Friends
friendship은 밖에서 정의하는 것이 아니라 해당 class 내부에서만 누구와 friend인지 정의한다. 그렇기때문에 private에 다른놈이 접근할 수 있도록 할지라도 OOP spirit을 위반하진 않는다.
오히려 public interface의 flexibility를 제공한다.
바깥 일반 함수 friend로 만드는건 간단한데, class 관여하면 순서가 좀 헷갈린다.
경우들 하나하나씩 보자.
Friend Classes
class끼리도 friend가 될 수 있다.
friend class Remote;
이렇게 특정 class내에서 선언하면 Remote는 해당 class의 friend가 된다.
위 friend 선언문을 public/private/protected 중 어디에 넣든 상관없다.
Remote class는 friend이니 해당 class의 private/protected에 접근할 수 있다.
어떤 관계일때 사용하냐면, is-a나 has-a로 표현될 수 없을때 사용한다.
Tv와 Remote class가 있다고 해보자. 둘은 is-a도 아니고 has-a도 아니다.
(특정 tv에 특정 리모컨이 묶인다면 has-a 겠지만 그렇지 않는다고 가정)
Remote는 Tv에 접근해 modify해야하므로 이는 Remote class가 Tv class의 friend가 되면 딱이다.
상기하자면, friend로 지정된 class 내부에서 해당 class의 private에 접근할땐
주로 object를 이용한다. 당연한 얘기긴한데, 막무가내로 접근할 순 없다.
보통 argument로 해당 class의 object를 받아서 바로 접근하거나 함.
일반적인 경우는 해당 class의 obejct있어도 private엔 당연히 접근 불가> 주의사항
Remote class 내부에서 Tv를 언급할 것이니(friend로 만들었으면 당연히 접근을 할것인데 언급을 안할리가),
이렇게 friend class 만들땐
1. Tv class를 Remote class보다 먼저 정의하거나
2. forward declaration을 사용해야한다.
참고로 한군데서 friend라고 했다고 서로 friend가 되는건 당연히 아니다.
A에서 B를 friend로 지정하면, B에서 A의 private에 접근할 수 있을 뿐이지 반대는 안된다.Friend Member Functions
특정 class 전체를 friend로 만들기보다 그 class에서 필요한 부분만, 즉 필요한 member functions만 friend로 만들 수 있다.
friend void Remote::set_chan(Tv & t, int c);
이렇게 해당 함수의 header를 full로 작성하고, 앞에 friend를 붙여서 원하는 class내부에 삽입.
당연히Remote::빼먹지 말자. 그거까지해야 구분되는 진짜 이름.
> 문제점
이 경우도 순서가 중요하다. 아래와 같이 한다.
제일 위의 class Tv;가 forward declaration이다.
class Tv; //forward declaration
class Remote{~};
class Tv{ friend void Remote::set_chan(Tv & t, int c); ~ };왜 friend classes에서와 달리 위 순서로 하냐면, 우선 위에서 말했듯이 remote내에선 Tv가 언급되므로 이전에 Tv가 선언돼야한다.
근데 또 문제가 이번엔 Tv내에서 remote의 함수를 friend로 만들어야한다는 것이다.
그래서 Tv내에서 friend로 만들기 전에 Remote와 그 안의 함수 선언부가 먼저 나와줘야한다.
그래서 위처럼 작성한다. 반대로 Remote를 forward declaration하는건 안된다.
왜냐하면 Tv가 Remote 내부 함수 선언부를 못봐서 set_chan을 인식하지 못하기 때문이다.
추가 내용이 있는데, 만약 Remote 내부에서 Tv를 type으로 언급하는 수준 정도가 아니라 Tv class member 함수를 직접 사용한다면,
★최종해결책
class Tv;
class Remote{~ prototype only ~};
class Tv{ friend void Remote::set_chan(Tv & t, int c); ~};
//Remote method definitions이렇게 일단 Remote class에선 prototype만 작성하고, Tv의 함수들을 본 뒤 definitions을 작성.
왜냐하면 위에서와 같은 이유로, remote에서 Tv의 method를 호출할거라면 Tv class 선언부만 볼게 아니라 그 함수도 봐야하니 그렇다.
요약하자면, member 함수를 friend로 만들땐 순서가 중요하다.
friend인 함수에서 friend class의 type만 만지는 수준(애초에 이런 경우는 잘 없을듯)이 아니라면,
가장 아래처럼 구조를 짜면 된다.
class끼리 friend로 만들때 이렇게 복잡하게 할 필요가 없었던 이유는
friend class Remote; 라는 statement 자체가 Remote를 class로 identify하기 때문이다.
>번외: class declaration?
저렇게 `class my_Class;`처럼 이름만 띡 써서 이게 class라는걸 알리는게 declaration이다.
일반적인 변수나 object의 declaration/definition과 class/template의 경우는 좀 다르다.
linkage가 object나 함수에나 적용되는거라 여기선 저 identifier가 class를 나타낸다고 알릴뿐이다.
만약 class/structure 이름도 다른 변수의 identifier처럼 linkage로 묶인다면,
knk에서 했던 incomplete type같은 기술은 안먹힐 것이다.
왜냐하면 다른 file에서도 member에 접근할 수 있을 것이기 때문.
