- dba로 접속
[oracle@rac1 ~]$ . oraenv
ORACLE_SID = [racdb1] ?
ORACLE_HOME = [/home/oracle] ? /u01/app/oracle/product/11.2.0/dbhome_1
The Oracle base for ORACLE_HOME=/u01/app/oracle/product/11.2.0/dbhome_1 is /u01/app/oracle
[oracle@rac1 ~]$ sqlplus / as sysdba- rac1에서 현재 상태정보 확인(데일리 체크 목록)
srvctl status database -d racdbselect group_number, name, type, state from v$asm_diskgroup;


- asm으로 접속
[oracle@rac2 ~]$ . oraenv
ORACLE_SID = [racdb2] ? +ASM2
The Oracle base for ORACLE_HOME=/u01/app/11.2.0/grid is /u01/app/oracle
[oracle@rac2 ~]$ sqlplus / as sysasmselect instance_name from v$instance;select group_number, name, type, state from v$asm_diskgroup;

system tablespace 이관작업(+ASM_DG -> +DATA)
- 데이터베이스 정상 종료후 상태 확인
srvctl stop database -d racdb -o immediate
- 데이터베이스 마운트까지 올린 후 접속
srvctl start database -d racdb -o mountselect instance_name, status from gv$instance;
-
rman 접속
rman target / -
이미지 copy하듯 DATA디스크 그룹에 copy본을 만듬
copy datafile '+ASM_DG/racdb/datafile/system.258.1184175705' to '+DATA'; -
copy 확인
list copy
-
DB로 다시 접속
sqlplus / as sysdba -
mount 단계에서 데이터파일의 위치를 rename 해준다.
alter database rename file '+ASM_DG/racdb/datafile/system.258.1184175705' to '+DATA/racdb/datafile/system.256.1184237765';- 변경정보 확인
select a.file#, b.name ,a.name, a.status, a.checkpoint_change#
from v$datafile a, v$tablespace b
where a.ts# = b.ts#;
-
DB를 MOUNT 단계에서 OPEN 단계로 변경
alter database open; -
rac2에서도 DB OPEN을 해줘야 한다.
alter database open;
select instance_name, status from gv$instance;
DISK GROUP 백업
- rman으로 접속해서 백업삭제
delete backup
-
백업 필요한 파일 확인
report need backup; -
백업받기
backup as compressed backupset database; -
백업정보 확인
list backup; -
ASM1 인스턴스로 접속
. oraenv
+ASM1 -
disk group에 대한 메타정보를 백업받을 디렉터리 생성
mkdir asm_backup
cd asm_backup/
pwd

-
asm 프롬프트 접속
asmcmd -
disk group의 메타정보 백업 받기
- 파일시스템에 백업받음
- asm_dg라는 디스크 그룹의 메타정보를 백업 받음
md_backup /home/oracle/asm_backup/asm_dg_backup -G ASM_DG
md_backup /home/oracle/asm_backup/data_backup -G DATA
md_backup /home/oracle/asm_backup/fra_backup -G FRA
-
exit로 나가서 백업파일 확인
ls asm_backup/ -
ASM1 인스턴스로 접속
sqlplus / as sysasm -
디스크 그룹 확인
select group_number, name, type, state from v$asm_diskgroup; -
강제로 diskgroup을 dismount
alter diskgroup asm_dg dismount force; -
ASM2 인스턴스에서도 강제로 dismount 해줘야한다.
alter diskgroup asm_dg dismount force; -
ASM1에서 강제로 DROP
drop diskgroup asm_dg force including contents; -
diskgroup이 삭제되었는지 확인
select group_number, name, type, state from v$asm_diskgroup; -
racdb1 인스턴스로 접속
. oraenv
racdb1
sqlplus / as sysdba -
테이블스페이스에 대한 정보 확인
select a.file#, b.name ,a.name, a.status, a.checkpoint_change#
from v$datafile a, v$tablespace b
where a.ts# = b.ts#;- 테이블 생성
- 없는 디스크 그룹의 테이블스페이스이기 때문에 오류가 발생한다.
create table hr.emp_copy
tablespace asm_tbs
as
select * from hr.employees;-
ASM1 인스턴스로 접속
. oraenv
+ASM1 -
asm 프롬프트 접속
asmcmd -
asm_dg_backup을 이용해서 메타데이터 restore 작업
md_restore /home/oracle/asm_backup/asm_dg_backup -G ASM_DG -
ls 하면 restore 되어있다.
