출처로는 위키에서 많이 가져옴.
확률의 공식 꼭 외우기!
Introduce
- 통계학(Statistics)
- 산술적 방법을 기초로 하여, 주로 다량의 데이터를 관찰하고 정리 및 분석하는 방법을 연구하는 수학의 한 분야이다. 근대 과학으로서의 통계학은 19세기 중반 벨기에의 케틀레가 톡일의 "국상학(國狀學, Staatenkunde, 넓은 의미의 국가학)"과 영국의 "정치산술(Political Arithmetic, 정치 사회에 대한 수량적 연구 방법)"을 자연과학의 "확률이론"과 결합하여, 수립한 학문에서 발전되었다. (출처 - 위키)

-
기술통계학(Descriptive statistics)
- 데이터를 수집하고 수집된 데이터를 쉽게 이해하고 설명할 수 있도록 정리 요약 설명하는 방법론
-
추론 통계학(Inferential statistics)
- 모집단으로 부터 추출한 표본 데이터를 분석하여 모집단의 여러가지 특성을 추측하는 방법론

1990년대부터 시작하게된 데이터 마이닝
2000년대부터 시작하게된 빅데이터
2020년대인 최근부터 AI가 크게 발달하게 됨.
데이터의 이해
데이터와 그래프
-
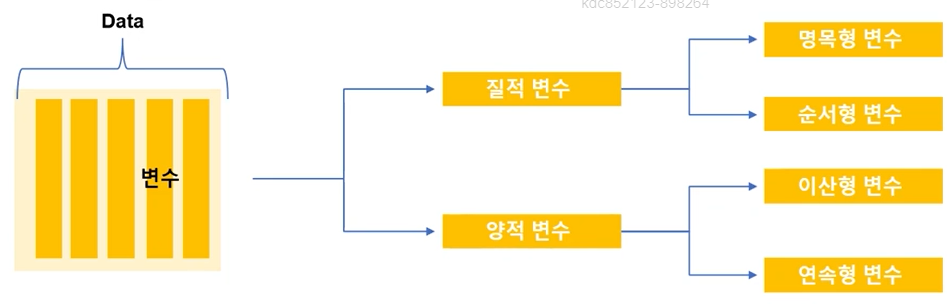
변수(Variable)
- 수학에서의 변수란, 어떤 정해지지 않은 임의의 값을 표현하기 위해 사용된 '기호'이다. 보통 쉽게 설명하기 위해서 '변하는 숫자'라는 표현을 자주 쓰고는 한다.
- 통계학에서는 조사 목적에 따라 관측된 자료값을 변수라고 함, 해당 변수에 대하여 관측된 값들이 바로 자료(Data)가 됨.
-
질적 자료
- 관측된 데이터가 성별, 주소지(시군구), 업종 등과 같이 몇 개의 범주로 구분하여 표현할 수 있는 데이터를 의미함
- 데이터 입력시 1은 남자, 2는 여자로 표현 가능하나 여기서 숫자의 의미는 없음(순서형 변수 : 교육수준, 건강상태)
-
양적 자료
- 관측된 데이터가 숫자의 형태로 숫자의 크기가 의미를 갖고 있음.
- 숫자를 표현할 때는 이산형 데이터와 연속형 데이터로 구분할 수 있음.
데이터를 분석하는 과정 중에 가장 많이 사용하는 분석방법을 Exploratory Data Analysis 라고함.
EDA는 데이터를 탐색하는 분석 방법으로 도표, 그래프, 요약 통계등을 사용하여 데이터를 체계적으로 분석하는 하나의 방법임. (EDA : 분석 초기에 가장많이 사용하게되는 방법)
- 목적
- 데이터 분석 프로젝트 초기에 가설을 수립하기 위해 사용
- 데이터 분석 프로젝트 초기에, 적절한 모델 및 기법의 선정
- 변수 간 트렌드, 패턴, 관계 등을 찾고 통계적 추론을 기반으로 가정을 평가
- 분석 데이터에 적절한가 평가, 추가 수집, 이상치 발견 등에 활용
- 데이터 시각화(data visualization)
- 데이터 분석 결과를 쉽게 이해할 수 있도록 시각적으로 표현하고 전달되는 과정을 말한다.
- 데이터 시각화의 목적은 도표(graph)라는 수단을 통해 정보를 명확하고 효과적으로 전달하는 것이다.
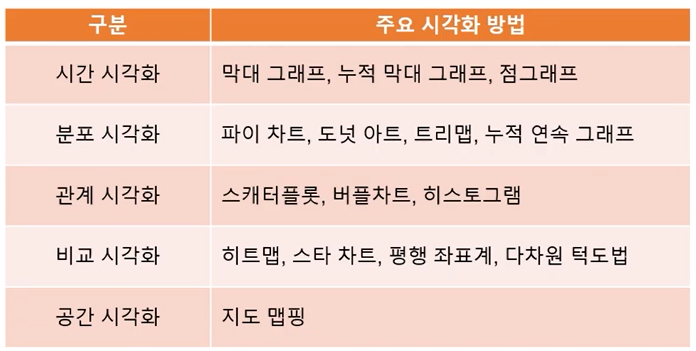
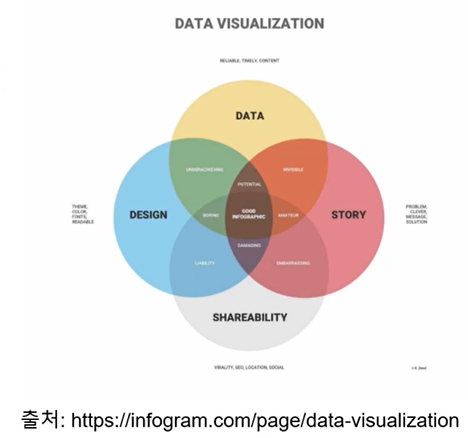
데이터의 그래프화 예시들
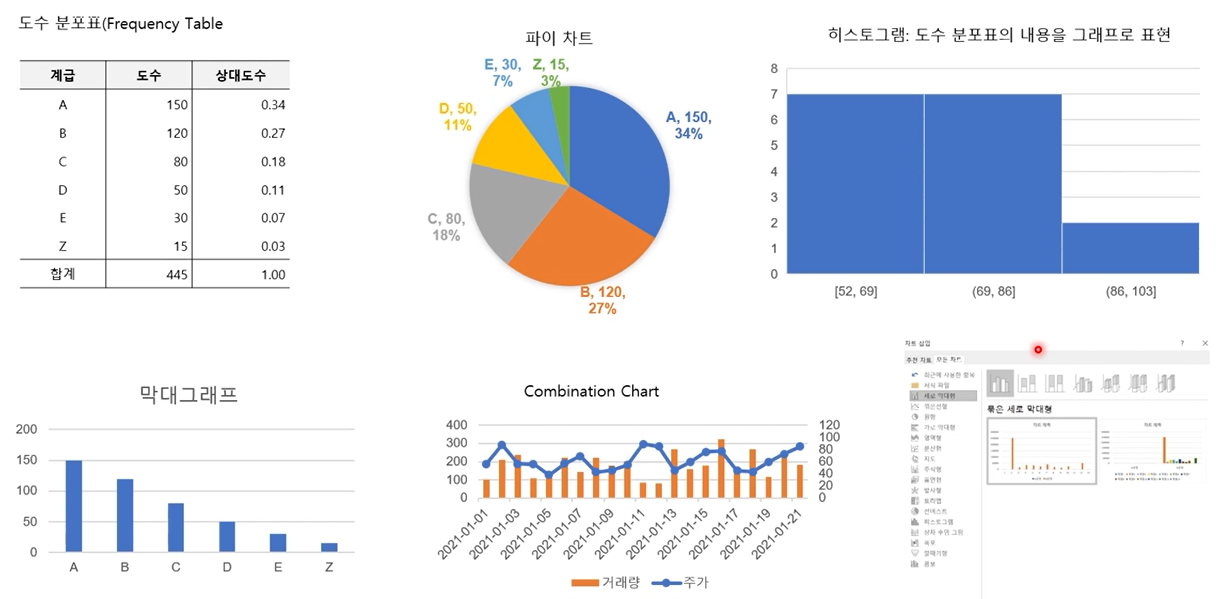
시각화 툴을 사용한 예시들
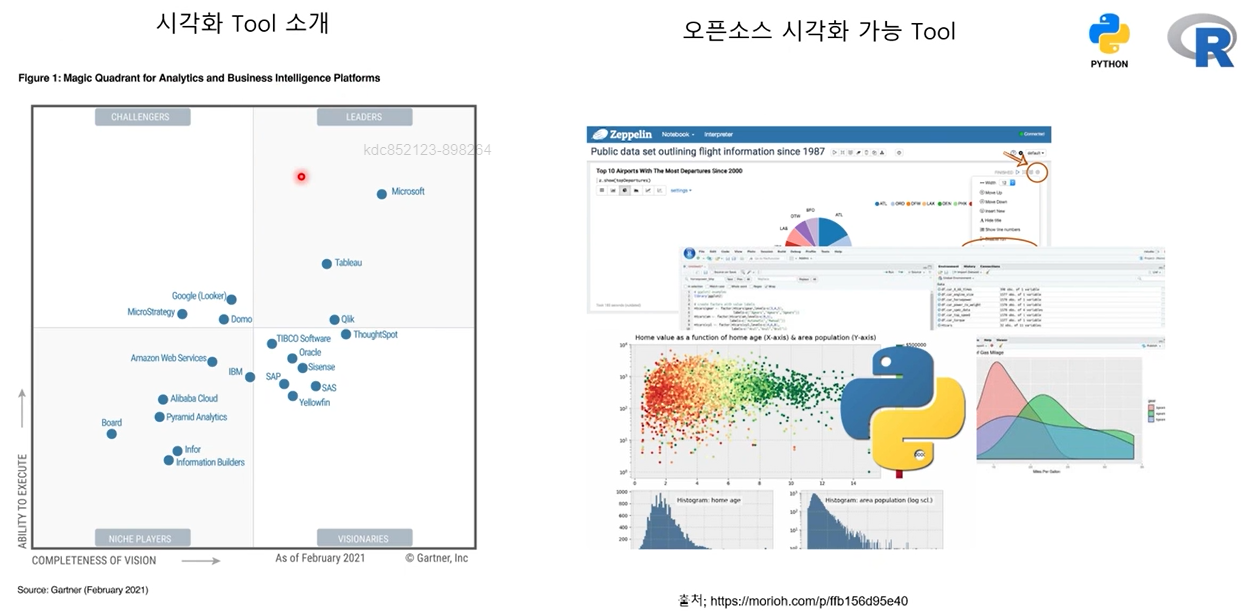 (Gartner로 검색하면 예시들이 많이 나옴)
(Gartner로 검색하면 예시들이 많이 나옴)
데이터의 기초 통계량
-
기초 통계량
- 통계량(statistic)은 표본으로 산출한 값으로, 기술통계량이라고도 표현함.
- 통계량을 통해 데이터(표본)가 갖는 특성을 이해 할 수 있음.
-
중심 경향치
- 표본(데이터)를 이해하기 위해서는 표본의 중심에 대해서 관심을 갖기 때문에 표본의 중슴을 설명하는 값을 대표값이라 하며 이를 중심 경향치라고 함.
- 대표적인 중심 경향치는 평균이며, 중앙값, 최빈값, 절사 평균 등이 있음.
-
평균은 모집단으로 부터 관측된 n개의 x가 주어 졌을때 아래와 같이 정의됨.
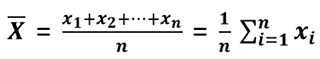
-
평균은 표본으로 추출된 표본 평균이라고 하며, 모집단의 평균을 모평균이라고 한다.
-
표본 평균

