병렬프로그래밍
1.개요
병렬프로그래밍은 어디에 사용되나. 코어를 늘려도, 성능상 체감이 되지 않는다. 왜냐하면 병렬처리하지 않았기 때문. 컴퓨팅 파워가 커짐에 따라, 처리할 수 있는 일들이 많아짐. 그리고 처리하기 힘든 일들도 많아짐(인공지능 학습 등) 기상청 예보, 단백질 분석 모델링, 빅
2.병렬 하드웨어와 소프트웨어
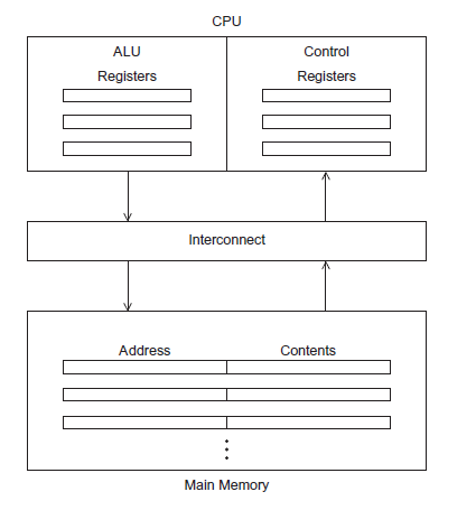
모든 데이터는 램에 저장하고, 계산은 레지스터에 적재하고 cpu가 계산한다. 그 결과는 다시 램에 저장한다. components CPU(Central Processing Unit) : 중앙처리 장치 Control unit 프로그램의 실행과 관련된 행동
3.캐시

