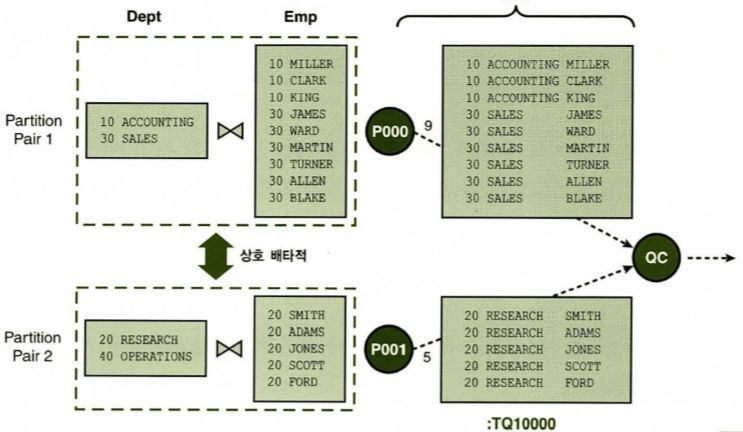
- 조인하려는 두 테이블의 조인키 컬럼을 기준으로 파티션된 경우
- 데이터 재분배가 필요 없다.
pq_distribute: full partition wise join으로 유도하는 힌트, 양쪽 테이블 모두 조인 컬럼에 대해 같은 기준으로 파티셔닝 되어 있을 경우 사용- pq_distribute(inner테이블(별칭), outer table distribution 방식, inner table distribution 방식)
- 파티션 테이블 생성
- emp_part와 dept_part 테이블은 department_id 컬럼을 기준으로 리스트 파티셔닝(list partitioning) 되어 있습니다.
- 이처럼 동일한 기준으로 파티셔닝된 테이블 간 조인은 데이터 재분배가 필요 없고 각 파티션에서 독립적으로 수행될 수 있습니다.
create table hr.emp_part
partition by list(department_id)
(partition p_dept_1 values(10,20,30,40),
partition p_dept_2 values(50),
partition p_dept_3 values(60,70,80,90,100,110),
partition p_dept_4 values(default))
as
select * from hr.employees;
create table hr.dept_part
partition by list(department_id)
(partition p_dept_1 values(10,20,30,40),
partition p_dept_2 values(50),
partition p_dept_3 values(60,70,80,90,100,110),
partition p_dept_4 values(default))
as
select * from hr.departments;- 파티션 정보 조회
select partition_position,partition_name,high_value, tablespace_name, num_rows,blocks,avg_row_len, to_char(last_analyzed,'yyyy-mm-dd hh24:mi:ss')
from dba_tab_partitions
where table_owner='HR'
and table_name='EMP_PART';
select partition_position,partition_name,high_value, tablespace_name, num_rows,blocks,avg_row_len, to_char(last_analyzed,'yyyy-mm-dd hh24:mi:ss')
from dba_tab_partitions
where table_owner='HR'
and table_name='DEPT_PART';
- 통계수집
execute dbms_stats.gather_table_stats('hr','emp_part');
execute dbms_stats.gather_table_stats('hr','dept_part');- 통계수집 정보 확인
select partition_position,partition_name,high_value, tablespace_name, num_rows,blocks,avg_row_len, to_char(last_analyzed,'yyyy-mm-dd hh24:mi:ss')
from dba_tab_partitions
where table_owner='HR'
and table_name='EMP_PART';
select partition_position,partition_name,high_value, tablespace_name, num_rows,blocks,avg_row_len, to_char(last_analyzed,'yyyy-mm-dd hh24:mi:ss')
from dba_tab_partitions
where table_owner='HR'
and table_name='DEPT_PART';
- hint를 주지 않고 쿼리 수행 후 실행계획 확인
- 파티션 해시 조인에서는 각 파티션에서 일치하는 department_id 값에 대해 독립적으로 조인됩니다.
- 데이터 재분배 없이 각 파티션끼리만 조인하므로 I/O를 최소화하며, 병렬 쿼리 효율이 높아집니다.
