Anaconda로 python 다운로드
https://www.anaconda.com/download
Spyder로 작업한다.
Python
-
인터프리터 언어(interpreter language)
한줄씩 소스코드를 해석해서 바로 실행해 결과를 확인할 수 있는 언어 -
특징
- 문법이 쉽다.
- 가독성이 좋다.
- 무료이다.
- 이식성이 좋다.
- 운영체제에 종속되지 않습니다.
- 쉽게 라이브러리를 추가 할 수 있다.
- 풍부한 라이브러리
- numpy : 수학, 과학 모듈, 인공지능 관련된 모듈
- pandas : 데이터 검색 모듈
- matplotlib : 시각화 모듈
- beautiful soup : 웹스크레핑 모듈
- scikit-learn : 머신러닝
- 동적타이밍
- 메모리 관리를 자동
- 런타임시에 type 체크하는 동적타이밍을 지원
변수에 타입은 값을 입력하는 순간 결정
python version check
import sys
sys.version
sys.version_info
from platform import python_version
python_version()변수
- 데이터를 저장할 수 있는 메모리 공간
- 첫글자는 영문, 한글, _
- 두번째 글자 부터는 영문, 한글, 숫자, _
- 대소문자 구분
- 예약어는 사용할 수 없다.
import keyword
keyword.kwlist
변수타입 확인
type(x)
type(_y)
메모리에 생성되어 있는 변수, 함수, 클래스, 모듈 확인
dir()
메모리에 생성된 객체(변수,함수,클래스,모듈) 삭제
del 객체이름
연산자
사칙연산
x + y : 더하기
x - y : 빼기
x * y : 곱하기
x / y : 나누기
x // y : 몫
x % y : 나머지
x ** y : 제곱연산,거듭제곱, 정수형 타입 결과값
import math
math.pow(x,y) : 제곱연산, 실수형 타입 결과값연산자 우선순위
1순위 : 거듭제곱, 제곱연산
2순위 : *, /, //, %
3순위 : +, -
연산자 축약
x = 2 x = 2
x = x + 1 같은 내용 x += 1
x x +=
-=
*=
/=
//=
%=
[문제]
700005초 값을 8일 2시간 26분 45초로 출력해주세요.
1분 = 60초
1시간 = 3600초
하루 = 86400초
x = 700005
y = x//86400
a = x%86400//3600
b = x%86400%3600//60
c = x%86400%3600%60
print('{0}일 {1}시간 {2}분 {3}초'.format(y, a,b,c)) ;비교연산자
x = 1
y = 2
x == y # 같다
x != y # 같지 않다
x > y # 크다
x >= y # 크거나 같다
x < y # 작다
x <= y # 작거나 같다논리연산자(and, or, not)
True and True # True
True and False # False
True or True # True
True or False # True
not True # False
not False # Trueexcape code
- \n : 줄바꿈
v_str = '오라클\n데이터베이스'
print(v_str)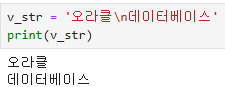
- \t : tab key
v_str = '오라클\t데이터베이스'
print(v_str)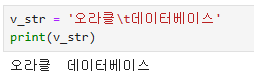
- \0 : null
v_str = '오라클\0데이터베이스'
print(v_str)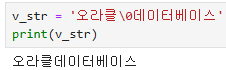
- \ : \뒤 부호를 문자로 인식
v_str = '오라클\'데이터베이스'
print(v_str)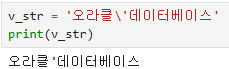
.format
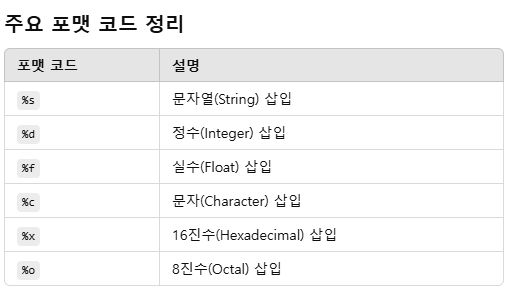
x = '오라클'
y = '엔지니어'
print('나의 직업은 {0} {1} 입니다.'.format(x,y))
% 포맷팅
x = '오라클'
y = '엔지니어'
print('나의 직업은 %s %s 입니다.'%(x,y))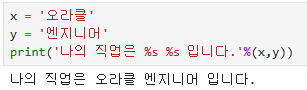
x = 3.141592
print('원주율은 %s, %d, %f 입니다.'%(x,x,x))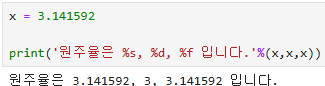
raw string
-
문자를 그대로 인식
print(r'오라클\n엔지니어') -
\n도 같은 결과
print('오라클\\n엔지니어')
print('o','r','a','c','l','e', sep' ')
-- 공백문자 있음(기본값)