-
모평균의 표기법
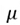
-
-
중앙값(median)
- 평균과 같이 자주 사용하는 값으로 표본으로 부터 관측치를 크기순으로 나열 했을 때, 가운데 위치하는 값을 의미함.
- 관측치가 홀수 일 경우 중앙에 취하는 값이고, 짝수 일 경우 가운데 두개의 값을 산술 평균한 값임.
- 이상치가 포함된 데이터에 대해서 사용함.

-
최빈값(mode)
- 관측치 중에서 가장 많이 관측되는 값
- 옷사이즈와 같이 명목형 데이터의 경우 사용

-
산포도
- 데이터가 어떻게 흩어져 있는지를 확인하기 위해서는 중심경향치와 함께 산포에 대한 측도를 같이 고려해야 함.
- 데이터의 산포도를 나타내는 측도로는 범위, 사분위수, 분산, 표준편차, 변동 계수 등이 있음.
-
범위(Range)
- 데이터의 최대값과 최소값의 차이를 의미함.
-
사분위수(quartile)
- 전체 데이터를 오름차순으로 정렬하여 4등분을 하였을 때, 첫 번째를 제1사분위수(Q1), 두 번째를 제2사분위수(Q2), 세 번째를 제3사분위수(Q3)이라고 함.
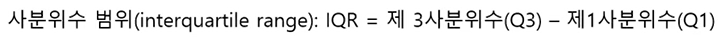
- 전체 데이터를 오름차순으로 정렬하여 4등분을 하였을 때, 첫 번째를 제1사분위수(Q1), 두 번째를 제2사분위수(Q2), 세 번째를 제3사분위수(Q3)이라고 함.
-
백분위수(percentile)
- 전체 데이터를 오름차순으로 정렬하여 주어진 비율에 의해 등분한 값을 말하며, 제p백분위수는 p%에 위치한 자료 값을 말함
- 데이터를 오름차수로 배열하고 자료가 n개가 있을 때, 제(100*p)백분위수는 아래와 같음.
1) np가 정수이면, np번째와 (np + 1)번째 자료의 평균
2) np가 정수가 아니면, np보다 큰 최소의 정수를 m이라고 할 때 m번째 자료
-
분산(variance)
- 데이터의 분포가 얼마나 흩어져 있는지를 알 수 있는 측도 임
- 데이터의 각각의 값들의 편차 제곱합으로 계산하며 수식은 아래와 같음.
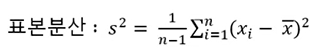
-
표준 편차(standard deviation)
- 분산의 제곱근으로 정의하며 수식은 아래와 같음

- 분산의 제곱근으로 정의하며 수식은 아래와 같음
-
분산
- 크기가 n인 모집단의 편귱을 u라고 할 때 모평균과 모분산은 다음과 같음.
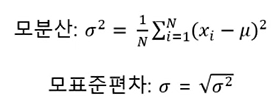
- 크기가 n인 모집단의 편귱을 u라고 할 때 모평균과 모분산은 다음과 같음.
-
변동계수(Coefficient of Variation : CV)
- 평균이 다른 두개 이상의 그룹의 표준편차를 비교할 때 사용함.
- 변동계수는 표준편차를 평균으로 나누어서 산출하여 단위나 조건에 상관 없이 서로 다른 그룹의 산포를 비교하며 실제 분석에서 자주 사용함.
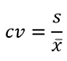
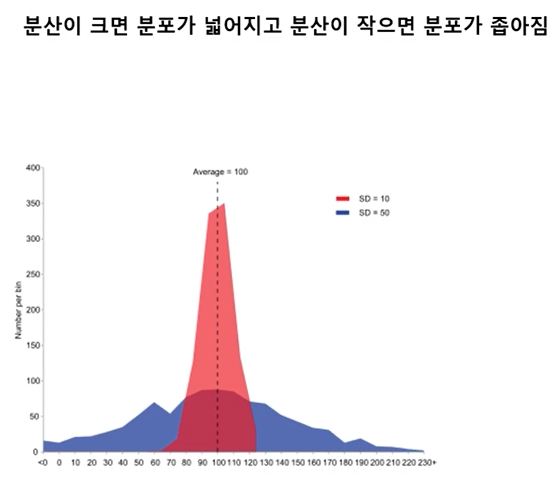
-
분포의 모양을 결정할 때 왜도와 첨도가 있다.
-
왜도(skew) : 자료의 분포가 얼마나 비대칭적인지 표현하는 지표임
왜도가 0이면 좌우가 대칭이고, 0에서 클수록 우측꼬리가 길고 0에서 작을수록 좌측 꼬리가 김.
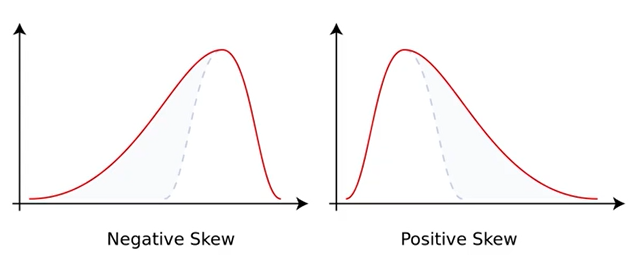
-
첨도(kurtosis) : 확률분포의 꼬리가 두꺼운 정도를 나타내는 척도임
첨도값(K)이 3에 가까우면 산포도가 정규분포에 가까움
3보다 작을 경우에는(K<3) 산포는 정규분포보다 꼬리가 얇은 분포로 생각할 수 있다, 첨도값이 3보다 큰 양수이면(K>3) 정규분포보다 꼬리가 두꺼운 분포로 판단.
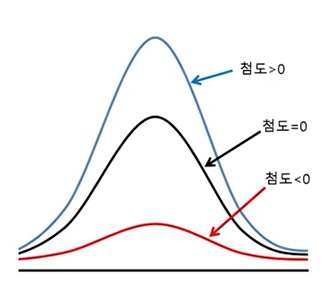
-
-
엑셀을 이용해서 구하는 평균, 분산, 표준편차
- 평균 : AVERAGE(시작:끝)
- 분산 : VAR(시작:끝)
- 표준편차 : sqrt(분산)
- 변동계수(CV) : 표준편차 / 평균으로 구할 수 있다.
확률이론
확률
-
확률(probability)
- 모든 경우의 수에 대한 특정 사건이 발생하는 비율이다. 대체로 수학 외에서는, 0과 1사이의 소수 혹은 분수나 순열 등으로 나타내시 보다는, 다른 비율을 나타낼 때처럼 0과 1사이의 확률에 100을 곱하여 0과 100사이의 백분율(%)로 나타내거나 옛날처럼 할.푼.리로 나타내기도 한다. (출처:위키)
-
확률의 고전적 정의
- 어떤 사건의 발생확률은 그것이 일어날 수 있는 경우의 수 대 가능한 모든 경우의 수의 비이다. 단, 이는 어떠한 사건도 다른 사건들보다 더 많이 일어날 수 있다고 기대할 근거가 없을 때, 그러니까 모든 사건이 동일하게 일어날 수 있다고 할 때에 성립한다. (확률의 최초의 정의는 수학자 라플라스의 논문 Theorie analytique des probabliltes)
-
표본 공간(Sample Space)
- 표본 공간이란 어떤 실험에서 나올 수 있는 모든 가능한 결과들의 집합
- 동전 던지기의 경우 S = {앞면, 뒷면}, 주사위 던지기 S = {1,2,3,4,5,6}
-
사건 A가 일어날 확률을 P(A)라고 하고, 표본 공간(S)가 유한집합일때 표본 공간의 모든 원소들이 일어날 확률이 같으면