- Oracle 옵티마이저가 파티션별로 조인을 수행하는 실행 계획을 자동 생성함으로써 파티션을 기준으로 작업이 독립적으로 처리됩니다.
select /*+ */ e.employee_id, e.last_name, e.salary, d.department_id, d.department_name
from hr.emp_part e, hr.dept_part d
where e.department_id = d.department_id;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last parallel'));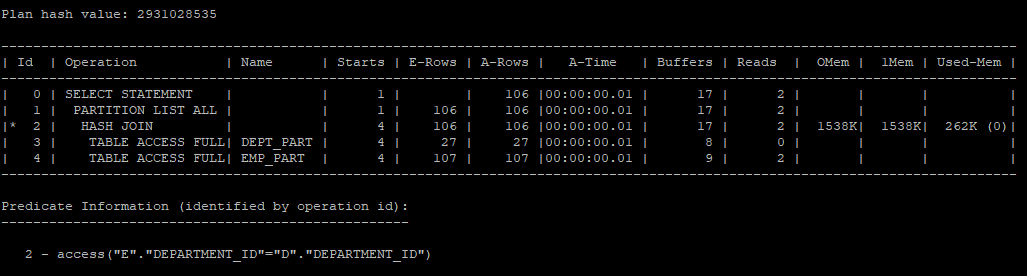
- 병렬 쿼리 힌트 사용한 조인 실행
pq_distribute(e,none,none): outer table과 inner table에 데이터 재분배를 하지 않는다.
select /*+ leading(d,e) use_hash(e) full(d) full(e) parallel(e 2) parallel(d 2) pq_distribute(e,none,none) */ e.employee_id, e.last_name, e.salary, d.department_id, d.department_name
from hr.emp_part e, hr.dept_part d
where e.department_id = d.department_id;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last parallel'));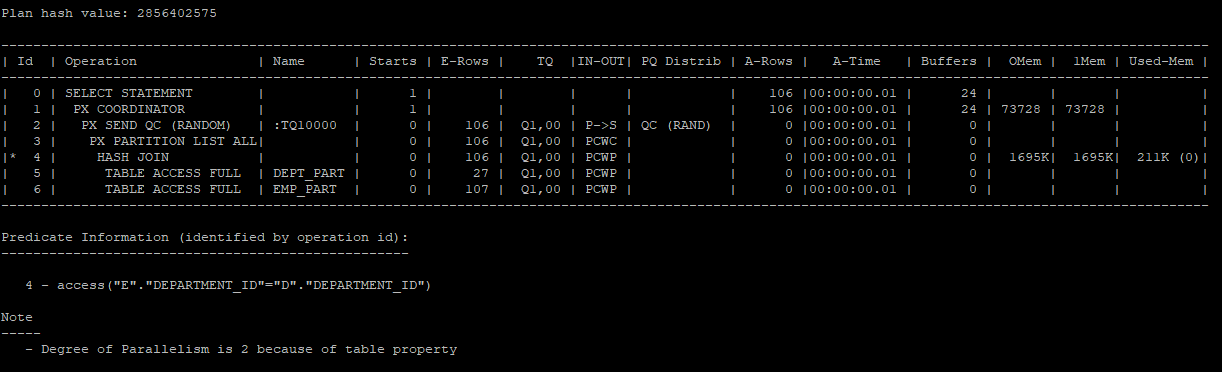
- 병렬 쿼리 상태 확인 (V$PQ_TQSTAT)
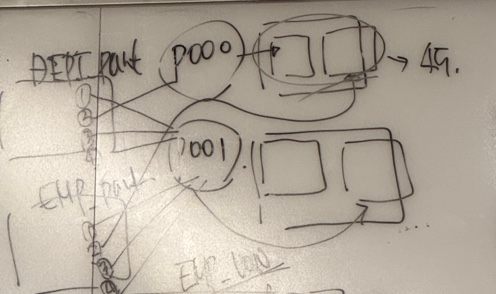
- 1.P000 프로세스:
P000은 department_id 50번 데이터를 처리하는 build 테이블과 probe 테이블을 구성하고 hash join을 수행했습니다.
이로 인해 45개의 행을 생성했습니다. department_id 값이 특정 범위로 나뉘어 있어, P000 프로세스는 해당 ID와 관련된 행만 처리하게 됩니다. - 2.P001 프로세스:
P001은 나머지 department_id 값을 가진 데이터를 처리하는 build 테이블과 probe 테이블을 구성하고 hash join을 수행했습니다.