좀 말이 이상할 수도 있긴한데 어쨌든 no linkage이고,
그래서 incomplet type같은게 있었던 것이다.(따로 어떻게 처리해주겠지)
ANSI standard specification:
"The following identifiers have no linkage:
an identifier declared to be anything other than an object or a function;"mutual friend
classes가 서로 friend로 지정한다면,
class Tv{
friend class Remote;
public:
//prototype only
};
class Remote{
friend class Tv;
public:
~ //얘는 definitions 와도 됨
};
//Tv member function definitions서로 friend이니, 서로의 member 함수에 접근한다고 가정하고 보자.
Tv class에선 friend 선언문으로 Remote가 class란 것만 알지, 나머지 자세한 함수 등은 모른다.
그러므로 Tv 내에서 inline으로 Remote의 함수들에 접근하진 못하고, Tv class는 일단 prototype들만 정의해두고 뒤에서 definitions을 정의해야한다.
반대로 Remote는 이미 Tv 함수들을 다 봤으니 그냥 inline으로 Tv 함수들 갖다써도 상관없다.(friend이기도하니)
Shared Friends
특정 함수가 두 class의 private에 접근해야 한다면, 그냥 그 두 class에서 각각 friend로 만들면 된다.
이때도 막 쓰면 안되고 주의할 점이 있다.
ex) void ccc(aaa & a, bbb & b); 라는 함수를 aaa와 bbb class의 friend로 만든다고 해보자.
두 class private에 접근할 것이니 당연히 (대부분) 위처럼 해당 class type의 parameter를 받을 것이다.
class bbb;
class aaa {
friend void ccc(aaa & a, bbb & b);
~
};
class bbb {
friend void ccc(aaa & a, bbb & b);
};그럼 ★이렇게 forward declaration을 써줘야, aaa내에서도 bbb가 type이라는 것을 compiler가 제대로 인지할 수 있다.
Nested Classes
class를 다른 class내에 위치시킬 수 있다. class내에 다른 type을 정의하는 것이다.
내부 class는 또 다른 class scope를 가지므로, 포함하는 class의 member들과 이름 충돌이 발생하지 않는다.
★nested class의 member 함수를 밖에서 정의할때는 ::를 두번 이용하면 된다.
Queue::Node::Node(){~}
>고찰 (+ 책 내용)
주된 사용 목적은 (1)이름 충돌을 피하고 (2)다른 class의 구현을 돕기위함이다.
서로 is-a 관계나 has-a 관계라기보단, class 내에서 특정 type이 필요할때 사용한다.
예를들어 Queue Class 내에서 Node 멤버를 표현하기위해 data와 nextlink를 묶어서 Structure로 만들었다고 해보자.
이는 Structure로 하기보단 Class로 만들어 버리는게 더 낫다. 그래야 데이터 하나하나 초기화하지않고 한번에 ctor 사용할 수도 있고, 여러 class 기능으로 더 안전하고 더 간단하게 사용할 수 있다.
(물론 c++에선 structure도 다 가능하지만, 앞에서 structure는 순수 data만 다루기로 약속함)
막무가내로 그냥 data member들 싹다 class로 묶으란건 아니다. 그런 기준이면 nested 무한임.
잘 보고 type화 할 만 한지, ctor 사용할만한 곳이 있는지 등 파악해서 type이 필요하다면 그렇게 하도록.
> Nested Class의 Scope와 Access
(너무 당연한 얘기같긴한데..)
Nested Class가 private내에 정의돼있다면, 당연히 nested class(type)은 그 class 내부에서만 쓰일 수 있다.
protected에 정의됐다면 derived class에서도 쓰일 수 있고,
public에 정의됐다면 밖에서도 쓰일 수 있다. 단 이때는 scope-resolution operator(::)을 사용해야 한다.
ex) Queue::Node a; 여기서 Node는 Queue의 public에 정의된 class.
(object가 관여해야되는 멤버 함수나 데이터는 object 통해야 하지만 이런 type은 그럴 필요가 없음.)
nested structure나 enumeration에도 마찬가지로 적용된다.
보통 enumeration은 public에 정의해서 client가 사용할 수 있도록 한다.
예를들어 iostream에서 formatting option을 지원하기위해 public에 enumeration 정의.nested class와 그걸 포함하는 class 간에는 access에 있어서 어떤 특권도 없다.
포함한다고 해서 nested class의 private에 접근할 수 있지도 않고, 마찬가지로 포함된다고해서 포함하는 class의 priavte에 접근할 수 없다.
즉, 둘 다 서로의 public member에만 접근할 수 있다.
nested class는 "보통" private에 선언하고, nested class 멤버들은 public으로한다.
그래서 어차피 외부에서 접근은 못하고 내부에선 자유롭게 사용할 수 있다.실제로 code 작성해보니 enclosing class에서 nested class의 private member에 접근하는건 허용이 안되는데,
반대로 nested class에서 enclosing class의 private member에 접근하는건 허용이 됐다.
찾아보니, 링크: nested class도 enclosing class의 member로 보고, 허용이 되도록 바뀐 것 같다.
(책 업뎃이 제대로 안됐나)
Nesting in a Template
위에서 했던 것처럼 Template 내에 Class를 위치시켜도 전혀 문제없다.
포함하던 class가 template class로 된 것일 뿐이지 그 점만 잘 알고 type 명시만 <>까지 붙여가며 잘해주면 문제 없음.
