RAC(Real Application Cluster)
- 동일한 데이터베이스에 대해 여러 instance를 실행하여 클러스터화된 하드웨어를 사용할 수 있도록 하는 소프트웨어 입니다.
- 데이터베이스 파일은 각 노드에 물리적 또는 논리적으로 연결된 디스크에 저장되므로 모든 활성 instance에서 읽고 쓸 수 있다.
RAC 장점
- 고가용성
- 24시간 끊김없은 서비스를 지원받을 수 있다.
- 즉 접속한 서버가 다운되었거나 인스턴스가 종료 되어도 나는 다른 서버에서 계속 서비스를 지원 받을 수 있다.
- 확장성
- 노드들을 계속 추가하면서 확장해 나갈 수 있다.
- 노드 갯수는 100개까지 가능하다.
RAC 네트워크 구조
- 공용 네트워크(Public Network)
- 개별 클라이언트 프로그램들은 public network를 통해서 오라클 인스턴스와 통신한다.
- 대부분 통신 SQL*Net(lisnter,tns)을 통해서 이루어진다.
- 전용 인터커넥트(Private Interconnect)
- 각 노드의 인스턴스들은 private interconnect를 통해서 서로 통신한다.
- 기가비트 이더넷(gigabit ethernet)과 UDP PROTOCOL을 사용하는것이 가장 전형적인 구현 방법
- 예) 1gbps 125MB/s, 10gbps 1.25GB/s, 요즘은 100gbps 12.5GB/s
cat /etc/hosts
## Public : 외부 클라이언트들이 노드로 접속할때 사용하는 IP주소
192.168.56.126 rac1
192.168.56.127 rac2
## Private : 노드간의 통신을 하기 위해서 사용되는 IP주소
192.168.55.126 rac1-priv
192.168.55.127 rac2-priv
## Virtual : Failover를 지원하기 위해서 사용되는 IP주소
192.168.56.128 rac1-vip
192.168.56.129 rac2-vip
## grid scan : Failover를 지원하기 위해서 사용되는 IP주소, 많은 Virtual 주소들을 grid scan IP가 관리한다.
192.168.56.130 rac-scanRAC 공유 스토리지(Shared Storage)
- 여러 노드가 데이터를 공유하기 위해서 공유 스토리지를 사용한다.
- 각 노드는 SAN(storage Area Network) 스위치를 통해 스토리지와 통신한다.
RAW DEVICE
- 파일 시스템을 사용하지 않고 원시적인 형태의 디바이스를 의미한다.
- raw device를 사용하는 경우에는 os메모리를 거치지 않고 바로 oracle memory로 올라온다. 별도의 파일시스템 없이 디스크를 직접 액세스한다.
- 장점 : 읽고 쓰는 속도가 빠르다
- 단점 : 관리가 어렵다.
클러스터 파일 시스템(Clustered File System)
- raw device의 불편함. 즉 파일시스템을 사용할 수 없다는 단점으로 인해 클러스터 파일 시스템을 채택하는 경우가 많다.
- 장점 : 관리가 쉽다.
- 단점 : 비용이 많이 들고 잘 깨진다.
- veritas 회사의 라이센스
ASM(Automatic Storage Management)
- 오라클 10g 버전에 출시
- raw device와 클러스터 파일 시스템의 모든 장점인 볼륨메니저 기능 제공
- 자동화 로드맵 중 스토리지에 대한 구현 제공
- 장점 : OS의 RAID기법을 구성하지 않고 오라클이 자동으로 스트라이핑(RAID 0(striping)), 미러링(RAID 1(mirroring))을 지원
- 스트라이핑 단위는 extent단위(1MB)로 하는거 같다.
- 단점 : 초창기(10g) 안정성이 떨어져서 버그에 대한 fix를 해야할 일이 많았다.
Cluster
-
여러대의 컴퓨터들이 연결되어 하나의 컴퓨터처럼 동작하는 기능의 소프트웨어
-
9i 버전까지는 OS의 클러스터 소프트웨어 서비스를 이용해야 했다.
SUN : SUN Cluster
HP : HP - serviceGuard
IBM AIX : HACMP(High Availability Cluster MultiProcessing) -
10g 버전부터 Oracle Cluster 소프트웨어를 지원한다.
