PIVOT 함수
- 행(세로) 데이터를 열(가로)로 변경하는 함수
- pivot(집계함수 for 컬럼 in);
<pivot을 이용한 가로방향 출력>
SELECT
*
FROM
(
SELECT
to_char(hire_date, 'yyyy') AS year,
COUNT(*) AS cnt
FROM
hr.employees
GROUP BY
to_char(hire_date, 'yyyy')
) PIVOT (
MAX ( cnt )
FOR year
IN ( 2001,2002,2003,2004,2005,2006,2007,2008 )),
--인라인뷰 카테시안 곱
(
SELECT
COUNT(*) AS 총인원수
FROM
hr.employees
); 
<교차테이블 PIVOT>
SELECT
*
FROM
(
SELECT
salary,
nvl(department_id, 0) AS dept_id
FROM
hr.employees
) PIVOT (
COUNT ( * )
FOR dept_id
IN ( 10,
20,
30,
40,
50,
60,
70,
80,
90,
100,
110, 0 AS "부서가 없는 사원" )
)
ORDER BY
1;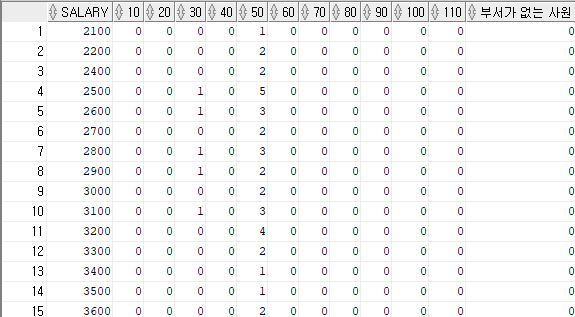
[문제49]
년도별 입사 인원수를 가로형으로 출력해주세요.
<풀이>
SELECT *
FROM (SELECT to_char(hire_date,'yyyy') as year
From hr.employees)
PIVOT (count(*) for year in (2001,2002,2003,2004,2005,2006,2007,2008));
[문제50]
요일별 입사 인원수를 가로방향으로 출력해주세요.
<풀이>
SELECT *
FROM (SELECT to_char(hire_date, 'day') as day
FROM hr.employees)
PIVOT(count(*) for day in
('월요일' "월요일",'화요일' "화요일" ,'수요일' "수요일" ,'목요일' "목요일",'금요일' "금요일",'토요일' "토요일",'일요일' "일요일"));
UNPIVOT 함수
- 열(가로)을 행(세로)으로 변경하는 함수
- UNPIVOT (value 컬럼명 FOR 기준컬럼명 IN (pivot 기준컬럼의 값을 그대로 넣어야 한다))
SELECT*
FROM (
SELECT *
FROM (SELECT to_char(hire_date, 'day') as day , count(*) as cnt
FROM hr.employees
GROUP BY to_char(hire_date, 'day') )
PIVOT(max(cnt) for day in
('월요일' "월요일",'화요일' "화요일" ,'수요일' "수요일" ,'목요일' "목요일",'금요일' "금요일",'토요일' "토요일",'일요일' "일요일"))
)
UNPIVOT(인원수 FOR 요일 IN (월요일,화요일,수요일,목요일,금요일,토요일,일요일));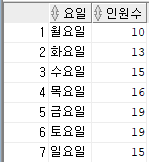
with
temp_01 as (
SELECT *
FROM (SELECT salary,to_number(to_char(hire_date,'yyyy')) as year
From hr.employees)
PIVOT (count(*) for year in (2001,2002,2003,2004,2005,2006,2007,2008))
)
select salary ,year,인원수 from temp_01 unpivot(인원수 for year in ("2001","2002","2003","2004","2005","2006","2007","2008"));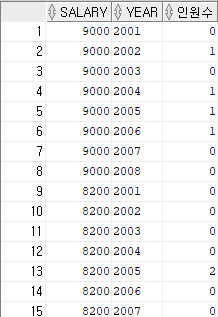
교차테이블에 대한 UNPIVOT시 PIVOT의 기준 컬럼만 UNPIVOT 후 기준컬럼 제외 나머지 컬럼들은 SELECT 절에 작성해주면 ORACLE이 알아서 매핑해주는 것을 발견하였다.
