Global Cache(buffer)
- RAC 시스템은 개별 인스턴스의 버퍼 캐시를 통합해서 마치 하나의 글로벌 캐시처럼 사용한다.
- 사용자는 현재 특정 블록이 어떤 인스턴스의 버퍼캐시에 있는지 알 필요가 없으며 캐시통합은 오라클 캐시 퓨전(cache fusion) 메커니즘에 의해 자동으로 이루어진다.
Cache Fusion
- 인스턴스간에 데이터를 융합(fusion)해서 사용하는 것을 말하며 오라클이 RAC의 글로벌 버퍼 동기화 과정을 개념적으로 설명하기 위해 만든 용어
- interconnect를 통한 효율적인 글로벌 버퍼 동기화를 수행한다.
- 디스크가 아닌 interconnect를 통한 블록 전송과 메모리 동기화가 캐시퓨전의 핵심
- cache fusion은 physical i/o일때 발생한다.
GRD(Global Resource Directory)
- RAC를 구성하는 각 인스턴스들은 개별 자원들에 대한 메타 정보를 GRD에서 관리한다.
- 모든 인스턴스에는 GRD가 있고 각각이 마스터 노드의 성격을 가진다.
- 분산 메모리 데이터베이스 일종이다.
- 어느 노드에 최신의 데이터가 있는지에 대한 위치 정보와 lock정보를 shared pool에서 관리한다.
- 즉 GRD는 shared pool에 있다.
GRD가 관리하는 서비스
-
GCS(Global Cache Service)
- 노드간의 데이터를 전송하는 서비스
- 데이터(블록) 전송 데몬 :LMS
show parameter gcs_server_processes
cpu 개수가 4개마다 1개의 LMS 프로세스 사용

-
GES(Global Enqueue Service)
- 노드간의 발생하는 락을 관리하는 서비스
- 글로벌 enqueue를 담당하는 데몬 :LMD,LCK -
CGS(Cluster Group Service)
- 클러스터의 멤버십을 관리
- 클러스터를 모니터링하면서 노드의 가입이나 탈퇴에 따른 클러스터의 상태를 관리
- 데몬 :LMON
node의 종류
- Master Node
- 역할: 특정 블록에 대한 중앙 관리 책임을 가진 노드로, GRD(Global Resource Directory)를 통해 어떤 노드가 해당 블록을 보유하고 있는지 또는 어떤 상태인지 추적합니다.
- 주요 작업:
- 블록 전송: 요청받은 블록을 자신이 가지고 있는 경우, 요청한 노드(Request Node)로 직접 전송합니다.
- Grant Message 전달: 클러스터 내에서 어느 노드도 해당 블록을 가지고 있지 않으면 Request Node에 블록을 공유(Shared) 모드로 적재할 수 있는 권한(Grant Message)을 부여합니다.
- Holder Node에게 요청 전달: 만약 블록을 다른 노드(Holder Node)가 보유하고 있다면, 해당 Holder Node의 LMS 프로세스에 블록 전송을 요청합니다.
- Request Node
- 역할: 블록을 필요로 하는 노드로, SQL 쿼리 등의 요청이 발생했을 때 필요한 블록을 Master Node에 요청합니다.
- 주요 작업:
- Master Node에 요청: 요청한 블록이 자신의 캐시에 없으면, Master Node에 블록 전송을 요청합니다.
- 블록 수신 및 캐싱: Master Node 또는 Holder Node로부터 블록을 수신하면, 자신의 버퍼 캐시에 적재하여 필요 작업을 수행합니다.
- Holder Node
- 역할: 해당 블록을 보유하고 있는 노드로, 다른 노드가 해당 블록을 요청하면 블록을 전송할 책임이 있습니다.
- 주요 작업:
- Request Node에 블록 전송: 자신이 보유한 블록이 요청되면, 인터커넥트를 통해 LMS(Lock Manager Server) 프로세스를 사용하여 Request Node에 블록을 전송합니다.