다른 메모리의 위치에 빠르게 접근할 수 있는 메모리 위치의 집단.최근에 업데이트된 아이템들이 다시 사용될 가능성이 있다(Temporal locality)근처에서 사용된다(Spatial locality)캐시는 레벨별로 메모리에 존재하며, 깊이가 깊어질수록 메모리의 크기
4.Virtual Memory & Pipelining
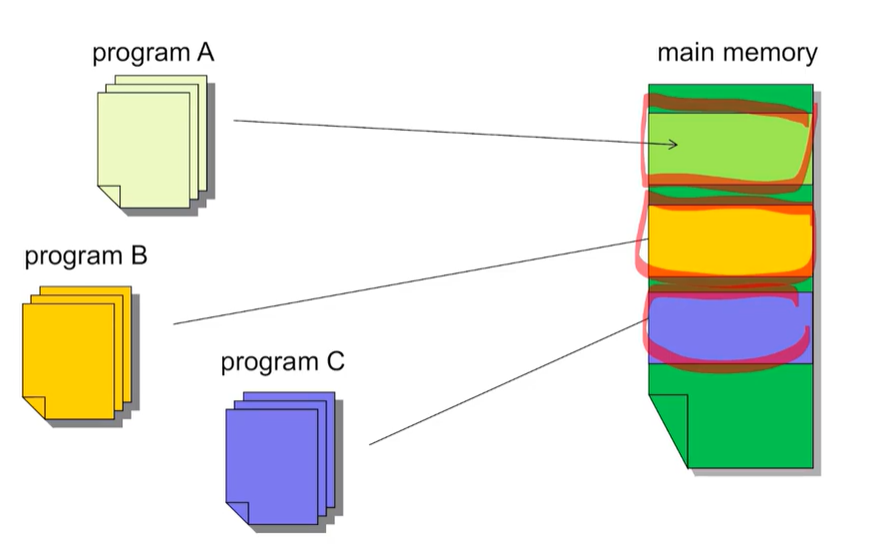
매우 큰 프로그램을 사용할 경우 하드디스크에 스왑 스페이스를 통해 하드 디스크에 가상 메모리를 생성하여 이곳에 넣음. -> 메인메모리의 캐시 역할을 한다.오랫동안 사용하지 않는 프로그램은 스왑 스페이스에서 보관한다. 메인메모리에서 사용 중인 프로그램들을 보관한다.여러
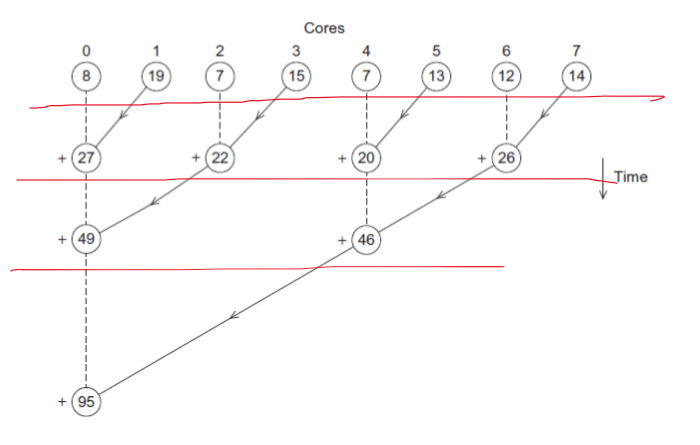
5.Multiple Issue, Hardware MultiThreading
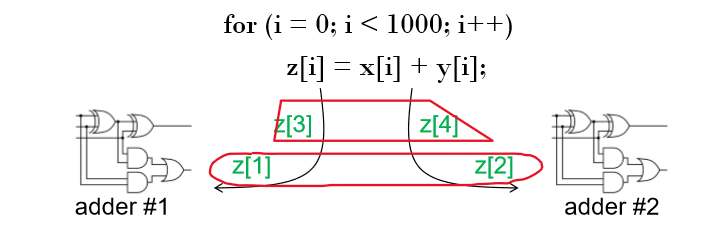
z1과 z2, z3와 z4가 동시에 계산되면 성능이 2배로 좋아진다.Static multiple issue : 정해진 순서(Compile time)에 의해 실행된다.Dynamic multiple issue : 런타임에 의해 실행된다. -> Superscalar라고도 불
6.Flynn's taxanomy, SIMD
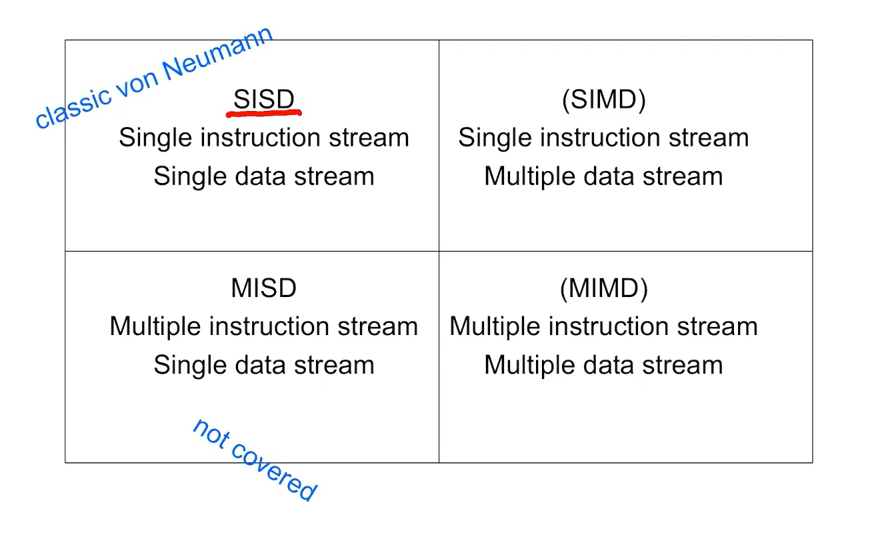
SISD : 하나의 데이터 스트림에 하나의 명령 체계 처리SIMD : 여러 개의 데이터 스트림을 처리하지만 똑같은 명령 체계 처리(GPU, Vector Processors와 같은 병렬처리)MISD : 여러 개의 명령체계를 하나의 데이터 스트림으로 처리(Systolic.
7.Graphics Processing Units & MIMD Systems
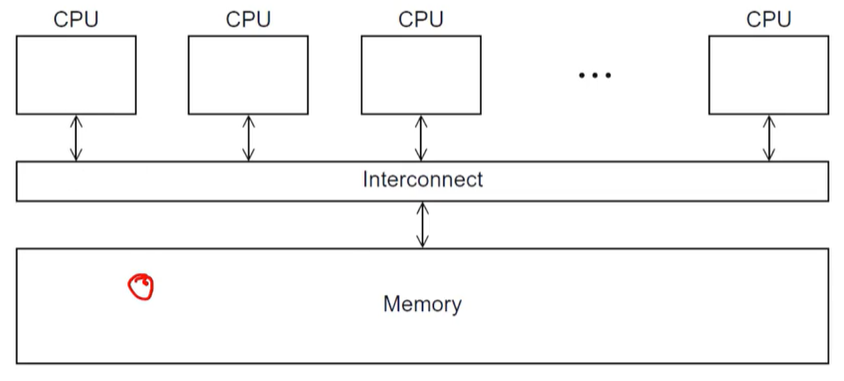
실시간 그래픽 어플리케이션 프로그래밍 인터페이스 혹은 점, 선 그리고 삼각형과 같은 표면형 물체를 표현하는 API에 사용된다.화면의 픽셀 하나하나를 계산하기 때문에, 병렬처리가 쉽다.이러한 파이프라인의 Several Stages(shader functions)는 프로그
8.Cache Coherence