다중열 서브쿼리
-- 쌍비교
SELECT
*
FROM
hr.employees
WHERE
( manager_id,
department_id ) IN (
SELECT
manager_id,
department_id
FROM
hr.employees
WHERE
first_name = 'John'
);
-- 비쌍비교 : 결국엔 크로스로 비교를 함 ex)100,200,300 과 10,20,30이 있으면 100과 10,20,30 이런식으로 모두 비교
SELECT
*
FROM
hr.employees
WHERE
( manager_id ) IN (
SELECT
manager_id
FROM
hr.employees
WHERE
first_name = 'John'
)
AND department_id IN (
SELECT
department_id
FROM
hr.employees
WHERE
first_name = 'John'
); Scalar Subquery(스칼라 서브쿼리)
- 한행에서 정확히 하나의 열값만 반환하는 쿼리(단일컬럼, 단일값만 리턴한다.)
- 동일한 입력값이 들어오면 수행횟수를 최소화 할 수 있는 로직이 구현된다.
- join은 기준 테이블의 로우 수 만큼 비교테이블과 비교하는 수행을 가져야 한다.
- query execution cache 기능이 수행된다.
- 키값이 없는 데이터가 입력되면 NULL값으로 리턴된다.(OUTER JOIN 기법처럼 결과가 출력된다.)
SELECT
e.employee_id,
e.department_id,
( -- 캐시기능이 수행되어 distinct department_id 수인 12번만 작동된다.
SELECT
department_name || ',' || manager_id -- 하나의 열값만 반환해야 하기 때문에 두가지 정보가 필요하면 || 기능을 이용한다.
FROM
hr.departments
WHERE
department_id = e.department_id
)
FROM
hr.employees e
ORDER BY
2;[문제51]
부서이름별 급여의 총액, 평균을 출력해주세요.
<일반적인 형식 풀이>
SELECT
b.department_name,
SUM(a.salary) AS sum_sal,
round(AVG(a.salary)) AS avg_sal
FROM
hr.employees a
JOIN hr.departments b ON a.department_id = b.department_id
GROUP BY
b.department_name;전체 M테이블의 ROWS 수 만큼 JOIN이 수행됨으로 가장 성능이 떨어지는 풀이방법
<inline view 풀이>
SELECT
a.department_name,
b.sum_sal,
round(b.avg_sal) AS avg_sal
FROM
hr.departments a
JOIN (
SELECT
department_id,
SUM(salary) AS sum_sal,
AVG(salary) AS avg_sal
FROM
hr.employees
GROUP BY
department_id
) b ON a.department_id = b.department_id;inline view에서 먼저 GROUP BY를 통해 row수를 줄인 다음 JOIN을 수행하는게 좀더 나은 성능을 보여준다
<scalar subquery 풀이> -- I/0 중복 문제가 있음
SELECT
a.department_name,
(
SELECT
SUM(salary)
FROM
hr.employees
WHERE
department_id = a.department_id
) AS sum_sal,
round((
SELECT
AVG(salary)
FROM
hr.employees
WHERE
department_id = a.department_id
)) AS avg_sal
FROM
hr.departments a;스칼라 서브쿼리의 문제점은 I/O 중복이 발생한다는 점이다.
<I/0중복 문제를 해결한 scalar subquery 풀이>
SELECT
department_name,
substr(aggr_sal, 1, 10) AS sum_sal, -- 1~10번까지는 sum(salary)의 자리수 라는것을 활용
substr(aggr_sal, 11, 10) AS avg_sal -- 11~20번까지는 avg(salary)의 자리수 라는것을 활용
FROM
(
SELECT
a.department_name,
(
SELECT
lpad(SUM(salary), 10)
|| lpad(round(AVG(salary)), 10) -- 1)스칼라 서브쿼리는 단일 컬럼만 올수 있기 때문에 || 연산자를 통해 한컬럼으로 묶어준다. 2) lpad함수를 통해 각 값마다 자리수를 정해준다.