GRD 시나리오
준비단계
-
hr 유저계정 상태 확인
select username, account_status from dba_users where username='HR';

-
계정정보 변경
alter user hr identified by hr account unlock;

-
변경정보 확인
select username, account_status from dba_users where username='HR';

-
찾고자 하는 데이터의 파일 id, block id 확인
select
dbms_rowid.rowid_relative_fno(rowid) as file_no,
dbms_rowid.rowid_block_number(rowid) as block_no
from hr.employees
where employee_id = 100;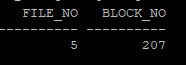
- 현재 100번 아이디에 해당하는 블록이 버퍼캐시에 올라와있는지 각 노드에서 확인
- 1번 노드 2번노드 둘다 올라와 있지 않다.
select b.lock_element_addr, b.status, e.mode_held, e.local
from v$bh b, v$gc_element e
where b.lock_element_addr = e.gc_element_addr
and b.file# = 5
and b.block# = 207;
시나리오 1: 1번 노드에서 첫 번째 SELECT 수행
-
쿼리 실행 및 블록 요청:
- 1번 노드의 사용자가
SELECT * FROM hr.employees WHERE employee_id = 100;쿼리를 실행하며, [5,207] 블록을 요청합니다.
- 1번 노드의 사용자가
-
Null 모드로 블록 할당:
- 1번 노드에 [5,207] 블록이 캐시되어 있지 않으므로, Free 버퍼를 찾아 Null 모드(NL0)로 블록을 획득합니다. 이때 buffer cache lock을 exclusive로 설정하여 캐시 공간을 확보합니다.
-
마스터 노드에 요청:
- GRD 상에서 마스터 노드 역할을 하는 2번 노드에 블록을 요청합니다. 이때 1번 노드는
gc cr requestwait event 상태에서 응답을 기다립니다.
- GRD 상에서 마스터 노드 역할을 하는 2번 노드에 블록을 요청합니다. 이때 1번 노드는
-
마스터 노드에서 GRD 정보 확인:
- 2번 노드의 GRD(Global Resource Directory)가 어떤 노드도 [5,207] 블록을 보유하고 있지 않음을 확인하고, 1번 노드에 Shared 모드로 블록 적재 권한을 부여합니다. 이때
gc cr/current grant 2-waywait event가 발생할 수 있습니다.
- 2번 노드의 GRD(Global Resource Directory)가 어떤 노드도 [5,207] 블록을 보유하고 있지 않음을 확인하고, 1번 노드에 Shared 모드로 블록 적재 권한을 부여합니다. 이때
-
1번 노드에서 디스크 I/O 수행:
- 권한을 획득한 1번 노드는 디스크에서 해당 블록을 읽어 캐시에 적재하며, 이 과정에서
db file sequential readwait event가 발생할 수 있습니다.
- 권한을 획득한 1번 노드는 디스크에서 해당 블록을 읽어 캐시에 적재하며, 이 과정에서
-
Shared 모드로 블록 변경 및 GRD 업데이트:
-
1번 노드는 블록을 Null 모드에서 Shared 모드(SCUR)로 변경하고, Buffer Cache Lock도 Shared 모드로 전환합니다. 이를 통해 1번 노드에서 해당 블록에 읽기 전용 접근이 가능해지며, 다른 노드와의 동시 읽기 공유가 허용됩니다.
-
마지막으로, GRD 정보를 업데이트하여 [5,207] 블록이 1번 노드의 Shared 모드로 존재함을 기록합니다.
-
결과
1번 노드의 캐시에 [5,207] 블록이 Shared 모드(SCUR)로 적재되며, Buffer Cache Lock도 Shared 모드로 설정되어 읽기 전용 접근이 가능해집니다. 이는 이후 다른 노드가 동일한 블록에 접근할 때 동시 읽기 공유가 가능하도록 지원하는 설정입니다.
**
[1번 노드]
select b.lock_element_addr, b.status, e.mode_held, e.local
from v$bh b, v$gc_element e
where b.lock_element_addr = e.gc_element_addr
and b.file# = 5
and b.block# = 207;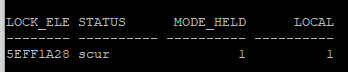
scur 상태
- RAC모드에서 블록이 공유 상태임을 나타냅니다 (Shared Current).
- 클러스터 내의 같은 블록에 대해 여러 인스턴스가 scur모드의 블록 상태를 가질 수 있다.
mode_held 컬럼
- 0(null)
- 1(shared)
- 2(exclusive 트랜잭션 작업할때)
local 컬럼
- 1(local)
- 0(global)
시나리오 2: 2번 노드에서 동일 블록 조회 (Select-Select Cache Fusion)
-
쿼리 실행 및 블록 요청
- 2번 노드의 사용자가
SELECT * FROM hr.employees WHERE employee_id = 100;쿼리를 실행하며, [5,207] 블록을 요청합니다.