- 이동해보면 아무 정보도 없다. 이는 뼈대(metadata)만 restore 한거기 때문이다.
cd ASM_DG/RACDB/DATAFILE
-
asm 프롬프트 나간 후 sysasm 접속
sqlplus / as sysasm -
메타데이터를 복구한 디스크 그룹 확인
select group_number, name, type, state, total_mb, free_mb from v$asm_diskgroup;
- +ASM2 인스턴스에서도 디스크 그룹 상태를 확인해야 한다.
select group_number, name, type, state, total_mb, free_mb from v$asm_diskgroup;
- dismount 되어있기 때문에 mount로 상태 변경 해야한다.
alter diskgroup asm_dg mount;
select group_number, name, type, state, total_mb, free_mb from v$asm_diskgroup;
-
오라클 racdb1로 이동
. oraenv
racdb1
sqlplus / as sysdba -
현재 테이블스페이스 상태 확인
- asm_dg 디스크 그룹은 삭제했다가 다시 메타데이터만 복구하였기 때문에 용량이 없다.
select tablespace_name, file_name, bytes/1024/1024 from dba_data_files;
- recover 해야하는 데이터파일 확인
select file#, name, status from v$datafile;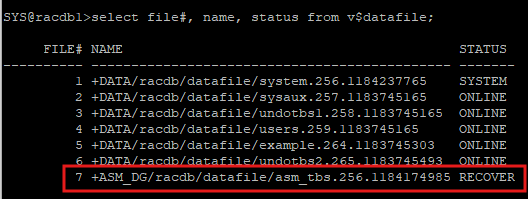
-
rman으로 접속
rmat target / -
rman에서도 다시 한번 데이터파일 상태 확인
report schema;
- 용량이 0이다
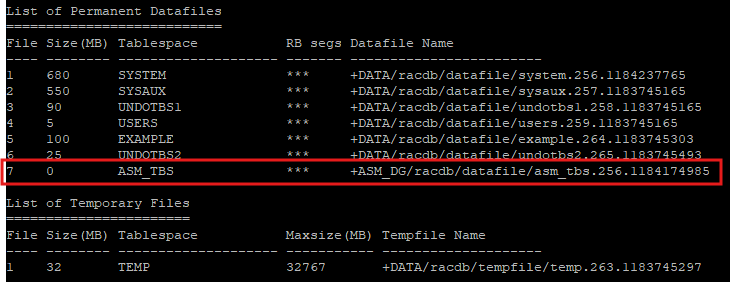
-
복구 작업을 하기 위해 7번 데이터파일을 offline으로 변경한다.
