C++ main 목표 중 하나는 code 재사용성을 높이는 것이다. 그 방법으론
1. Public inheritance
2. object인 class member 사용 => containment, composition, layering라고 함.
3. Private/Protected inheritance
1번은 is-a relationship, 2번3번은 has-a relationship 구현
is-a 관계가 아닌데 public inheritance를 쓰면 안좋다.
예를들어 student class에서 string으로 이름을 표현한다면 이는 is-a가 아닌 has-a이다.
이때 public inheritance를 하게되면, student에 string operation을 직접 할 수 있게된다.
설계상 보기 안좋은듯, 문제가 있네The valarray Class (간단하게)
valarray header file을 통해 지원하는 class
숫자 data의 배열을 표현하고, (vector/array class와 다른 점은) 데이터합, max찾기, min찾기 같은 여러 연산을 지원한다는 것이다.
여러 data에 대해 적용될 수 있도록 template class로 만들어짐.
valarray<int> weights; //이렇게 object를 생성할때 type을 명시해준다.valaaray<double> v1; : size 0인 double 배열
valarray<double> v2(3); : size 3인 double 배열
valarray<int> v3(10,8); : size 8인 배열, 각 elements는 10으로 세팅
valarray<double> v4(gpa, 4); : size4인 배열, 첫 4개 elements를 gpa 배열의 첫 4개로 초기화
valarray<int> v5 = {10, 17, 15}; : C++11 이후로 가능
operator[], size(), sum(), max(), min() 연산 가능
`typedef std::valarray<double> ArrayDb;`로 private에서 선언해두면
해당 class 내부에서만 간단하게 해당 type을 표현할 수 있다.Containment (composition/layering)
: 특정 class에서 다른 class의 object를 member로 가지는 것=> 보통 private에 추가
has-a relationship을 구현하는데 사용.
이렇게 내부에 선언된 ojbect member는 해당 class의 interface가 아닌 implementation을 획득한다.
그러므로 그 object member를 통해서 해당 class의 interface(멤버함수 등)을 사용해야 한다.
복습) explicit keyword 활용해서 parameter 하나인 ctor의 implicit conversion 막기!
필요한 순간엔 explicit으로 호출해서 쓰면되니, 매번 주의를 기울이는 것보단 이게 낫다.Contained Objects 초기화
inherited components처럼 모든 member objects는 다른 것들이 만들어지기전에 만들어진다.
그래서 마찬가지로 이런 member objects도 member initializer list를 사용하여 초기화한다.
사용하지 않으면 해당 object들의 기본 ctor이 자동 호출된다.
당연히 객체 이름 사용하여 member initializer list에서 초기화한다.
member object가 다른 member들보다 먼저 만들어져야된단건 왜 있는진 잘 모르겠긴한데,
어쨌든 member initializer list 안쓰면 default ctor호출된단건 당연한 얘기.
class object 만들려면 ctor 당연히 써야된다. 여러번 말하지만 ctor {}내부에서 하는건
assign 형식이므로 일단은 default ctor로 member ojbect들을 생성할 것이다.짚고넘어갈 것들
(책에서 code 직접 작성해보는데 언급 넘어갈만한 것들..)
이미 만들어진 class에서 << operator로 print하는 기능 지원하지 않는다면,
즉, 이미 만들어진 class의 object를 사용하는데, <<가 overload안돼서 사용할 수 없다면,
당연히 그냥 직접 print하는 함수를 작성해야한다.(ex: p.793)
private method도 당연히 class 밖에서 다른 멤버함수들처럼 정의해도 된다. 접근을 제한하는 것일 뿐.
Private Inheritance
마찬가지로 has-a relationship을 구현하는데 사용.
class Student : private std::string, private std::valarray<double> {~};
이렇게private을 앞에 붙여준다. 사실 아무것도 안붙이면private이 기본이다.
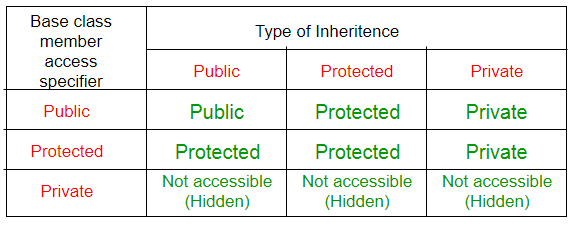
Base class의 public과 protected member가 Dervied class의 private member가 된다.
(private은 어떤 inheritance를 사용하든 직접 접근할 순 없다.)
private inheritance에선 base의 public methods가 derived의 private methods가 되므로
derived class는 "base-class interface"를 inherit 하지 않는 셈이다.
즉, containment에서처럼 interface가 아닌 implementation을 받아오므로, 둘의 차이는 구현에 있지 사용되는 interface는 같다.
즉, private inheritance이든 containment이든 client의 code는 같다.
containment에선 named member object가 가시적으로 추가됐다면,
private inheritance에선 unnamed inherited object가 derived class에 추가된다.