이로 인해 65개의 행을 생성했습니다. department_id 50번 외의 모든 데이터가 P001에 할당되면서 이 프로세스가 더 많은 데이터를 처리했습니다.
select tq_id, server_type, process, num_rows, bytes, waits
from v$pq_tqstat
order by tq_id, decode(substr(server_type,1,4),'Rang',1,'Prod',2,'Cons',3), process;
partial partition wise join
- 조인 테이블에 한쪽만 파티셔닝된 경우
- 파티셔닝이 되어 있지 않은 다른 쪽 테이블을 같은 기준으로 파티셔닝하고 나서 full partition wise join을 수행한다.
- 동적 파티셔닝을 위한 데이터 재분배 필요
pd_distribute(e,none, partition): inner테이블은 outer 테이블 파티션 기준에 따라 파티셔닝 하라는 의미. 당연히 outer table은 조인키 컬럼에 대해 파티셔닝 되어 있을때 작동된다.
테스트 1
- 파티션 되어있지 않은 테이블 생성
create table hr.emp_none
as
select * from hr.employees;- pq_distribute(e,none,partition) 힌트를 사용하여 inner table을 outer table 파티션 기준에 따라 데이터를 재분배한다.
select /*+ leading(d,e) use_hash(e) full(d) full(e) parallel(e 2) parallel(d 2) pq_distribute(e,none,partition) */ e.employee_id, e.last_name, e.salary, d.department_id, d.department_name
from hr.emp_none e, hr.dept_part d
where e.department_id = d.department_id;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last parallel'));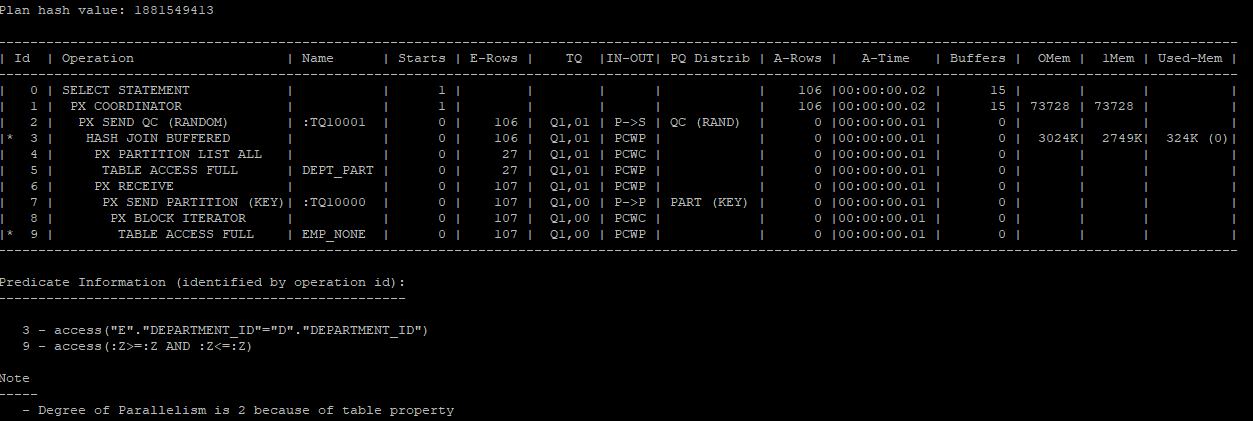
- 실행 과정
1.P002, P003 프로세스가 emp_none 테이블의 107건 데이터를 나눠서 추출한다.
2.P002와 P003에서 전달받은 데이터를 P000,P001프로세스에서 파티셔닝을 한후 build table과 probe 테이블을 만든다.
- P000 프로세스
build table : dept_part테이블에서 50번과 120번 이후의 데이터들
probe table : P002,P003프로세스가 추출한 데이터들중 50번과 null 값 - P001 프로세스
build table : dept_part테이블에서 50번과 120번 이후의 데이터를 제외한 값
probe table : P002,P003프로세스가 추출한 데이터들중 50번과 null값을 제외한 값
3.P000, P001프로세스 안에서 hash join이 발생하고 결과값을 QC에게 전달한다.