- 10g의 g는 Grid
OCR(Oracle Cluster Repository)
-
RAC 구성의 전체 정보를 저장하고 있는 디스크로 RAC에 핵심 역할을 담당한다.
-
RAC를 시작하려면 OCR에 저장되어 있는 정보를 보고 RAC를 구성해야 하는데 10g RAC까지는 RAC 시작후에 ASM instance를 시작하기 때문에 OCR를 ASM에 저장할 경우 RAC를 시작할 수 없게 되었다.
-
단 11g 에서는 이 부분이 개선되어 ASM 디스크를 사용 가능하다.
-
오라클에서 권장하는 OCR최소 크기는 100MB입니다.
-
OCR이 장애가 나면 RAC 전체가 중단된다.
-
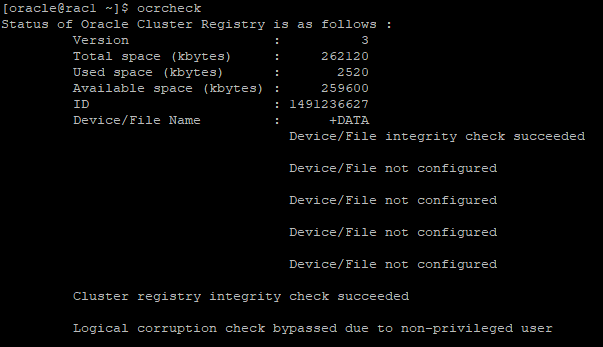
OCR 정보 확인
cat /etc/oracle/ocr.loc- DATA라는 디스크 그룹에 저장되어 있고 global하게 사용이 된다.

ocrcheck
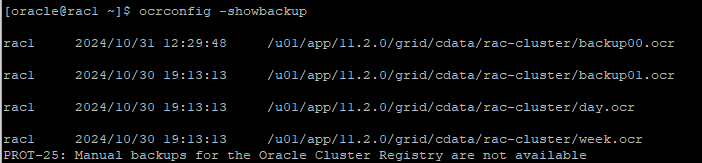
ocrconfig -showbackup - ocr은 자동으로 백업이 받아진다.(4시간마다, 매일, 매주)
- 한쪽 node에만 받아진다.
- DATA라는 디스크 그룹에 저장되어 있고 global하게 사용이 된다.
Vote Disk
-
RAC는 여러개의 instance node들로 구성이 되어 있으며 각 node들이 문제가 있는지 없는지를 실시간으로 파악하고 있어야한다. 그래야 클라이언트들이 요청하는 서비스를 정확하게 연결해 줄 수 있기 때문이다.
-
cssd프로세스: 각 node들이 정상적으로 작동하고 있는지 interconnect을 통해서 매초마다heartbeat를 보내고 각 node들은 그에 대한 응답을 다시 보내어서 자신이 정상적으로 동작하고 있다는 것을 알려 주게 된다. 이런 정보를 vote disk에 저장한다. -
오라클에서 권장하는 vote disk 최소크기는 20MB
-
11g RAC부터는 OCR과 vote disk를 모두 ASM Storage에 저장할 수 있다.
-
vote disk 정보 확인
crsctl query css votedisk- 저장위치를 볼 수 있다.

- 저장위치를 볼 수 있다.
명령어
클러스터 리소스 상태확인
crsctl check crs
- CSS appears healthy(Cluster Synchronization Services)
노드 간의 심장박동(heartbeat)을 보내서 서로 살아있는지 확인하는 역할
관련된 데몬 : cssd - CRS appears healthy(Cluster Ready Services)
고가용성 작업을 보장하기 위한 서비스
관련된 데몬 : crsd - EVM appears healthy(Event Manager)
문제가 발생하면 클러스터 이벤트를 전달하는 서비스
관련된 데몬 : evmd

ps -ef | grep cssd

ps -ef | grep crsd

현재 RAC 상태를 확인
crs_stat -t
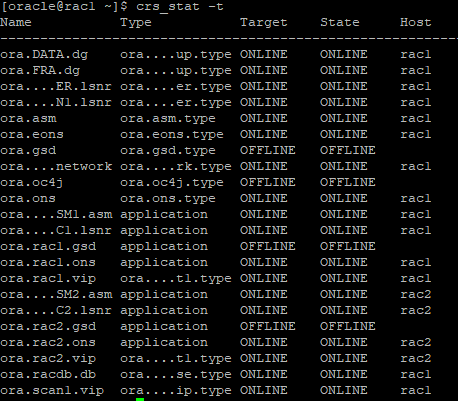
- watch 명령어를 이용해서 n초에 한번씩 refresh하여 실시간 상황을 보여준다.