sql 'alter database datafile 7 offline'; -
백업 받아놓은 7번 데이터파일 restore
restore datafile 7;
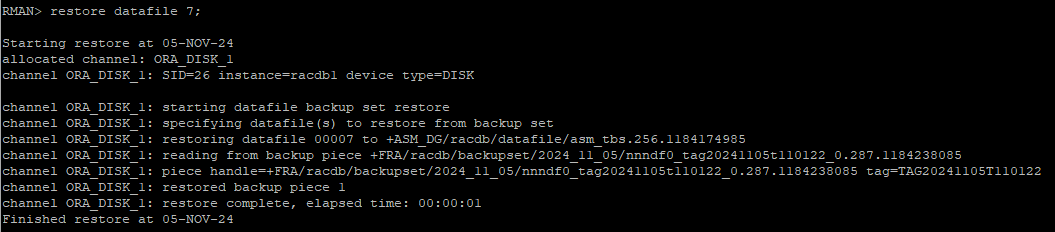
-
7번 데이터파일 복구
recover datafile 7;
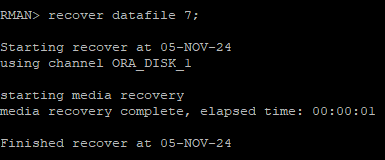
-
offline으로 변경되어있는 상태를 online으로 변경
sql 'alter database datafile 7 online';

-
데이터파일 상태 확인
report schema;
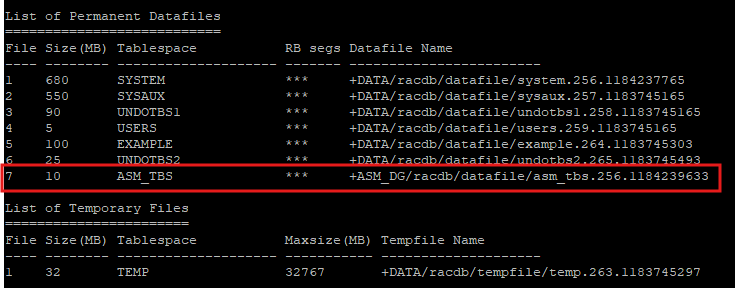
-
sqlplus로 접속해서 데이터파일 상태 확인
select file#, name, status from v$datafile;

RAC환경에서 REDO LOG FILE 관리
- RAC 환경에서는 redo log group은 서로 같이 공유하지만, 쓰기는 따로 사용한다.
rac1
select a.group#,a.thread#, a.sequence#, b.member, a.archived, a.status,a.bytes/1024/1024 as MB, a.first_change#, a.next_change#
from v$log a, v$logfile b
where a.group# = b.group#;
rac2
select a.group#,a.thread#, a.sequence#, b.member, a.archived, a.status,a.bytes/1024/1024 as MB, a.first_change#, a.next_change#
from v$log a, v$logfile b
where a.group# = b.group#;
rac에서 redo log group 추가
- rac1 노드에 redo log group 추가
alter database add logfile thread 1 group 5 ('+DATA','+FRA') size 50m;
select a.group#,a.thread#, a.sequence#, b.member, a.archived, a.status,a.bytes/1024/1024 as MB, a.first_change#, a.next_change#
from v$log a, v$logfile b
where a.group# = b.group#;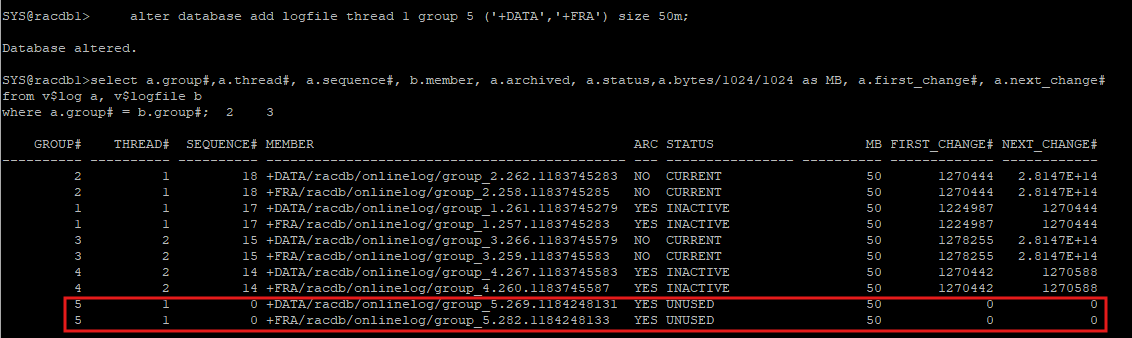
- rac2 노드에 redo log group 추가
alter database add logfile thread 2 group 6 ('+DATA','+FRA') size 50m;
select a.group#,a.thread#, a.sequence#, b.member, a.archived, a.status,a.bytes/1024/1024 as MB, a.first_change#, a.next_change#