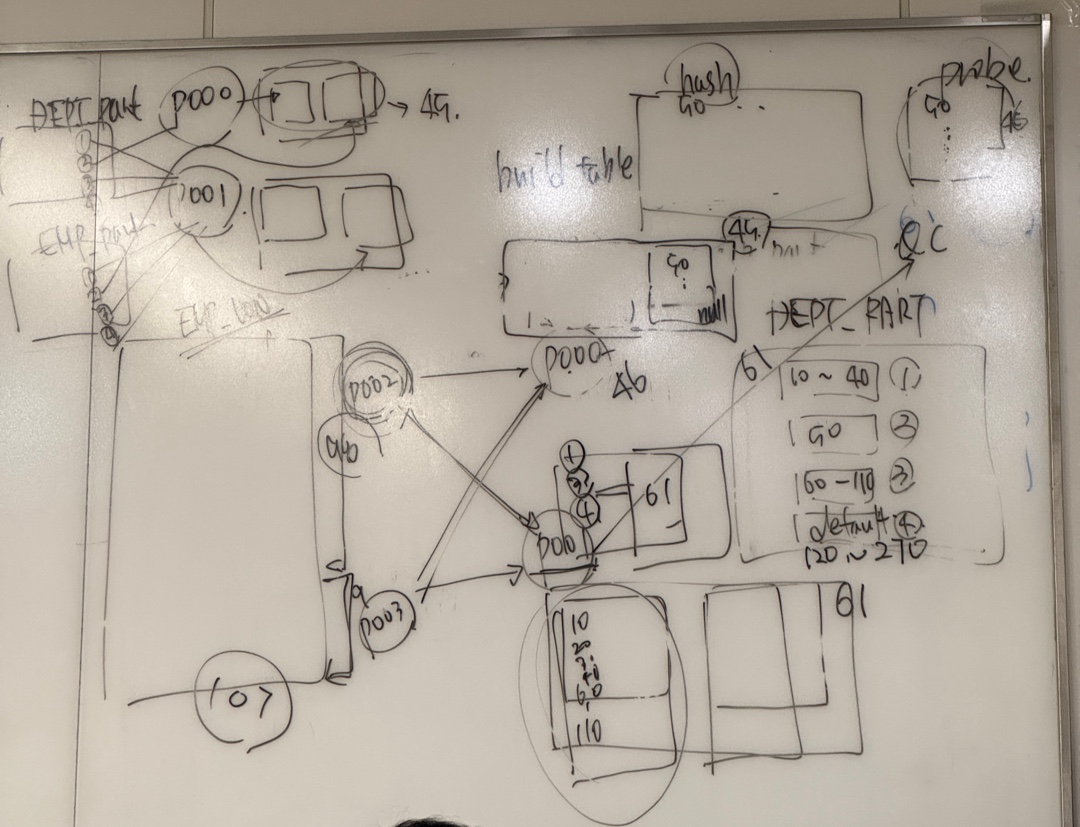
select tq_id, server_type, process, num_rows, bytes, waits
from v$pq_tqstat
order by tq_id, decode(substr(server_type,1,4),'Rang',1,'Prod',2,'Cons',3), process;
테스트2
- partition이 설정되어있지 않은 1쪽 집합 테이블 생성
create table hr.dept_non
as
select * from hr.departments;- inner table은 파티션이 되어있고 outer table은 파티션이 되어있지 않기 때문에 pq_distribute(e,partition,none) 으로 설정해야 한다.
- partial partition wise join 일때 full partition wise join으로 수행하기 위해서 사용한다. 즉 outer table을 inner table 파티션 기준에 따라 파티셔닝하라는 의미
- 실행계획을 보면
PART JOIN FILTER CREATE,PX PARTITION LIST JOIN-FILTERoperation이 있는데 이는 probe테이블에서 build table로 데이터를 올릴때 filter 해서 올리라는 의미 PX SEND PARTITION (KEY): outer table을 inner table의 파티션 키 컬럼을 기준으로 파티셔닝을 한다.