watch -n 5 crs_stat -t
데이터베이스의 상태
srvctl status database -d racdb(db이름)

특정 인스턴스의 상태
srvctl status instance -d racdb -i racdb1

srvctl status instance -d racdb -i racdb2

모든 node 상태 정보
srvctl status nodeapps
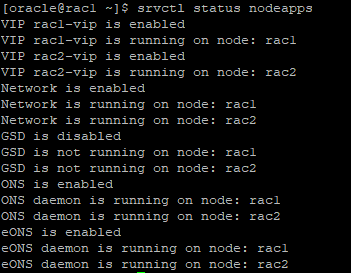
데이터베이스의 종료
- shutdown [normal | transactional | immediate | abort] 같은 옵션들 사용가능
srvctl stop database -d racdb(db이름) -o immediate
데이터베이스의 시작
- startup [nomount | mount | open] 같은 옵션들 사용가능
srvctl start database -d racdb(db이름)
RAC 종료
instance -> asm -> application 순서로 종료
-
instance 종료
srvctl stop instance -d racdb -i racdb1
srvctl stop instance -d racdb -i racdb2 -
asm 종료
srvctl stop asm -n rac1
srvctl stop asm -n rac2 -
application 종료
srvctl stop nodeapps -n rac1
srvctl stop nodeapps -n rac2 -
작업을 한번에 종료 해주는 명령어
crs_stop -all
RAC 시작
application -> asm -> instance 순서로 시작
-
application 시작
srvctl start nodeapps -n rac1
srvctl start nodeapps -n rac2 -
asm 시작
srvctl start asm -n rac1
srvctl start asm -n rac2 -
instance 시작
srvctl start instance -d racdb -i racdb1
srvctl start instance -d racdb -i racdb2 -
작업을 한번에 시작 해주는 명령어
crs_start -all
listener 상태정보
srvctl status listener -n rac1
- enable로 정상상태

srvctl status listener -n rac2
- enable로 정상상태

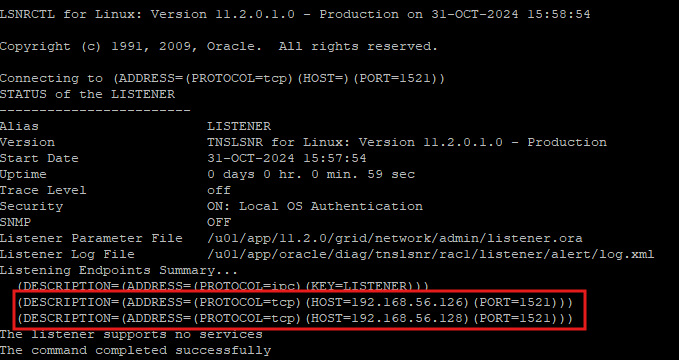
lsnrctl status
- public 주소와 private 주소 둘다 기록되어있다.
- listener.ora 파일이 rac에서는 GRID_HOME에 있다.
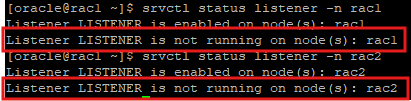
listener 중지
srvctl stop listener -n rac1
srvctl stop listener -n rac2
- 활성화는 되어있지만 실행는 안하고 있다.
