집합연산자
- 주의사항
1) SELECT 절의 컬럼의 갯수가 일치해야 한다.
2) 대응되는 컬럼 끼리 데이터 타입도 일치해야 한다.
3) 컬럼 수를 맞추기 위해 null값 사용 가능
4) ORDER BY 절은 제일 마지막에 기술한다.
5) ORDER BY 절에는 첫번째 SELECT문의 컬럼이름을 사용해야한다.
열별칭, 위치표기법을 사용할 수 있다.
6) UNION, INTERSECT, MINUS 연산자는 중복을 제거하기 위해 SORT 정렬이 발생한다.
7) UNION ALL 중복을 포함한다. 정렬이 발생하지 않습니다.
합집합
UNION
- 중복제거
중복제거를 위해 SORT 발생
SELECT employee_id, job_id, salary
FROM hr.employees
UNION
SELECT employee_id, job_id , NULL
FROM hr.job_history;
UNION ALL
중복포함
SELECT employee_id, job_id, salary
FROM hr.employees
UNION ALL
SELECT employee_id, job_id , NULL
FROM hr.job_history;INTERSECT (교집합)
- sort를 발생시킴
- EXISTS를 사용할수 있으면 하는게 좋다.
SELECT employee_id, job_id
FROM hr.employees
INTERSECT
SELECT employee_id, job_id
FROM hr.job_history; job_history 테이블은 부서 변경 이력 테이블로 과거 가졌던 부서를 남기는 테이블이다. 그래서 해당 쿼리문으로 나오는 결과는 현재 직무를 가지고 있는 테이블과 과거 이력 테이블의 교집합으로 결과를 해석하자면 부서를 옮겼다가 과거 부서로 다시 돌아간 사람을 추출해준다
MINUS (차집합)
- 앞테이블에서 뒤테이블을 MINUS OR 뒤테이블에서 앞테이블을 MINUS 하냐에 따라 결과 값이 달라진다.
- NOT EXISTS가 가능하면 튜닝해주는게 좋다
SELECT employee_id, job_id
FROM hr.employees
MINUS
SELECT employee_id, job_id
FROM hr.job_history; [문제54]
job_id를 바꾸지 않은 사원들의 정보를 출력해주세요.
<집합연산자 풀이>
SELECT
a.*
FROM
hr.employees a
WHERE
employee_id IN (
SELECT
employee_id
FROM
hr.employees
MINUS
SELECT
employee_id
FROM
hr.job_history
);<상관서브쿼리 풀이>
SELECT
a.*
FROM
hr.employees a
WHERE
NOT EXISTS (
SELECT
1
FROM
hr.job_history
WHERE
employee_id = a.employee_id
);[문제55]
UNION → UNION ALL + NOT EXISTS을 이용해주세요.
SELECT e.employee_id , d.department_name FROM hr.employees e, hr.departments d WHERE e.department_id = d.department_id(+) UNION SELECT e.employee_id , d.department_name FROM hr.employees e, hr.departments d WHERE e.department_id(+) = d.department_id;
<풀이>
SELECT e.employee_id , d.department_name
FROM hr.employees e, hr.departments d
WHERE e.department_id = d.department_id(+);
UNION ALL
SELECT null , d.department_name
FROM hr.departments d
WHERE NOT EXISTS (SELECT 1
FROM hr.employees
where department_id = d.department_id) NOT EXISTS를 사용하여 사원정보가 없는 부서정보만 추출한다.
[문제56]
1) department_id, job_id, manager_id 기준으로 총액 급여를 출력
2) department_id, job_id 기준으로 총액 급여를 출력
3) department_id 기준으로 총액 급여를 출력
4) 전체 총액 급여를 출력
- (1)+(2)+(3)+(4) 를 한 테이블에 한꺼번에 출력하세요.