from v$log a, v$logfile b
where a.group# = b.group#;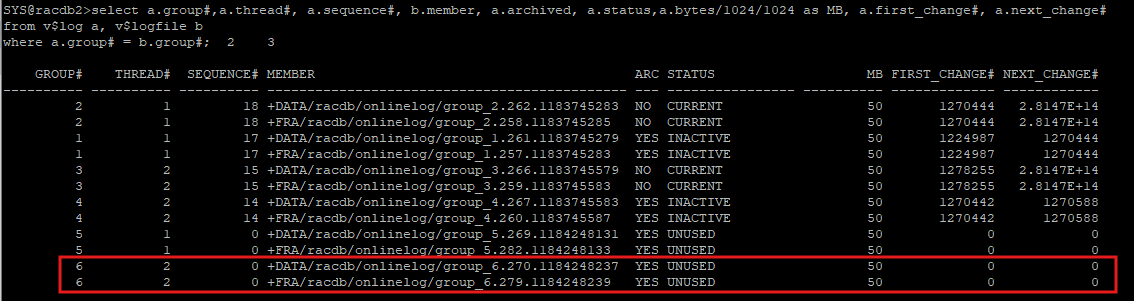
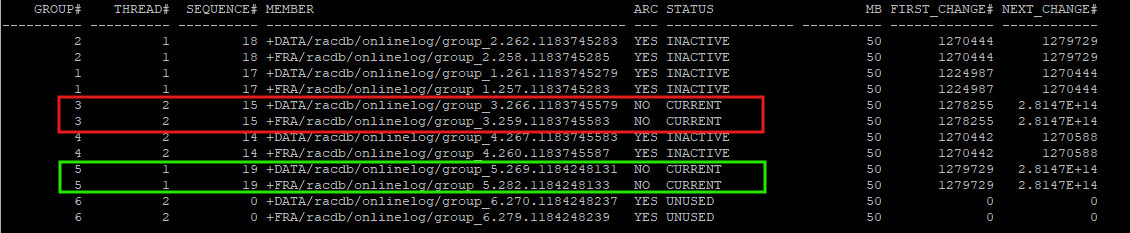
rac에서 수동으로 로그 스위치 발생
-
명령어를 수행하는 node에서만 로그 스위치가 발생한다.
alter system switch logfile; -
rac1 node에서만 current 로그 그룹이 변경 되었다.


rac 모든 노드에 대한 로그 스위치
-
current한 redo log그룹을 아카이브 파일 만들기 때문에 모든 node에 적용한다.
alter system archive log current; -
rac1 과 rac2의 current log file이 변경되었다.
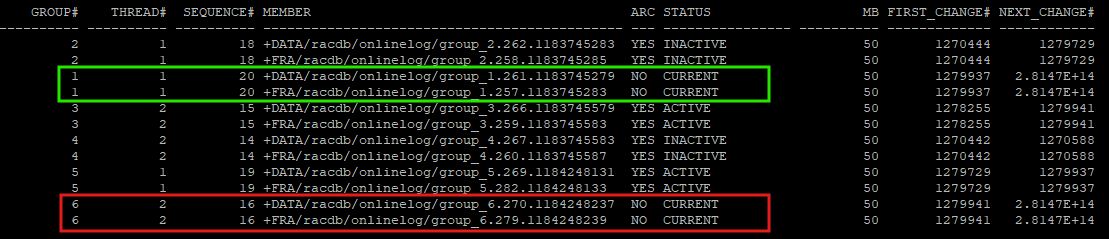
체크포인트
-
한쪽 노드에만 영향
alter system checkpoint local; -
모든 노드에 영향
alter system checkpoint global;
control file 다중화
select name from v$controlfile;
select group_number, name,type,state, total_mb, free_mb
from v$asm_diskgroup;
-
데이터베이스 상태 조회
srvctl status database -d racdb

-
데이터베이스 정상적인 종료
srvctl stop -d racdb -o immediate -
데이터베이스를 nomount 단계까지 실행
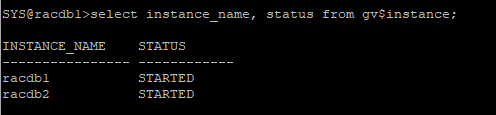
srvctl start database -d racdb -o nomount
select instance_name, status from gv$instance;
-
rman으로 접속 후 기존 컨트롤 파일을 가지고 새로운 컨트롤 파일 restore
restore controlfile to '+ASM_DG' from '+DATA/racdb/controlfile/current.260.118374527
5';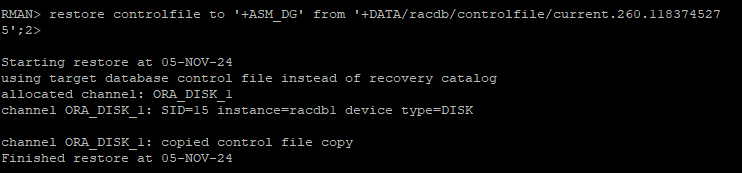
-
다른 node에서 ASM2 인스턴스로 접속
. oraenv
+ASM2 -
ASM 프롬프트로 접속
asmcmd -
restore한 컨트롤파일을 찾기 위해 이동
cd +asm_dg/RACDB/CONTROLFILE
찾은 컨트롤파일 이름 :current.257.1184252093

-
rac1 node에 기존 컨트롤파일에다가 새로운 컨트롤파일 정보 추가
alter system set control_files = '+DATA/racdb/controlfile/current.260.118374527