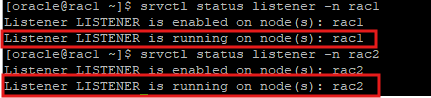
listener 시작
srvctl start listener -n rac1
srvctl start listener -n rac2
TNS로 접속(접속노드 고정)
local에 있는 xe버전 tns 파일 수정
C:\oraclexe\app\oracle\product\11.2.0\server\network\ADMIN
rac1 =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.56.126)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = racdb)
)
)
rac2 =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.56.127)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = racdb)
)
)cmd 창
rac1 node로 접속
sqlplus sys/oracle@rac1 as sysdba
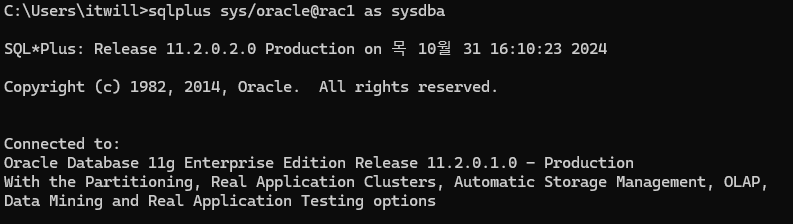
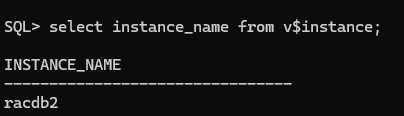
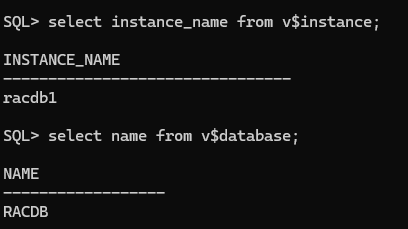
인스턴스 이름과 데이터베이스 이름 확인
rac2 node로 접속
sqlplus sys/oracle@rac2 as sysdba
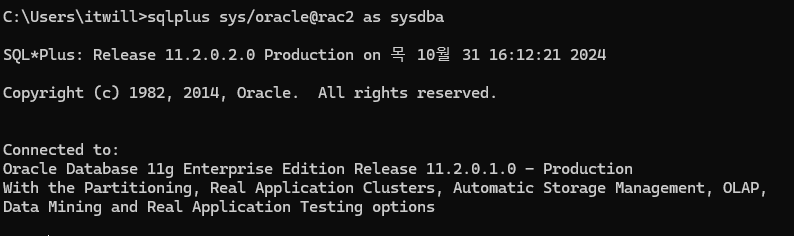
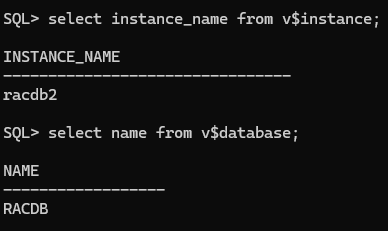
인스턴스 이름과 데이터베이스 이름 확인
Application Failover
Application Failover는 Oracle RAC 환경에서 데이터베이스 세션에 장애가 발생할 경우, 애플리케이션이 자동으로 다른 가용한 노드로 전환하여 지속적으로 작업을 수행할 수 있도록 해주는 기능입니다.
- client tns정보를 이용해서 접속할때 load balancing
- virtual ip 주소를 입력해야한다.
LOAD_BALANCE=YES추가
racdb =
(DESCRIPTION =
(LOAD_BALANCE=YES)
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.56.128)(PORT = 1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.56.129)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = racdb)
)
)
CTF(Connect Time Failover)
-
RAC1 노드에 장애가 있어 접속이 안될경우 관리자의 간섭이나 별다른 조치 없이 자동으로 RAC2 노드로 찾아서 접속하게 만들어서 데이터베이스에 저장된 데이터 접근할 수 있도록 만들어 주는 기능이다.
-
새롭게 접속한 사용자들 입장에서는 장애를 알 수 없고 서비스를 받을 수 있다.
-
단 기존에 RAC1 노드에 접속되어 있던 사용자는 접속이 끊어지고 재접속을 할 경우 자동으로 RAC2노드로 연결이 되며 작업중이였던 transaction은 자동 rollback;
-
tnsnames.ora에서 구현해야한다.
