관계형 데이터베이스
관계형 데이터베이스(Relational DataBase) : 테이블, 행, 열의 정보를 구조화하는 방식
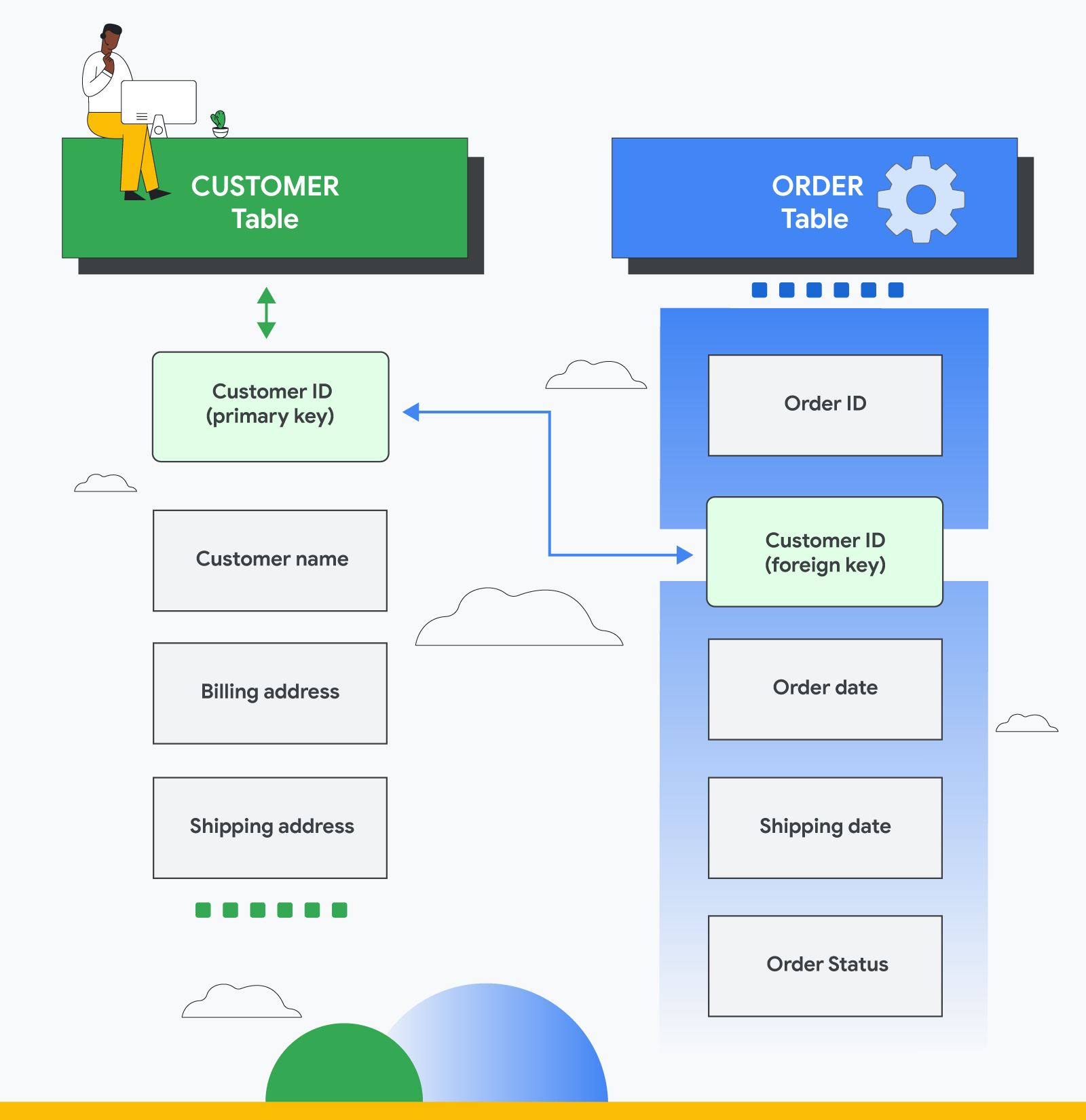 출처 : Google Cloud
출처 : Google Cloud
RDB의 장점
- ACID 를 지원하여 오류, 실패 또는 기타 잠재적 오작동에 관계없이 데이터 유효성을 보장한다
- 락을 제공하여 공동 작업 시 동시에 같은 데이터에 접근할 수 없다
- 역할 기반 보안을 통해 데이터 접근을 특정 사용자로 제한할 수 있다
- 데이터베이스 정규화 : 데이터 중복성을 줄이고 데이터 무결성을 향상시키는 정규화라고 하는 설계 기법을 사용한다
- 표준 언어인 SQL을 다양한 플랫폼에서 사용이 가능하다
- 데이터의 분류, 정렬, 탐색 속도가 빠르다
- 스키마가 명확하게 정의되어 있다
→ 유지보수가 편하다
RDB의 단점
- 스키마를 수정하기 어렵다
- 시스템이 커지면 쿼리가 복잡해진다
- Scale-up 만 지원하기 때문에 성능 향상 비용이 많이 든다
- 많은 자원을 사용하기 때문에 시스템 부하가 높다
트랜잭션(transaction)
데이터베이스에서 데이터의 상태를 변경하기 위해 수행하는 논리적인 작업의 단위
→ 논리적인 작업의 단위이기 때문에 하나의 쿼리나 문장이 아니다
* 트랜잭션은 ACID 원칙을 만족해야 한다
트랜잭션 구성
- 데이터에 영구적인 변경을 하는 DML : 롤백이 가능하다
- 하나의 DDL : AUTO COMMIT 이므로 롤백이 불가능
- 하나의 DCL
COMMIT, ROLLBACK 이전의 데이터 상태
SELECT로 작업 결과 확인 가능- 작업 수행 이전의 데이터 복구 가능
- 다른 사용자는 작업 결과 볼 수 없음
- 변경한 row에 대해 lock이 설정되어 다른 사용자가 변경할 수 없음
COMMIT 이후의 데이터 상태
- 변경사항이 데이터베이스에 영구적으로 반영됨