print('o','r','a','c','l','e', sep'')
-- 공백문자 없음
블록 잡고 같이 출력해도 \n이 기본값
print('오라클',end='\n')
print('엔지니어')블록잡고 같이 출력하면 한줄이 인쇄됨
print('오라클',end=' ')
print('엔지니어')문자 길이
job = 'job' # job에 대한 정의 먼저 해야함
len(job)# 인덱싱(indexing)
- substr과 비슷함
맨 앞글자 추출
job[0]맨 뒤에서 첫번째 글자 추출함
job[-1]# 슬라이싱
- [시작인덱스, 종료인덱스 -1]
job[0:2]
-- 0번, 1번 추출4번인덱스 전까지 추출
job[:4]-도 사용가능함
job[4:-3]전체 출력
x = '0123456789'
x[:][시작인덱스:종료인덱스-1:증가분]
x[::1]
x[0:7:3]역순 출력
x[::-1]슬라이싱특정문자 수정은 불가능함
x = '오리클'
x[1] = '라' # 특정문자 수정은 불가능함# 문자를 치환하는 함수(미리보기)
- replace와 비슷한데 미리보기임
x.replace('리','라')
x = x.replace('리','라') -- 이렇게 수정
-- select replace('오리클','리','라') from dual;과 같음# 입력하는 문자로 시작되는지 판단하는 함수
- true/false 리턴됨, 대소문자 구분
x = 'hello world'
x[0] == 'h' --> 0번이 h인지
x.startswith('h') --> h로 시작하는지# 입력하는 문자로 끝나는지 판단하는 함수
- true/false 리턴됨, 대소문자 구분
x = 'hello world'
x[-1] == 'd' --> 맨 마지막이이 d인지
x.endswith('d') --> d로 끝나는지
x.endswith('ld') --> ld로 끝나는지# 입력한 문자가 있는 위치를 찾는 함수
- instr 비슷
x.find('w') -->처음 나온 w 위치 파악, 없으면 -1을 리턴
x.find('o',0) --> 0번 인덱스부터 검색(기본값)
x.find('o',5) --> 5부터 시작index로 바꿔서 수행 -> 찾는 문자열이 없으면 -1이 아닌 오류 발생
x.index('w') -->처음 나온 w 위치 파악, 없으면 -1을 리턴
x.index('o',0) --> 0번 인덱스부터 검색(기본값)
x.index('o',5) --> 5부터 시작
x.index('o',8)
ValueError: substring not found# 찾는 문자열이 몇번 나오는지 리턴하는 함수
x.count('o')
x.count('O') #없으면 0이 리턴# 변수에 문자열이 있으면 true 없으면 false 리턴
x.count('o') > 0
x.find('o') >= 0이렇게도 가능함
'o' in x
'O' in x# 대문자 변환하는 함수
x.upper()# 소문자 변환하는 함수
x.lower()# 문장을 기준으로 첫 글자를 대문자 나머지는 소문자 변환하는 함수
x = 'hello world'
x.capitalize()# 공백문자를 기준으로 첫 글자를 대문자 나머지는 소문자 변환하는 함수
x = 'hello world'
x.title()# 대소문자를 switch 함수
x.swapcase()
x.title() .swapcase() # 첫글자만 소문자로 나옴# 자리수를 고정시킨 후 중앙, 왼쪽, 오른쪽에 배치하는 함수
x = 'hello world'
x.center(20) # 양옆에 공백 만들어서 20자 맞춤
x.center(20,'*') # 양옆에 *로 채움왼쪽에 글자를 붙이고 오른쪽에 지정한 문자 채우기(rpad랑 같음.. 오라클이랑 반대임)
x.ljust(20)
x.ljust(20,'*')
= select rpad('hello world', 20) from dual;
= select rpad('hello world', 20, '*') from dual;
오른쪽에 글자를 붙이고 오른쪽에 지정한 문자 채우기(lpad랑 같음.. 오라클이랑 반대임)
x.rjust(20)
x.rjust(20,'*')
= select lpad('hello world', 20) from dual;
= select lpad('hello world', 20, '*') from dual;예시
"1000" .rjust(10)
"1000" .rjust(10,'*')
"1000" .ljust(10)
"1000" .ljust(10,'*')# 양쪽 오른쪽 왼쪽 공백을 제거하는 함수
- trim과 같음(select trim(' hello ') from dual;)
x = ' hello '
len(x)
x.strip()오른쪽 공백 제거
x.rstrip()왼쪽 공백 제거
x.lstrip()# 왼쪽(접두), 오른쪽(접미)연속되는 글자 제거하는 함수