test
1. client tnsnames.ora
racdb =
(DESCRIPTION =
(LOAD_BALANCE=YES)
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.56.128)(PORT = 1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.56.129)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = racdb)
)
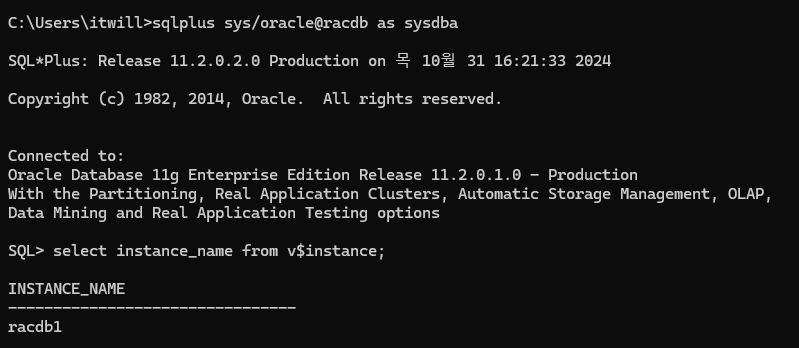
)2. client 접속
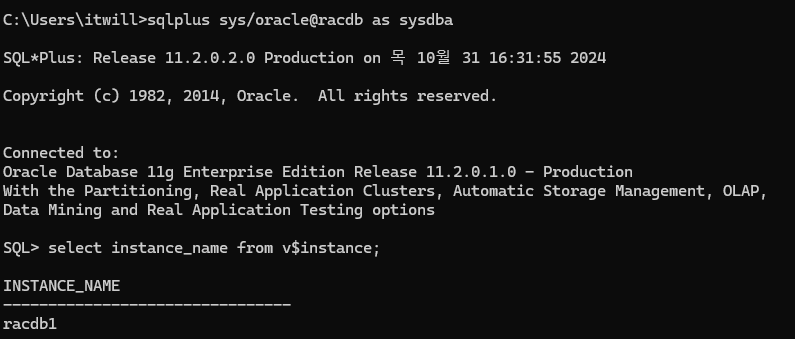
3. RAC1(2) 노드로 접속해서 장애 발생 준비
putty rac1 노드로 접속후 sqlplus 접속
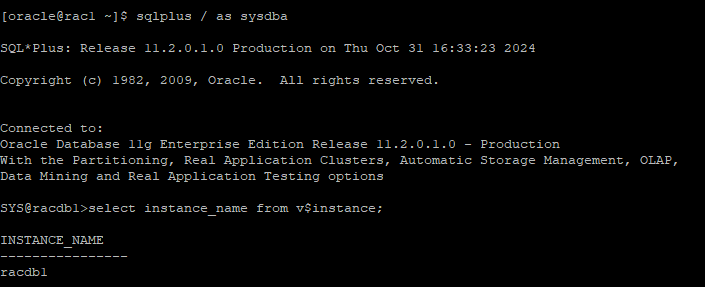
4. client(cmd)에서 select문 수행 준비
- 아직 쿼리 수행 시키면 안된다.
select * from all_objects;
5. 장애 발생(4번을 수행하고 있는 동안)
- client(cmd)에서 쿼리문 수행하자마자 putty rac1에서 shutdown abort수행
- instance가 내려가는거다.
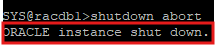
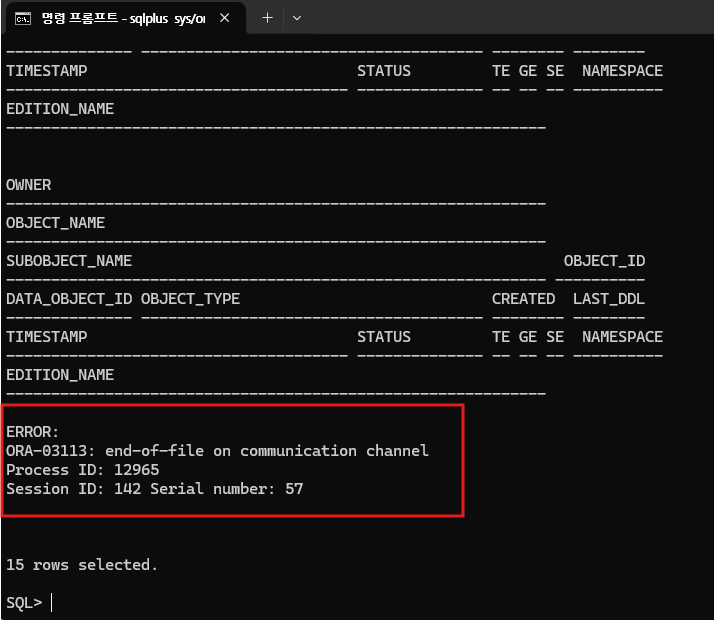
6. 다시 재접속
- 재접속 하니 이전에는 rac1 노드였지만 rac2 노드로 변경되어있다.