- 이전 데이터 복구 불가능
- 모든 사용자가 결과를 볼 수 있음
- lock이 해제됨
ROLLBACK 이후의 데이터 상태
- 데이터 변경사항 취소
- 이전 데이터가 재저장됨
- lock이 해제됨
예시 : 은행 계좌 이체
- 상황: A가 B에게 10만 원을 이체하는 경우
- 트랜잭션 처리 단계:
- A 계좌에서 10만 원 출금
- B 계좌에 10만 원 입금
- 두 작업은 동시에 성공하거나, 동시에 실패해야 한다
→ A 계좌에서 출금되었는데 B 계좌에 입금되지 않으면 데이터 불일치 발생
ACID 원칙
Atomicity
원자성(Atomicity) : 트랜잭션 전체를 실행하거나 어떤 부분도 실행하지 않는 것
- 하나의 트랜잭션이 성공하면 트랜잭션 내의 모든 작업이 데이터베이스에 반영된다
- 트랜잭션 실행 도중 실패하면 트랜잭션 내의 모든 작업이 취소되고 트랜잭션 실행 전의 상태로 돌아간다 (ROLLBACK)
Consistency
일관성(Consistency) : 트랜잭션이 실행되기 전과 후의 데이터베이스 상태가 항상 일관성 있는 상태를 유지해야 한다는 것
즉, 트랜잭션이 성공적으로 완료되면 데이터베이스는 정의된 모든 제약 조건(무결성 제약조건)을 만족하는 상태로 유지되어야 한다는 의미
데이터베이스가 항상 유효한 상태를 유지하도록 보장한다
예시 : 은행 계좌 이체
-
A 계좌: 100만 원
B 계좌: 50만 원 -
시스템 규칙: A + B의 총합은 항상 150만 원이어야 함
-
트랜잭션: A → B로 10만 원 이체
트랜잭션 전: A=100, B=50, A+B=150
트랜잭션 도중: A=90 (출금은 했는데 B에 입금은 아직 안 됨)
트랜잭션 후: A=90, B=60, A+B=150
→ 트랜잭션이 끝난 후에도 총합(150만 원)은 유지되므로 일관성 유지
이 경우는 DBMS에서 관리하는 무결성 제약조건에 속하는게 아니라 비즈니스 무결성/논리적 무결성에 해당된다
왜?