(진짜로? ㅇㅇ진짜 추가됨. 사실 다른 inheritance도 마찬가지임. 링크1링크2. 이 추가되는 object를 책에선 subobject라고 하겠다고 함.)
private inheritance는 containment와 달리 object 하나만 추가한다.
이름있는 object를 만들어서 쓰는 느낌이 아니라,
inherit하는 순간 derived class가 inherit한 class 자체를 포함하는? 표현할 수 있는 것이다.Constructors in Private Inheritance
public inheritance에서처럼 base class의 ctor을 member initializer list에 추가해 초기화한다.
containment에선 실제 named object가 추가된거라 member initializer list에 그 member 변수의 이름을 사용했지만, 여기선 당연히 class name이 ctor 함수 이름일테니 그걸 사용한다.
Base-Class Methods 사용하기
public에서와 마찬가지다. Base class의 private이 아닌 함수는 그냥 이름으로 호출할 수 있다.
sum();
만약 redefine돼서 가려졌거나, MI여서 같은 이름의 함수가 있다면
std::valarray<double>::sum();식으로 ::를 사용해 구분해서 호출해줘야 한다.
Base-Class Objects 접근하기
private inheritance에선 implicit upcasting 안된다.
(p.738에 애초에 public inheritance라고 적혀있었음)
생각해보면 upcasting이 의미가 없는게, base pointer로 derived object를 가리켜봤자,
base pointer가 사용할 수 있는 부분들은 전부 private이다.
그렇기때문에 Derived-class object에서 Base-class object 부분을 접근하려면
아예 explicit typecasting을 해야한다.
Q. 근데 그럼 왜 explicit type casting은 허용하지? 그리고 그렇게 해도 결국 base부분은 private아닌가?
답변
그냥 별 의미없이 c style의 이런 casting은 그냥 거의 아무때서나 되는 강제..수준이네
그리고 아마 downcasting할때 typecast했듯이, 여기서도 explicit typecast하면 기존 객체 이용하는게 아니라 새롭게 만들며 casting 되므로 base부분이 private이라곤 생각 안해도 되지않을까..
참고로 implicit upcasting은
public inheritance라면 아무때나 가능하고,
protected inheritance라면 derived class내에서만 가능하고,
private inheritance라면 implicit upcasting은 아예 불가능하다.
Base-Class Friends 접근하기
마찬가지로 public inheritance인 경우와 크게 다를게 없다.
friend functions은 class의 member가 아니므로 argument가 잘 구별되도록 호출한다.
주로 typecasting을 이용
Containment VS Private Inheritance
Q. 둘 다 has-a relationship 표현하면 뭐를 써야하지?
A. 대부분 C++ programmers는 containment를 선호
1) 명확한 object name이 있으니 관계가 잘 보인다.(함수호출할때도 어떤놈인지 잘 보이고 그럴듯)
반면 inheritance에선 좀 모호할 수 있다.
2) 뒤에 보겠지만 inheritance는 MI를 할 경우 문제가 될 수 있다.
3) 같은 class에서 여러 object를 포함할 수 있다. inheritance는 nameless object라 하나밖에 안된다.
하지만 아래의 경우 private inheritance 사용
1) protected를 사용해야한다면 private inheritance를 사용해야 한다. containment론 base의 protected에 접근하지 못한다.
2) virtual functions을 redefine하고 싶다면 마찬가지로 inheritance를 사용해야한다.
> 성능
성능 측면에선 private inheritance가 더 나을 수 있다.
new로 할당받아서 초기화할 경우를 생각해보자. composition이나 private inheritance나 사용하는 memory 면에선 크게 차이가 없다.
하지만 composition을 사용할때 포인터나 reference로 class 내부에서 선언한다면, 객체가 memory 여기저기에 흩어질 수 있다.
최근 cpu에선 cache 메모리를 많이 사용하면서 특정 객체가 메모리에 여기저기 흩어져있으면 속도면에서 불리할 수 있다.
(이정도까지 신경쓸 일이 많이 있으려나 싶다만 알고는 있자)
Protected Inheritance
마찬가지로 has-a relationship을 구현하는데 사용.
class Student : protected std::string {~};
Base-class의 public과 protected member가 Derived-class의 protected member가 된다.
private inheritance와의 차이점은 derivation이 3번 일어날때 발생할때를 본다.
A<-B<-C 순으로 inherit이 됐다고 했을때
private inheritance에선 C가 A의 public/protected member에 접근할 수 없지만,
protected inheritance라면 C에서 A의 public/protected member에 접근할 수 있다.함수 Access 변경하기
Private/Protected Inheritance에서는 Base-class methods가 Private/Protected가 된다.
(함수들은 보통 Base의 public에 있을테니 그런거임. 당연히 private에 있는 함수들은 예외)
만약 그 함수들을 public으로 바꾸고 싶다면?
- base-class method를 이용하여 함수를 redefine한다.