-
통계적 확률 정의

-
확률의 성질
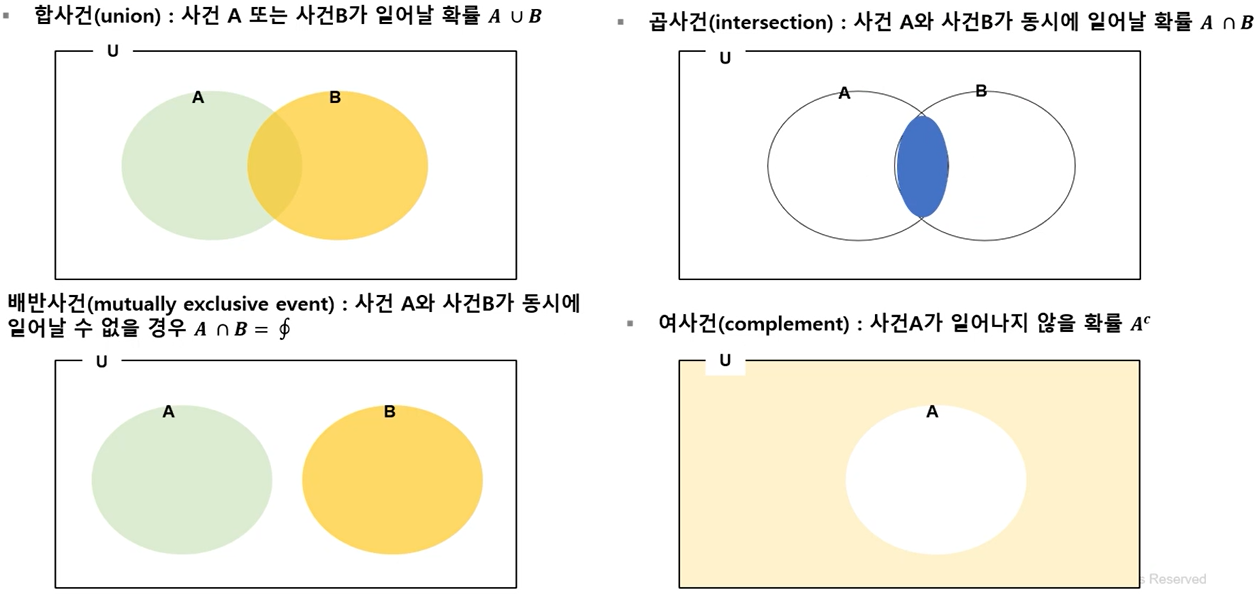 1) 확률의 덧셈법칙 : P(A∪B) = P(A) + P(B) - P(A∩B)
1) 확률의 덧셈법칙 : P(A∪B) = P(A) + P(B) - P(A∩B)
2) A와 B가 배반 사건이면, P(A∩B) = P(∮) = 0
3) A의 여사건이 A^c이면, P(A) + P(A^c) = 1
확률 - 조합과 순열
-
! (Factorial) : n개를 일렬로 늘여 놓은 경우의 수를 n!로 표현하며, 공식은 아래와 같다.
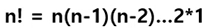
-
순열(Permutation) : 순서를 고려하여 n개 중 r개를 뽑아서 배열하는 경우의 수
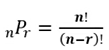
-
조합(Combination) : 순서를 고려하지 않고 n개중 r개를 뽑아서 배열하는 경우의 수
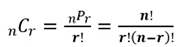
확률 - 조건부 확률
-
조건부 확률(conditional probability) : 어떤 사건 A가 발생한 상황에서(주어졌을 때) 또 하나의 사건 B가 발생할 확률임
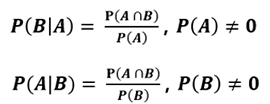
-
확률의 곱셈법칙

-
베이즈 정리(Bayes' Theorem)
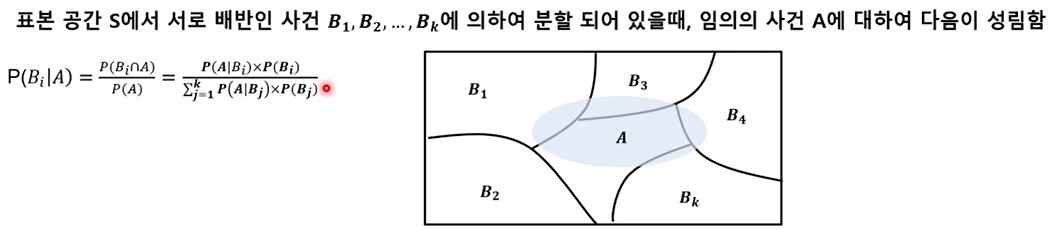
확률 변수
-
확률 변수(random variable) : 표본공간에서 각 사건에 실수를 대응시키는 함수를 확률 변수라고 함
-
확률변수의 값은 하나의 사건에 대하여 하나의 값을 가지며, 실험의 결과에 으하여 변함.
-
일반적으로 확률변수는 대문자로 표현하며, 확률변수의 특정값을 소문자로 표현함.

-
확률 변수의 평균 : 기대값 이라고 표현하기도 하며, 수식은 아래와 같음
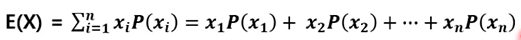
-
주사위를 던졌을때의 기대값은
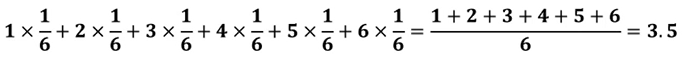
-
확률 변수의 분산
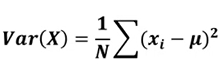
-
기대값의 성질

-
분산의 성질

- 공분산
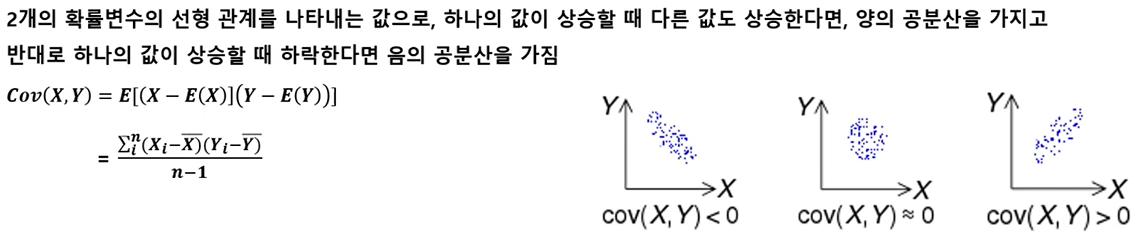
확률 분포
이산형 확률 분포
-
확률 분포(probability distribution) : 확률 변수 X가 취할 수 있는 모든 값과 그 값을 나타낼 확률을 표현한 함수
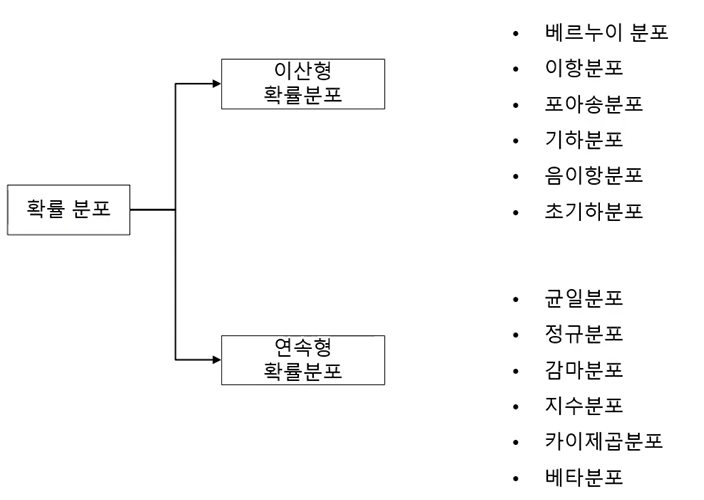 확률 분포는 크게 이산형과 연속형으로 나뉘어진다.
확률 분포는 크게 이산형과 연속형으로 나뉘어진다.-
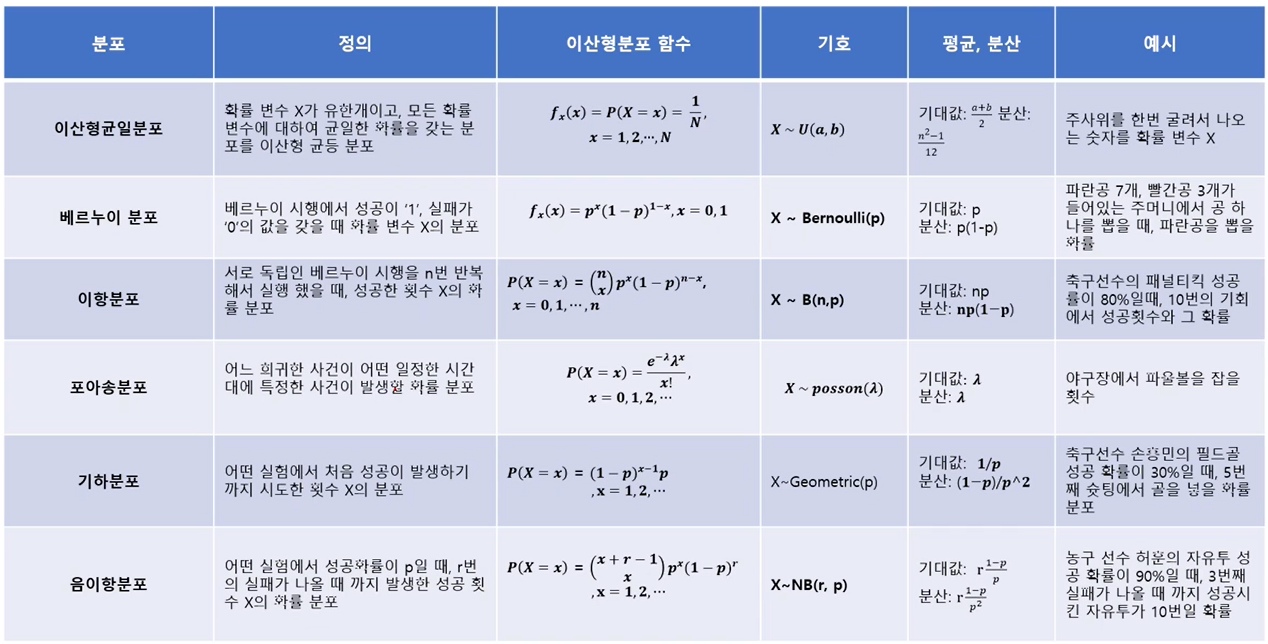
이산형 균등 분포(discrete uniform distribution) : 확률 변수 X가 유한개이고, 모든 확률 변수에 대하여 균일한 확률을 갖는 분포를 이산형 균등 분포라고 함.
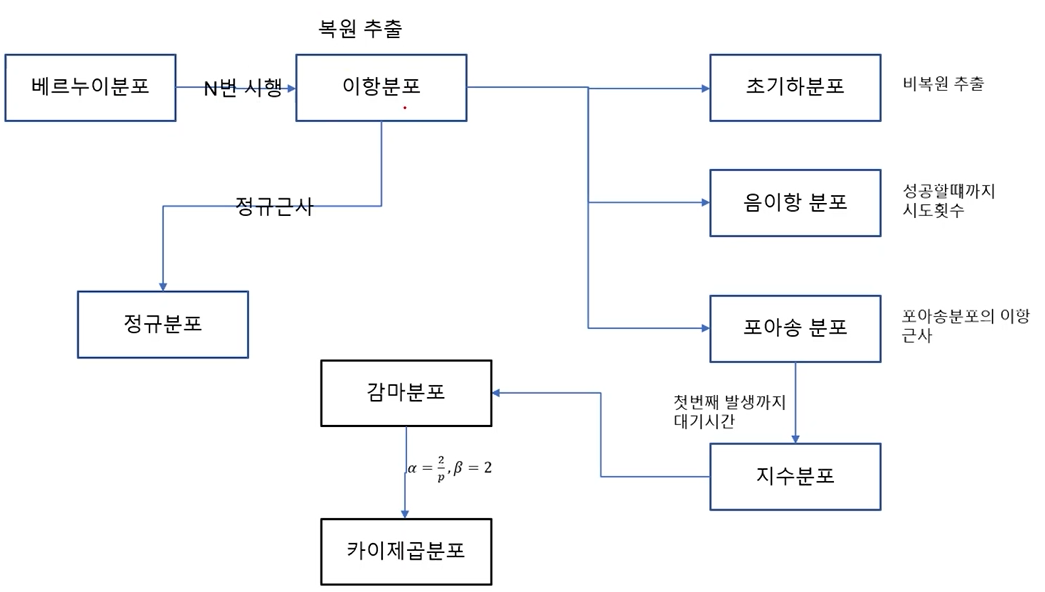
![] 각 분포들관의 관계를 필수로 알아둬야함.
각 분포들관의 관계를 필수로 알아둬야함. -
베르누이 시행(Bernoulli trial) : 각 시행의 결과가 성공, 실패 두가지 결과만 존재하는 시행을 베르누이 시행이라고 함.
- 베르누이 시행에서 성공이 '1', 실패가 '0'의 값을 갖을 때 확률 변수 X의 분포를 베르누이 분포(Bernoulli distribution)라고 하며 다음과 같이 정의함.