select /*+ leading(d,e) use_hash(e) full(d) full(e) parallel(e 2) parallel(d 2) pq_distribute(e,partition,none) */ e.employee_id, e.last_name, e.salary, d.department_id, d.department_name
from hr.emp_part e, hr.dept_non d
where e.department_id = d.department_id;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last parallel'));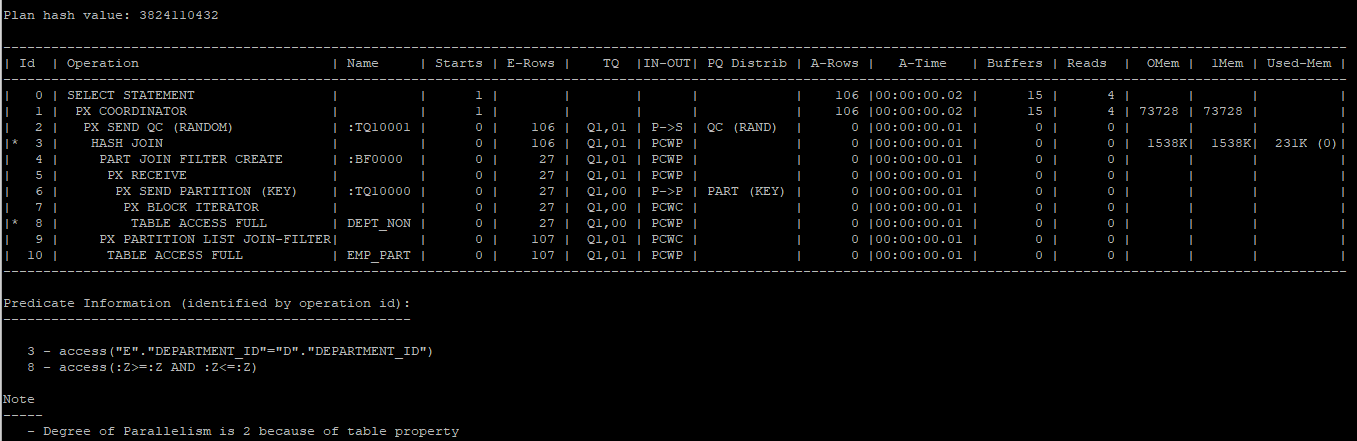
- 실행 과정
1.P002, P003 프로세스가 dept_non 테이블의 27건 데이터를 나눠서 추출한다.
2.P002와 P003에서 전달받은 데이터를 P000,P001프로세스에서 파티셔닝을 한후 build table과 probe 테이블을 만든다.
- P000 프로세스
build table : P002,P003프로세스가 추출한 데이터들중 50번과 120번이후의 값을 파티셔닝
probe table : emp_part테이블에서 50번과 null값 - P001 프로세스
build table : P002,P003프로세스가 추출한 데이터들중 50번과 120번이후의 값을 제외한 나머지값들을 파티셔닝
probe table : emp_part테이블에서 50번과 null값을 제외한 값
3.P000, P001프로세스 안에서 hash join이 발생하고 결과값을 QC에게 전달한다.
select tq_id, server_type, process, num_rows, bytes, waits
from v$pq_tqstat
order by tq_id, decode(substr(server_type,1,4),'Rang',1,'Prod',2,'Cons',3), process;
둘다 파티셔닝 되지 않은 경우 : 동적 파티셔닝
- 어느 한쪽도 조인 컬럼에 대해 파티셔닝이 되지 않은 상황
- 양쪽 테이블이 모두 대용량
pq_distribute(inner table, hash,hash): 조인키 컬럼을 해시 함수에 적용하고 반환된 값을 기준으로 양쪽 테이블을 동적 파티셔닝 하라는 의미
- 양쪽 테이블을 hash partition을 통해 파티셔닝을 한 뒤 해쉬 조인을 하게된다.