→ 총합이 150만원이어야 한다는 제약조건을 SQL에서 표현하지 못하기 때문
Isolation
고립성(Isolation) : 동시에 여러 트랜잭션이 수행될 때, 각 트랜잭션은 독립적으로 실행되는 것처럼 보여야 한다는 성질
즉, 트랜잭션 A가 실행 중일 때 트랜잭션 B가 A의 중간 결과를 볼 수 없어야 한다
→ 데이터 일관성과 무결성이 깨지지 않음
Isolation 이 없다면?
| 문제 | 설명 | 예시 |
|---|---|---|
| Dirty Read | 아직 커밋되지 않은 데이터를 다른 트랜잭션이 읽음 | A가 값 변경 후 커밋 전인데 B가 그 값을 읽음 |
| Non-Repeatable Read | 한 트랜잭션 내에서 같은 SELECT를 했는데 결과가 달라짐 | A가 읽었을 때 100, 두 번째 읽을 땐 B가 변경해서 200으로 됨 |
| Phantom Read | WHERE 조건에 해당하는 행 수가 실행 중에 달라짐 | 처음엔 SELECT COUNT(*) = 5였는데 도중에 B가 행을 추가함 |
Isolation은 CPU의 공유 자원 문제(예: 임계 영역, race condition)과 매우 유사한 개념
Durability
영속성(Durability) : 트랜잭션이 성공적으로 커밋된 후에는 시스템이 다운되거나 장애가 발생하더라도 그 결과는 영구적으로 보존되어야 한다는 성질
영속성 보장 방법
-
Write-Ahead Logging (WAL)
데이터를 실제 반영하기 전에 로그를 먼저 디스크에 기록
→ 시스템 장애 발생 시 이 로그를 보고 복구(Redo) -
Redo/Undo 로그
Redo 로그: 커밋된 트랜잭션 복원
Undo 로그: 롤백 시 이전 상태로 되돌림 -
디스크 플러시 (flush)
트랜잭션 커밋 시 변경 사항을 메모리 → 디스크에 저장
디스크에 반영된 이후에만 COMMIT 성공으로 처리 -
저널링 파일 시스템 (파일 단위 DB)
SQLite 같은 DB는 트랜잭션 정보를 저널 파일에 기록하고 장애 복구 시 활용
무결성 제약 조건
데이터베이스에 잘못된 데이터가 들어가지 않도록 제한을 두는 규칙
테이블을 정의할 때 설정하며, DBMS는 이를 자동으로 검사하고 위반되면 오류를 발생시켜 트랜잭션을 막는다
무결성 제약 조건을 설정하는 이유
- 데이터 정확성 보장: 실수나 프로그램 오류로 잘못된 데이터 입력 방지
- 일관성 유지: 여러 테이블 간 관계가 깨지지 않도록 유지 (FK)
- 신뢰성 향상: 시스템이 자동으로 데이터 검사를 해주기 때문에 믿고 사용할 수 있음
주요 무결성 제약조건 종류
| 제약조건 | 설명 | 예시 |
|---|---|---|
| NOT NULL | 값이 반드시 있어야 함 | 이름, 이메일은 NULL이면 안 됨 |
| UNIQUE | 중복을 허용하지 않음 | 주민번호, 이메일 |
| PRIMARY KEY | 기본키. NOT NULL + UNIQUE 조합 | 사용자 ID |
| FOREIGN KEY | 다른 테이블의 값을 참조 | 주문 테이블의 customer_id는 고객 테이블 참조 |
| CHECK | 특정 조건을 만족해야 함 | 나이는 0보다 커야 함 |
| DEFAULT | 값이 없을 경우 기본값 지정 | 가입일 = 현재 날짜 |
트랜잭션 격리 수준
SQL 표준의 4단계 격리 수준
아래로 갈수록 동시성 높음, 위로 갈수록 안정성/일관성 높음
* 격리 수준이 높을수록 동시 처리 성능이 떨어질 수 있음 (락 걸림)
| 격리 수준 | 설명 | 허용되는 문제 |
|---|---|---|
| Serializable | 완전한 격리, 트랜잭션 순차 실행처럼 보임 | 없음 |
| Repeatable Read | 읽은 행은 트랜잭션 중 변경 불가 | Phantom Read 허용 |
| Read Committed | 커밋된 데이터만 읽음 | Non-Repeatable Read 허용 |
| Read Uncommitted | 커밋되지 않은 데이터도 읽음 | Dirty Read 허용 |