-
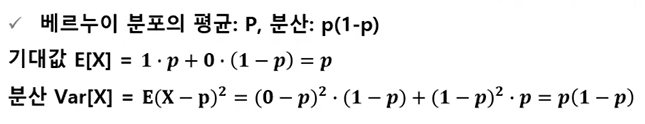
-
이항분포(Binomoal distribution) : 연속적인 베르누이 시행을 거쳐 나타나는 확률 분포임
- 서로 독립인 베르누이 시행을 n번 반복해서 실행했을 때, 성공한 횟수 X의 확률 분포

분산
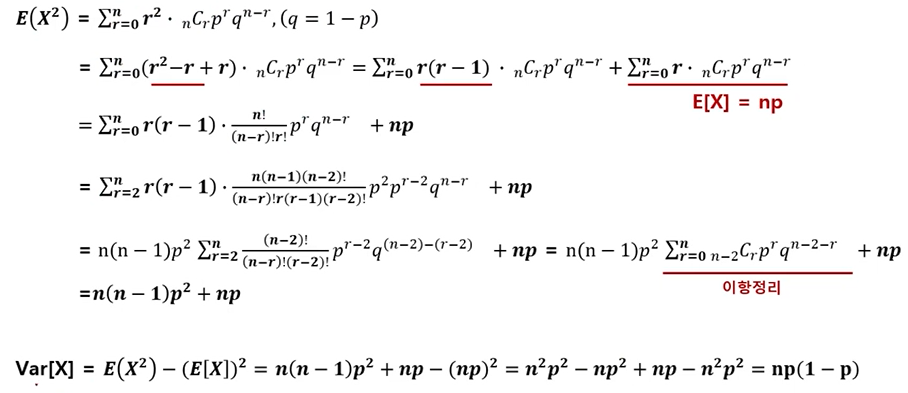 (분산)
(분산)
- 포아성 분포(poisson distribution) : 어느 희귀한 사건이 어떤 일정한 시간대에 특정한 사겅이 발생할 확률 분포 임.

-
이항 분포의 포아송 근사
- 확률 변수 X가 X ~ B(n,p)이고, n이 충분히 크고, p가 아주 작을 때, X의 분포는 평균이 λ=np인 포아송 분포로 근사 시킬 수 있음
보통 n이 클때, np<5를 만족하게 p가 작으면 근사 정도가 좋다고 함 X ~ Poisson(np)
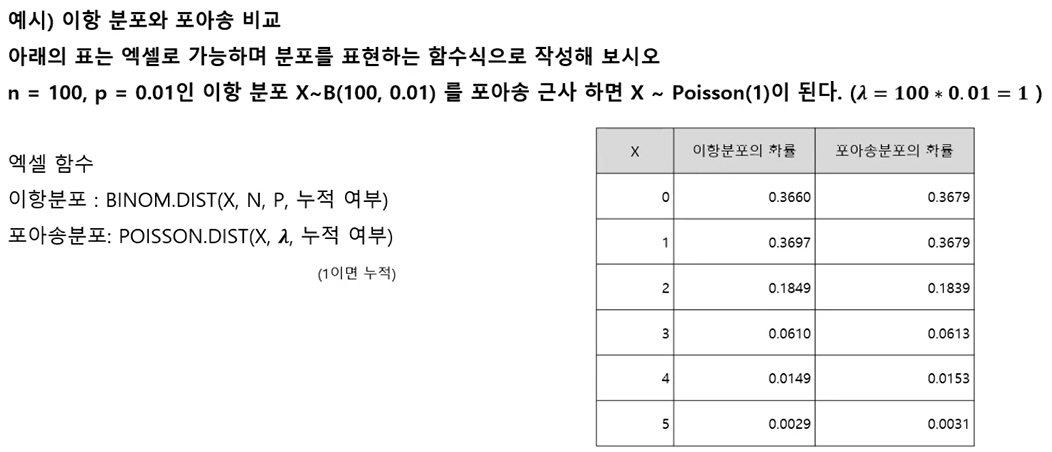
- 확률 변수 X가 X ~ B(n,p)이고, n이 충분히 크고, p가 아주 작을 때, X의 분포는 평균이 λ=np인 포아송 분포로 근사 시킬 수 있음
-
기하분포(geometric distribution) : 어떤 실험에서 처음 성공이 발생하기 까지 시도한 횟수 X의 분포, 이때 각 시도는 베르누이 시행을 따름

-
음이향분포(negative binomial distribution) : 어떤 실험에서 성공확률이 p일 때, r번의 실패가 나올 때 까지 발생한 성공 횟수 X의 확률 분포