STATISTICS COLLECTOR: 통계정보가 없기 때문에 다이나믹 통계수집을 하면서 실행계획을 생성한다.HYBRID HASH: 양쪽 테이블의 키 컬럼에서 조인되지 않는 값들은 굳이 해쉬 파티셔닝 하지 말라는 의미(왜냐하면 크기가 큰 값을 메모리에서 파티셔닝 해서 템프파일에 내리고 하는 작업들이 비효율적이기 때문이다)
alter session set statistics_level = all;
select /*+ leading(d,e) use_hash(e) full(d) full(e) parallel(e 2) parallel(d 2) pq_distribute(e,hash,hash) */ e.employee_id, e.last_name, e.salary, d.department_id, d.department_name
from hr.emp_none e, hr.dept_non d
where e.department_id = d.department_id;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last parallel'));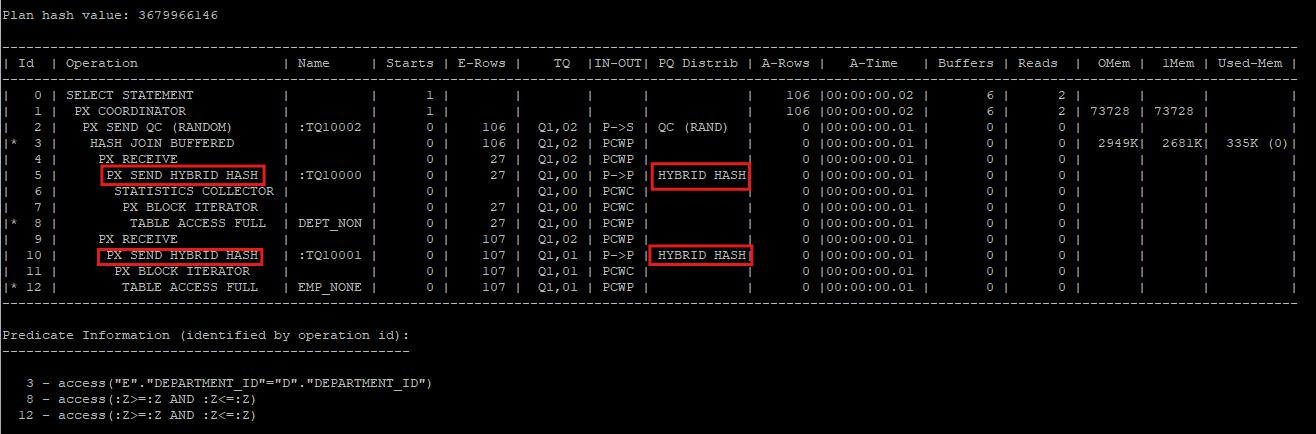
- P000, P001이 각각 department_id을 파티셔닝 키 값으로 hash value들을 만들고 P002,P003으로 부터 데이터를 받아서 해쉬조인을 하게 된다.
- 키 컬럼에 대한 hash value를 봤을때 P000은 (1,3)hash value를 가지고 파티셔닝을 했을 것으로 예상된다.
select tq_id, server_type, process, num_rows, bytes, waits
from v$pq_tqstat
order by tq_id, decode(substr(server_type,1,4),'Rang',1,'Prod',2,'Cons',3), process;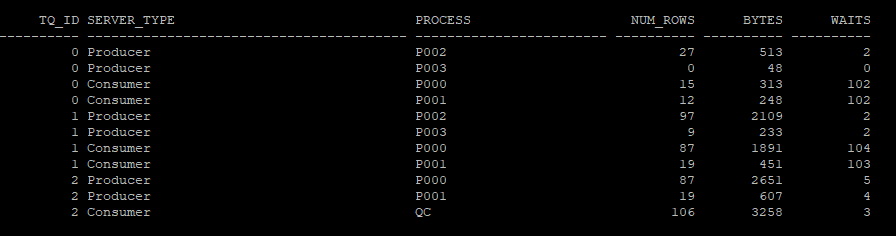
ora_hash(컬럼, hash bucket수,시드 고정값) : 컬럼값의 hash value를 볼 수 있다.
select department_id, ora_hash(department_id,6,0),cnt
from(
select department_id, count(*) cnt
from hr.emp_none
group by department_id)
order by 1,2;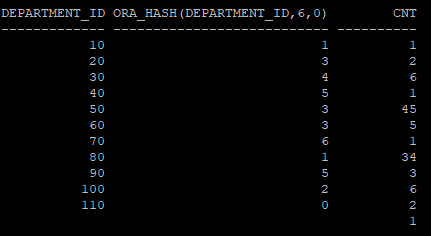
select department_id,ora_hash(department_id,6,0)
from hr.dept_non
order by 1;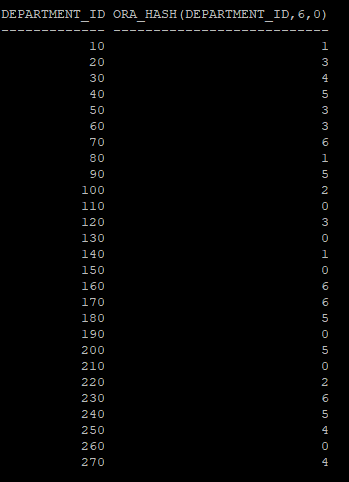
둘다 파티셔닝 되지 않은 경우 : broadcast
- 어느 한쪽도 조인 컬럼에 대한 파티셔닝이 되지 않은 상황
- 둘중 하나의 데이터 집합이 매우 작을때 유용하다.