프로그래머는 캐쉬 데이터를 관리할 수 없다. 하드웨어에서 업데이트해서 사용하기 때문이다.코어0, 1에서 병렬적으로 처리한다고 가정한다면, 위 테이블대로 처리한다면 z1의 값은 28이 나올 것이다. 하지만 x가 저장된 Cache 0가 오랜 시간동안 사용되지 않아 사라지고
9.Parallel Software

하드웨어, 컴파일러들은 우리가 필요한만큼의 속도를 따라오고 있다. 현재는 Shared memory programs와 Distributed memory programs로 이루어져있다.SPMD(Single Program Multiple Data) Programming은 조
10.Memory Interconnects
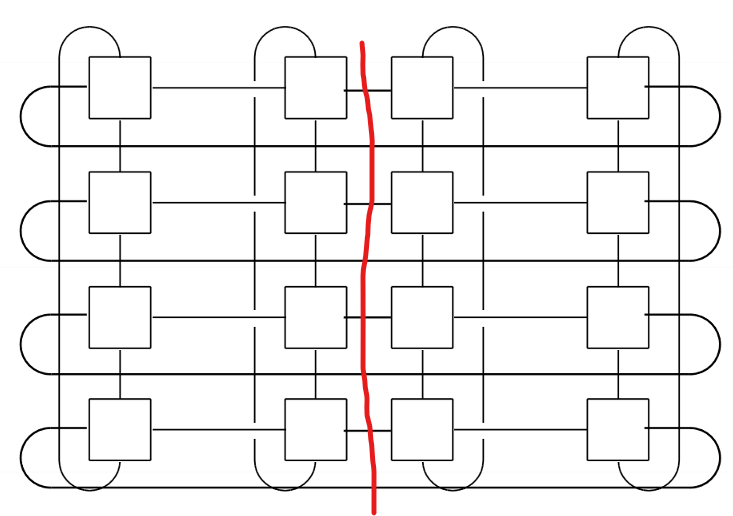
Interconnection Networks 분배되고 공유된 메모리 시스템의 성능에 영향을 끼친다(왜냐하면 병렬적으로 처리하고 나중에 한 곳으로 뭉칠 때, 짧은 시간 안에 서로 통신해야하기 때문이다). Interconnection Networks는 두 가지로 나뉜
11.성능 & Design

우리가 병렬프로그래밍을 하는 이유는 성능을 향상시키기 위해서이다. -> 속도를 빠르게!병렬프로그램이 빨라진 정도는 (직렬 처리 시간) / (병렬처리 시간) 로 계산할 수 있다.EfficienyOverhead예를 들어보자.여기, 한 병렬 프로그램의 효율성과 Speedup
12.Pthread
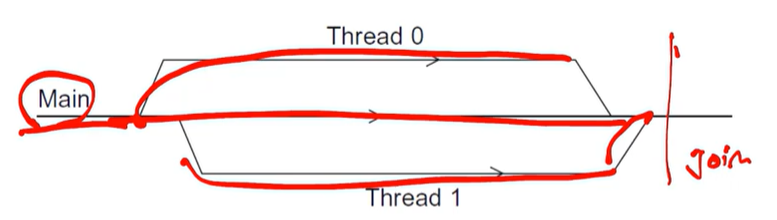
프로세스는 실행되는 프로그램의 인스턴스이다. 스레드는 "light weight" 프로세스이다(프로세스랑 유사함).공유 메모리 프로그램에서의 싱글 프로세서는 다수의 제어 스레드들을 갖고 있을 것이다.Posix : A Standard for Unix-like operati
13.Critical Sections