연속형 확률 분포
- 확률 밀도 함수(probability density function) : 연속형 확률 변수 X에 대하여 함수 f(x)가 아래의 조건을 만족하면 확률밀고함수라고 함.
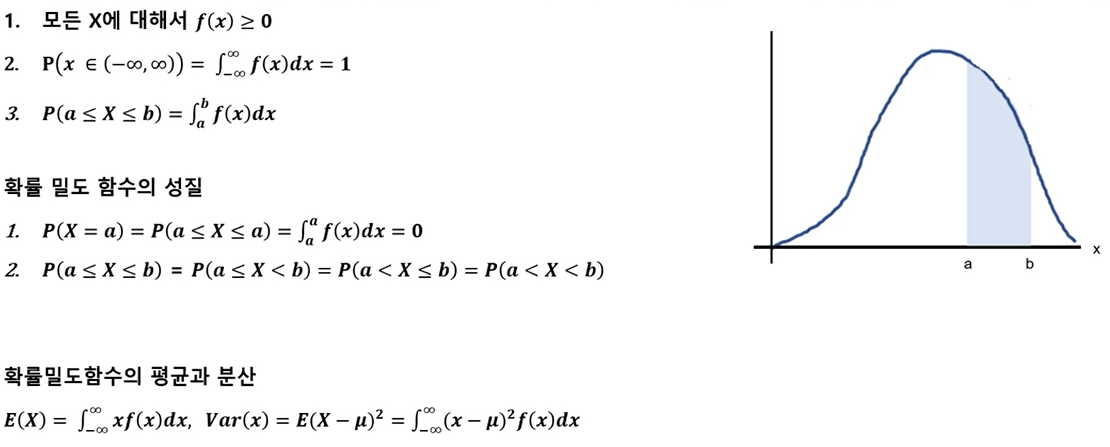
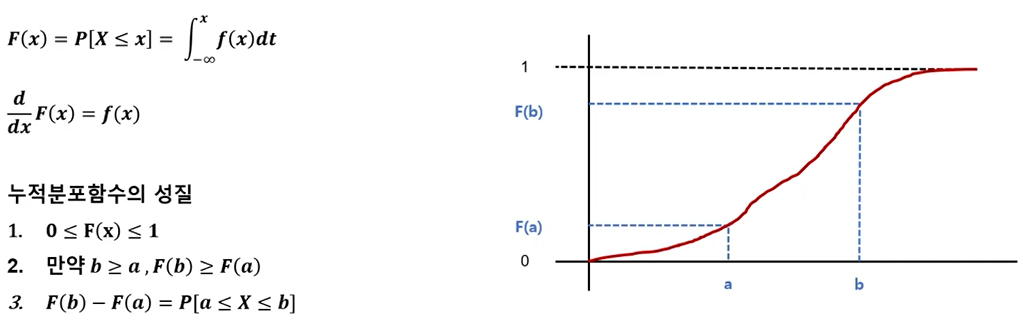
- 누적분포함수(cumulative density function) : 확률밀도함수를 적분하면 누적분포함수가 됨.
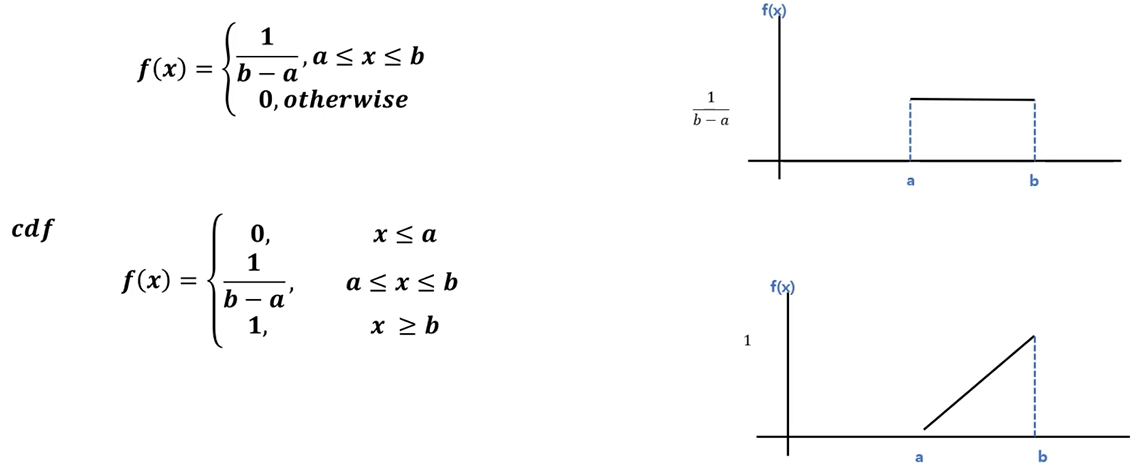
- 균일분포(uniform distribution) : 확률 변수 X가 a와 b사이에서 아래와 같은 확률 밀도 함수(pdf)와 같음
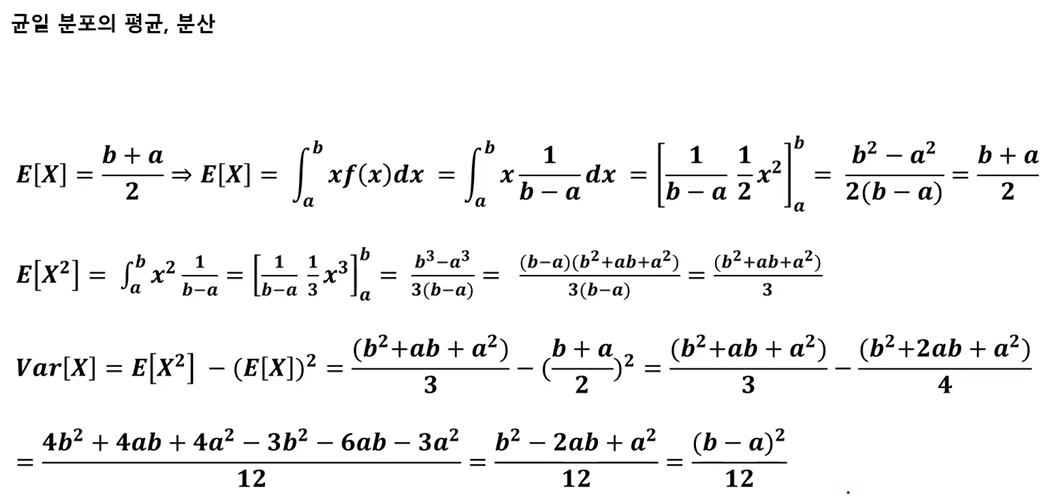
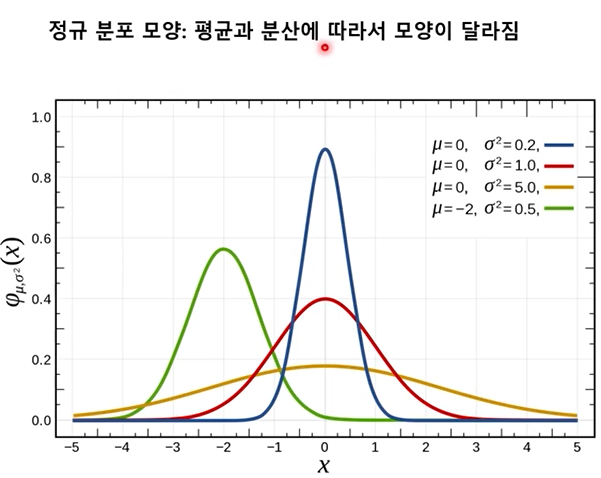
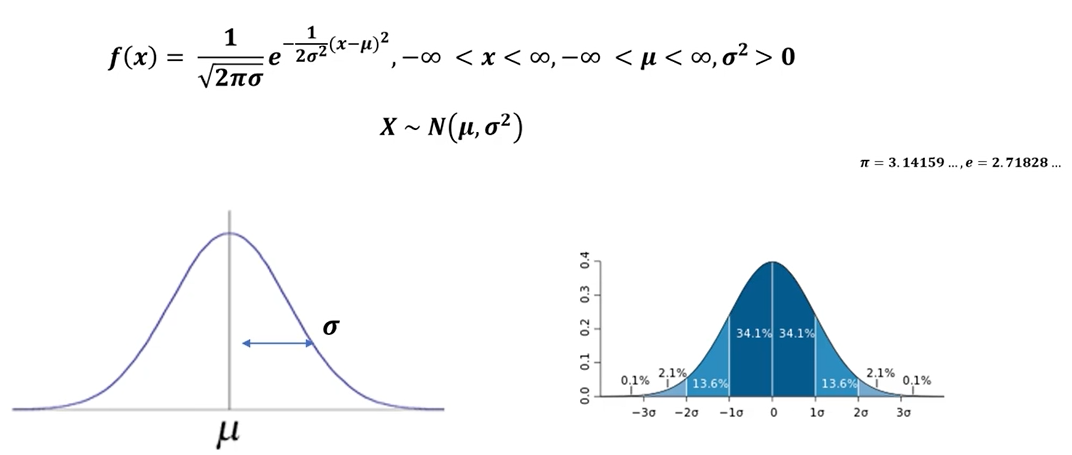
- 정규분포(normal distribution) : 19세기 최대 수학자라고 불리는 독일의 가우스에 의해 제시된 것으로 가우스 분포라고도 함.
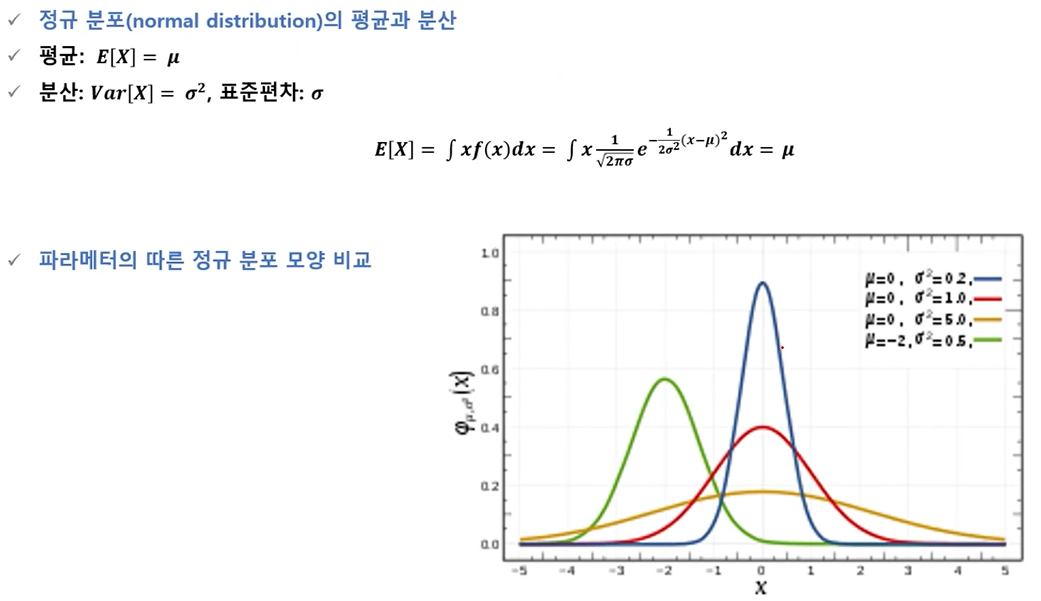
확률 밀도는 활률 변수 X가 평균이 μ이고, 분산이 ∂²인 정규분포를 따를 때 아래와 같음. (가장 중요한 분포)
- 표준정규 분포(standard normal distribution)
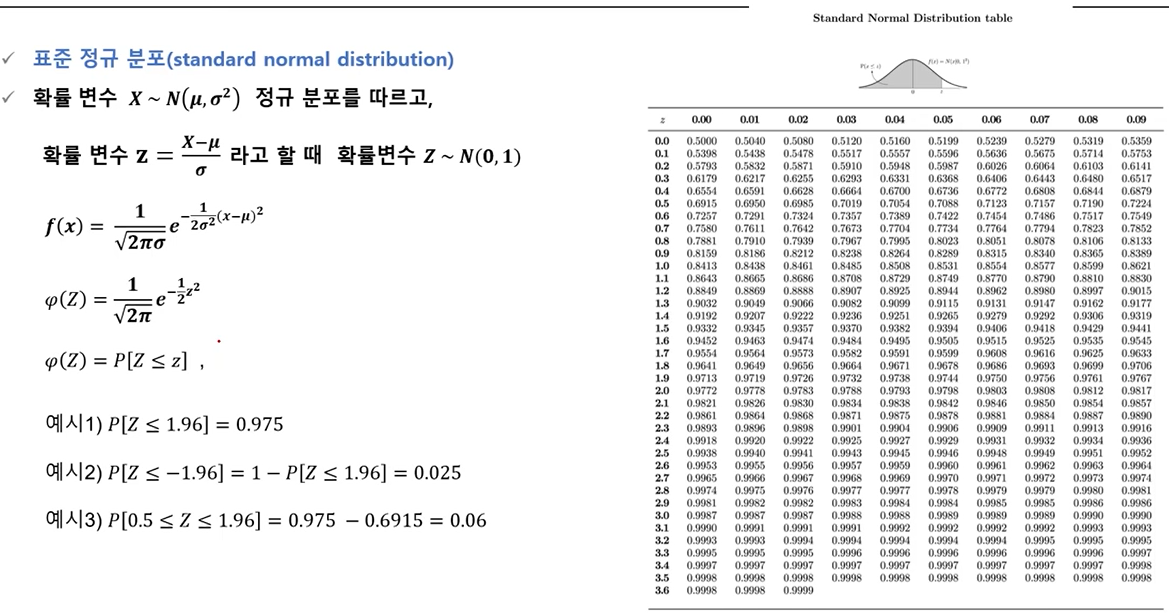
- 정규분포의 성질