FROM
hr.employees
WHERE
department_id = a.department_id
) AS aggr_sal
FROM
hr.departments a
);[문제52]
사원들의 last_name, salary, grade_level을 출력해주세요.
<조인 풀이>
SELECT
a.last_name,
a.salary,
b.grade_level
FROM
hr.employees a
JOIN hr.job_grades b ON a.salary BETWEEN b.lowest_sal AND b.highest_sal; <scalar subquery 풀이>
SELECT
a.last_name,
a.salary,
(
SELECT
grade_level
FROM
hr.job_grades
WHERE
a.salary BETWEEN lowest_sal AND highest_sal
)
FROM
hr.employees a
ORDER BY
2;[문제53]
사원들의 employee_id, last_name을 출력하는데 department_name을 기준으로 오름차순 정렬해주세요.
<풀이>
SELECT
employee_id,
last_name
FROM
(
SELECT
a.employee_id,
a.last_name,
(
SELECT
department_name
FROM
hr.departments
WHERE
department_id = a.department_id
) AS department_name
FROM
hr.employees a
)
ORDER BY
department_name;<ORDER BY 절에 스칼라서브쿼리 적용 풀이>
SELECT
e.employee_id,
e.last_name
FROM
hr.employees e
ORDER BY
(
SELECT
department_name
FROM
hr.departments
WHERE
department_id = e.department_id
) ASC;[9일차 후기]
오늘은 크게 보면 [PIVOT, UNPIVOT, 다중열 서브쿼리, 스칼라 서브쿼리]를 배우는 시간을 가져 보았다. 우선 어제 세로형 출력되는걸 가로형으로 변환 하는 과정에서 좀더 간단한 방법이 있을거 같은데 꼭 SELECT절에 하나 하나 조건문을 주면서 변환 할수 밖에 없는걸까 라는 의문이 있었는데, 오늘 그것을 한번에 해결해 주었던 함수가 바로 PIVOT , UNPIVOT 함수였다. 이전 python으로 pandas와 numpy를 좀 다뤄봤던 입장에서 너무 반가웠던 함수들 이었다. 처음에는 작동방법에 익숙치 않아 좀 시행착오를 겪었지만, 여러 예제들을 가지고 연습해보니 어느정도 감을 잡은 것 같다. 그리고 대망의 스칼라 서브쿼리를 배웠는데 그동안 초급 개발자의 시선으로만 작성했던 쿼리문을 한단계 발전 시켜줄수 있는 기능이라고 나는 느꼈다. 업무를 파악해서 문제를 해결할때 지금까지는 그거 그냥 JOIN하면 되는거 아닌가 라는 가벼운 생각을 하고 있었지만, JOIN을 함으로써 발생하는 성능저하 까지는 생각하지 못했다.그렇다고 JOIN을 무조건 쓰면 안된다는 것은 아니다 그러한 문제점을 해결해주는게 바로 scalar subquery 인데 해당 서브쿼리는 query excution cache 기능을 가지고 있어, 중복된 값이 들어오면 이전 값을 캐시에 저장하고 있다 바로 불러와 주어 성능을 저하시키지 않는다고 한다.
단, 단점이라고 하면 단일컬럼만 반환한다는 건데 그럼 처음에는 스칼라서브쿼리를 여러개 써서 여러개 컬럼을 가져오면 되는게 아닌가? 라고 생각했다. 하지만 또 그렇게 하면 I/O입출력이 중복되어 또 성능이 나빠지게 된다고 하니 아! 이렇게지도 성능을 고려 해야하는구나 라는 깨달음을 얻었다. 그래서 I/O입출력 중복이 되지 않는 방법까지 배워보고 나니 내가 지금까지 작성했던 쿼리문은 정말 초보자 수준이었구나 라는것을 다시 한번 깨닫는 하루였다.