여기, 하나의 값(파이)을 추측하는 식이 있다고 가정하자. 값의 발산식과 의사코드는 다음과 같이 나온다.이를 pthread로 계산하면 다음과 같은 코드가 나온다.이 코드가 과연 잘 돌아갈까?그것은 아니다. n을 증가시킬 수록 값이 달라진다.그 이유는 sum에 합산을 하
14.세마포어

Producer-Consumer Synchronization and SemaphoreBusy Waiting은 주어진 순서대로 Critical Section에 접근하기 때문에 성능적으로 별로다.Mutex는 시스템의 임의의 방식으로 순서가 정해진다(랜덤).각 스레드에 cr
15.Barriers and Condition Variables

모든 스레드가 같은 지점에서 실행될 수 있도록 보장해주는 것을 Barrier이라고 한다. 특정 지점을 barrier로 막아두고, 모든 스레드가 도착할 때까지 대기한다고 보면 된다. 일반적으로 Barrier를 많이 쓰게 되면 성능이 좋진 않다.기다리는 지점은 모두 똑같지
16.Read-Write Locks
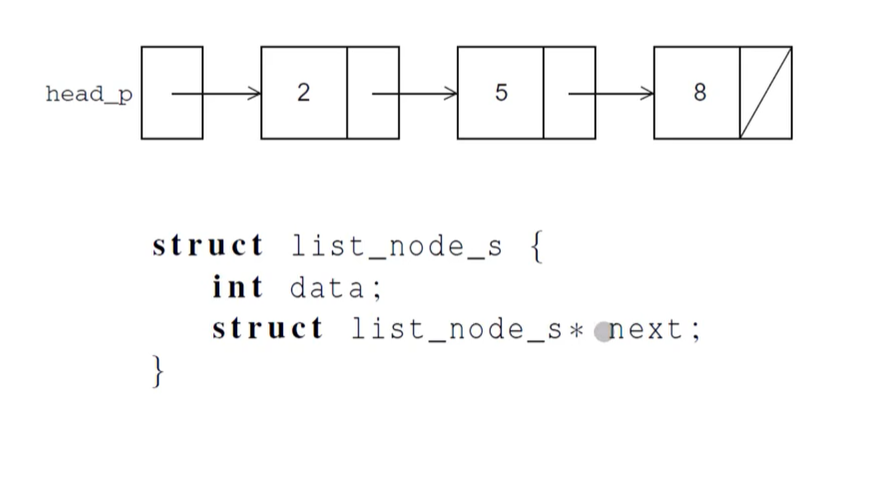
공유 데이터 구조는 멤버인지 아닌지, 삽입 그리고 삭제에 대한 명령들이 int로 정렬된 Linked List라고 가정하자.그리고, 멤버가 존재하는 지의 여부를 알려주는 소스코드가 있다.삽입 오퍼레이션이다. 저장하고자하는 요소를 임시 노드에서 값을 가져와, 중간에 연결고
17.Read-Write Locks
공유 데이터 구조는 멤버인지 아닌지, 삽입 그리고 삭제에 대한 명령들이 int로 정렬된 Linked List라고 가정하자.그리고, 멤버가 존재하는 지의 여부를 알려주는 소스코드가 있다.삽입 오퍼레이션이다. 저장하고자하는 요소를 임시 노드에서 값을 가져와, 중간에 연결고
18.False Sharing
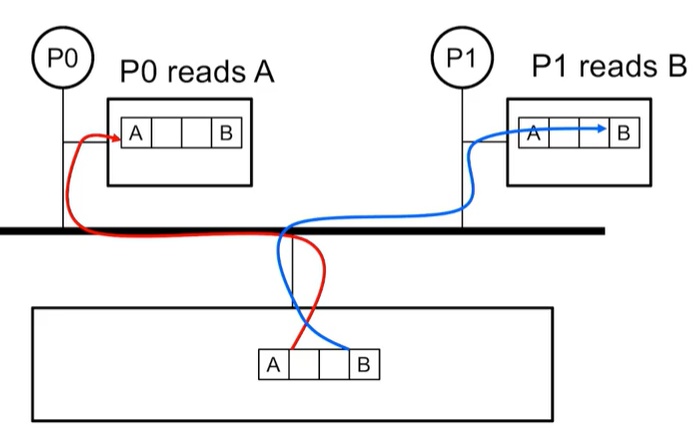
캐쉬는 최근의 사용된 아이템, 자주 사용된 아이템들을 프로세서와 가까운 쪽에 저장한다. 이러한 캐쉬는 Shared-memory에 많은 영향을 줄 수 있다.2개의 프로세서가 같은 캐시 라인에 할당되어 있다. P0가 프로세스 A를 읽고, P1이 프로세스 B를 읽는 것 자체
19.Thread-safety