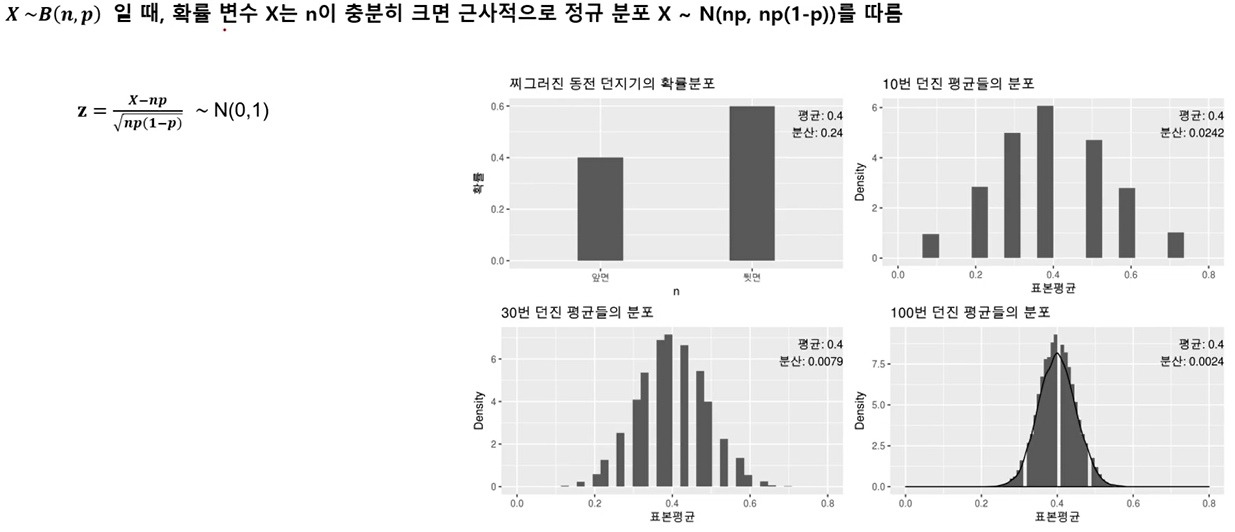
- 이항분포의 정규근사
- 지수분포(expom=nential distribution) : 단위 시간당 발생할 확률 λ인 어떤 사건의 횟수가 포아송 분포를 따른다면, 어떤 사건이 처음 발생 할때까지 걸린 시간 확률 변수 X는 지수 분포임.
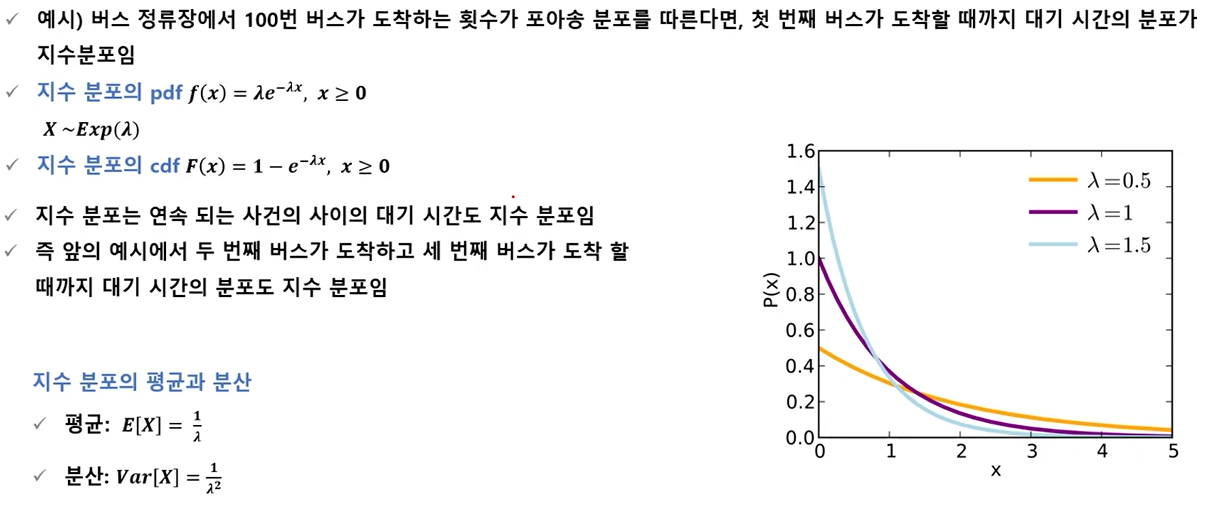
- 지수분포의 예시

- 지수분포의 무기억성(Memoryless Property)
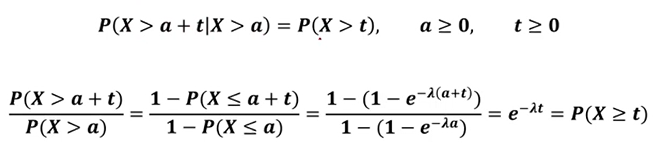
어떤 시점 부터 소요되는 시간은 과거 시간에 영향을 받지 않음

- 지수분포와 포아송 분포의 관계
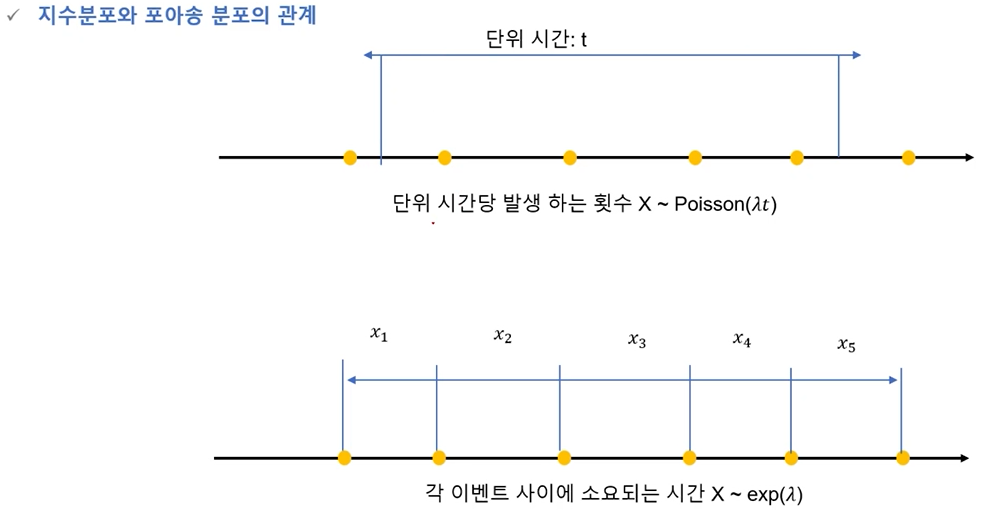
- 확률 분포의 관계도
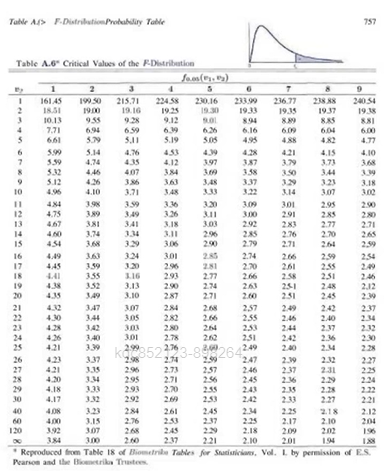
모집단과 표본분포
모집단과 포본
-
모집단(Population), 표본(Sample)
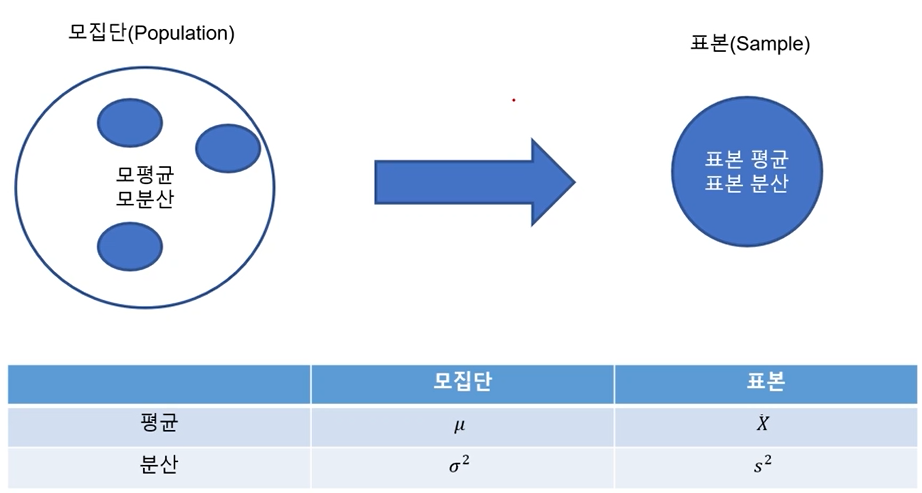
모집단
평균 : μ : 유
분산 : σ² : 시그마 제곱표본
평균 : X : 엑스
분산 : s² : 에스제곱
-
표본추출(Sampling) : 모집단으로 부터 표본을 추출하는 것을 Sampling이라고 하며, 표본으로부터 그 특성을 찾아내고 모집단의 특성을 추론하고자 함.
모집단에서 표본을 추출하는 방법에는 여러가지가 있음. -
복원추출(Sampling with replacement) : 모집단에서 데이터를 추출할 때 하나를 추출하고 다시 넣고 추출하는 방법으로 동일한 표본이 투툴 될 수 있음.
-
비복원추출(Sampling without replacement) : 모집단에서 데이터를 추출 할 때 하나를 추출하고 다시 넣지 않고 추출하는 방법
-
Random Sampling : 모집단에서 데이터를 추출할 때 주의할 점은 편향되지 않아야 함, 각 개체가 모두 동일한 확률로 추출하는 방법(한쪽으로 치우쳐지지 않아야한다.)
-
불균형데이터(Imbalanced Data)의 문제
- 데이터가 불균형 데이터 일 경우 문제가 생김
- 우리가 예측모형을 만드는 목적은 관심이 있는 대상이 발생할 확률을 예측하는 경우가 대부분임, 그런데 예측 대상이 전체 대비 아주 낮다면? 모형의 성능이 괜찮을가?(ex : 신용 평가 모형 개발, 제조 불량 예측 등)
1) Sampling 기법을 통하여 해결
2) 모델을 통한 성능 개선(ex : Cost-sensitive learning)
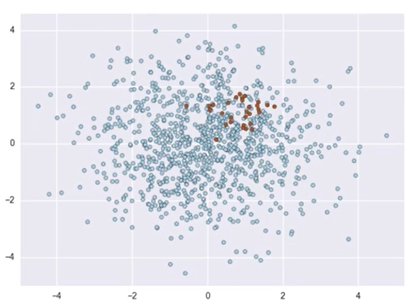
Sampling 기법
- 관심의 대상이 아주 비율이 낮은 경우
- Over Sampling
- 타겟 데이터 적은 class의 수를 많은 class의 비율만큼 증가 시킴(일정 비율로 복원추출 하는 개념)
- 과도적합의 문제 발생할 수 있음
- Under Sampling
- 타겟 데이터의 많은 class의 수를 적은 class의 비율만큼 감소 시킴
- 임의로 뽑은 데이터가 biased(편향)될 수 있고, 모형의 성능이 떨어질 수 있음.
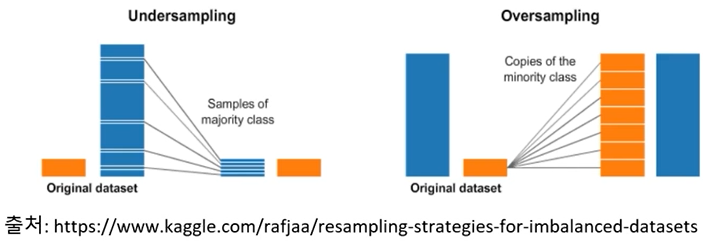
- Over Sampling
표본 분포
- 통계량(Statistic) : 분포에 기초하여 계산되는 수치 함수를 통계량이라고 함.
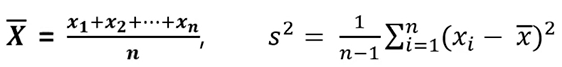
-
표본분포(Sampling distribution) : 통계량들이 이루는 분포를 표본분포라고 함.
-
표본 평균(Sampling mean)
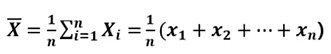
-
표본평균 X바의 기대값?
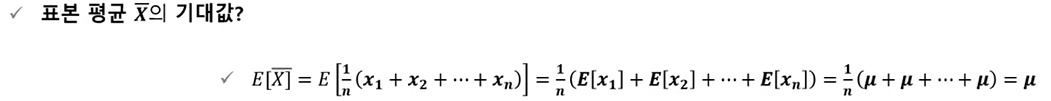
-
표본평균 X바의 분산?
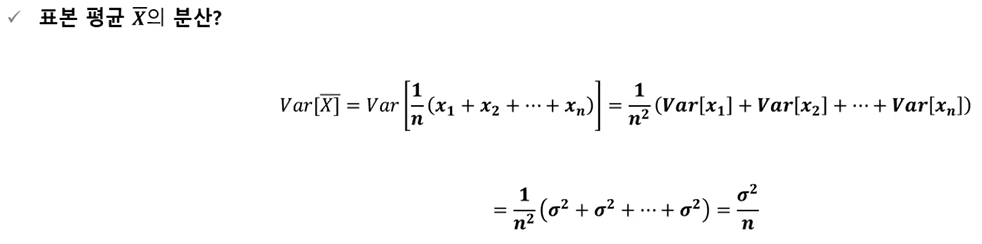
-
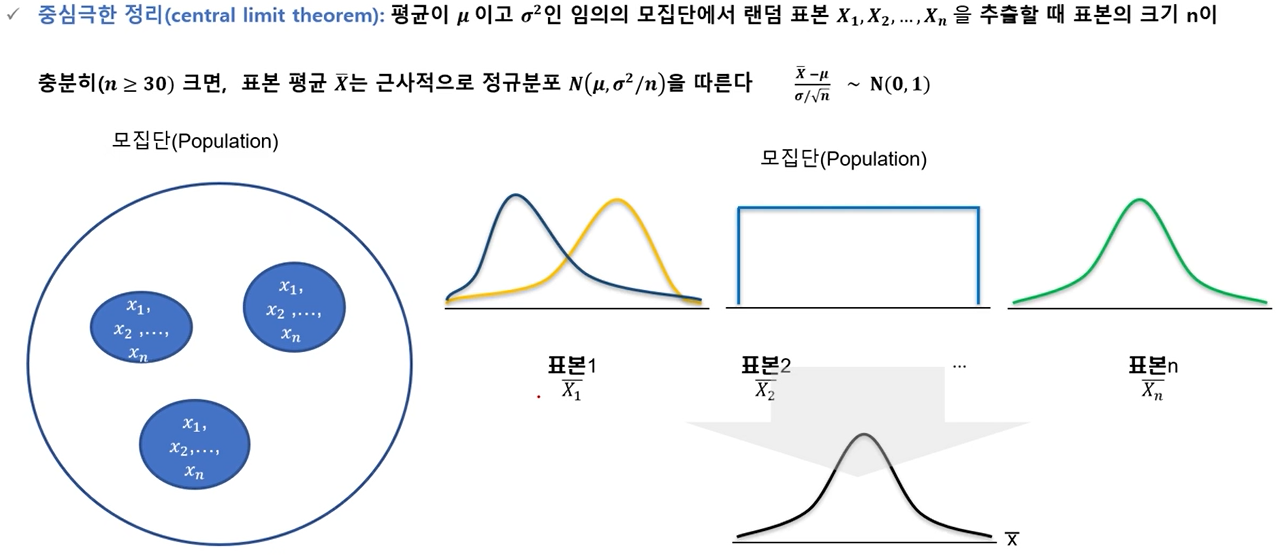
중심극한 정리(central limit theorem)
- 예시