* Read Committed: 대부분의 DBMS에서 기본값 (Oracle, PostgreSQL 등)
* Repeatable Read: MySQL의 기본값
Key
Primary Key
Primary Key (PK) : 테이블 내에서 각 행을 고유하게 식별하는 데 사용되는 열
특징
- 유일성: 각 행을 고유하게 식별한다
- NULL 값은 허용되지 않음
- 하나의 테이블에 하나만 존재한다 (중복 허용 X)
* 자주 참조되는 데이터는 다른 테이블에서 Foreign Key (FK)로 참조된다
Foreign Key
Foreign Key (FK) : 다른 테이블의 Primary Key를 참조하는 열
다른 테이블의 데이터를 참조하여 테이블 간 관계를 형성
외래키는 참조 무결성을 보장하는 데 사용된다
특징
- 참조 무결성: 외래키로 참조된 값이 기존의 Primary Key와 일치해야 하며 삭제나 수정 시 관련 데이터를 자동으로 처리할 수 있다
- 외래키는 NULL 값을 가질 수 있으며, 이는 참조되지 않는 값을 의미한다
- 하나의 테이블에 여러 외래키가 있을 수 있다
ON DELETE, ON UPDATE 옵션
부모 테이블(참조 대상)의 변경이나 삭제가 자식 테이블에 어떤 영향을 줄지를 정하는 옵션
| 옵션 | 설명 |
|---|---|
| CASCADE | 부모가 변경되거나 삭제되면 자식도 같이 변경/삭제됨 |
| RESTRICT | 부모가 참조 중이면 부모의 데이터를 삭제하거나 수정하는 것이 불가능 |
| SET NULL | 부모가 삭제되면 자식의 해당 외래키를 NULL로 설정 |
| NO ACTION | RESTRICT와 비슷. 다만 즉시 오류를 발생하지 않을 수도 있음 (DBMS에 따라 차이 있음) |
| SET DEFAULT | 부모가 삭제되면 자식의 외래키를 기본값으로 설정 (MySQL은 지원 안 함) |
Unique Key
Unique Key (UK) : 테이블 내에서 특정 열이나 열들의 값이 중복되지 않도록 보장하는 제약조건
Primary Key와 비슷하지만, NULL 값을 허용한다
특징
- 유일성: 중복되지 않는 값을 보장한다
- 하나의 열에 대해 단 하나의 NULL 값을 허용할 수 있다
- 하나의 테이블에 여러 개의 Unique Key가 있을 수 있다
Data Type
MySQL
정수
| 타입 | 저장 크기 | 범위 (SIGNED 기준) |
|---|---|---|
| TINYINT | 1바이트 | -128 ~ 127 |
| SMALLINT | 2바이트 | -32,768 ~ 32,767 |
| MEDIUMINT | 3바이트 | -8,388,608 ~ 8,388,607 |
| INT/INTEGER | 4바이트 | -2,147,483,648 ~ 2,147,483,647 |
| BIGINT | 8바이트 | -9경 ~ 9경 (±9,223,372,036,854,775,807) |
실수
| 타입 | 설명 |
|---|---|
| FLOAT(M,D) | 소수점 이하 D자리까지 표현. 4바이트 Single Precision(약 7자리 정확도) |
| DOUBLE(M,D) | 더 정밀한 표현. 8바이트 Double Precision(약 15자리 정확도) |
| DECIMAL(M,D) | 고정 소수점 숫자. 정확한 소수 계산 필요 시 사용 (예: 금융) |
* 고정 소수점 vs. 부동 소수점
고정 소수점은 소수점 위치가 고정되어 정밀도가 높아 정확한 값이 필요할 때 사용하고
부동 소수점은 정밀도는 낮을 수 있지만, 넓은 값의 범위와 빠른 연산이 필요할 때 사용한다
문자열
| 타입 | 설명 |
|---|---|
| CHAR(n) | 고정 길이 문자열 (공백 포함하여 n자). |
| VARCHAR(n) | 가변 길이 문자열. 최대 65,535바이트까지 가능. |
| TINYTEXT | 최대 255자 |
| TEXT | 최대 65,535자 |
| MEDIUMTEXT | 최대 16,777,215자 |