(예제 code는 p.893부터)
Nested Class 생각
class ABC{
public:
int a;
int b;
class DEF{
public:
int sum(void){return a+b;}
};
};위 code에서 잘못된 점을 바로 하나 짚자면, a와 b라고 썼단 것이다.
nested class에서 특별한 접근 권한이 없는건 둘째치고,
저렇게 data member를 함수내에서 unqalified name으로 사용하려면 member 함수여야한다.
다른말로 하자면, data member를 함수내에서 unqalified name으로 사용하려면 *this를 argument로 받아야한다.
static data member라면 굳이 member 함수가 아니어도(== this가 없어도) qualified name으로 사용할 수 있지만,
저런 non-static data member는 특정 object에 종속되므로 *this가 필요하다. 명심하자.
(friend도 그래서 this가 없으니 object를 parameter로 따로 받았다.)
Dependent Names
링크1 (링크들어가서 아래 "Dependent Names"부터 보면 됨)
요약하자면, template을 사용하게 되면 dependent name 이라는 것이 발생한다.
template 내부에 nested class가 있는 경우와 또다른 template이 있는 경우가 해당한다.
두 경우 모두 본인이 속한 template의 type 변수를 사용한다면, 그 변수에 의존성을 갖는다.
말그대로 template argument에 의존하는 name이라는 것이다.(nested class내에서 template argument 활용하면 그 한 경우)
non-dependent name은 look up이 template definition에서 이루어지지만,
dependent name은 look up이 instantiation시에 이루어진다.(template argumnet를 받아야하니)
그래서 compiler는 dependent name이 type인지, non-type인지, template인지 알지 못한다.
그럴때, type이라면 typename, template이라면 template keyword를 사용해 compiler에게 알려주는 것이다.
(더 자세히 말하자면, 특정 template 내의 class를 사용할때는 typename을 붙여줘야하고, 특정 template 내의 template을 사용할때는 template을 붙여줘야한다.(두 경우 모두 내부적으로 본인이 속한 template의 type 변수를 사용하는 경우를 말하는 것, 당연히 그래야 의존성이 생긴다.))
링크
typename, template으로 따로 알려주지 않아도 되는 예외상황이 있는데,
해당 template definition내부에서 쓰이면 현재 instantiation으로 알아서 인식해서 definition때 name lookup이 가능하다.
예를들어 A라는 class template 내에 B라는 nested class가 있고, 그 nested class에서 template argument를 사용한다고하자.
그럼 class template 내부에선 굳이 typename A::B 라고 하지 않고, 그냥 A::B 혹은 B 라고 해도 된단 뜻이다.
그런데 멤버함수 return type 위치에는 이상하게 `typename A<T>::B` 식으로 제대로 명시해야되네.
아마 return type 뒤에 `A<T>::func1`라고 멤버함수임이 나오기때문에
그 이전인 return type에선 B가 무엇인지 제대로 인식이 안돼서 그런 것 같다.
parameter에는 그냥 `B a` 식으로 parameter를 명시해줘도 괜찮다.
(C++20이후론 return type에서 typename은 빼도 됨)링크2: C++20부턴, type이 와야할 자리(ex. return type)엔 typename이라고 표시 안해줘도 된다.
사실 오류/예외를 처리하는 방법은 매우 다양하다. 뭐 내맘대로 code짜면 되니까.
굳이 이런 틀에 의존안하고 내 맘대로 할 수도 있지만, 모든 system에서 일관되게 처리하는게 좋다.runtime때 발생하는 예외상황을 처리하는 방법들을 알아보자.
(오해하면 안되는게, exceptions은 다 내가 처리해야한다. 이런 상황일때 무조건 이런 예외가 뜬다기보단, 내 프로그램에 맞게 내가 알아서 잘 활용해 처리해야한다.)
1. abort()
abort() 함수는 cstdlib header에 있다.
프로그램 종료시키는 함수인데, 이를 이용해 그냥 예외상황일때 종료하도록 하는 것이다.
예를들어 분모로 0이 들어온 경우, 미리 if문으로 캐치해서 종료시키는 것이다.
exit() 함수를 사용할 수도 있다.
2. Returning an Error Code
예외상황일때 해당 문제를 알려주는 error code를 함수가 반환하도록 한다.
반환할 수 없다면, 미리 지정해둔 특정 변수에 저장하도록 한다.
error code보고 판단해 처리할 수 있으니 위 abort 방식보다 더 유연하게 쓰일 수 있다.
math.h에서 이 방법 주로 씀. errno에 저장/return 값도 보고,,
왜 둘 다 하나 싶겠지만, 이렇게 중복되는 일을 하는거면 다른 경우들처럼 역사적인 이유겠지,,
뭐가 먼저 있었는데 나중에 다른게 추가되고 이전꺼를 지우기엔 legacy가 너무 많아져버린..Exceptions
C++에서 말하는 exception이란 "program 실행 중 발생하는 예외 상황에 대한 반응(대책)"이다.
Exception Mechanism은 아래 세 단계로 구성된다.