- 2번 노드의 사용자가
-
마스터 노드에 요청
- 2번 노드는 마스터 노드에 블록 요청을 보냅니다.
-
GRD 정보 확인 및 블록 전송 요청
- 마스터 노드는 GRD를 통해 1번 노드의 버퍼 캐시에 해당 블록이 Shared 모드(SCUR)로 존재함을 확인하고, 1번 노드에 2번 노드로의 블록 전송을 요청합니다.
-
2번 노드의 대기 상태
- 이때 2번 노드는 블록을 기다리며
gc cr requestwait event가 발생합니다.
- 이때 2번 노드는 블록을 기다리며
-
1번 노드의 블록 전송 (Select-Select Cache Fusion)
- 1번 노드의 LMS 프로세스가 Interconnect를 통해 2번 노드에 블록을 전송합니다. 이를 Select-Select Cache Fusion이라고 하며,
gc cr/current block 2-waywait event가 발생합니다. (3개 이상의 노드에서는3-way로 나타납니다)
- 1번 노드의 LMS 프로세스가 Interconnect를 통해 2번 노드에 블록을 전송합니다. 이를 Select-Select Cache Fusion이라고 하며,
-
Shared 모드로 변경 및 GRD 갱신 요청
-
2번 노드는 블록을 Null 모드에서 Shared 모드(SCUR)로 변경하고, Buffer Cache Lock도 Shared 모드로 전환합니다. 이를 통해 2번 노드의 버퍼 캐시에서 해당 블록에 읽기 전용 접근이 가능해지며, 다른 노드와의 동시 읽기 공유가 가능합니다.
-
또한, GRD에 이 정보를 갱신하도록 요청하여 블록이 Shared 모드로 적재되었음을 알립니다.
-
결과
[5,207] 블록이 1번 노드와 2번 노드 모두의 Shared 모드(SCUR)로 존재하며, 각 노드는 동일한 블록을 읽기 전용으로 접근할 수 있습니다. 이때 Buffer Cache Lock도 Shared 모드로 설정되어, 다중 노드에서의 동시 읽기 공유를 지원하게 됩니다.
[2번 노드]
select b.lock_element_addr, b.status, e.mode_held, e.local
from v$bh b, v$gc_element e
where b.lock_element_addr = e.gc_element_addr
and b.file# = 5
and b.block# = 207;
1번 노드 버퍼캐시에 있던 블록이 2번노드 버퍼캐시로 블록이미지가 이동되었다.
[1번 노드]
select b.lock_element_addr, b.status, e.mode_held, e.local
from v$bh b, v$gc_element e
where b.lock_element_addr = e.gc_element_addr
and b.file# = 5
and b.block# = 207;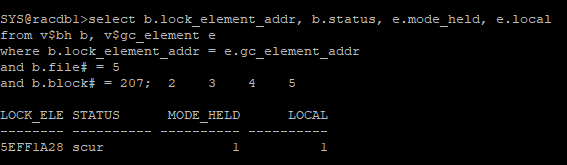
시나리오 3: select(shared) - dml(exclusive)
-
쓰기(DML) 요청
- RAC2 노드의 사용자가 [5,207] 블록에 대한 쓰기(DML) 작업을 요청합니다.
-
GRD 정보 확인
- 마스터 노드는 GRD(Global Resource Directory)를 통해 RAC1 노드에 [5,207] 블록이 Shared 모드(SCUR)로 존재하고 있음을 확인합니다.
-
Shared 모드에서 Null 모드로 다운그레이드 요청
- 마스터 노드는 RAC1 노드에 [5,207] 블록을 Shared 모드에서 Null 모드로 다운그레이드하도록 요청합니다. 이를 통해 RAC1 노드는 해당 블록에 대한 읽기 권한을 포기하게 됩니다.
-
Exclusive 모드로 전환
- RAC1 노드가 블록을 Null 모드로 변경하면, RAC2 노드는 [5,207] 블록을 Exclusive 모드(XCUR)로 가져와 쓰기 작업을 수행할 수 있습니다.