어떤 코드가 다수의 스레드에 의해 아무 문제 없이 실행되는 것을 Thread-safe하다고 할 수 있다.영어 텍스트로 구성되어 있는 파일을 다수의 스레드를 사용하여 토크나이즈하는 상황을 가정해보자. 텍스트에 공백문자, 탭키 등을 통해 텍스트들을 구분해본다.가장 심플한
20.Message Passing Interface(MPI)
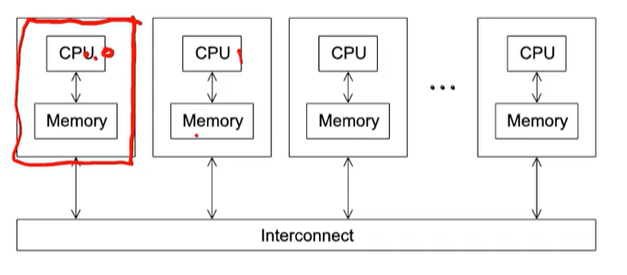
분산 메모리 환경에서, 각 CPU는 독립적인 환경을 갖고 있기 때문에 MPI를 통해 메세지를 주고 받는다. 서로 다른 interconnect를 가진 CPU들이 같은 소프트웨어를 읽어야 하기 때문에 이를 MPI에서 담당하게 된다.C코드에서 MPI를 사용하기 위해서, mp
21.MPI Programming Example

이번엔 MPI를 이용하여 적분을 계산해볼 것이다.적분식은 다음과 같다.이 적분식을 Serial Code로 작성하면 아래처럼 나온다.이 적분코드를 병렬화시켜보려고 한다. 고려할 점들을 정리하자면1\. 문제해결에 대한 작업들을 나눈다.2\. 작업들 간 필요한 통신채널을 정
22.Collective Communication

위와 같은 동작을 실행한 트리 구조로 된 통신이 Sum을 하게 된다면, 아래처럼 나온다.또 하나의 예시로, 하나의 합으로 모으는 과정이 있다.MPI_Reduce를 사용하면, 위에서 합을 계산한 것처럼, 각 프로세스에서 계산한 결과를 한 곳으로 모아줄 수 있다.MPI_R
23.데이터 분산
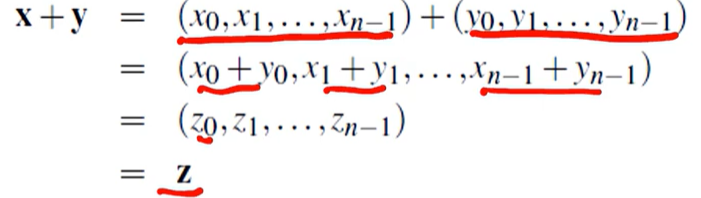
위와 같은 연산식이 있다고 치자. 시리얼하게 실행하면 단순히 for문을 돌려서 계산할 것이다. 하지만 이를, 분산 컴퓨팅으로 계산하려면 어떻게 해야될까?12개의 컴포턴트 벡터를 3개의 프로세스로 파티션을 나눈다.데이터를 분산시키는데에 3가지 방법이 있다.Block전체를
24.성능 평가 & 병렬 정렬

성능 평가 시간 측정 일반적으로 elasped time으로 병렬처리 시간을 계산한다. 병렬처리가 되기 전의 시간을 구하고 병렬 처리가 끝난 뒤의 시간을 구한 뒤 이 두 시간의 차이를 계산한다. 이 경우엔 MPI를 사용할 필요는 없다. timer.h에서 제공하는 함수