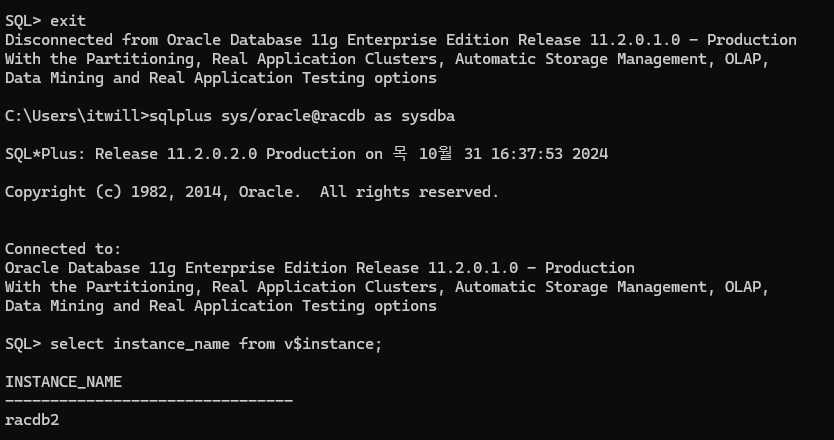
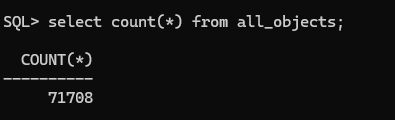
7. 쿼리문 재수행
select count(*) from all_objects;
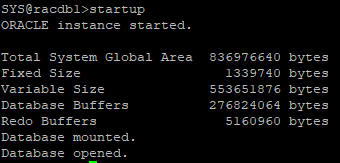
8. rac1 노드에서 다시 startup
startup
TAF(Transparent Application Failover)
- RAC1 노드에 장애가 발생되어 인스턴스가 비정상 종료되어도 RAC1에서 작업을 하던 사용자의 작업이 RAC2 노드로 그대로 넘어가서 사용자는 계속 작업을 지속할 수 있다.
- 단 이 작업은 SELECT작업에만 적용이 가능하다.
- tnsnames.ora에서 구현해야한다.
FAILOVER 기능 활성화, 기본값은 NO(OFF)
FAILOVER=YES(ON) | NO(OFF)
TYPE=SESSION | SELECT | NONE
SESSION
클라이언트가 SELECT를 수행하고 있는 도중에 해당 인스턴스가 장애가 나서 중단 될 경우, 수행하던 SELECT문은 에러가 발생하고 중단된다. 그리고 문제가 없는 다른 노드로 자동으로 재접속이 된다.SELECT
SESSION보다 발전한 방법으로 기존 노드에서 수행중이던 SELECT문장을 새로운 노드에 접속한 후 계속 수행해서 오류 없이 결과를 만들어 준다.
METHOD=BASIC | PRECONNECT
- BASIC
장애가 발생할 경우 다른 노드를 찾아서 재접속을 시도하는 방식 - PRECONNECT
처음 접속을 할 때 장애를 대비해서 두개의 접속을 미리 수행하는 방식
노드의 수가 많을 경우 찾는 수고를 덜기위해
test1. type=session
1. client tnsnames.ora
racdb_taf =
(DESCRIPTION =
(LOAD_BALANCE=YES)(FAILOVER=YES)
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.56.128)(PORT = 1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.56.129)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = racdb)
(FAILOVER_MODE=(TYPE=SESSION)(METHOD=BASIC))
)
)2. client 접속
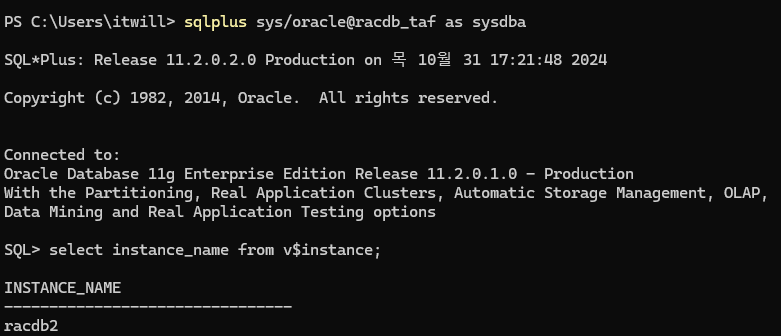
3. RAC2(1) 노드로 접속해서 장애 발생 준비
putty rac2 노드로 접속후 sqlplus 접속
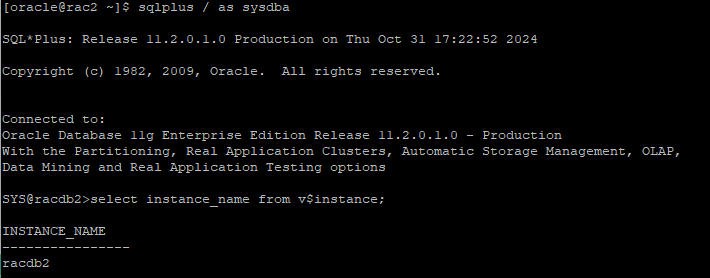
4. client(cmd)에서 select문 수행 준비
- 아직 쿼리 수행 시키면 안된다.