-
GRD 정보 갱신
- 마스터 노드는 GRD에 [5,207] 블록이 RAC2 노드의 Exclusive 모드로 존재하게 되었음을 갱신하여 다른 노드들이 최신 정보를 사용할 수 있게 합니다.
최종 상태
- RAC2 노드는 [5,207] 블록을 Exclusive 모드(XCUR)로 보유하고 있으며, 쓰기 작업을 수행할 수 있습니다.
- RAC1 노드는 [5,207] 블록에 대한 접근 권한이 없는 상태(NL0)로 전환되어, 이후 필요 시 다시 요청할 수 있습니다.
[1번 노드]
select b.lock_element_addr, b.status, e.mode_held, e.local
from v$bh b, v$gc_element e
where b.lock_element_addr = e.gc_element_addr
and b.file# = 5
and b.block# = 207;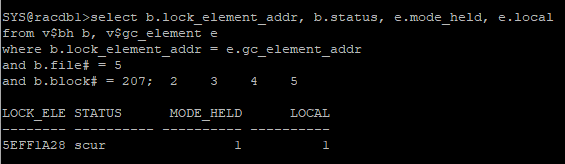
[2번 노드]
select b.lock_element_addr, b.status, e.mode_held, e.local
from v$bh b, v$gc_element e
where b.lock_element_addr = e.gc_element_addr
and b.file# = 5
and b.block# = 207;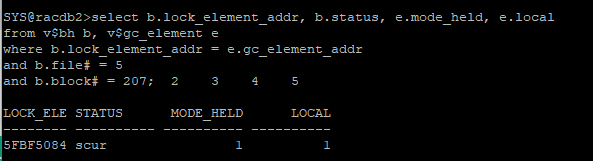
- 업데이트
update hr.employees
set salary = 20000
where employee_id = 101;- rac2에서 확인
- exclusive 모드로 변경되었다.
select b.lock_element_addr, b.status, e.mode_held, e.local
from v$bh b, v$gc_element e
where b.lock_element_addr = e.gc_element_addr
and b.file# = 5
and b.block# = 207;
[1번 노드]
- null모드로 다운그레이드되어서 조회되지 않는다.
select b.lock_element_addr, b.status, e.mode_held, e.local
from v$bh b, v$gc_element e
where b.lock_element_addr = e.gc_element_addr
and b.file# = 5
and b.block# = 207;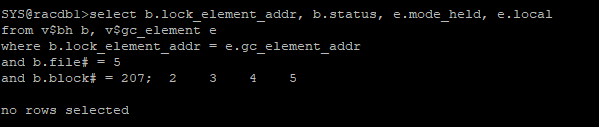
RAC1 노드의 블록이 Null 모드로 변경되더라도 해당 블록은 여전히 RAC1의 데이터 버퍼 캐시에 남아 있습니다. 단, 이 블록은 읽기 또는 쓰기 작업에 사용할 수 없는 상태이며, 이후 다시 요청이 발생하면 필요한 권한을 부여받아 활성화될 수 있습니다.
이유
버퍼 캐시에 남아 있는 이유: RAC는 캐시 메모리 사용을 최적화하기 위해 버퍼 캐시에 있는 블록을 완전히 제거하지 않고 Null 모드(NL0)로 전환하여 일시적으로 비활성화하는 방식을 사용합니다. 필요 시 해당 블록을 다시 활성화하기 위해 재활용할 수 있기 때문입니다.
상태 변화만 발생: RAC1의 [5,207] 블록이 Null 모드가 되어도, 데이터는 여전히 버퍼 캐시에 남아 있으며, 상태가 Shared 또는 Exclusive 모드로 전환되면 다시 접근 가능해집니다.
Null 모드의 의미
- Null 모드는 해당 블록에 대한 권한을 해제한 상태이므로, 다른 노드가 독점 권한을 가져갈 수 있습니다.
- 데이터가 캐시에서 사라지는 것은 아니며, 필요 시 빠르게 다시 활성화할 수 있도록 캐시에 남아 있게 됩니다.
따라서, Null 모드로 전환되더라도 블록 자체는 버퍼 캐시에 남아 있으며, 추가 요청에 대비하는 방식으로 Oracle RAC는 캐시 효율성을 높이고 있습니다.