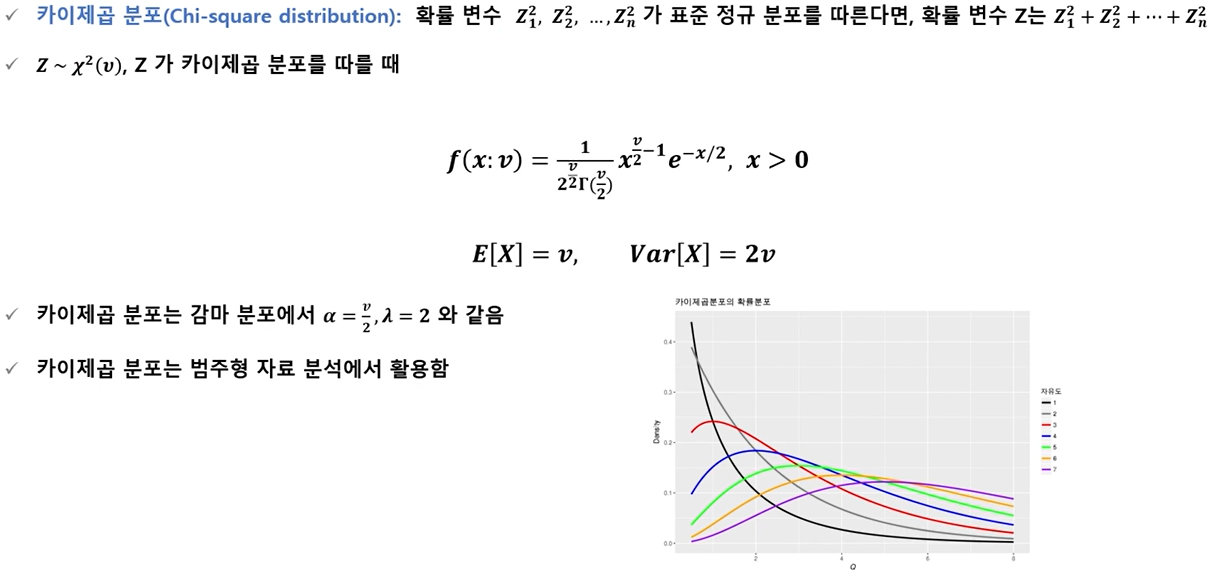
- 카이제곱 분포(Chi-square distribution)
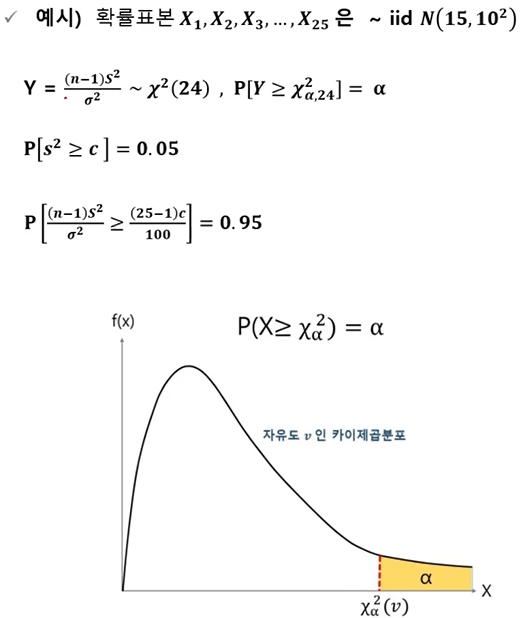
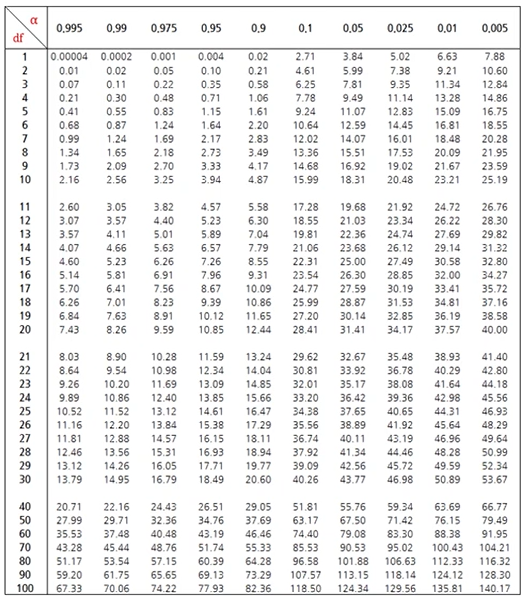
- 자유도(degree of freedom) : 표본수-제약조건의 수 또는 표본수-추정해야 하는 모수의 수를 의미하며 일반적으로 n-1을 사용함
예시적으로 표본의 크기가 5이고, 표본 평균이 3로 정해졌다면, 숫자 4개는 자유롭게 정할 수 있으나 마지막 하나의 숫자는 나머지 네개의 숫자에 의해 결정. 1,2,3,4를 골랐다면 마지막 숫자는 자동으로 5가 되야 평균이 5로 정해져있음
카이제곱 분포는 자유도 v의 크기에 따라 모양이 달라짐 자유도가 커질수록 분포가 좌우 대칭 형태로 됨.
카이제곱 분포는 자유도가 커지면서 표준정규 분포에 근사하며, v ≥ 30이면, 확률을 근사적으로 정규분포로 구할 수 있음.
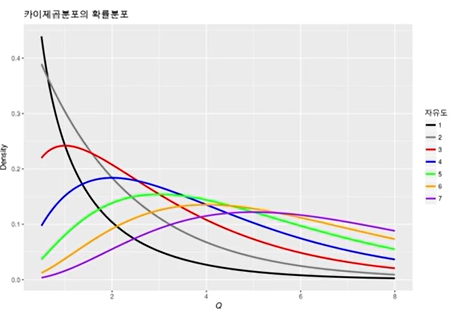
- T분포(t-distribution)
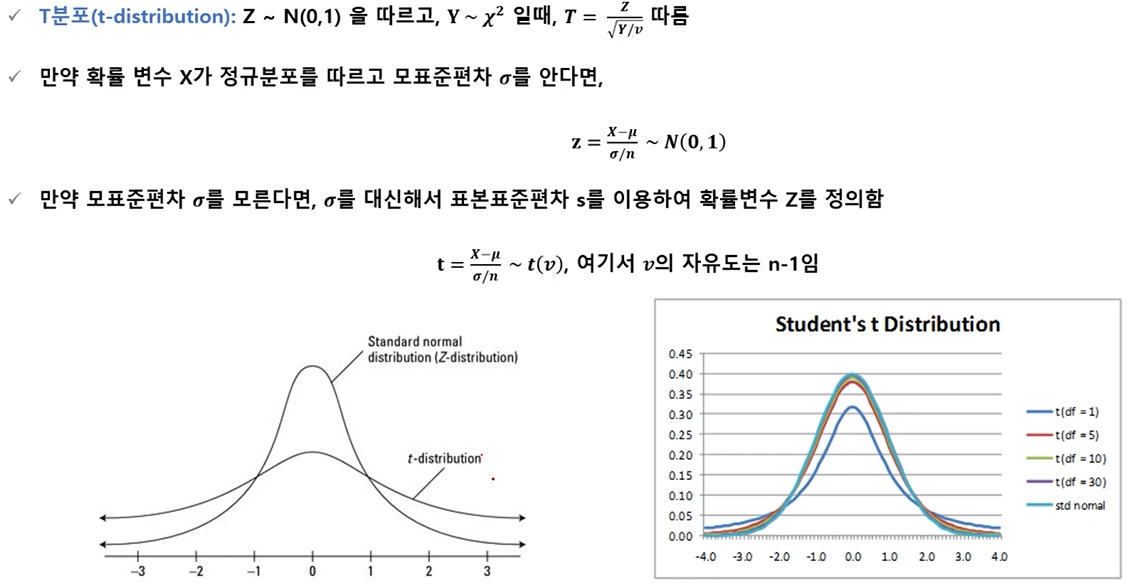

