병렬 하드웨어의 종류(Flynn's taxanomy기준 분류)
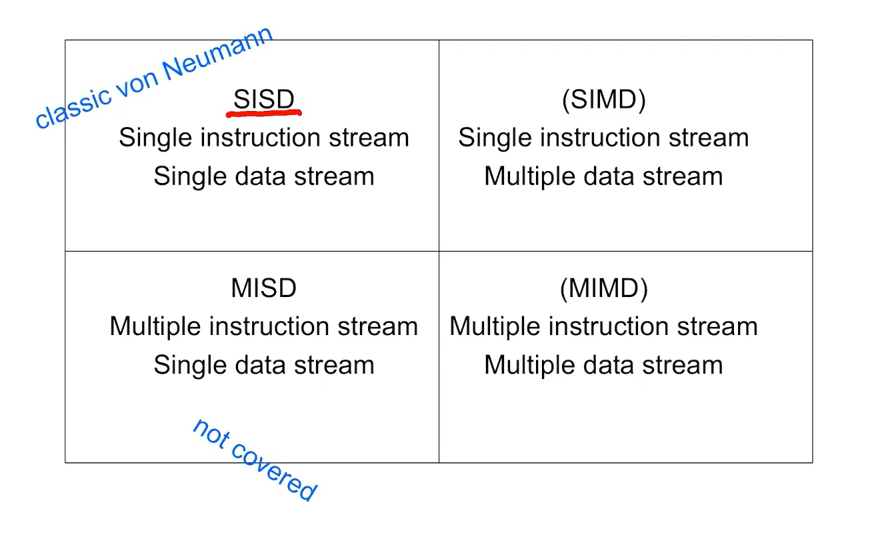
SISD : 하나의 데이터 스트림에 하나의 명령 체계 처리
SIMD : 여러 개의 데이터 스트림을 처리하지만 똑같은 명령 체계 처리(GPU, Vector Processors와 같은 병렬처리)
MISD : 여러 개의 명령체계를 하나의 데이터 스트림으로 처리(Systolic.. 이런 게 있다 정도!)
MIMD : 여러 개의 프로세스로 여러 개의 데이터 스트림 처리(분산 처리에 가깝다.. 웹서버같은 독립적인 프로세스?)
SIMD
데이터를 나눠서 병렬 처리(여러 개의 프로세서 적용)
Data Parallelism으로 불린다.
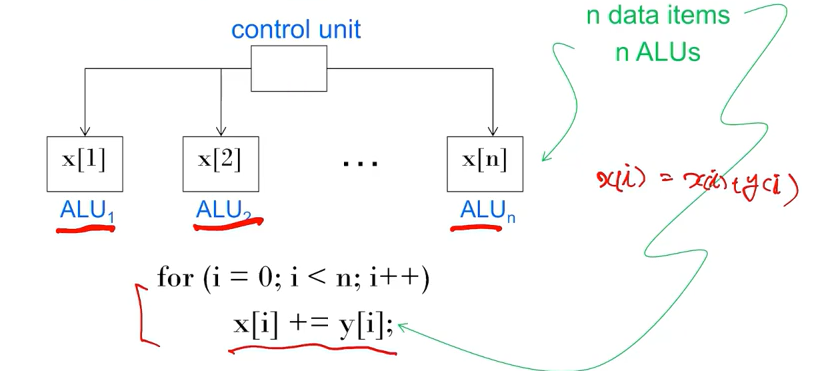
만약 데이터에 비해 ALU가 많지 않다면? (ex : 4 ALUs, n = 15 data items)
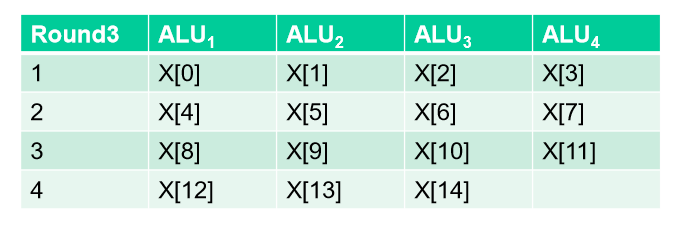
이런 식으로 데이터를 나눌 수 있다(나누는 기준은 사용자 기준이다).
빈칸은 데이터가 없으므로 IDLE상태에 빠진다.
장점 : 여러 데이터에 같은 명령 체계를 적용하여 간편하게 처리할 수 있음.
단점 :
- 데이터 상태에 따라, IDLE상태에 빠질 수도 있다 -> 비효율적인 상황 발생 가능.
- 동시에 처리되기 때문에 동기화가 필요하다.
- ALU는 명령 스토리지가 따로 없다.
- 동기를 많이 해줘야 하는 데이터 병렬 처리에는 비효율적으로 갈 수도 있다.
Vector Processors
Array나 Vector와 같은 대량의 데이터를 CPU에서 처리한다.
vector registers
벡터를 저장하거나 동시에 계산하는데 효율적이다.
Vectorized and pipelined functional units
벡터 내부의 요소에 같은 계산이 적용되도록 한다
Vector instructions
스칼라가 아닌 벡터로 작동된다.
Interleaved momory
독립적으로 접근이 가능한 여러 개의 Memory Bank.
여러 개의 Bank에 벡터 요소들을 분배하고 연속된 요소들을 줄이거나 지운다.
Special HW to accelerate
- Strided memory access : 프로그램은 고정된 간격에 위치한 벡터의 요소에 접근한다.
- Scater/gatter : 불규칙한 간격으로 위치한 벡터의 요소를 쓰거나 읽는다.
Vector Processors 특징
장점
- 빠르고 사용하기 쉽다.
- 재호출이 용이하다
- High Memory bandwidth
- 모든 데이터를 캐시에서 사용한다.
단점
- 불규칙적인 데이터를 처리하지 못한다
- 프로세서의 개수가 제한이 있으므로, 문제가 커진다고 효율이 좋아지는 것은 아니다.
