Virtual Memory
매우 큰 프로그램을 사용할 경우 하드디스크에 스왑 스페이스를 통해 하드 디스크에 가상 메모리를 생성하여 이곳에 넣음. -> 메인메모리의 캐시 역할을 한다.
오랫동안 사용하지 않는 프로그램은 스왑 스페이스에서 보관한다. 메인메모리에서 사용 중인 프로그램들을 보관한다.
여러 개의 프로그램의 메모리 영역을 독립시켜 서로에게 영향이 끼치지 않도록 한다.
- Swap Space(스왑 스페이스) : 하드디스크의 두번째 블럭
- Page(페이지) : data와 instruction을 한번에 translation해준다. 1바이트씩 읽으면 효율이 떨어지기 때문에, 한 번에 모아서 묶음 단위로 처리한다. 4~16킬로바이트까지 블록을 할당한다.
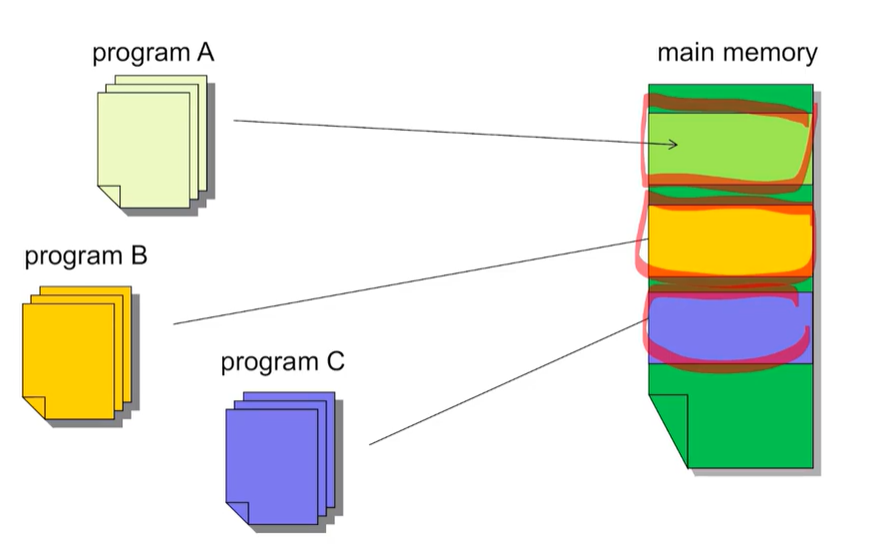
Virtual Page Numbers
프로그램이 컴파일될 때, Page들은 가상 페이지 번호를 할당받는다.
프로그램이 실행될 때, 물리적 주소에 할당된 가상 페이지 번호 테이블을 생성한다(VPN -> PPN Translation)

Translation-Lookaside Buffer(TLB)
Translation을 하기 위해 메인메모리를 한번 거치고, 완전히 번역된 결과값을 가지고 실제 데이터에 접근하기 위해 한번 더 메인메모리를 거친다.(총 두 번을 거치게 된다)
-> 가상 메모리를 사용하면 처리 시간이 증가한다는 뜻이다.
어떻게 하면 프로그램의 런타임을 개선할 수 있을까?
Page Table은 가상 페이지 번호와 물리 페이지 번호를 갖고 있는 작은 해시테이블이다. 이 테이블을 캐싱한 것을 TLB라고 한다. 이름 그대로, Translation을 위한 테이블 버퍼이다.
- Page Fault : 물리 주소에 접근했는데 메인 메모리에 없으면, Swap Space로 가게 되는데 이것을
Page Fault라 한다. 오버헤드가 발생되어 리소스 소모가 심해진다.
Instruction Level Parallelism(ILP)
여러 개의 명령을 동시에 사용할 수 있도록 멀티 프로세서를 사용한다.
- Pipelining : 각 명령(Instruction)마다 functional unit들을 스테이지로 나열되어있다.
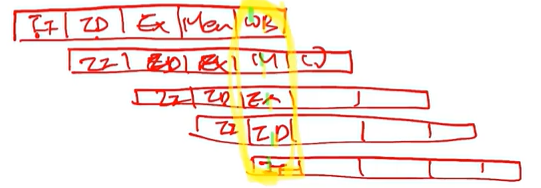 여러 개의 Instruction이 동시에 처리된다(Super Scalar 머신). -> 성능 향상
여러 개의 Instruction이 동시에 처리된다(Super Scalar 머신). -> 성능 향상
Pipelining 예시
소수를 더하는 명령체계가 있다고 가정하자 두 숫자는 9.87 \* 10^4과 6.54 \* 10^3이 있을 때, 다음과 같은 테이블이 나온다.