ROLLUP(8i시작)
GROUP BY 절에 지정된 열 리스트를 오른쪽에서 왼쪽 방향으로 이동하면서 그룹화를 만드는 연산자
ex)select a,b,c,sum(sal) from test group by rollup(a,b,c); sum(sal) = {a,b,c} sum(sal) = {a,b} sum(sal) = {a} sum(sal) = {}
SELECT department_id, job_id, manager_id,sum(salary)
FROM hr.employees
GROUP BY ROLLUP (department_id, job_id, manager_id)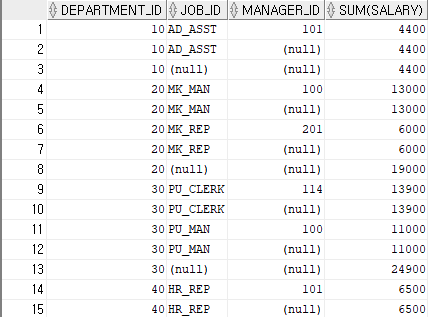
CUBE(8i 시작)
ROLLUP 연산자의 기능을 포함하고, 모든 그룹화 할 수 있는걸 만드는 연산자.
ex)select a,b,c,sum(sal) from test group by cube(a,b,c); sum(sal) = {a,b,c} sum(sal) = {a,b} sum(sal) = {a,c} sum(sal) = {b,c} sum(sal) = {a} sum(sal) = {b} sum(sal) = {c} sum(sal) = {}
SELECT department_id, job_id, manager_id, sum(salary)
FROM hr.employees
GROUP BY CUBE(department_id, job_id, manager_id)
ORDER BY 1,2,3;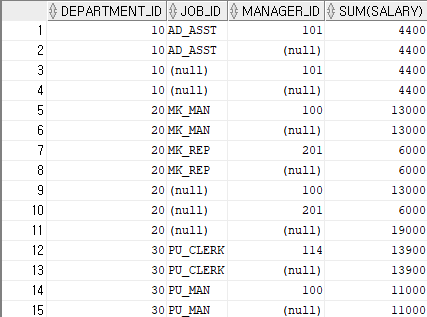
예를 들어
sum(sal) = {a,b} , sum(sal) = {a,c} 만 해야 할 경우
SELECT a,b,NULL,SUM(sal)
FROM test
GROUP BY a,b
UNION ALL
SELECT a,NULL,c,sum(sal)
FROM test
GROUP BY a,c해당 방법으로 하기에는 번거로움이 있다
GROUPING SETS(9i 시작)
내가 원하는 그룹을 만드는 연산자
ex)SELECT a,b,c,SUM(sal) FROM test GROUP BY GROUPING SETS((a,b),(a,c),())
SELECT department_id, job_id, manager_id, sum(salary)
FROM hr.employees
GROUP BY GROUPING SETS ((department_id, job_id),( department_id,manager_id),())
ORDER BY 1,2,3;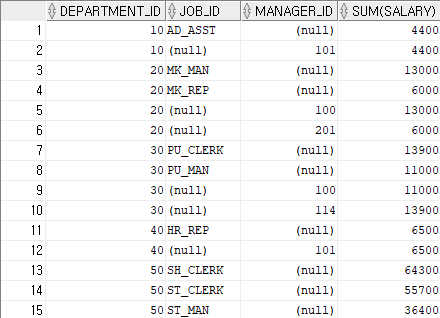
계층검색(hierarchical query)
트리구조
START WITH, CONNECT BY PRIOR
-- 하향식
select employee_id, last_name, manager_id
from hr.employees
start with employee_id = 101 -- 시작점,시작해야 할 조건
connect by prior employee_id = manager_id; -- 다음행으로 이전의 employee_id를 manager_id로 가지고 있는 행을 보여줌
-------------------->
-- 상향식
select employee_id, last_name, manager_id
from hr.employees