Oracle RAC에서 RAC2 노드가 롤백을 하더라도 RAC1의 Null 모드가 자동으로 Shared 모드로 돌아오지 않고, RAC2의 Exclusive 모드 역시 자동으로 Shared로 변경되지 않습니다. 이는 RAC의 락 모드와 블록 상태 관리 방식에 따른 것으로, 다음과 같은 이유가 있습니다.
이유
1. 블록 상태의 명시적 요청 필요:
- 블록 상태는 각 노드가 명시적으로 해당 블록을 요청할 때마다 업데이트됩니다. RAC1의 Null 모드 블록이 자동으로 Shared로 돌아오지 않는 이유는, RAC1이 명시적으로 다시 블록을 요청하지 않았기 때문입니다.
- 동일하게, RAC2의 Exclusive 모드 역시 RAC1이나 다른 노드가 다시 요청하지 않으면 Shared로 변경되지 않고 그대로 유지됩니다.
- 락 모드 효율성:
- 블록을 롤백했을 때 자동으로 다른 노드가 해당 블록을 Shared 모드로 가져가게 하면, 불필요한 락 모드 전환이 자주 발생하여 성능에 영향을 줄 수 있습니다.
- Oracle RAC는 필요한 경우에만 명시적으로 요청이 들어오면 상태를 변경하도록 설계되어, 불필요한 자원 소모를 줄입니다.
- GRD 관리 방식:
- GRD(Global Resource Directory)는 노드의 명시적 요청에 따라 락 모드를 전환하며, 자동으로 상태를 되돌리는 방식이 아니라 요청 기반의 효율적인 락 관리를 수행합니다.
요약
RAC 환경에서 롤백 후 블록 상태가 자동으로 변경되지 않는 것은 락 관리와 성능 최적화에 따른 결과입니다. 이후 RAC1이나 다른 노드가 [5,207] 블록을 다시 요청하면, 필요한 권한(Shared 또는 Exclusive)에 따라 GRD가 적절히 상태를 조정하게 됩니다.
시나리오 4: RAC1에서 Null 모드 블록을 다시 SELECT (Null to Shared 모드 전환)
-
RAC1에서 블록 요청 (SELECT)
- RAC1의 사용자가
SELECT * FROM hr.employees WHERE employee_id = 100;쿼리를 실행하며, [5,207] 블록을 요청합니다. - 현재 RAC1의 데이터 버퍼 캐시에는 [5,207] 블록이 Null 모드(NL0)로 존재하고 있으므로, Shared 모드로 블록을 획득하기 위해 GRD에 Shared 모드 전환 요청을 보냅니다.
- RAC1의 사용자가
-
마스터 노드로 요청 전달
- RAC1은 [5,207] 블록의 마스터 노드인 RAC2에 Shared 모드 전환을 요청합니다. 이때
gc cr requestwait event가 발생하여 응답을 기다리게 됩니다.
- RAC1은 [5,207] 블록의 마스터 노드인 RAC2에 Shared 모드 전환을 요청합니다. 이때
-
GRD 정보 확인
- RAC2의 GRD(Global Resource Directory)는 현재 [5,207] 블록이 RAC2에서 Exclusive 모드(XCUR)로 존재하고 있음을 확인합니다.
-
Exclusive 모드 해제 및 Shared 모드로 다운그레이드
- 마스터 노드는 RAC2에게 [5,207] 블록의 Exclusive 모드를 Shared 모드로 다운그레이드하라고 요청합니다.
- RAC2는 Exclusive 모드를 Shared 모드(SCUR)로 전환하여, 다른 인스턴스에서도 해당 블록을 읽을 수 있도록 준비합니다.
-
RAC1에 Shared 모드로 블록 전송
- RAC2는 LMS 프로세스를 통해 Interconnect를 사용하여 [5,207] 블록을 Shared 모드로 RAC1에 전송합니다. 이 과정에서
gc cr/current block 2-waywait event가 발생합니다.
- RAC2는 LMS 프로세스를 통해 Interconnect를 사용하여 [5,207] 블록을 Shared 모드로 RAC1에 전송합니다. 이 과정에서
-
RAC1에서 Shared 모드로 블록 캐싱 및 GRD 갱신
- RAC1은 Shared 모드로 [5,207] 블록을 버퍼 캐시에 적재하고, Buffer Cache Lock도 Shared 모드로 전환하여 읽기 전용 접근이 가능하도록 합니다.