- exception Throw 하기(
throw statement;)
: throwing은 본질적으로 jump이다. UNIX에서도 C의 setjmp/longjmp로 exception 처리를 구현하기도 한다. - exception handler(
catchblock)로 exception Catching
:catchkeyword 뒤에()안에 type declaration이 온다. 그 type의 exception을 catch하는 것이고 바로 뒤에{}안에는 해당 exception일때 취할 action이 기술된다.
catch문은 label 역할이다. (그렇다고 switch에서처럼 break가 필요하거나 자동으로 뒤로 흘러넘어가거나 그렇진 않음) tryblock 사용
: 특정 exceptions이 발생할만한 code block을try에 작성한다. 뒤엔 하나 이상의catchblock이 온다.
//example
int main(void){
double x, y, z;
try{
z = hmean(x, y);
}
catch(char * s){
}
...
}
double hmean(double a, double b){
if (a == -b)
throw "bad hmean arguments, a=-b not allowed";
return (2.0*a*b)/(a+b);
}exception이 throw되면 return문처럼 해당 함수는 바로 종료되고, "매칭되는 try-catch문"이 존재하는 함수가 나올때까지 calling function으로 거슬러 올라간다.
(이게 return과는 다름. return은 calling function으로 한번만 올라감.)
그리고 매치되는 type을 가지는 catch문으로 들어간다. 이때 throw된 exception이 s(변수)에 assign된다.(catch가 함수 definition처럼도 보이는데 함수는 아니다)
이후 해당 catch문 내부가 실행되고 나머지 catch들은 skip된다.
exception이 발생하지 않으면 catch부분은 그냥 skip된다.
위에서 catch문은 label같다고했는데, 말 그대로 위치 표시 수준 그 이상도 이하도 아니기 때문이다.
{} 내부에 scope도 따로 가지고 따로 도는 함수같은게 아니라 그냥 위치표시정도이니 바깥과 같이 작동> Exceptions으로 Object 사용
보통은 exceptions으로 object를 throw한다.
built-in type은 한정적이지만, class type은 내 맘대로 만들 수 있으니 어떤 exception인지 구분하기도 편리하고, object에 exception 관련 정보를 포함하도록 class를 만들 수 있다.
그 정보를 이용해 catch에서 어떤 action을 취할지도 정할 수 있다.
즉, 특정 exception을 표현할 class(type)를 우리가 정의해서 사용하는 것이다.
(보통은 exception을 표현할 용도만으로 class를 만들어서 씀. 기존 일반 class 써도 되긴함.)
그렇다고 이름만 정의하는 껍데기까진 아니고, 내부 private에 특정 예외 관련 정보들 포함해도되고, ctor이 있어도 된다. (ctor에서 new사용했으면 dtor도 있어야겠지요)
throw AAA(a,b); 식으로 ctor 이용해서 throw하면 편하다.
Exception Specifications
exception specifications 이란 특정 "함수"의 exception throwing 여부와 throw하는 exception 종류를 알 수 있도록 하는 것이다.
ex) double harm() throw(bad_thing); 이렇게 defintion이나 prototype 뒤에 throw(~)가 붙어서 어떤 종류의 exception을 던지는지, 아니면 exception을 던지지 않는지를 알려준다.
double marm(double) throw(); 이러면 이 함수는 exception을 던지지 않는 것
(1)사용자에게 어떤 throw를 던지는지 알려줘서 처리할 수 있도록 하고,
(2)compiler가 이를 runtime에 체크할 수 있는 code를 추가할 수 있도록 한다.
문제는 (1)은 주석으로 간단하게 해결가능하고, (2)도 크게 의미는 없다. 추가 내용/문제점
무엇보다 해당 함수가 야기하는 모든 exception을 작성하려면 내가 해당 프로그램의 모든 코드를 주의 기울여 작성해야한다. 쉽지않다. 특정 part만 update되며 갑자기 exception을 던질 수도 있다.
어쨌든 그래서 전문가분들께서 C++11 이후론 Exception Specifications을 없애버렸다.(무시해도됨)
대신 특정 함수에서 exception이 발생하지 않을때 noexcept keyword를 함수에 명시할 수 있다.
이는 compiler 최적화를 돕는다.
noexcept() operator도 있다. 얘는 operand가 exception을 던질 수 있는지 여부를 report한다.Unwinding the Stack
exception을 throw하는건 return과 비슷하다고 했다.
차이는 return은 stack에서 함수 하나씩 빼오지만, exception throwing은 unwinding the stack이란걸 한다.
"매칭되는 try-catch문"이 존재하는 함수가 나올때까지 stack을 freeing한다.
그리고 "함수호출문 다음 statement로 가는게 아니라" 곧바로 catch block으로 향한다.
그리고 이렇게 빼내오는 과정에 stack에 존재하는 모든 automatic object들의 ★destructor는 모두 호출된다.(당연히 stack제거되니 automatic variable들 전부 freeing은 됨)
catch문에서 `throw;` 라고 하면, 해당 catch가 잡은 exception이 rethrow된다."temporary copy" When throwing an exception
exception을 throwing할때는, catch에서 reference/pointer로 받더라도, 무조건 temporary copy를 만들어서 던진다.
그렇기때문에 간단하게 ctor 이용해서 바로 던져버릴 수 있다.
copy가 만들어지지 않는다면 던질때의 storage duration을 고민해봐야하지만, 그럴 필요가 전혀 없다.
Q. 그런데 catch에서 reference/pointer로 받는 경우는?
A. exception을 표현하는 class들이 상속관계로 구현됐을때, base-class reference/pointer가 derived-class object를 가리킬 수 있다는 것을 사용하기 위함이다.
물론 reference/pointer가 아니라 그냥 일반 Base object로 받아도 derived object 다 받을 수 있다.
