
❓데이터베이스 인덱싱이란?
데이터베이스 인덱싱은 데이터베이스 내에서 데이터 검색 속도를 향상시키기 위한 구조입니다. 인덱싱은 책의 색인처럼 동작하며, 빠른 데이터 검색을 가능하게 합니다.
❔왜 인덱싱이 필요한가?
-
속도
- 데이터베이스 내 데이터가 많아질수록 원하는 데이터를 찾기 위한 시간이 증가합니다. 인덱싱은 이 검색 시간을 크게 줄여줍니다.
-
최적화된 쿼리 수행
- 인덱싱은 쿼리 성능을 최적화하며, 이를 통해 전체 시스템 성능도 향상됩니다.
-
인덱싱의 원리
- 트리 구조와 그 작동 방식
데이터베이스 인덱싱의 대표적인 구조로 B-tree와 B+ tree가 있습니다. 이러한 트리 구조를 이해하면 인덱싱이 어떻게 빠른 검색 속도를 제공하는지 이해하는 데 도움이 됩니다.
- 트리 구조와 그 작동 방식
B-tree (Balanced Tree)
B-Tree는 자식 2개 만을 갖는 이진 트리(Binary Tree)를 확장하여 N개의 자식을 가질 수 있도록 고안된 것이다. 그리고 좌우 자식 간의 균형이 맞지 않을 경우에는 매우 비효율적이라, 항상 균형을 맞춘다는 의미에서 균형 트리(Balanced Tree)라고 불린다.
B-Tree는 최상위에 단 하나의 노드 만이 존재하는데, 이를 루트 노드(Root Node)라고 한다. 그리고 중간 노드를 브랜치 노드(Branch Node), 최하위 노드를 리프 노드(Leaf Node)라고 한다.
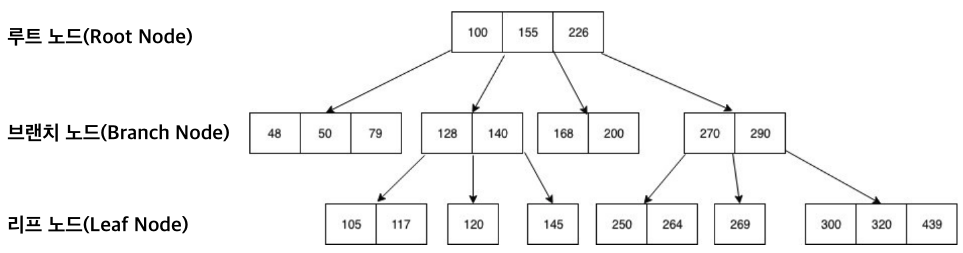
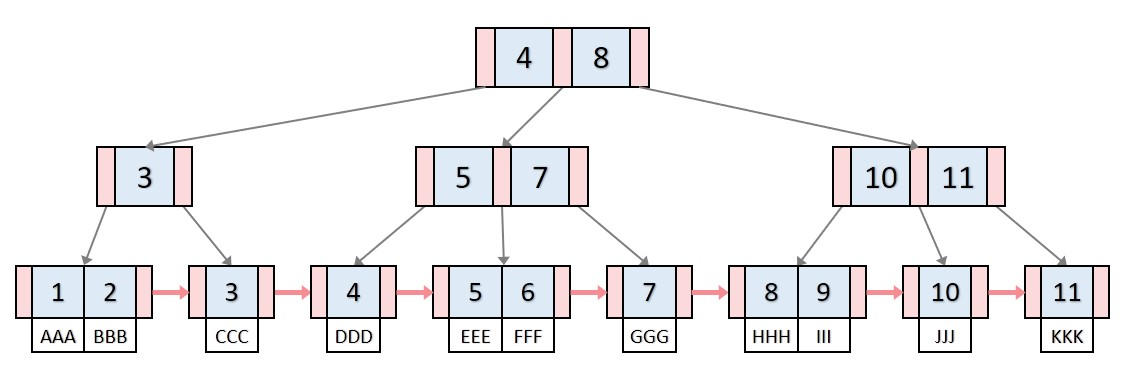
B+ tree
B-tree의 변형으로, 실제 데이터는 리프 노드에만 저장됩니다.
내부 노드는 키 값의 범위만 가지며, 실제 데이터에 대한 포인터는 가지고 있지 않습니다.
대부분의 데이터베이스 시스템에서 선호되는 인덱스 구조입니다.
💡예시
10만 개의 이름이 저장된 데이터베이스에서 '이영희'라는 이름을 찾는다고 가정해봅시다.
B+ tree 인덱스가 있다면,
1. '이' 성을 가진 사람들
2. '이영'으로 시작하는 이름
3. '이영희'를 훨씬 더 빠르게 찾을 수 있습니다.
실제 데이터는 리프 노드에서만 접근되므로, 트리의 높이만큼의 스텝으로 원하는 데이터를 찾을 수 있습니다.
⁉️ 인덱싱의 장단점
👍장점
- 빠른 데이터 검색: 인덱스의 주된 목적입니다.
- 정렬된 데이터 액세스: 인덱스를 통해 정렬된 순서로 데이터에 액세스할 수 있습니다.
👎단점
- 저장 공간: 인덱스는 추가적인 저장 공간을 필요로 합니다.
- 삽입/삭제 오버헤드: 인덱스가 있는 테이블에 데이터를 삽입하거나 삭제할 때, 인덱스도 함께 업데이트해야 합니다.
❗인덱스(index)를 사용하면 좋은 경우
- 규모가 작지 않은 테이블
- INSERT, UPDATE, DELETE가 자주 발생하지 않는 컬럼
- JOIN이나 WHERE 또는 ORDER BY에 자주 사용되는 컬럼
- 데이터의 중복도가 낮은 컬럼
- 기타 등등
인덱스를 사용하는 것 만큼이나 생성된 인덱스를 관리해주는 것도 중요하다. 그러므로 사용되지 않는 인덱스는 바로 제거를 해주어야 한다.
📖결론
데이터베이스 인덱싱은 대규모 데이터 처리에 필수적입니다. 하지만, 모든 상황에 인덱스를 사용하는 것이 좋은 것은 아닙니다. 인덱스의 장단점을 충분히 고려하여, 적절한 전략을 세워야 합니다.
참고 자료