select * from all_objects;
5. 장애 발생(4번을 수행하고 있는 동안)
- client(cmd)에서 쿼리문 수행하자마자 putty rac2에서 shutdown abort수행
- instance가 내려가는거다.

6. 쿼리문만 실패되고 세션은 끊기지 않은 상태에서 재접속이 되었다.
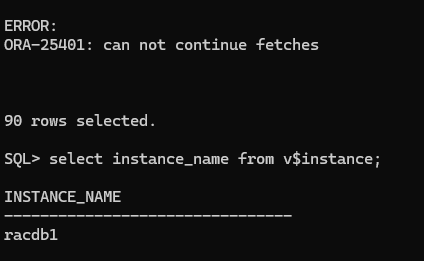
7. 쿼리문 재수행
select count(*) from all_objects;
test2. type=select
1. client tnsnames.ora
racdb_taf =
(DESCRIPTION =
(LOAD_BALANCE=YES)(FAILOVER=YES)
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.56.128)(PORT = 1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.56.129)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = racdb)
(FAILOVER_MODE=(TYPE=SELECT)(METHOD=BASIC))
)
)2. client 접속
3. RAC1(2) 노드로 접속해서 장애 발생 준비
putty rac1 노드로 접속후 sqlplus 접속
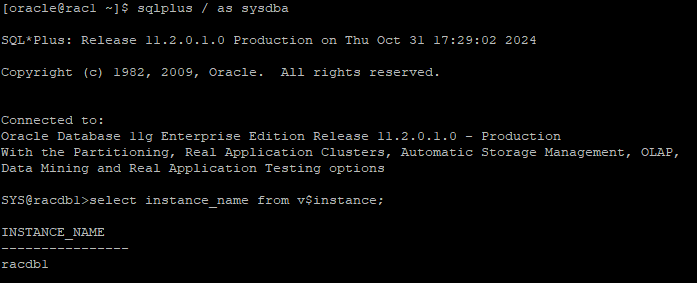
4. client(cmd)에서 select문 수행 준비
- 아직 쿼리 수행 시키면 안된다.
select * from all_objects;
5. 장애 발생(4번을 수행하고 있는 동안)
- client(cmd)에서 쿼리문 수행하자마자 putty rac1에서 shutdown abort수행
- instance가 내려가는거다.
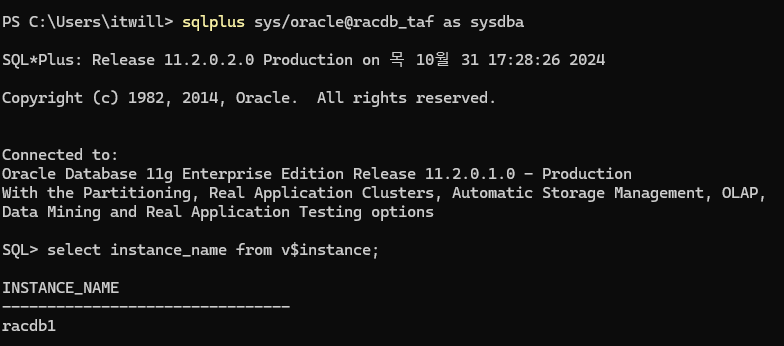
6.쿼리문은 실패되지도 않고 세션이 끊기지 않은 상태에서 재접속이 된다.
7. 재접속된 노드 확인
select instance_name from v$instance;