x = 'wwhelloww'
x.strip('w')
x.lstrip('w')
x.rstrip('w')
# select trim('w' from 'wwhelloww') from dual; 과 같음
# select ltrim('wwhelloww','w') from dual; 과 같음
# select rtrim('wwhelloww','w') from dual; 과 같음# 문자열 안에 알파벳, 한글로 이루어져있는지 확인하는 함수
x = 'hello'
y = 'hello2004'
z = '안녕하세요'
x.isalpha() # 다 알파벳이니까 true
y.isalpha() # 숫자있어서 false나옴
z.isalpha() # 다 한글이니까 true# 문자열 안에 알파벳, 한글, 숫자로 이루어져있는지 확인하는 함수
x.isanlnum()
y.isanlnum()
z.isanlnum()# 문자열 안에 숫자로 이루어져있는지 확인하는 함수
x. isnumeric()
y. isnumeric()
z. isnumeric()# 특정한 문자를 기준으로 분리하는 함수
x = 'hello,world'
x.split(',')
Out[121]: ['hello','world']x = 'hello world'
x.split(" ")x = 'abc'
x[0]+','+x[1]','+x[2]
','.join(x) # 글자 사이마다,넣기
','.join(x) .strip(',')# python 자료형
1. list(배열 아니지만 배열처럼 표현됨)
- 데이터 목록을 다루는 자료형
- 서로 다른 데이터 타입을 가질 수 있는 자료형
- 중첩할 수 있다.
- [ ], list()
예시
x = [10,20,30]
x
type(x) # 자료형이 list로 나옴
len(x) # list변수 안에 있는 값 리턴### 인덱싱(indexing)
x[0]
x[1]
x[2]
x[-1]
x[-2]
x[-3]### 슬라이싱(slicing)
x[0:2]
x[1:]
x[:-1]### 리스트 값 수정
1개 수정
x[0] = 100
x여러 개 수정
x[1:3] = [200,300]### 리스트 변수의 값 추가
값 1개 추가
x.append(400) # 제일 뒤에 추가됨
x### 기존 리스트변수에 다른 리스트변수를 이어붙이는 함수
y변수를 x변수에 이어붙이기
y = [600,700]
x.extend(y)
x### 인덱스를 이용해서 새로운 값을 입력하는 함수
x[4]
x.insert(4,500)
x### 서로 다른 리스트변수를 이어붙이는 함수(미리보기)
z = [800,900,1000]
x + z### 리스트 마지막 값을 제거하는 방법
x[-1]
x[:-1] # 미리보기
del x[-1] # 바로 적용
x.pop() # 바로 적용, 값 안넣으면 마지막값 제거### 특정 인덱스에 있는 값을 제거하는 방법
del x[-2] # 바로 적용
x.pop(2) # 값을 넣으면 위치 지정해서 제거### 리스트변수에 있는 값을 제거
x.remove('a')### 중첩 리스트
x = [1,2,3,['a','b','c'],4,5] # 대괄호 안에 있는 ['a','b','c']는 1개로 취급
len(x) # 6개로 나옴
x[3] # ['a','b','c']가 출력됨
len(x[3]) # 3개로 출력됨3번인덱스 안에 첫번째 글자 유형 찾기
type(x)
type(x[3])
x[3],[0]
type(x[3][0]) # str로 나옴3번 인덱스 안에 제일 뒤에 값 제거
x[3].append('d')
x[3] pop()3번 인덱스 첫번째 수정
x[3][0] = x[3][0].upper()
x### 리스트변수값 내용 제거
- 변수가 지워진건 아니고 값만 지워짐
x.clear()
x
x.append(100)
x.append(200)
xdir()
id(x) # 메모리 주소
del x # 변수 삭제### 오름차순 정렬(바로 정렬)
x = [1,3,5,4,2]
x.sort()
x### 내림차순 정렬(바로 정렬)
x = [1,3,5,4,2]
x.sort(reverse = True)
x### 오름차순 정렬(미리보기)
x = [1,3,5,4,2]
sorted(x)### 내림차순 정렬(미리보기)
x = [1,3,5,4,2]
sorted(x,reverse = True)### 리스트 변수 안에 있는 값을 역순으로 출력(미리보기)
x = [1,3,5,4,2]
x[::-1] ### 리스트 변수 안에 있는 값을 역순으로 출력(바로적용)
x = [1,3,5,4,2]
x.reverse()
x2. tuple자료형
- list라는 자료형과 유사. 파이썬은 상수 개념이 없음
- 리스트와 차이점은 추가, 수정, 삭제를 할 수 없다.
- 리스트는 변수로 사용, 튜플은 상수처럼 사용
- 중첩할 수 있다.