즉, derived-class의public에 redefine 함수를 작성하고,
그 redefine 함수 내에서 그냥 기존 함수를 호출해버린다. usingdeclaration을 사용한다.
public: using std::valarray<double>::min;
이런식으로 derived class의 public에 추가하면 이제 여기선 public 함수가 된다.
당연히 redefine이든 using을 쓰든 containment에선 안된다.
containment에선 기존 Base-class 함수들 그대로 사용할 수 밖에 없다.
private/protected 상속일때 public을 바꾸는 경우 말고,
다르게 Access 수정하는 경우도 많지않나? 그때도 다 위처럼 적용하면 되나?
: 책에선 위 경우만 보긴 함. 뭐 다른 경우(ex. Access를 protected로 변경)여도 될거같긴한데..
위처럼 private/protected 상속일때 base 함수들 public으로 바꾸는 경우가 대부분일듯?Multiple Inheritance (MI)
C++은 다중 상속이 가능하다.
class SingingWaiter : public Waiter, Singer { ~ };
이렇게 , 로 구분한다. default는 private이므로 위에서 Singer는 private inheritance
문제점
MI는 (공통 조상 class가 있을때) 문제가 생기기 쉽다.
(1)중복된 instance가 derived class에 생기는 경우
(2)같은 이름의 methods를 각 class에서 상속 받는 경우
그래서 대부분 C++ community에선 MI를 강하게 거부한다. (잘 쓰면 유용하긴 함.)
위 문제점을 하나씩 해결해보자.(public MI라고 가정)
Virtual Base Classes
B와 C가 A를 inherit하고, D가 B와 C를 inherit(MI)한다고 해보자.
D에는 A의 instance가 두개가 생긴다.
즉, A * base_ptr = &d_obj;는 ambiguous이다.
(d_obj는 D class object라고 가정,, d_obj에는 A part가 두개 있으니 뭘 말하는지 모름)
> 해결법1
A * base_ptr = (B *) &d_obj;, A * base_ptr = (C *) &d_obj;
이런 식으로 어떤 곳의 A 부분인지를 명시해준다.
그러나 이런 방식은 polymorphism을 어렵게 한다.
> 해결법2
Virtual Base Class를 이용한다. 아래와 같이 선언, virtual 순서는 상관없다.
class B : virtual public A {~};
class C : public virtual A {~};
공통 base를 가지는 class들로부터 상속받은 class의 object가, 공통 부분은 하나만 만들도록 해준다.
무슨 말이냐면 위처럼 B와 C에서 A를 virtual base class로 만들면 B와 C를 상속하는 D의 object는 A object를 하나만 포함한다.
여기서 말하는 virtual은 virtual 함수와 다른 의미이다.
C++ community에서 새로운 keyword가 추가되는건 별로 안좋아해서(기존 프로그램과 충돌가능성)
기존의 virtual을 새로운 기능의 keyword로도 사용한 것이다.
왜 base class 자체를 virtual로 만들지 않고 inherit할때 저렇게 선언해줄까?
base의 multiple copies가 실제로 필요한 상황이 있을 수도 있다.
그리고 그렇게 만들면 program에 추가적인게 늘어날 수 있고,
말했듯이 우리에게 필요하지 않은 기능에 비용을 지불하지 않는 것이 설계 원칙이다.
나중에 필요성을 알았을때 존재하는 code에 가서 virtual을 붙여줘야하는 단점도 있다.Virtual Base Class에서의 Constructor
non-virtual base class에서는 derived-class의 ctor에 immediate base class의 ctor밖에 못왔다.
여러 단계로 상속된다면 자동으로 쭉 base-class constructor가 호출된다.
Virtual Base Class인 경우는 해당 Base Class의 Constructor가 자동 호출되지 않는다.
왜냐하면, 공통 Base의 Object는 하나만 만들어져야하는데, 자동 호출되면 constructor가 두번이상 호출될 수 있기 때문이다.
그러므로 우리가 virtual base class의 ctor을 호출해줘야한다.(member initializer list에)
무슨 말이냐면, 위 예시를 그대로 보자면,
D class constructor에서 A class constructor를 호출해줘야한다는 소리다.
원래는 D에서 A를 호출할 필요가 없었다. 왜냐하면 자동으로 쭉 ctor들이 연쇄적으로 호출되니까.
근데 virtual base class에선 그러지 않으므로, virtual base class를 "직간접적으로 상속받는 모든 class"는 해당 virtual base class의 ctor을 직통으로 직접 호출해야한다.
(여기서 말하는 간접적인 상속은 D와 A 같은 관계를 말한다. 바로 상속 받는게 아닌.. 이런 관계에서의 ctor 호출은 virtual base class가 아니라면 illegal이다.)
항상 그래왔듯 따로 지정하지 않으면 default ctor를 호출한다.
MI에서의 함수 설계
다른 classes에 같은 이름을 가진 함수가 있을때 MI가 일어나면
당연히 두 함수는 ::를 통해 class name으로 구분해준다.
show() 함수를 예시로 들어보자. show()는 각 class의 data를 print한다.
B와 C는 A를 inherit해서 각각 show()를 redefine한다.(A에 virtual로 선언해 정의함.)