- 마지막으로 GRD에 이 정보를 업데이트하여 [5,207] 블록이 RAC1과 RAC2 모두에서 Shared 모드(SCUR)로 존재함을 기록합니다.
시나리오 5: Write (DML 수행 중) - Select (Consistent Read 요청)
- RAC2에서 Exclusive 모드로 DML 작업 수행
- RAC2 노드의 사용자가 [5,207] 블록을 Exclusive 모드(XCUR)로 획득하여 DML 작업을 수행합니다.
- 이 작업으로 인해 RAC2 노드의 버퍼 캐시에 [5,207] 블록이 Exclusive 모드로 존재하게 됩니다.
update hr.employees
set salary = 20000
where employee_id = 101;- RAC1에서 Select로 블록 읽기 요청
- RAC1 노드의 사용자가 [5,207] 블록에 대해 읽기 요청을 합니다.
SELECT * FROM hr.employees WHERE employee_id = 100;
- RAC1 노드의 사용자가 [5,207] 블록에 대해 읽기 요청을 합니다.
- GRD에서 Exclusive 모드 확인
- 마스터 노드는 GRD를 통해 현재 [5,207] 블록이 RAC2 노드에서 Exclusive 모드로 작업 중임을 확인합니다.
select b.lock_element_addr, b.status, e.mode_held, e.local
from v$bh b, v$gc_element e
where b.lock_element_addr = e.gc_element_addr
and b.file# = 5
and b.block# = 207;
- CR 블록 생성 요청
- RAC2 노드는 RAC1 노드에 Consistent Read (CR) 블록을 전송해야 합니다. 이때 아직
COMMIT이 이루어지지 않았으므로, 언두(Undo)에 저장된 이전 블록 이미지를 사용해 CR 블록을 생성해야 합니다.
- RAC2 노드는 RAC1 노드에 Consistent Read (CR) 블록을 전송해야 합니다. 이때 아직
- 불완전한 CR COPY 블록 전송
- RAC2 노드의 LMS 프로세스는 불완전한 상태의 CR COPY 블록을 먼저 생성하여 RAC1에 Exclusive 모드로 전송합니다. 이 불완전한 블록은 LMS 프로세스의 부하를 줄이기 위해 Undo 정보 적용 없이 전송되며, 최종 CR 블록 생성 작업은 RAC1에서 이루어집니다.
- RAC1에서 최종 CR 블록 생성 및 Shared 모드 변경
- RAC1은 수신한 불완전한 CR COPY 블록을 자체적으로 완성하여 최종 CR 블록을 생성합니다. 이 과정에서 Undo 정보를 사용하여 Consistent Read 버전을 완성합니다.
- 이 최종 CR 블록은 Shared 모드(SCUR)로 변경되어 RAC1의 버퍼 캐시에 적재됩니다.
최종상태
- RAC1 노드는 완성된 CR 블록을 Shared 모드(SCUR)로 캐시에 보유하게 되며, 읽기 전용 접근이 가능해집니다.
- RAC2 노드는 여전히 Exclusive 모드로 [5,207] 블록을 보유하며, COMMIT 또는 ROLLBACK이 이루어질 때까지 DML 작업을 계속 수행할 수 있습니다.
시나리오 6 : RAC2 노드에서 DML에 대한 Commit 이후 RAC1 노드에서 SELECT
-
RAC1에서 블록 읽기 요청 (SELECT)
- RAC1 노드의 사용자가 [5,207] 블록에 대해 읽기 요청을 합니다.
- 이에 따라 RAC1은 마스터 노드에 [5,207] 블록의 공유 모드(SCUR) 요청을 보냅니다.
-
GRD에서 최신 정보 확인
- 마스터 노드는 GRD(Global Resource Directory)를 통해 RAC2 노드가 [5,207] 블록을 Exclusive 모드(XCUR)로 보유하고 있음을 확인합니다.
-
트랜잭션 상태 및 모드 확인 후 다운그레이드
- 마스터 노드는 RAC2에서 [5,207] 블록에 대한 트랜잭션이 커밋된 상태임을 확인하고, Exclusive 모드를 Shared 모드(SCUR)로 다운그레이드합니다.
-
RAC2에 블록 전송 요청
- 마스터 노드는 RAC2에게 다운그레이드된 [5,207] 블록을 RAC1로 전송하도록 요청합니다.