5',
'+FRA/racdb/controlfile/current.256.1183745275',
'+ASM_DG/RACDB/CONTROLFILE/current.257.1184252093' scope = spfile;- 똑같이 rac2 node에도 추가
alter system set control_files = '+DATA/racdb/controlfile/current.260.118374527
5',
'+FRA/racdb/controlfile/current.256.1183745275',
'+ASM_DG/RACDB/CONTROLFILE/current.257.1184252093' scope = spfile;- 양쪽 node shutdown 후 다시 startup
Row Cache Lock
- dictionary object를 보호하는 시스템 락
- shared pool안에 있는 data dictionary cache는 딕셔너리 정보에 대한 캐시영역, 유저, 인덱스, 테이블, 시퀀스, 함수, 프로시저, 패키지, 트리거 등 SQL, PL/SQL을 실행하기 위해 필요한 모든 딕셔너리 오브젝트들은 반드시 딕셔너리 캐시를 통해 액세스함
select inst_id, pool, name, bytes from gv$sgastat where name = 'row cache';: 양쪽 노드에 대해 row cache 양 확인select inst_id, cache#, type, parameter from gv$rowcache order by 1,2;: 객체 확인
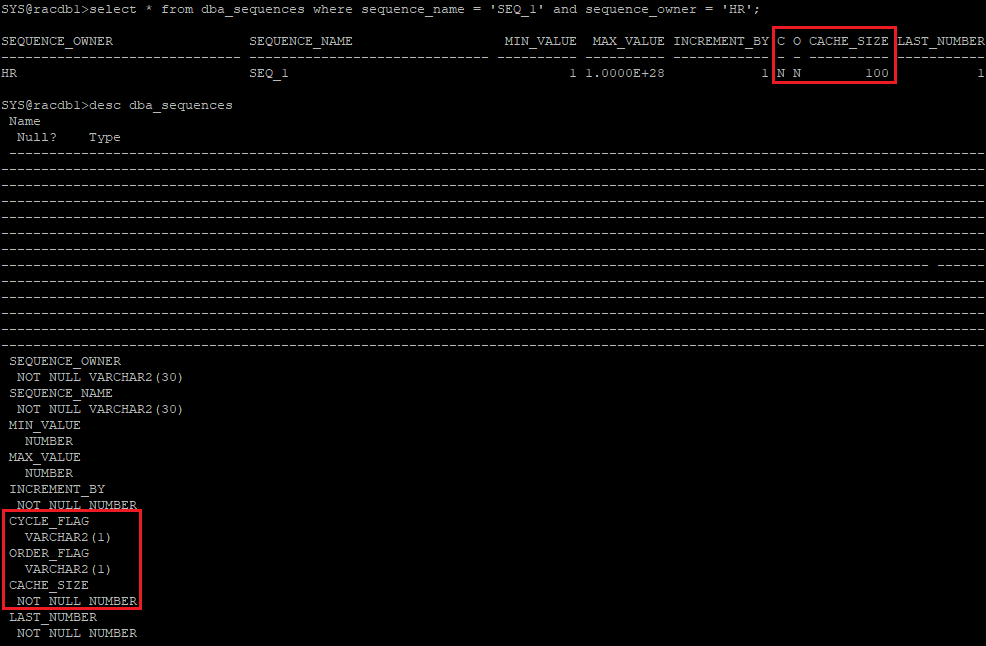
- test를 위해 시퀀스 객체 생성 및 확인
create sequence hr.seq_1 nocache;
select * from dba_sequences where sequence_name = 'SEQ_1' and sequence_owner = 'HR';
- rac1에서 hr접속
exec dbms_application_info.set_client_info('sess_1')
declare
v_value number;
begin
for idx in 1..100000 loop
select hr.seq_1.nextval into v_value from dual;
end loop;
end;
/- rac2에서 hr접속
exec dbms_application_info.set_client_info('sess_2')
declare
v_value number;
begin
for idx in 1..100000 loop
select hr.seq_1.nextval into v_value from dual;
end loop;
end;
/- 아무 노드에서 sys 접속