D는 B와 C를 inherit해서 show()를 redefine하고 싶지만, 잘 안된다.
단일 상속이었다면 간단하게 base 함수 호출하고 D의 정보만 추가 print하도록 redefine하면 되지만,
MI에선 A,B,C,D의 data를 모두 print하려고하면, base의 함수를 호출하면 중복 print가 된다.
D의 show()에서 B::show();와 C::show();를 하면 A의 부분이 두번 print된다. 그렇다고 B::show(); 하나만 쓰면 C부분이 print가 안된다.
1.
이럴때 각 class 본인의 components만을 다루는 helper 함수가 있으면 좋다.
예를들어 위 경우에선 data() 함수를 만들어서, 그 함수는 각 class의 data만을 print하도록 한다.
이런 helper 함수는 내부적으로 도움을 주기위해 쓰이는 것이므로 protected에 만들면 좋다.
(protected가 유용한 순간)
그러면이제 MI가 일어나도 그 helper 함수를 조합하기만 하면 된다.
2.
혹은 모든 data를 protected로 만들 수도 있다.
위 같은 경우에서도 우리가 굳이 base의 함수를 이용하는 이유는 직접 base class의 data에 접근할 수 없기 때문이다.
protected로 만들면 원하는 data에 접근해서 직접 정보를 print 할 수 있다.
하지만 1번 방식이 더 data 관리하긴 좋다.
정리하자면, MI에서 공통 ancestor가 있다면,
1. virtual base class를 이용해야하고,
1-1. virtual base class의 ctor은 직간접적으로 상속받는 모든 class에서 직통으로 호출해야한다.
2. 그리고 바로 위에서 봤듯이 show() 같은 함수는 helper 함수를 protected에 정의해서 사용한다.추가 내용
Q. Virtual과 Nonvirtual Base가 섞여서 inherit되면 어떻게 되나?
A. virtual로 상속받았던 애들에선 subobject가 하나만 만들어지고, nonvirtual인 곳에선 하나씩 다 subobject가 만들어진다.
classes C와 D에 B가 virtual로 상속되고, X와 Y에 nonvirtual로 상속됐을때,
M이 C,D,X,Y를 모두 inherit한다면,
C/D에서 하나, X/Y에서 각각 두개, 총 3개의 B의 subobject가 M에 만들어지는 것이다.
Dominance
일반적인 MI에서 같은 이름의 함수가 두개 있다면 unqualified인 경우 ambiguous이다.
하지만 virtual base class가 관여한다면, unambiguous일 수도 있다.
링크에서 답변에 "An important detail here is this line:"부터 보면 됨.
예시들
언제쓰일지도 잘 모르겠고 남발하면 코드 어려워질거같은데.. 일단은 이런게 있다 정도로만 알고가자.
결론
결국 잘 보면 MI에서의 문제들은 "공통 ancestor때문"이다.(diamond구조로 inherit될때)
그런 경우가 아닌 MI라면 그냥 qualifying만 잘해주면 된다.★
(diamond 구조 상속은 피하는게 맞으니 qualifying만 잘하자..)
Class Templates
type generic Class를 만들고 싶을 때도 있다. ex) type generic Stack
(Stack 같은 class를 container class라고 하는데, 사실 templates을 도입한 main motivation은 이런 container class의 재사용성을 높이기 위함이었다.)
매번 필요한 type마다 class를 만드는 것보다 type 자체를 parameter로 받아버려서 그걸로 class를 만들도록 하는 것이다.
function template에서처럼 우리는 Class Template을 통해 type을 인자로 받아서 Class를 만드는 틀을 만들 수 있다.
※ Class Template 선언/정의
template <class Type>template <typename Type>둘 중 하나를 Class declaration 앞에 붙여준다. 그럼 그 밑의 Class가 template에 속해지는 것이다.
<> 이게 type을 받는 "template parameter"를 적는 곳이다.
(class/typename은 Type parameter 변수가 어떤 type이든 받을 수 있는 parameter라는 뜻)
class의 member 함수들에도 template <class Type> 을 붙여준다.
그리고 class 구분을 위해 함수 이름 앞에는 Stack<Type>:: 을 붙여준다.
inline defintion으로 작성한다면 이런거 안붙여도 된다.
여기서 Stack<Type>이 class의 full name인 셈. 그냥 Stack이라고 축약형으로 표현하려면 class scope 내부여야 한다.
template <class Type>
bool Stack<Type>::push(const Type & item) {
...
}(작동원리)
잘 보면, 이 member 함수와 class는 각각 따로 template으로 선언된다.
template <class Type>이 앞에 똑같이 붙었다고해도 내부적으로 특별한 연결고리가 만들어지는게 아니다. 잘 생각해야된다. 그냥 각자 template으로 만들어진거다.
specialization시에 각각 template에 의해 실제 instantiation이 만들어지고, 그게 우리가 봐왔던 class와 멤버함수처럼 연결이 되도록 모양을 잡아주는 것일 뿐이다.