start with employee_id = 101 -- 시작점,시작해야 할 조건
connect by employee_id =prior manager_id; -- 다음행으로 이전의 manager_id를 employee_id로 가지고 있는 행을 보여줌
<-----------------------level(가상컬럼)
select level, employee_id, last_name, manager_id
from hr.employees
start with employee_id = 100 -- 시작점,시작해야 할 조건
connect by prior employee_id = manager_id;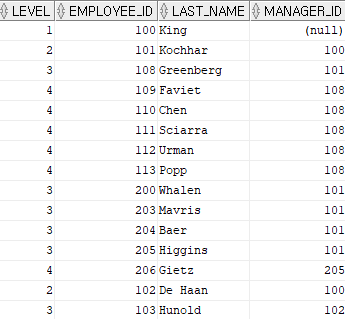
- LPAD를 활용한 LEVEL별 들여쓰기 기법
select level, lpad(' ',level*2 -2,' ')||last_name
from hr.employees
start with employee_id = 100 -- 시작점,시작해야 할 조건
connect by prior employee_id = manager_id;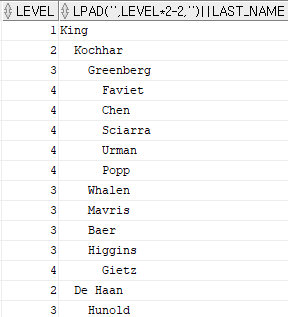
- SIBLINGS 키워드를 활용한 정렬 방법
- 해당 키워드를 사용하면 계층을 유지한채 정렬을 할수 있다.
SELECT
level,
lpad(' ', level * 2 - 2, ' ')
|| last_name
FROM
hr.employees
START WITH
employee_id = 100 -- 시작점,시작해야 할 조건
CONNECT BY
PRIOR employee_id = manager_id
ORDER SIBLINGS BY
last_name;
-- 계층검색에서 정렬수행할때 꼭 SIBLINGS 옵션을 입력해야 한다.
-- ORDER SIBLINGS BY 사용할때는 컬럼의 별칭, 위치표기법 사용불가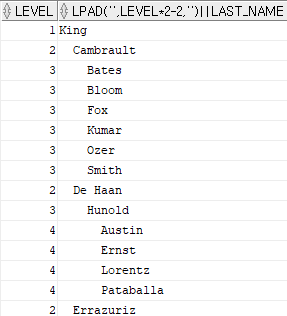
- 특정한 행만 제거 방법
- WHERE절에 조건절 기술
select level, employee_id, last_name, manager_id
from hr.employees
where employee_id != 101 -- 특정한 행을 제어
start with employee_id = 100 -- 시작점,시작해야 할 조건
connect by prior employee_id = manager_id;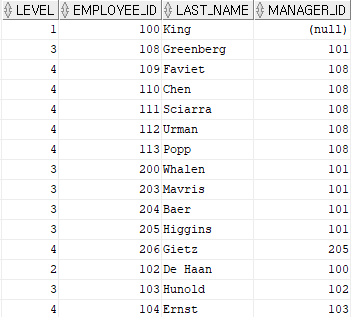
- 분기 제거(가지치기) 방법
- CONNECT BY PRIOR 절 뒤에 AND를 이용해 조건 기술
SELECT
level,
employee_id,
last_name,
manager_id
FROM
hr.employees
START WITH
employee_id = 100 -- 시작점,시작해야 할 조건
CONNECT BY PRIOR employee_id = manager_id
AND employee_id != 101; -- 101사원의 조직을 전부제거, 분기제거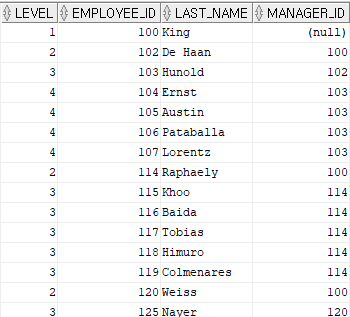
[문제57]
SELECT문을 이용해서 1~100까지 출력해주세요.
<풀이>
select level
from dual
connect by level <= 100;
[문제58]
SELECT문을 이용해서 2단을 출력해주세요.