하지만 reference/pointer가 효율이 더 좋고, object로 인자를 받아오면 virtual 함수도 의미없어진다.참고로 이렇게 상속관계 exceptions일땐 상속 역순으로 catch로 구현한다.
만약 아래에서 catch 순서를 반대로 구현한다면, 아래 위에서 Base가 모두 예외를 처리하므로 나머지 catch들이 의미없어진다.
try{~}
catch(Derived2 & a){~}
catch(Derived1 & b){~}
catch(Base & c){~} //switch문에서의 `default:` 같은 역할하게 함.> 번외
(만약 모르는 함수를 호출하거나 할때) 어떤 type of exception인지 모른다면,
catch (...) { //statements } 이렇게 ellipsis(...)를 이용해 모든 exceptions을 받도록 할 수 있다.
The exception Class
exceptions이란 것은 class처럼 프로그래밍 방식 자체를 바꾼다.
library에서 어느 정도 규격을 제공하는데 그게 exception header의 exception class이다.
이 exception class는 다른 exception class들의 base class로 활용된다.
exception class엔 const char * what() 이라는 virtual 함수가 있다.
exception에선 implementation dependent인 string을 반환하는데,
virtual이므로 보통 derived class에서 해당 exception 정보 문자열을 return하도록 redefine한다.
(exception class를 상속한 exception이라면...) 특정 exception을 catch한 후, 이 what 함수를 이용해 정보를 프린트 해볼 수 있다.
exceptions들을 마구잡이로 사용자따라 그들만의 방식으로 표현하기보단,
base class라는 틀을 제공함으로써 exceptions 표현하는 class들을 좀 묶이도록? 한다.stdexcept Header file
stdexcept header file엔 많은 Exception Classes들이 있다.
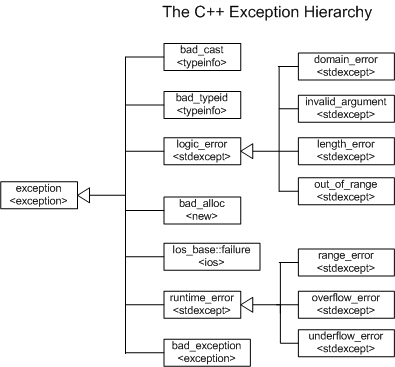
-
logic_errorclass : inheritexceptionpublicly
1-1.domain_errorclass : inheritlogic_errorpublicly
: 함수 정의역 벗어난 경우
1-2.invalid_argumentclass : inheritlogic_errorpublicly
: unexpected value가 함수로 넘어온 경우
1-3.length_errorclass : inheritlogic_errorpublicly
: 특정 action을 취하기에 공간이 모자란 경우
1-4.out_of_boundsclass : inheritlogic_errorpublicly
: index error -
runtime_errorclass : inheritexceptionpublicly
2-1.range_errorclass : inheritruntime_errorpublicly
2-2.overflow_errorclass : inheritruntime_errorpublicly
2-3.underflow_errorclass : inheritruntime_errorpublicly
이부분들 정리해야됨. 구성만 좀 바꾸면 될듯 ㅇㅇ
위의 모든 class들은
`explicit logic_error(const string& what_arg);`
이런 식의 `const string&` 인자만을 갖는 ctor을 가진다.
이렇게 입력받은 string은 `what()` 함수의 반환값으로 사용된다.
(참고로 이 ctor은 `explicit`으로 정의되네, implcit 형변환 불가할듯)
위 모든 class들은 같은 general characteristics를 갖는다. 차이는 class이름인데, 이걸 통해 각각 다른 exception으로 구분하고 다르게 처리할 수 있게 해주는 것이다.
각 exception class 아래에 설명한 상황들은 주로 그럴때 쓰인단 것일 뿐이다.//example. inherit 관계니까 역순으로 처리,, 배운대로,, ㅎㅎ
try { ... }
catch(out_of_bounds & oe) {...}
catch(logic_error & oe) {...}
catch(exception & oe) {...}Q. runtime_error들은 실제 over/underflow 발생시 내부적으로 throw되나?
A. No. 내가 알아서 if문쓰거나 더하기빼기해서 미리 판단해서 예외처리 해야됨.
오해하면 안되는게, exception은 자동으로 발생하는게 아니다.
우리가 if문 등 동원해가며 예외적인 상황을 미리 정의하고 이럴땐 어떻게 행동하도록 정의하는 것이다.
위의 class들은 그런 exceptions을 표현해 종류를 구분하고 정보를 담도록 도와주는 것일뿐이다.
"내부"적으로 exception 자동생성 안 한다는 것이지, library 같은덴 당연히 exception 던질수도 있다.
(library도 사람 손으로 쓴 것이니 당연.. new도 bad_alloc 던지기도 하고 그럼)bad_alloc class와 new
예전의 new는 C에서처럼 할당실패시 null pointer을 반환했지만,
지금의 new는 null pointer를 반환하지 않고, bad_alloc exception을 throw한다.
bad_alloc은 new header에 정의된 class이다.
exception대신 null pointer를 반환하도록 하게 만들고 싶다면,
int * pi = new (std::nothrow) int;
이렇게 (std::nothrow)를 중간에 넣어준다.