- 작은 테이블을 복사해서 두개의 테이블로 만들고 각각 큰 테이블의 반쪽에 보내서 consumer process 에서 join 작업을 하고 나머지 테이블도 큰 테이블의 남은 반쪽에 보내서 두번째 consumer process에서 join작업을 한뒤 QC에 보낸다.
pq_distribute(inner table, broadcast,none): 작은 테이블이 큰 테이블쪽으로 브로드캐스트 한다.
- build table이 작은 테이블이기 때문에 큰 테이블로 broadcast 해야한다.
- 원래는 작은테이블 위에 broadcast operation이 나와야 하는데 둘다 너무 작은 테이블이다보니깐 오라클은 굳이 broadcast를 안해도 된다고 판단한것 같다.
select /*+ leading(d,e) use_hash(e) full(d) full(e) parallel(e 2) parallel(d 2) pq_distribute(e,broadcast,none) */ e.employee_id, e.last_name, e.salary, d.department_id, d.department_name
from hr.emp_none e, hr.dept_non d
where e.department_id = d.department_id;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last parallel'));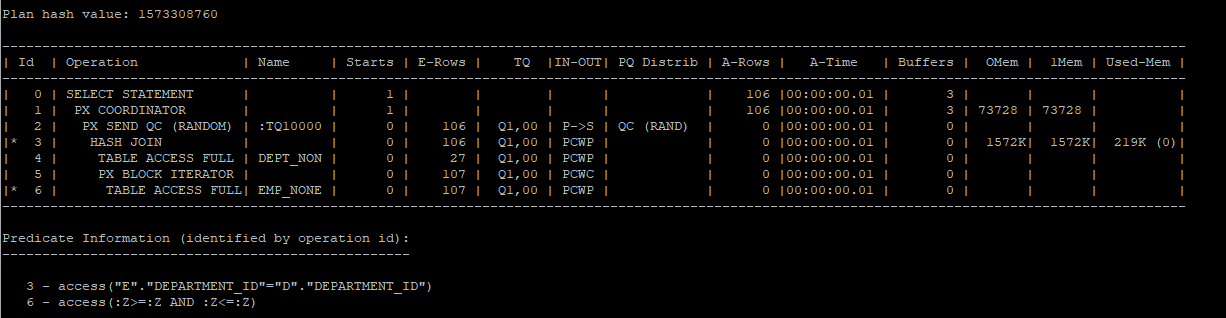
select tq_id, server_type, process, num_rows, bytes, waits
from v$pq_tqstat
order by tq_id, decode(substr(server_type,1,4),'Rang',1,'Prod',2,'Cons',3), process;
병렬 Transaction
create table hr.emp_copy as select * from hr.employees where 1=2;
explain plan for
INSERT /*+ parallel(e1, 2) */ INTO hr.emp_copy e1
SELECT /*+ parallel(e2, 2) */ * FROM hr.employees e2;
-- direct write 방식, 병렬처리 할건데 실행계획부터 볼거임
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
-------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
-------------------------------------------------------------------------------------------------------------------
| 0 | INSERT STATEMENT | | 107 | 7383 | 2 (0)| 00:00:01 | | | |
| 1 | LOAD TABLE CONVENTIONAL | EMP_COPY | | | | | | | |
| 2 | PX COORDINATOR | | | | | | | | |
| 3 | PX SEND QC (RANDOM) | :TQ10000 | 107 | 7383 | 2 (0)| 00:00:01 | Q1,00 | P->S | QC (RAND) |
| 4 | PX BLOCK ITERATOR | | 107 | 7383 | 2 (0)| 00:00:01 | Q1,00 | PCWC | |
| 5 | TABLE ACCESS FULL | EMPLOYEES | 107 | 7383 | 2 (0)| 00:00:01 | Q1,00 | PCWP | |
-------------------------------------------------------------------------------------------------------------------
-- 여기는 CONVENTIONAL LOAD라서 이렇게 하면 안됨PDML is enable in current session
병렬 DML 먼저 켜기(기존 세션 트랜잭션중이면 안되니 새 세션으로 했음)
alter session enable parallel dml;
Session altered.