<풀이>
select '2 * ' || level || ' = '|| 2*level
from dual
connect by level <= 9;
[문제59]
SELECT문을 이용해서 2단 ~9단 출력해주세요.
<풀이>
SELECT
a || ' * ' || b || ' = ' || a * b AS 구구단
FROM
(
SELECT
level + 1 a
FROM
dual
CONNECT BY
level <= 8
)
CROSS JOIN (
SELECT
level b
FROM
dual
CONNECT BY
level <= 9
) ;
DQL(Data Query Language)
SELECT : 데이터베이스 있는 데이터를 조회하는 SQL문
DDL(Data Definition Language)
- CREATE
- ALTER
- DROP
- RENAME
- TRUNCATE
- COMMENT
유저관리
권한(privilege)
특정한 SQL문을 수행할 수 있는 권리
- 권한
- 시스템 권한 : 데이터베이스에 영향을 줄 수 있는 권한
- 객체권한 : 객체(테이블)를 사용할 수 있는 권한
- ROLE(롤) : 유저에게 부여할 수 있는 권한을 모아 놓은 객체,관리 편리성
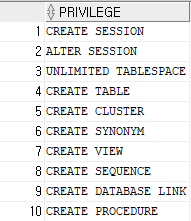
내가 받은 시스템 권한을 확인(DBA로 부터 직접 받은 시스템권한)
SELECT * FROM user_sys_privs;
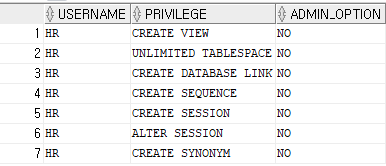
UNLIMITED TABLESPACE- 데이터베이스 저장공간을 마음대로 쓸 수 있는 권한, (절대 함부로 부여하면 안되는 권한)
내가 받은 롤을 확인
SELECT * FROM session_roles;
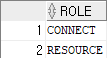
내가 받은 롤 안에 시스템 권한 확인
SELECT * FROM role_sys_privs;
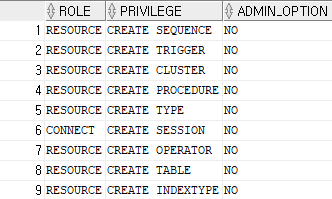
내가 받은 객체 권한 또는 내가 부여한 객체 권한 확인
SELECT * FROM user_tab_privs;

내가 받은 롤안에 객체 권한 확인
SELECT * FROM role_tab_privs;

내가 시스템에 직접 받은 권한과 롤을 통해 받은 권한을 한번에 확인
SELECT * FROM session_privs;
[10일차 후기]
총 교육 기간이 101일 인데 벌써 10일 지났다. 앞으로 지금까지 교육받은기간을 9번 밖에 더 받으면 된다고 생각하니 과연 내가 90일 뒤에는 전문성을 가지고 잘 할수 있을까 라는 걱정도 드는 날이었다. 게다가 방금 마지막에 배운 유저관리의 권한을 배우고 나니 지금까지 했던 DQL문은 오라클 시스템안에서 빙산의 일각이었구나 라는 생각 또한 들었다. 오늘은 크게 집합연산자와 계층검색에 대해 공부하였는데, 계층검색의 작동 원리를 배울때 python의 DFS(깊이우선탐색)이 생각 나는 원리였다.아마 같은 알고리즘 인거같다 이전에 connect by prior 절을 배울때는 부모 & 자식 위치에 대해 헷갈린 부분이 있었는데 강사님께서 같이 테이블을 보며 설명해 주셔서 요번기회에 확실하게 작동 방법을 알게 되었다. 집합 연산자 부분에서는 UNION, INTERSECT, MINUS는 구현시 정렬을 발생하여 성능에 악영향을 주니 가능하면 EXISTS, NOT EXISTS를 활용하여 데이터를 추출하는 부분이 인상적이었다.