위 링크 보니 표준엔 널포인터 반환 안하는게 맞긴한데 하는 경우도 있긴한거같네.
그래도 그냥 표준에 딱 명시된대로 `bad_alloc` exception 처리하도록 중점두는게 맞는듯nested class로 exception 표현
특정 class의 exception을 다루는 class(type)는 그냥 그 class 내부에 정의해버릴 수 있다.
예를들어 input class에서 invalidinp라는 exception을 처리하고 싶다면, invalidinp class를 input class에서 nested class로 정의해 사용하는 것이다.
위처럼 nested class로 예외 class를 만들어뒀을때 상속이 발생하면,
상속된 class에서도 exception을 처리하기위한 class를 만들 것이다.
그럼 그 class는 따로 base class의 exception 다루는 class를 상속받으면 된다.
(p.922 예제 코드있음)
왜 exception 정의하는 class끼리도 상속받나? : 공통 부분이 있을 확률이 높다. 따로 놀 수 있으면 따로 놀게해도 상관 없음.
번외
p.922 code에 보면 dtor에 throw()가 붙는다.(exception specification)
그러면 drived class의 dtor에도 똑같은 exception specification을 명시해야한다.
dtor 뿐만 아니라 상속관계 모든 virtual 함수들의 exception specification에는 base 함수의 exception specification에서 허용하는 exception들만 올 수 있다.
throw()는 exception이 없단 소리이므로 그대로 throw()를 적어줘야함.
링크에 보면 아래와 같이 나옴.
dtor은 상속되는게 아니지않나.. 쨌든 링크보니 dtor도 예외는 아니라고하네.
If a virtual function has an exception-specification,
all declarations, including the definition, of any function
that overrides that virtual function in any derived class shall only allow exceptions
that are allowed by the exception-specification of the base class virtual function
(C++03 §15.4/3).Exception 처리 빗나갔을때
Exception이 throw됐을때 두가지 이유로 빗나갈 수 있다.
1. uncaught exception
: 던져진 exception이 exception specification과는 일치했지만, try block이 없거나 catch와 일치되지 않을때
2. unexpected exception
: 던져진 exception이 exception specification과 매치되지 않을때
> uncaught exception 발생
terminate()->abort()
프로그램은 우선 terminate() 함수를 호출하고, terminate()는 default로 abort()를 호출한다.
abort()말고 다른 함수가 호출되도록 변경할 수 있는데, set_terminate()를 이용하여 terminate가 호출하는 함수를 변경할 수 있다.
typedef void (*terminate_handler)();
terminate_handler set_terminate(terminate_handler f) noexcept; //C++11버전보면 알겠지만, 변경할 함수는 void를 return하고 argument가 없어야 한다.
이 조건만 만족하도록 내 마음대로 함수 만들어서 set_terminate로 설정해두면, uncaught exception이 발생했을때 그 함수가 호출된다.
참고로, terminate()와 set_terminate() 모두 exception header file에 있다.
set_terminate가 여러번 호출되면,
terminate()는 본인 기준 가장 최근 호출된 set_terminate가 세팅한 함수를 호출한다.> unexpected exception 발생
(C++11 이후로 없어졌다곤하지만, 아직 존재하는 code도 있고.. 알고는 있자)
unexpected()->terminate()->abort()
프로그램은 우선 unexpected() 함수를 호출하고, unexpected()는 terminate()를 호출한다. 그리고 그 terminate()는 default로 abort() 호출.
마찬가지로 여기선 set_unexpected()를 이용하여 unexpected()가 호출하는 함수를 변경할 수 있다.(위와 달리 조건이 몇개 있다. 아래 "대체될 함수 조건" 참고)
typedef void (*unexpected_handler)();
unexpected_handler set_unexpected(unexpected_handler f) noexcept; //C++11버전참고로, unexpected()와 set_unexpected() 모두 exception header file에 있다.
얘도 set_terminate() 쓰면되지않나?
: 설계상 용도에따라 둘을 구분하는게 더 좋지. 같이 control해버리면 구분이 안됨.
uncaught 처리하려고 이렇게 만들었는데, 그걸로 unexpected까지 처리되는 꼴이다.
그래서 uncaught는 set_terminate 이용하고, unexpected는 set_unexpected 이용하는 것이다.대체될 함수 조건
우선 uncaught에서와 마찬가지로, 변경할 함수는 void return하고 arugment 없어야한다.
추가로, 해당 함수는 아래 선택지 중 골라야한다.
1. terminate(), abort(), exit() 중 하나를 호출해 프로그램 종료시키거나
2. 다시 exception을 throw해야한다.
(== "명시된 exception아니니까 다시 던지던가 종료시키던가!!")
다시 exception을 throw할 경우 아래 3가지 경우로 나뉜다.
1. 새로 던진 exception이 exception specification과 일치할 경우,
아무 일 없던 것처럼 그 새로운 exception으로 진행한다. catch 문 매칭되는거 찾고..
2. 새로 던진 exception도 exception specification과 일치하지 않고, exception specification에 std::bad_exception type이 없는 경우, terminate() 호출한다.
3. 새로 던진 exception도 exception specification과 일치하지 않고, exception specification에 std::bad_exception type이 있는 경우, 던져진 exception은 std::bad_exception으로 대체된다.
std::bad_exception class는 exception class를 inherit하고, exception header file에 존재
좀 복잡한데 말로 쉽게 하자면,
일단 명시된 exception 목록에 포함되지 않으면 다시 던지던가 종료시켜야한다.