둘은 따로 선언된 것이므로 Class가 instantiate됐다고해도 member 함수 definition도 같이 만들어지진 않는다. class내의 member 함수 declaration만 class랑 같이 만들어질 뿐이다.(답변참고)
> File 분리하지 않기
일반 Class에서와 다르게 Template member 함수들을 다른 file에 분리해두면 작동 안한다 :이유
책에선 template member 함수들은 실제 함수가 아니므로 따로 compile 될 수 없다고 함.
(template은 틀이므로 함수 찍어내고 나면 없어지는 놈이다.)
(HeaderFile에 넣는건 괜찮다. 애초에 헤더는 컴파일할때 따로 목적파일이 생기지 않기 때문이다. 일반 소스파일이 헤더 코드에서 필요한 정보를 가져와 목적파일로 변환될 뿐이라 그렇다.)
그래서 보통은 그냥 class template은 header file에 member 함수까지 통째로 넣고 사용한다.
근데 header file에 함수도 몰아넣어버리면, a.cpp와 b.cpp에 같은 함수가 instantiate될 수 있지 않나?
그럼 함수 정의가 두개 생기는데, ODR 위반 아닌가?
: ㄴㄴ ODR은 같은 정의라면 OK이다.
예를들어 a.cpp에 int x;와 b.cpp에 int x;가 있다면 이는 ODR 위반이지만(전역변수일때)
int x=5;와 int x=5;가 있다면 ODR 위반이 아니다.
class template의 멤버함수 경우도 같은 함수 정의가 instantiate 될 것이므로 ODR 위반이 아니다.
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
template member 함수들을 다른 파일에 위치시켜도 되도록 하는게 export keyword라고하는데,
C++11 이후론 중단됐다. export란걸 이럴때 썼구나 정도만 알면 될듯.※ Template Parameter
위에선 generic type이 하나라서 parameter가 하나였지만, 여러개여도 괜찮다.
ex) template<class t1, class t2, int n> class ex {~};
Template Parameter에는 아래 두가지 종류가 있다.
-
Type Parameter
일반 parameter와 달리 type을 표현(저장)하는 parameter이다.
template <typename T>에서의T가 바로 type parameter -
Non-type Parameter (|| expression parameter)
template은 type이 아닌 argument도 non-type parameter를 이용해 받을 수 있다.
template<class T, int n> class ex {~};에서의n이 바로 non-type parameter
Non-type 제한사항
non-type parameter는 integer type/enumeration type/reference/pointer 중에 하나여야만 한다.
또, template code는 non-type parameter의 값을 변경하려하거나 주소를 가져오려하면 안된다.
마지막으로, template을 instantiate할때 expression argument에 사용되는 값은 무조건 constant expression이어야 한다.
그래서 `double`은 안되지만, `double & m`은 OK
또 constant expression을 입력받아서 그런지, template내에서 constant expression으로 쓰인다.
배열 길이에도 쓰고..> Default Type Template Parameters
type parameter에 기본값을 줄 수 있다.
template <typename T1, typename T2 = int> class Topo { ~ };
함수 template parameter에선 안된다.
non-type parameter에도 기본값을 줄 수 있는데, 이건 함수이든 class이든 다 가능하다.
explicit specialization이랑 다른가? 라고 생각할 수 있는데,
어느 정도 기능이 비슷한건 맞지만 사용처도 다르고 확실히 다르다.
얘는 그냥 보조해주는 느낌이고, default type도 같은 class를 구현한다.
explicit specialization은 해당 type에 특수화되게 아예 다르게 구현된 것이다.> Non-type parameter VS Constructor parameter
ex.
Stack class template이 있다고하자. Stack size를 명시하는 방법이 위 두가지가 있다.
전자 방식은 non-type parameter를 통해 stack size를 입력받아 array를 만들어버린다.
후자 방식은 class instantiation과 별개로 ctor을 통해 stack size 입력받아 동적할당 받는다.
1) 일단 non-type parameter 방식이 더 빠르다. 전자에선 array를 만드므로 ss를 사용하고, 후자는 heap에 할당받으므로 당연히 후자가 상대적으로 느리다.
2) 같은 type의 다른 길이 stack을 만들때 non-type parameter 방식은 memory 낭비된다.
ArrayTP<duoble, 12> a; ArrayTP<double, 13> b; 하면 stack size 12,13인 class가 각각 총 2개 만들어진다.
반면 Stack<int> a(12); Stack<int> b(13); 하면 Class는 하나만 만들어서 사용한다.
3) constructor 방식은 stack size가 class member에 저장되므로 사용 범위가 넓다.
전자 방식에선 서로 다른 size끼리 assign하거나 할때 함수 만들기가 쉽지 않을 것이다.
그래서 vector class template도 constructor의 parameter로 크기 입력 받는듯
※ Specializations
template 목적이 뭔지 다시 잘 생각해보자. type generic을 위한 틀이다, type을 template argument로 넘겨주면 해당 class를 만든다.