| LONGTEXT | 최대 4,294,967,295자 |
| ENUM('a','b') | 사전에 정의된 값 중 하나만 선택 가능. |
| SET('a','b') | 여러 개 선택 가능한 집합형. |
* 고정 길이 문자열 vs. 가변 길이 문자열
고정 길이 문자열은 n자로 고정되어 입력한 문자열이 n자보다 적을 경우 공백으로 채워지게 된다
가변 길이 문자열은 n자 내에서 입력한 문자열만큼만 저장한다
→ 고정 길이 문자열은 저장공간을 낭비할 가능성이 있지만 삽입, 정렬, 비교, 검색 속도가 가변 길이 문자열보다 빠르다
날짜 및 시간
| 타입 | 설명 |
|---|---|
| DATE | 'YYYY-MM-DD' |
| DATETIME | 'YYYY-MM-DD HH:MM:SS' |
| TIMESTAMP | Unix 시간 기반. 자동 생성/수정 유용. Timezone 설정 가능 |
| TIME | 'HH:MM:SS' |
| YEAR | 'YYYY' (연도만 저장) |
기타
| 타입 | 설명 |
|---|---|
| BIT(n) | 비트 필드. 1~64 비트 저장 |
| BINARY(n) | 고정 길이 이진 데이터 |
| VARBINARY(n) | 가변 길이 이진 데이터 |
| TINYBLOB | 최대 255바이트 |
| BLOB | 최대 65,535바이트 |
| MEDIUMBLOB | 최대 16,777,215바이트 |
| LONGBLOB | 최대 4,294,967,295바이트 |
* BLOB?
BLOB은 Binary Large Object의 약자로 텍스트가 아닌 데이터(이미지, 동영상, 오디오, PDF 등)을 인코딩 없이 바이트 그대로 저장할 때 사용한다
→ 보통 대용량 데이터는 데이터베이스가 아닌 스토리지에 저장하고 스토리지 경로만 데이터베이스에 저장하기 때문에 사용할 일이 거의 없다
Oracle
숫자형
| 타입 | 설명 |
|---|---|
| NUMBER(p, s) | 정밀한 숫자 표현 (p: 전체 자리수, s: 소수점 이하 자리수) |
| INTEGER | 정수형, NUMBER(38)과 동일 |
| FLOAT | 부동소수점 숫자, NUMBER와 거의 동일하지만 과학 계산용 표현 |
| BINARY_FLOAT | 32비트 부동소수점 (빠른 계산용, 정밀도 낮음) |
| BINARY_DOUBLE | 64비트 부동소수점 (더 정밀함) |
문자형
| 타입 | 설명 |
|---|---|
| CHAR(n) | 고정 길이 문자열 (최대 2000바이트) |
| VARCHAR2(n) | 가변 길이 문자열 (최대 4000바이트) → 오라클에서 VARCHAR 대신 사용 |
| NCHAR(n) | 유니코드 고정 길이 문자열 (국제화 지원) |
| NVARCHAR2(n) | 유니코드 가변 길이 문자열 |
| CLOB | 큰 텍스트 데이터 (최대 4GB) |
* 유니코드 문자열
- 다국어 지원: 한 테이블에 한국어, 일본어, 영어, 이모지 등을 동시에 저장 가능
- 국제 서비스 개발에 필수
- 문자 깨짐 방지 (인코딩 혼선 없앰)
날짜 및 시간형
| 타입 | 설명 |
|---|---|
| DATE | 날짜와 시간 모두 저장 (YYYY-MM-DD HH24:MI:SS) |
| TIMESTAMP | 날짜 + 시간 + 소수초 (정밀도 설정 가능) |
| TIMESTAMP WITH TIME ZONE | 타임존 포함 시간 |
| TIMESTAMP WITH LOCAL TIME ZONE | 세션의 타임존 기준으로 변환 저장 |
| INTERVAL YEAR TO MONTH | 두 날짜 사이의 차이 (연/월 단위) |
| INTERVAL DAY TO SECOND | 두 시간 사이의 차이 (일/시/분/초 단위) |
대용량 파일
| 타입 | 설명 |
|---|---|
| BLOB | 이진 대용량 데이터 저장 (이미지, 파일 등) |
| CLOB | 문자 대용량 데이터 저장 |
| NCLOB | 유니코드 기반 CLOB |