다시 던졌을때 exception specification과 일치하면 그대로 쭉 진행된다.
다시 던졌을때 exception specification(es)과 일치하진 않지만
es에 std::bad_exception이 있다면 `std::bad_exception`으로 대체되는 것이다.
그것마저 없다면 terminate() 호출활용
unexpected를 무조건 catch하고 싶다면 아래와 같이 한다.(details는 p.930부터)
0. #include <exception>
1. void myUnexpected(){ throw std::bad_exception(); } 함수를 set_unexpected로 추가한다.
사실 위 myUnexpected()는 그냥 throw;로 받은걸 rethrow해도 상관없다.
2. std::bad_exception을 호출할 함수의 exception specification에 추가하고, catch문에서도 이를 다루도록 한다.
Exception Cautions
편리하긴하지만, program size 늘리고 speed 느리게한다.
template과도 잘 작동하지않고, 동적할당 있으면 문제도 좀 있다.
그런 단점이 있음에도 불구하고, exception 체킹안해서 발생하는 cost가 더 클 것이다.
void test1(int n) {
string mesg("AAAAAAAA");
...
if (oh_no)
throw exception(); //exception class ctor 사용한거네
...
return;얘는 괜찮다. 왜냐하면 앞서 말했듯이 throw시에 알아서 dtor 잘 호출되니까.
void test2(int n) {
double * ar = new double[10];
...
if (oh_no)
throw exception(); //exception class ctor 사용한거네
...
delete [] ar;
return;얘는 문제다. dtor은 제대로 호출되지만 이 경우 throw하면 바로 종료돼서 delete [] ar;은 호출되지 않으므로 메모리 누수 생긴다.
> 해결책1
같은 함수내에서 catch해서 다시 throw한다. 이때 메모리 해제해준다.
void test3(int n) {
double * ar = new double[10];
...
try{
if (oh_no)
throw exception();
}
catch(exception & ex) {
delete [] ar;
throw;
}
...
delete [] ar;
return;그냥 test2의 if문 내에서 delete 하면되지않나?
: No. 동적할당 받은걸 throw하는 경우를 생각해보면 됨. 우린 copy를 throw하므로 동적할당 받은 것도 throw하고나선 지워줘야된다. 하지만 test2의 if문에서 delete 하는 방식으론 이런 경우를 처리하지 못한다.
위처럼 exception 발생했을때 뒷부분에 skip되면 안되는 code들 처리하고 다시 throw하도록 exception 처리를 두번 해주자.
> 해결책2
smart pointer templates 사용
Runtime Type Identification(RTTI)
runtime에 object의 type을 판단하기위한 standard way를 제공하기위해 만들어졌다.
(몇몇 compiler에선 RTTI를 on/off 할 수 있는 option이 따로 있다.)
debugging 목적이나 upcasting시에 type에 맞는 함수호출 목적 등으로 쓰인다.
(virtual로 해결된다면 그렇게 해야한다. RTTI는 필요한 곳에만 딱 써야한다.)
virtual method가 있어야 RTTI가 지원된다.
이유는 책에도 그렇고 검색해보니 꽤 되는듯, C structure와의 호환성도 문제고, 애초에 vtbl에 RTTI정보를 담기도하고..링크
아래 세가지가 RTTI를 지원한다.
1) dynamic_cast operator
2) typeid operator
3) type_info structure
1. dynamic_cast Operator
Superb * pm = dynamic_cast<Super *>(pg);
pg가 Super * 으로 안전하게 변환될 수 있는지 여부를 판단한다.
안전하게 변환될 수 있는 경우는 "같은 type"이거나 "inherit 구조상 조상에 있는 type"인 경우뿐이다.
(derived여도 특정 경우엔 되긴함.. inherit하고 추가한 멤버가 없을때.. 근데 그런 경우가 있나)
안전하게 변환될 수 있다면 해당 object의 address를 반환하고,
그럴 수 없다면 null pointer을 반환한다.
(cast이긴한데 upcasting이니까 강제 형변환 안하고 그냥 안전하면 upcasting하라고 주소반환해주네)
왜 변환가능 여부를 보나? RTTI는 type을 판단한다고 안했나?
: 굳이 type을 자세히 볼 필요가 없는 경우도 많기 때문이다.
이 pointer assign해도 제대로 virtual 함수 호출이 되는지만 보면 되는 경우가 많다.pointer말고 reference에서도 적용 가능하다.
근데 reference는 null pointer를 가질 수 없으니, 이 경우 안전하지 않다고 판단하면 bad_cast exception을 throw한다.
(bad_cast는 typeinfo header file에 있고, exception class를 inherit한다.)
근데 이런건 우리가 알아서 코드보고 판단해서 써야하지않나?
이게 안전할지 아닐지는 class 상속 구조보고서 우리가 판단해야되지 않나?
: 사용자 입력을 받아야하거나 랜덤으로 object가 넘어오는 경우 잘 모를 수도 있다.
실제로 여기서도 random으로 object 무작위로 받아와서 안전한지 판단하고 pointer에 assign함.2. typeid Operator & type_info Class
type_info class는 typeinfo header file에 있다.
그리고 이 class는 ==와 != operator를 overload 해뒀다.