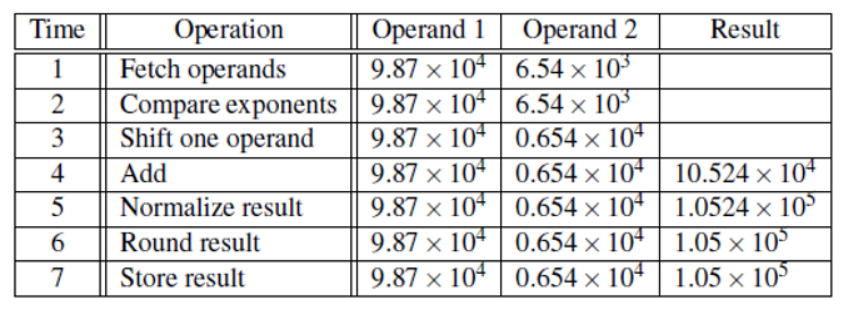 7번의 명령체계를 거쳐야 두 소수의 합을 구할 수 있다. 하나의 명령을 수행할 때 1 nanosecond가 소요된다.
7번의 명령체계를 거쳐야 두 소수의 합을 구할 수 있다. 하나의 명령을 수행할 때 1 nanosecond가 소요된다.
이러한 작업을 1000번 거친다고 하면,
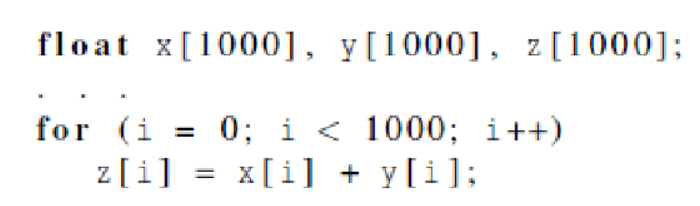 이런 식의 코드가 나온다. 단순하게 계산해보면, 소수점을 한번 계산할 때 7 nanoseconds가 소요되므로, 1000번 계산하면 7000 nanoseconds가 소요된다. 이 작업을 기능적 단위(Functional Unit)으로 명령을 나누면 효율성을 높일 수 있다.
이런 식의 코드가 나온다. 단순하게 계산해보면, 소수점을 한번 계산할 때 7 nanoseconds가 소요되므로, 1000번 계산하면 7000 nanoseconds가 소요된다. 이 작업을 기능적 단위(Functional Unit)으로 명령을 나누면 효율성을 높일 수 있다.
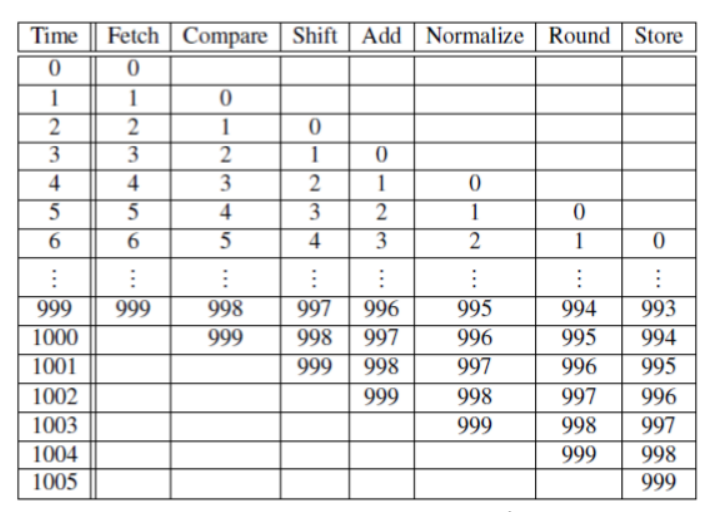
각 명령을 유닛별로 독립시켜 동시에 실행하게 된다면, 위 표처럼 수행하게 된다. 하나의 명령이 끝나면 다음 명령이 실행되고 다음 데이터에 대해 명령을 실행한다. 이 작업을 동시에 실행하면 실행시간을 1006 nanoseconds로 줄일 수 있다.