이렇게 argument를 넘겨줘서 실제로 만들어진 특정 class를 instantiation, specialization이라고 한다.
template을 정의할때 사용하는 parameter는 class name 앞에 적었지만, 그곳에 넘겨주는 argument는 class name 뒷쪽에 작성한다. template parameter VS argument
specialization을 만들려면 당연히 type argument는 필요하므로, 모두 name 뒷쪽에 template argument가 명시된다.
Specializations 엔 총 3가지 종류가 있다.
1. Explicit Instantiations
(template의 목적 그대로 template이라는 틀을 이용해 class를 만들어내는 것)
template class Stack<int>;
이렇게 앞에 template이라고 작성해주고, 뒤에 <>안에 argument를 작성한다.
이러면 template을 이용해 Stack<int> Class가 만들어진다.
2. Implicit Instantiations
Stack<int> stack_obj;
이렇게 template keyword 없이 실제 object를 만드는 것처럼 사용한다.
마찬가지로 template argument는 명시하지만, Stack<int>라는 class(type)을 이용해 object를 만드는 문법이랑 비슷하다.
이 경우도 마찬가지로 template을 이용해 Stack<int> Class를 만들고, 그 class를 이용해 stack_obj object까지 만든다.
3. Explicit Specializations
template <> class Classname<specialized-type-name> { ~ };
template을 이용해 Class를 만들지않고, 특정 경우에서의 Specializations을 미리 만든다.
(특정 type에선 template 틀을 이용하고 싶지 않을 수 있다.)
<specialized-type-name>과 같은 template argument가 들어왔을때, template을 이용해 class를 만드는게 아니라 이 정의를 사용한다.
explicit specializations은 기존 template이랑 틀은 같은데 뒤에 template argument만 명시한다.
위 두 instantiations과는 다르게 template argument로 class를 만드는게 아니라
이런 template argument에선 이렇게 처리하겠다고 명시해주는 느낌이네3-1. Partial Specializations
전부 완전히 specialize하는게 아니라, 부분적으로 specialize할 수도 있다.
ex)
template <class T1, class T2> class Pair { ~ }; //general template
template <class t> class Pair<t, int> { ~ }; //T2:int, T1은 아무 type가능
Pair<double, double> p1; //general template 사용
Pair<double, int> p2; //partial specialization 사용
template<class T> class Feeb { ~ }; //general template
template<class k> class Feeb<k*> { ~ }; //pointer partial specialization
Feeb<char> fb1; //general template 사용
Feeb<char *> fb2; //Feeb<k*> specialization 사용
template<class T1, class T2, class T3> Trio{ ~ }; //general template
template<class t1, class t2> Trio<t1,t2,t2>{ ~ };
template<class T1> Trio<T1, T1*, T1*>{ ~ };
Trio<int, short, char*> t1; //general template 사용
Trio<int, short> t2; //Trio<t1,t2,t2> 사용
Trio<int, short, char*> t1; //Trio<T1, T1*, T1*> 사용
"type argument"를 기준으로 가장 specialized된 형태를 사용한다.
Trio<int, short> t2; 이것도 argument만 보면 t2는 중복되니까 줄거 다 준거임.중간에 pointer 다루는건 책 문법이 이상해서
https://docs.microsoft.com/ko-kr/cpp/cpp/template-specialization-cpp?view=msvc-170
여기 예시처럼 작성함.보면 template parameter가 비지않고 명시되는데, 얘네는 기존 general template 선언에서의 parameter와 상관없다.
partial specializations의 argument에 사용되는 parameter인 것이다.
(책에선 기존 template 선언문이랑 partial specializations이랑 parameter 문자를 같게해둬서 둘이 연관이 있는건가 헷갈림. 난 그래서 일부러 다르게 적음)
이런 explicit (full/partial) specialization은 어떻게보면 template에서 overloading?하는 방법이다.
functions은 signature로 모든 함수가 구분되기때문에 signature가 좀만 다르면 overload가 되는거였지만, template은 애초에 type generic이기때문에 overloading은 의미가 없고 이런 특수한 경우를 정의해주는게 함수에서의 overloading 역할을 하는 셈이다.
(override보단 overload 같기도하고..)
CH8에 나오는 overloaded template은 overloading된 여러 버전의 함수 각각에 대해서 template을 만들어준다는거지, template parameter를 이용해서 template이 overload된다는게 아님.
※ Template 사용
일반 class에 하듯이 사용할 수 있다.
template으로 만든 class의 full name을 이용해서 실제 class type처럼 사용할 수 있다.
즉, Template_name<Type_name>이 사실상 class 이름인 셈이다.
object 선언, parameter/return type 명시 등.. Stack<int> i_stack;, Stack<int> func();
단순히 type 명시하고, object 만드는 것 뿐만 아니라 당연히 constructor도 사용할 수 있다.