이 class의 멤버함수인 name() 함수는 보통 class의 name을 반환한다.(implementation dependent이긴함)
typeid Operator는 다음이 operand로 올 수 있다.
1) class의 name
2) object가 결과로 나오는 expression
그리고 이 operator는 type_info의 reference를 반환★한다.
그래서 활용하려면, 일단 #include <typeinfo>해주고,
특정 object 두놈 비교하려면 typeid(A_obj) == typeid(B_obj); 식으로 하면 된다.(둘은 type_info 반환하는데 그 class에서 == overload했음)
아니면 object가 어떤 class인지 출력하고 싶다면, cout << typeid(A_obj).name(); 이렇게 typeid가 type_info를 반환한다는걸 잘 써먹으면 된다.
> RTTI 오용
C++ community에서 RTTI에 많은 비판이 있다. 이에 대한 토론은 나중에 더 공부하고 하시고,,
p.942 code보면, RTTI가 필요할때 dynamic_cast 쓰는게 typeid 쓰는 것 보다 훨씬 간결하다.
typeid는 하나하나 어떤 type인지 판단해야하지만, dynamic_cast를 사용하면 안전성만 판단하고 바로 assign 해버릴 수 있기 때문이다.
즉, typeid가 쓰인 곳엔 virtual functions이나 dynamic_cast가 쓰일 수 있는지 꼭 확인하고,
그렇다면 virtual function을 사용하도록하거나 dynamic_cast로 대체해서 코드를 더 간결하게 만들어야 한다.
Type Cast Operators
C의 type casting은 비야네 형님이 보시기에 너무 느슨했다고 한다.
정말 말도안되는 의미없는 type 변환도 강제로 casting 해버리면 OK였다.(어떤 casting이든 OK)
비야네 형님은 그래서 4가지의 규율잡힌 type cast opeator를 만들었다.
1. dynamic_cast
2. const_cast
3. static_cast
4. reinterpret_cast
4개 다 xxxxx_cast < type-name > (expression) 형식을 갖는다.
각 목적에 맞게 골라서 casting을 하면 된다. 목적을 알고 직접 명시하는 것이므로 실수할 확률도 줄고, 명확하게 사용할 수 있다.
(그래서 어떤걸 써도 같은 결과가 나오는 겹치는 상황도 있는데, 그럴때도 같은 결과라고 아무거나 쓰지말고 목적에 맞게 골라서 쓰는게 좋다.)
> const_cast
const와 volatile 유무만 변경해주는 연산자이다.
그러므로 <type-name>과 (expression)의 type은 cv의 존재유무를 제외하곤 같아야 한다.
그리고 pointer이거나 reference여야한다. 즉, "값 자체의 constantness는 바꿀 수 없다"는 소리다.
constant이지만 가끔 값을 바꿀 필요가 있을때 주로 사용한다.
pointer에서 const를 떼어내는 것은 UB이다. 떼어내지긴 하겠지만, 만약 그 값 자체가 const라면 변경할 수 없을 것이다.
const int a = 3;
const int * pt = &a;
int * pc = const_cast<int *>(pt);
*pc += 1; //Invalid기타: 돌아다니다가 본건데 한번 가져와봄. 첫번째 경우는 값 자체를 const로 지정하지 않았으므로(답변 비유에 의하면 칠판에 적힌 값이므로) 변경이 되지만 2,3번 경우는 안되는 것
> static_cast
<type-name>이 (expression)과 같은 type으로 implicit하게 변경될 수 있거나
반대로 (expression)의 type이 <type-name>으로 implicit하게 변경될 수 있는 경우에만 VALID
반대 방향으로 implicit conversion가능해도 되니까, downcasting도 가능하단 뜻
말고 다양한 numeric conversion; float to long 같은 것도 당연히 되고,
enumeration value도 integral type으로 implicit하게 변경될 수 있으니 얘도 가능하다.
얘는 굳이 pointer/reference가 아니어도 가능(링크:제일 위 답변)
> reinterpret_cast
내재적으로 위험한 type cating 지원한다.
가끔 implement-dependent나 안전하지않은 것을 해야할때도 있는데 그럴때 사용한다.
보통 low-level/implement-dependent인 상황에서 주로 사용하므로 portability는 없을 수도있다.그렇다고 얘도 C typecast처럼 다 허용하진 않고,
1)pointer를 주소표현을 담기엔 작은 integer type이나 floating type으로 변환하는 것
2)함수포인터-data포인터 간의 변환
을 막는다. 추가로 const 관련 casting도 안된다.
(pointer type을 주소표현 다 담을 수 있는 큰 integer type으로 변환하는건 괜찮다. 작은데로 가는게 안되는거임)
//reinterpret_cast 사용 예제
struct dat {short a; short b;}
long value = 0xA22B118;
dat * pd = reinterpret_cast< dat *> (&value);
cout << hex << pd->a; //값의 처음 2bytes만 출력> C++ 일반 type cast
C와 달리 C++은 일반 type cast도 제한적이다.
위에서 설명했던 cast 연산자들이 할 수 있는것은 다 할 수 있고 + 위 연산자들의 combination도 가능
(위 cast 연산자들을 동시에 쓰는 것처럼도 할 수 있단 소리)
말고는 안된다.
char ch = char (&d);
그래서 이게 C에선 허용도지만 C++에선 안된다. 보통 char에 주소표현 담기는 너무 작으니까.