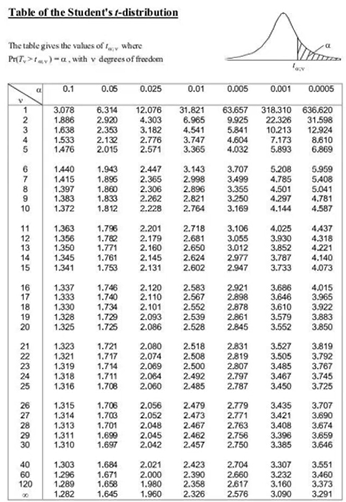
- F분포(F distribution)

- F분포 그래프 예시
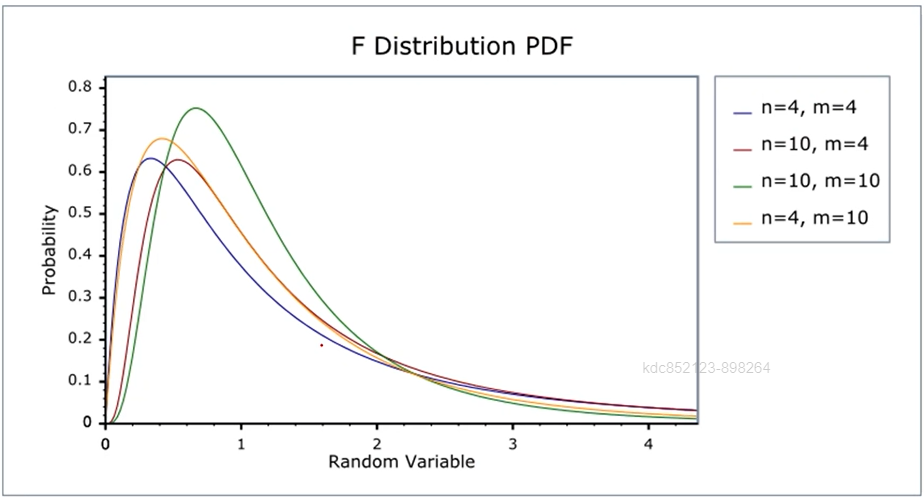

4c가아닌 3c가 맞음.
추정
추정
-
추정(estimation) : 모집단의 모수를 모를 경우 표본으로 추출된 통계량을 모집단의 근사값으로 사용하는 것을 추정이라고 함.
-
추정량(estimator) : 표본 평균으로 모평균을 추정할 때 표본 평균을 모평균에 대한 추정량이라고 함.
- 모수를 푸정하는 방법에는 점추정(point estimation)과 구간 추정(interval estimation)이 있음
- 점추정 : 모수를 하나의 특정값으로 추정 하는 방법
- 구간 추정 : 모수가 포함될 수 있는 구간을 추정하는 방법


-
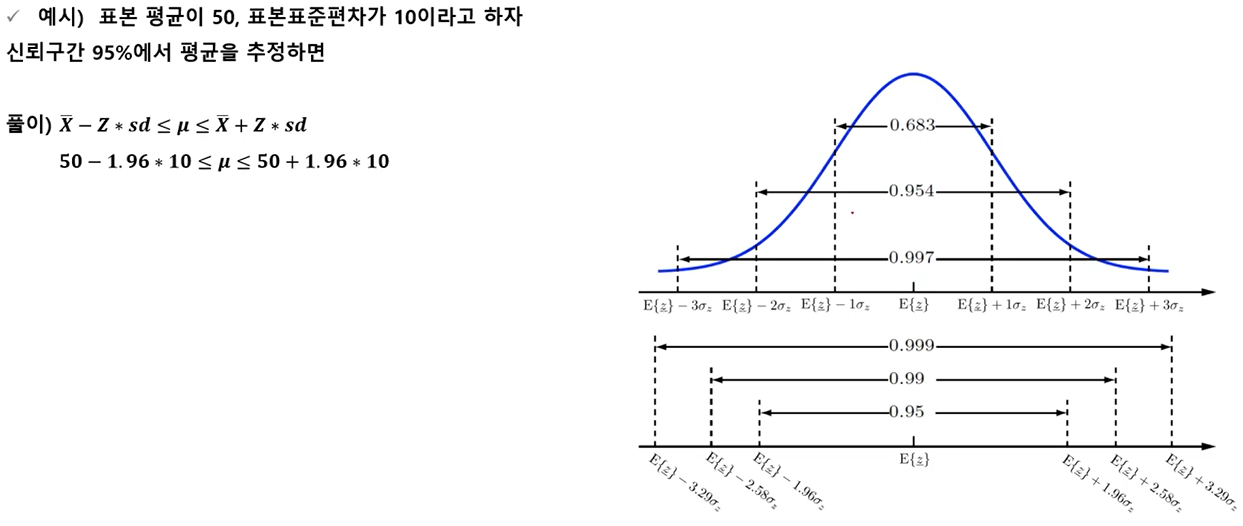
구간추정에서 신뢰구간의 의미는 아래의 이미지로 이해 알 수 있음
-
P(-z≤Z≤z)의 CI가 0.95일 때 z=1.96임



모비율 추정
-
모비율의 점추정
- 비율에 대한 추정으로 우리가 원하는 속성(class)에 속하면'1' 아니면 '0'일 때, 1의 속성을 갖는 것의 개수를 X라고 하면 X ~ b(N,P) 임
- 이 때 모비율의 점추정량을 표본 비율(sample proportion)이라고 함
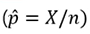
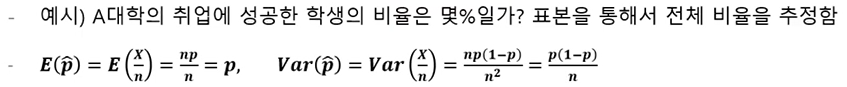
-
모비율의 구간추정
- 모비율 구간 추정에서 정규분포의 근사가 가능한 대표본은 보통 np>5, n(1-p) > 5 를 동시에 만족해야 함
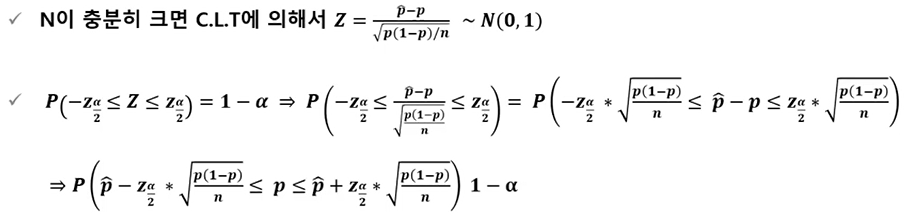
- 모비율 구간 추정에서 정규분포의 근사가 가능한 대표본은 보통 np>5, n(1-p) > 5 를 동시에 만족해야 함
- 예시

-
모평균 차이의 추정(점추정)
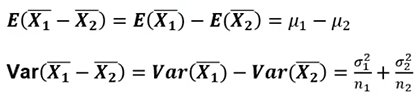
-
모평균 차이의 추정(구간 추정 : 대표본)
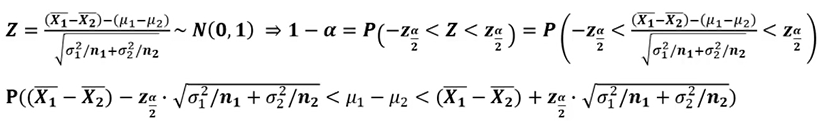

-
모평균 차이의 추정(구간 추정 : 소표본, 모분산을 모르는 경우)
- 두 모집단의 분산을 아는 경우에는 대표본과 동일하게 추정 가능하지만, 모르는 경우에는 등분산 가정이 필요

- 두 모집단의 분산을 아는 경우에는 대표본과 동일하게 추정 가능하지만, 모르는 경우에는 등분산 가정이 필요
-
합동 분산 추정량(pooled variance estimator) : 공통 분산의 추정량
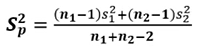
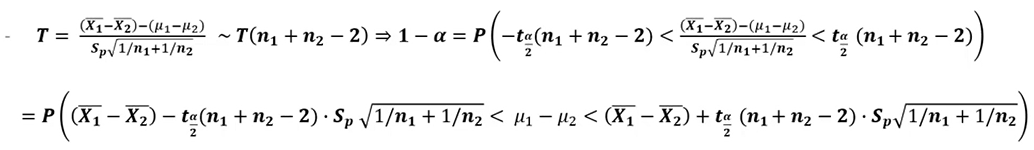
- 엑셀에서 사용하는 함수
- 평균 : AVERAGE()
- 표준편차 : STDEV()
- 분산 : 표준편차^2를 하거나 VAR()를 사용해도된다.
- 엑셀에서 사용하는 함수
- 모비율 차이의 추정(잠추정)
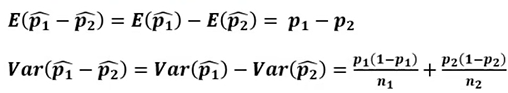
- 모비율 차이의 추정(구간 추정)
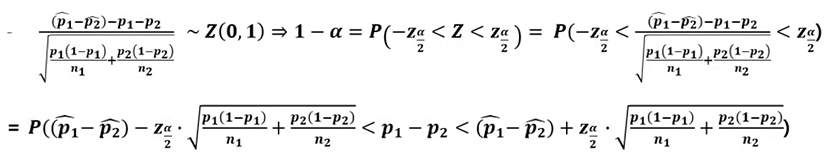
- 모비율 차이의 추정(예시)