select inst_id, client_info, sid from gv$session where client_info in ('sess_1', 'sess_2');- 위에서 각 hr 세션에서 바로 던지고 해당 쿼리 연속해서 던져서 확인
select h.address, h.cache_name, h.saddr, s.sid, h.lock_mode
from gv$rowcache_parent h, gv$rowcache_parent w, gv$session s
where h.address = w.address
and w.saddr = (select saddr from gv$session where event = 'row cache lock' and rownum = 1)
and h.saddr = s.saddr
and h.lock_mode > 0;
- sys에 접속해 알아낸 sess 정보를 안에 넣고 확인
select inst_id, sid, event, wait_class, wait_time, seconds_in_wait, state
from gv$session_wait
where sid in (29);
- 전에 수행한 sql쿼리 확인
select sql_text
from gv$sql
where address in (select prev_sql_addr from gv$session where sid in (29));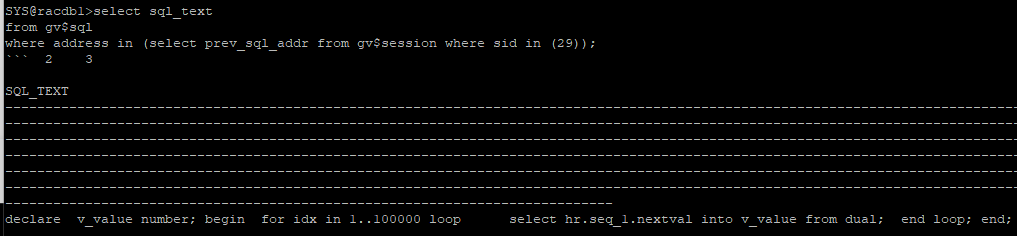
row cache lock 경합
sequence를 nocache 속성으로 생성
- nextval 수행할때마다 딕셔너리 정보를 변경하기 위해 ssx모드를 획득해야함으로 이때 경합 발생
- 해결 방법:
- cache 크기 설정(
create sequence hr.seq1 cache 100)
cache 크기가 작을 경우enq : SQ - contention발생, nocache로는 생성을 현장에서 무조건 안하므로 cache로 해야함 cache + noorder- 두 노드의 rac에서 cache속성이 100일때 1~100번(로컬 캐시)은 rac1에 101~200번(로컬 캐시)은 rac2에 각각 생성
- 한 노드에서 1~100까지 로컬 캐시가 모두 사용된 경우 로컬 캐시가 생성될때 까지
enq : SQ - contention발생
cache + order: 꼭 필요할때만 사용해야함- 두 노드의 rac에서 cache속성이 100일때 ra1, ra2 두 노드 모두 1~100번(로컬 캐시)을 공유하며 동일하게 생성
- nextval을 호출할때마다
SV LOCK을 이용한 동기화가 필요한데 이때DFS lock handle대기 이벤트 발생
- cache 크기 설정(
- test
drop sequence hr.seq_1;
create sequence hr.seq_1 cache 100;
select * from dba_sequences where sequence_name = 'SEQ_1' and sequence_owner = 'HR';