Pat<string> ar[2] = {Pat<string>("dog"), Pair<string>("cat")}
Pair<string, int> a("The Duck", 5);
심지어 다른 template class를 만들때도 사용된다. Array < Stack<int> > asi;
(C++11 이후론 상관없긴한데, 위처럼 > 띄워써야했다. confusion with >>)
이를 이용해 2차원 배열 만들 수도 있음.
ArrayTP< ArrayTP<int, 5>, 10> twodee; == int twodee[10][5];
(ArrayTP code는 p.843)
template 내부에서 다른 template을 쓴다면,
자세하게 Stack<int>로 안하고 Stack<T> 식으로도 쓸 수 있다.(general하게)
실제로 member 함수 template에서나 friend 선언할때나 여러 곳에서 쓰이는 듯functions template 다시
사실 function template에서도 type parameter를 제대로 명시해야한다.
예를들어 generic Swap 함수도 Swap(a,b);가 아니라, 제대로 하면Swap<int>(a,b);가 맞지.
함수 호출 방식을 쓰든 어떻든간에 '함수 template'도 원칙대로면 type도 parameter 정보로 받아야한다.
class에서 Stack<int>가 해당 class의 full name이듯, function에서도 Swap<int>(int, int)가 그 함수의 full name이다.(Swap<int>(int,int)랑 Swap<char>(char,char)랑은 구분되는 다른 함수)
하지만 함수에선 argument로 type을 추측할 수 있었기때문에 특정 경우엔 template argument를 명시하지 않는게 허용됐던 것이다.
Class를 explicit instantiate할때와 다른 점은, argumnet도 명시해줘야 한다는 것이다.
함수는 같은 이름이어도 overload되면 다른 함수이니 signature까지 포함해야 full name이다.※ Template 사용처 확장
1. Class Template의 "Member"로 사용
Template 자체가 다른 Template의 member가 되는 것이다.
(template 뿐만 아니라 class/structure의 member가 될 수도 있다.)
별다를건 없고, member에 template이 통째로 와버리면
그 member가 template이란 것만 잘 인지해서 하던대로 활용하면 된다.
template이 통째로 오지않고, (함수 template이든 class template이든) 정의는 밖에서 할 수도 있다.
template<class V>
class ABC {
template<typename t> class hold;
public:
template<typename Y> void blab(V v);
};
template<typename V>
template<typename t>
class beta<V>::hold {
...
};
template<typename V>
template<typename Y>
void blab(V v) {
...
}보는 것처럼 template을 연달아 작성해주고, member 함수에 했듯이 class name으로 구분해준다.
template<typename V> template<typename t> 는 template<typename V, typename T>로 대체될 수 있다.
2. Class Template의 "parameter"로 사용 (Template Template Parameter)
template parameter <>에 template이 오는 것이다.
template<template<typename T> class Thing> class ABC {~};
주목할 부분은 template<typename T> class Thing 이다.
Thing이 변수이름이고 그 앞까진 type이다. 즉 argument가 template이도록 한다.
사용하려는 type(class) 또한 template으로 돼있을때 사용하면 좋을듯
ABC class 내부에선 이 Thing을 활용할 수 있다, Thing<int> s1; 식으로 object 생성 가능
(Thing이 template임을 잊지말고..)
쓸모가 많나? 언제 쓰지 : 답변 rarely needed feature..이라고하네
Template과 friend
일반 Calss에선 friend functions을 쉽게 가지지만, Template Class에선 어떻게 해야될까?
Non-template friend functions일 경우
template <class T>
class HasFriend {
public:
friend void counts();
friend report(HasFriend<T> &); //member아니므로 class scope 아님. 그래서<T>적어야함.
};
void counts() {...};
void report(HasFriend<short> &) {...}; //여기선 HasFriend를 int와 short로만 만든다고 가정
void report(HasFriend<int> &) {...};간단하다. 위처럼 사용할 것 같은 함수의 정의는 따로 정의해주고, 그 함수가 friend라는건 class template내에서 <T>로 일반화해버린다.
상기하자면, class내에서 friend로 선언하는건, 그냥 그 함수는 해당 class의 friend라는 것이다.
실제로 만들어질때 어떻게 될지 고민해보면 어렵지 않음.
아래 사용할 함수들을 그냥 정의해둔거고, 그게 friend라는걸 알려주기위해 template내의 양식을 갖춘것.
Non-const Static Member (in class template) 초기화하기
참고로 class template내의 non-const static member 변수는 아래와 같이 class 밖에서 초기화한다.
template<typename T>
int HasFriend<T>::ct = 0;Bound Template friend functions일 경우
//template prototypes
template <typename T> void counts();
template <typename T> void report(T &);
//template class
template <typename TT>
class HasFriend {
...
public:
...
friend void counts<TT>();
friend void report<HasFriend<TT> >(HasFreind<TT> &);
//friend void report<>(HasFreind<TT> &);
//report의 경우엔 name뒤에 <>안에는 없애도 argument로 유추, counts는 생략하면 안됨.