-
RAC2에서 RAC1로 블록 전송 (LMS 작업)
- RAC2 노드는 LMS 프로세스를 통해 Interconnect를 사용하여 [5,207] 블록을 Shared 모드(SCUR)로 RAC1 노드에 전송합니다.
-
RAC1에서 블록 모드 변경
- RAC1은 수신한 [5,207] 블록을 Null 모드에서 Shared 모드(SCUR)로 변경하고, 버퍼 캐시에 적재합니다.
-
GRD 정보 갱신 요청
- RAC1은 마스터 노드에 GRD 정보를 갱신하도록 요청하여, [5,207] 블록이 RAC1과 RAC2 모두에서 Shared 모드로 존재함을 기록합니다.
최종상태
RAC1과 RAC2 모두 [5,207] 블록을 Shared 모드(SCUR)로 보유하게 되어, 두 노드 모두 해당 블록에 대해 읽기 전용 접근이 가능해집니다.
시나리오 7 :Write - Write (서로 다른 행이지만 동일한 블록에 대해 동시에 Write 작업)
상황 요약
RAC1 노드에서 특정 행(예: 100번 행)을 변경한 후, RAC2 노드가 동일한 블록([5,207])의 다른 행(예: 101번 행)에 대해 Write 작업을 수행하고 Exclusive 모드를 보유한 상태입니다. 이후 RAC1 노드에서 변경된 100번 행의 값을 다시 조회하려고 할 때 Redo 로그를 사용하는 과정을 설명합니다.
-
RAC2에서 [5,207] 블록 쓰기 요청
- RAC2 노드의 사용자가 [5,207] 블록에 대해 쓰기(DML) 요청을 합니다.
-
GRD에서 Exclusive 모드 확인
- 마스터 노드(RAC2에 위치한 GRD)는 RAC1이 [5,207] 블록을 Exclusive 모드(XCUR)로 보유하고 있는 것을 확인합니다.
-
RAC1의 PI(Past Image) 블록 생성 및 전송 준비
- RAC1 노드는 Exclusive 모드의 [5,207] 블록을 PI(Past Image) 모드로 다운그레이드하여, 변경된 데이터의 이전 이미지를 보존한 후 RAC2에 전송합니다.
- 이때, RAC1 노드는 Redo 로그에 현재 변경 사항을 기록하여, 이후 변경 내역을 재구성할 수 있도록 합니다.

-
RAC2에서 Exclusive 모드로 블록 획득
- RAC2 노드는 Exclusive 모드로 [5,207] 블록을 획득하고 쓰기 작업을 수행할 수 있습니다.
- 마스터 노드는 GRD에 [5,207] 블록이 RAC2의 Exclusive 모드로 보유되고 있음을 갱신합니다.
-
RAC1에서 변경된 데이터 조회 요청
- 이후, RAC1에서 동일한 [5,207] 블록에 대해 SELECT 쿼리를 실행하여 100번 행의 변경된 데이터를 확인하려고 합니다.
-
RAC2가 Exclusive 모드로 보유 중 확인
- RAC1은 [5,207] 블록이 현재 RAC2에서 Exclusive 모드로 보유되고 있음을 확인하고, Redo 로그를 통해 최신 데이터를 조회하기로 합니다.
-
Redo 로그와 Undo 로그 활용하여 CR 블록 생성
- RAC1은 Redo 로그와 Undo 정보를 활용하여 변경된 데이터를 반영한 CR 블록을 생성합니다.
- Redo 로그는 RAC1에서 이전에 변경된 100번 행의 정보를 보유하고 있으므로, 이를 참조해 일관된 데이터(Consistent Read) 상태로 CR 블록을 완성합니다.
-
RAC1에서 완성된 CR 블록으로 조회
- Redo 로그를 통해 완성된 CR 블록은 RAC1의 Shared 모드로 버퍼 캐시에 적재되고, 쿼리 요청에 따라 최신의 변경된 데이터를 반영한 결과를 반환합니다.
최종 상태
- RAC2는 여전히 [5,207] 블록을 Exclusive 모드로 보유하고 있으므로, 이후에도 동일 블록에 대한 쓰기 작업을 수행할 수 있습니다.
- RAC1은 Redo 로그를 통해 생성한 CR 블록으로 자신의 변경 내용을 일관성 있게 조회할 수 있습니다.