- 서로 다른 데이터타입을 가질 수 있다.
- ()로 표현됨(list는 [ ]로 표현됨)
예시1
13//2 # 몫
13%2 # 나머지
divmod(13,2) # 몫, 나머지 한번에 출력할 수 있음
z=divmod(13,2)
type(z) # tuple라는 자료형으로 나옴예시2
x = (10,20,30)
x
type(x) # tuple임
x = 10,20,30
x
type(x) # tuple임예시3 - tuple 아니니 주의
x = (10)
x
type(x) # tuple 아님. 하나의 값만 들어가있기 때문.
x = (10,) # 이렇게 ,로 마무리하면
x
type(x) # 단일값이지만 tuple로 나옴튜블은 추가, 삭제, 수정할 수 없다. 오류발생
x.append('d')
del x[0]
x.pop()
x.remove('c')
x[0] = 'A'
x = (1,2,3)
y = (4,5,6)
x.extend(y) # 오류발생
x.append(y) # 오류발생
z = x + y
z.sort() # 오류
sorted(z) # 미리보기
sorted(z,reverse=True) # 미리보기
sorted(z,reverse=True)
Out[190] : [6,5,4,3,2,1]
z.reverse() # 오류
z[::-1] # 역순출력3. dictionary
- key, value 값을 가지는 자료형
- {key1:value1, key2:value2,...}
예시
dic = {'이름' : '홍길동',
'전화번호' : '010-1000-0001',
'주소' : '서울'}
dic
type(dic) # dict
dic.keys()
dic.values()
dic.items()
dic.keys()
Out[194] : dict_keys(['이름','홍길동'),('전화번호','010-1000-0001'),('주소','서울')])
dic['이름']
dic[전화번호']
dic['주소']
dic['직업'] : '오라클 엔지니어'
dic
dic['근무지'] # 키가 없으면 오류 발생
dic.get('근무지') # 키가 없으면 None존재하면 true, 아니면 false
'이름' in dic,keys()
'근무지' in dic.keys()
'홍길동' in dic.values()
'박찬호' in dic.values()4. 집합(Set)
- list와 비슷하지만 index가 없음
- 중복을 허용하지 않음(자동제거), 유일한 값만 제공
- { }, set()
x = {1,1,1,2,3,3,3,2,2,4,5,5,5}
x # 중복이 자동제거됨
type(x) # set으로 나옴x = [1,1,1,2,3,3,3,2,2,4,5,5,5]
x
set(x) # 중복이 자동제거됨list로 쓰려면
x = [1,1,1,2,3,3,3,2,2,4,5,5,5]
x
list(set(x))
x = [1,2,3,6]
y = [1,2,3,4,5]
x.extend(y) # union all 개념처럼 만들 수 있음합집합처럼 쓸 수 있음
set(x) .union(set(y))
set(y) .union(set(x))
-- 집합자료형으로 바꿔서 출력해야 함
set(x) | set(y)교집합처럼 사용
set(x).intersection(set(y))
set(x) & set(y)차집합처럼 사용(x집합에만 있는 데이터 추출)
set(x).differebce(set(y))
set(x) - set(y)대칭차집합(symmetric difference, 차집합이 좌우대칭인 모양)
x-y | y-x
(x-y).union(y-x)
x.symmetric_difference(y)
x^y서로소집합(disjoint set) : 두집합에 공통된 원소가 없는 집합
{1,2,3}.isdisjoint({1,2,3}) # false나옴 공통값이 있으니까
{1,2,3}.isdisjoint({4,5,6}) # True나옴 공통값이 없으니까부분집합(subset)
{1,2,3} <={1,2,3,4}
{1,2,3}.issubset({1,2,3,4})
{1,2,3,4}.issubset({1,2,3})상위집합인지 확인하는 함수
{1,2,3,4}.issuperset({1,2,3})집합안에 원소가 있는지 체크
x = {1,2,3,4}
1 in x # True
5 in x # False집합에 있는 값(원소)을 제거
x.remove(1)집합에 '하나'의 값(원소)을 추가
x.add(5)
x집합의 여러개의 값(원소)을 추가
x.update([6,7,8])
x.5. bool
- 참(True), 거짓(False)를 나타내는 자료형
x = True
Y = False
type(x)
type(y)조건제어문에서 True 표현방법
bool(1) # 숫자는 무조건 true
bool(-1)
bool('oracle')
bool([1,2,3])
bool((1,2,3))
bool({1,2,3})
not 0
not None조건제어문에서 False 표현방법
bool(0) # 0은 무조건 False
bool(None)
bool([])
bool(())
bool({})
bool('')
bool("")
not 1
not -100if 1: # '1'같은 문자형도 가능
print('참')
else:
print('거짓')