다시 수행
explain plan for
INSERT /*+ parallel(e1, 2) */ INTO hr.emp_copy e1
SELECT /*+ parallel(e2, 2) */ * FROM hr.employees e2;
-- direct write 방식, 병렬처리 할건데 실행계획부터 볼거임
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
-----------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
-----------------------------------------------------------------------------------------------------------------------------
| 0 | INSERT STATEMENT | | 107 | 7383 | 4 (0)| 00:00:01 | | | |
| 1 | PX COORDINATOR | | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10000 | 107 | 7383 | 4 (0)| 00:00:01 | Q1,00 | P->S | QC (RAND) |
| 3 | LOAD AS SELECT (HYBRID TSM/HWMB)| EMP_COPY | | | | | Q1,00 | PCWP | |
| 4 | OPTIMIZER STATISTICS GATHERING | | 107 | 7383 | 4 (0)| 00:00:01 | Q1,00 | PCWP | |
| 5 | PX BLOCK ITERATOR | | 107 | 7383 | 4 (0)| 00:00:01 | Q1,00 | PCWC | |
| 6 | TABLE ACCESS FULL | EMPLOYEES | 107 | 7383 | 4 (0)| 00:00:01 | Q1,00 | PCWP | |
-----------------------------------------------------------------------------------------------------------------------------=> LOAD AS SELECT : 다이렉트 패스 로드로 하면 LOAD가 안쪽에 들어감. HWM 뒤에 save 방식으로 들어감
병렬 dml 꺼봄(트랜잭션중이면 안되니 안되면 새 세션으로)
alter session disable parallel dml;
Session altered.
병렬트랜잭션 수행하는 힌트로 수행하면 똑같이 병렬트랜잭션함(alter session disable parallel dml;과 같음)
explain plan for
INSERT /*+ enable_parallel_dml parallel(e1, 2) */ INTO hr.emp_copy e1
SELECT /*+ parallel(e2, 2) */ * FROM hr.employees e2;
실행계획 보면 똑같음
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
-----------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
-----------------------------------------------------------------------------------------------------------------------------
| 0 | INSERT STATEMENT | | 107 | 7383 | 4 (0)| 00:00:01 | | | |
| 1 | PX COORDINATOR | | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10000 | 107 | 7383 | 4 (0)| 00:00:01 | Q1,00 | P->S | QC (RAND) |
| 3 | LOAD AS SELECT (HYBRID TSM/HWMB)| EMP_COPY | | | | | Q1,00 | PCWP | |
| 4 | OPTIMIZER STATISTICS GATHERING | | 107 | 7383 | 4 (0)| 00:00:01 | Q1,00 | PCWP | |
| 5 | PX BLOCK ITERATOR | | 107 | 7383 | 4 (0)| 00:00:01 | Q1,00 | PCWC | |
| 6 | TABLE ACCESS FULL | EMPLOYEES | 107 | 7383 | 4 (0)| 00:00:01 | Q1,00 | PCWP | |
-----------------------------------------------------------------------------------------------------------------------------
Note
-----
- Degree of Parallelism is 2 because of table property=> IN-OUT 컬럼에 나올 수 있는 항목
아무것도 안적혀있음 : blank라고 부름. serial 작업할 때 저렇게 나타남
P->S : Parallel To Serial : 각 병렬 서버 프로세스가 처리한 데이터를 QC에게 전송.
PX SEND QC(ORDER) 이 표시가 없을 때는 병렬프로세스들이 무순위로 QC에게 데이터를 전송
P->P : Parallel to Parallel : 데이터 정렬, 그룹핑하거나 조인을 위해 동적으로 파티셔닝 할 때 사용.
첫 번째 병렬 서버 집합이 읽거나 가공한 데이터를 두 번째 병렬 서버 집합에 전송.
S->P : Serial From Parallel : QC가 읽은 데이터를 테이블 큐를 통해 병렬 서버 프로세스에게 전송
(병렬 프로세싱이 되지 않았다는 뜻이므로 문제상황임)
PCWP : Parallel Combineded With Parent : 한 서버 집합이 현재 스탭과 그 부모스탭을 모두 처리할 때
PCWC : Parallel Combineded With Child : 한 서버 집합이 현재 스탭과 그 자식스탭을 모두 처리할 때