| BFILE | 외부 파일 참조 (DB 외부 저장소) |
객체
데이터를 저장하거나, 제어하거나, 처리하기 위한 이름 있는 논리 구조
기본 객체
| 객체 | 설명 |
|---|---|
| Table | 데이터를 행(Row)과 열(Column)로 저장하는 기본 구조 |
| View | 하나 이상의 테이블에 대한 가상 테이블 (저장된 쿼리 결과) |
| Index | 검색 성능 향상을 위한 데이터 구조 |
| Sequence | 자동으로 순차적인 숫자를 생성하는 객체 |
| Synonym | 다른 객체에 대한 별칭 (Oracle 전용 개념) |
| Schema | 논리적인 객체들의 집합 (사용자 = 스키마) |
| Database | 스키마, 테이블, 뷰 등 여러 객체들을 포함하는 가장 큰 단위 |
-
시퀀스 생성
CREATE SEQUENCE sequence_name [INCREMENT BY n] [START WITH n] [MAXVALUE n | NOMAXVALUE] [MINVALUE n | NOMINVALUE] [CYCLE | NOCYCLE] [CACHE n | NOCACHE] [ORDER | NOORDER];옵션 설명 START WITH n시퀀스 시작 값 지정 (기본값: 1) INCREMENT BY n다음 값으로 증가 또는 감소할 양 (기본값: 1, 음수도 가능) MAXVALUE n시퀀스가 가질 수 있는 최대값 설정 NOMAXVALUE최대값 없음 (기본값: 증가 시 10^27) MINVALUE n시퀀스가 가질 수 있는 최소값 설정 NOMINVALUE최소값 없음 (기본값: 감소 시 -10^26) CYCLEMAXVALUE 또는 MINVALUE 도달 시 다시 시작값으로 순환 NOCYCLE순환 없이 멈춤 (기본값) CACHE nn개의 시퀀스 값을 메모리에 미리 할당 (성능 향상) NOCACHE캐시 없이 디스크에서 매번 읽음 (성능 저하) ORDER병렬 처리 환경에서 시퀀스 값의 순서 보장 NOORDER순서 보장 없음 (기본값, 단일 인스턴스에서는 차이 없음)
제어 및 자동화 객체
| 객체 | 설명 |
|---|---|
| Trigger | 테이블에 대해 INSERT/UPDATE/DELETE가 발생할 때 자동 실행되는 프로시저 |
| Procedure | 저장된 일련의 SQL 문 (입출력 파라미터 있음) |
| Function | 반환값이 있는 저장 함수 |
| Package | 관련된 프로시저, 함수 등을 묶어놓은 단위 (Oracle 전용) |
| Constraint | 테이블 열에 적용되는 데이터 무결성 제약 조건 (PK, FK, NOT NULL 등) |
보안 및 권한 관련 객체
| 객체 | 설명 |
|---|---|
| User | 데이터베이스에 접속하고 객체를 소유할 수 있는 계정 |
| Role | 권한을 묶어서 사용자에게 일괄 부여 |
| Profile | 사용자 리소스 사용량 제한 (Oracle) |
Dictionary
데이터베이스의 구조와 메타정보(테이블, 컬럼, 인덱스, 사용자 등)를 저장하고 관리하는 시스템 테이블 또는 뷰 집합
ORACLE 서버에 의해 생성되고 유지보수된다
Dictionary에서 저장하는 데이터
- ORACLE 서버 사용자명
- 사용자에게 허가된 권한
- 데이터베이스 객체명
- 테이블 제약조건
- 감사(Auditing) 정보
Dictionary View 종류
| 뷰 종류 | 설명 | 접근 대상 범위 |
|---|---|---|
USER_ 뷰 | 현재 로그인한 사용자(스키마) 소유 객체 정보 조회 | 🟢 나의 객체만 |
ALL_ 뷰 | 현재 사용자에게 권한이 부여된 모든 객체 정보 조회 | 🟡 내 것 + 접근 권한 있는 타인 것 |
DBA_ 뷰 | 데이터베이스 전체 객체 정보 조회 (DBA 권한 필요) | 🔴 전체 데이터베이스 |
V$ 뷰 (동적 성능 뷰) | 인스턴스의 성능, 세션, 메모리 등 실시간 정보 제공 | 🔴 관리자 전용 실시간 뷰 |