};
//template functions definitions
template <typename T> void counts() {...}
template <typename T> void report(T & hf) {...}
/*
참고로 counts를 호출할때는 counts<int>(); 식으로 구분해서 호출해야한다.
report는 argument로 구분되지만, counts는 counts<int>();,counts<double>();,... 구분필수
사실 rugment있어서 편하게 하는것도 허용되는거지, 원래 저렇게 구분해서 호출하는게 정석이긴 함.
*/위와 다른점은, 사용할 함수를 하나하나 손으로 만드는게 아니라 template을 이용해 필요할때 만들도록(만들어지도록)한다.
class 내부에 friend 선언문이 좀 독특한데, template을 이용해 만든 함수의 full name이다.
class 내부에서 밖의 함수가 friend임을 알려주려면 당연히 밖 함수와 같은 형식을 사용해서 선언해야한다.
밖의 함수들은 template을 이용해 만들어지는데, template 이용해서 만들어지는 함수들은 당연히 func_name<type_name>의 이름을 가진다. 그러므로 그걸 맞춰주기위해 저렇게 선언한 것이다.
바로 위에선 그냥 일반 함수처럼 class내에서 friend로 선언했는데,
실제로 밖의 함수가 그냥 선언한 일반함수 였기때문이다.
여기서 저렇게 매칭을 안시켜주면 당연히 friend임이 인식이 안됨.Unbound Template friend functions일 경우
unbound라 함은, class template parameter가 friend 함수 template parameter와 다른 것
template <typename T>
class ManyFriend {
...
public:
...
template <typename C, typename D> friend void show2(C & c, D & d);
};
template <typename C, typename D> void show2(C & c, D & d) {
std::cout << c.item << ", " << d.item << std::endl;
}이렇게 정의해두면, 어떤 type을 사용해서 show2를 호출하든 전부 다 ManyFriend Class의 friend가 된다.
왜냐하면, 일단 show2는 멤버 함수가 아니다. 그러니 사실 object를 사용하든 안하든 show2는 아무때나 호출할 수 있다.(이 경우는 item 멤버가 있는 object여야겠지만)
그렇게 show2를 아무 argument 넘겨가며 호출한다면, template으로 구현돼있으니 specialization이 만들어질 것이다.
위에 class내의 friend 선언부도 마찬가지다. show2라는 같은 이름을 호출했으니 위에서도 specializatio이 만들어진다.
(함수 탬플릿은 원래 주로 선언부랑 정의부 구분해서 적었었음. 그래도 각각 따로 만들어졌었다.)
그러니 호출하는 즉시 마찬가지로 friend로도 인정이 되는 것이다.
Template Aliases (C++11)
template design 하다보면 이름이 복잡해질때가 있다.
그때 typedef로 template specializations의 aliases를 만들면 좋다.
ex) typedef std::array<double, 12> arrd', typdef std::array<int, 12> arri;
근데 위처럼 쓰면 본래 type의 특징을 까먹거나,
type 이름과 정보를 혼합해서 사용하기때문에 복잡해질 수 있다.
template<typename T> using arrtype = std::array<T, 12>;그때 이렇게 template과 using =을 이용하면 편리하다.
arrtype<double> gallons;, arrtype<int> days;
위와 비교하면 type name과 정보가 잘 분리돼서 확실히 눈에 잘 들어온다.
non-template에도 using =는 사용 가능, typedef랑 사실상 같은 역할
typedef const char * pc1; == using pc1 = const char *
Summary
private/public inheritance에선 base class의 interface를 내부적으로만 사용할 수 있다.
그래서 이를 interface가 아닌 implementation을 inherit한다고 얘기한다, 왜냐하면 derived object가 base class interface를 사용할 수 없기 때문이다.
따라서 derived class object를 base class object로 볼 수 없기때문에 upcasting은 안된다.(typecasting 하면 됨)
implicit specializtion
: class IC<int> object; 이런 식으로 앞에 class를 붙여도 된다.
(class없는게 딱 type이란게 드러나서 깔끔한데, 위 문법은 어떤 의돈지 모르겠네. 어쨌든 알고는있자.)
Programming Exercise
1번 문제에서
Wine::Wine(const char * l, int y, const int yr[], const int bot[]) : stores(valarray<int>(yr,y), valarray<int>(bot, y)){~}
식으로 작성했는데(여기서 stores는 pair of valarray),
초기활할때 꼭 valarray<int>가 앞에 있어야되나? 싶었다. 어차피 초기화될때는 먼저 pair의 ctor을 사용할 것이고, 그 ctor의 인자로 (yr,y)가 들어갈때 valarray의 ctor이 호출될테니 문제없지않나? 라고 생각했음.
근데 아니다. (yr,y)는 자동으로 변환되지 않고 아마 comma operator를 사용한 것으로 인식됐을 것이다.
내가 생각하는 매커니즘은 argument가 하나일때나 그렇게 작동하지, 2개 이상일땐 아니다.
object parameter에 단일 인자로 넘기겼을때나(아니면 {}쓰던가) 그렇게 implicit 형변환이 일어나는거나 copy ctor 호출되는거지 저런 경우는 당연히 안된다.
