1. Choose Your ML Problems
실무에서 데이터과학자와 분석가들은 다음과 같은 프로세스를 거치며 프로젝트를 진행.
- 비즈니스 문제
- 실무자들과 대화를 통해 문제를 발견
- 데이터 문제
- 문제와 관련된 데이터를 발견
- 데이터 문제 해결
- 데이터 처리, 시각화
- 머신러닝/통계
- 비즈니스 문제 해결
- 데이터 문제 해결을 통해 실무자들과 함께 해결
1.1 우선 예측해야 하는 타겟을 명확히 정하고 그 분포를 살펴보기
1.1.1 지도학습(Supervised learning)에서는 예측할 타겟을 먼저 정합니다.
테이블 형태의 데이터세트인 경우 어떤 특성을 예측타겟으로 할지 먼저 정해야 합니다.
어떤 문제는 회귀/분류문제가 쉽게 구분이 안되는 경우도 있습니다.
- 이산형, 순서형, 범주형 타겟 특성도 회귀문제 또는 다중클래스분류 문제로도 볼 수 있습니다.
- 회귀, 다중클래스분류 문제들도 이진분류 문제로 바꿀 수 있습니다.
1.2 정보의 누수(leakage)가 없는지 확인
아직 데이터에 대해 완전히 이해하고 있지 못할 때, 모델을 만들고 평가를 진행했는데 예측을 100% 가깝게 잘 하는 경우가 있음.
이때 너무 좋아하시면 안됩니다! 정보의 누수가 존재할 가능성이 매우 큽니다!
여러 특성을 다루다 보면
- 타겟변수 외에 예측 시점에 사용할 수 없는 데이터가 포함되어 학습이 이루어 질 경우
- 훈련데이터와 검증데이터를 완전히 분리하지 못했을 경우
정보의 누수가 일어나 과적합을 일으키고 실제 테스트 데이터에서 성능이 급격하게 떨어지는 결과를 확인할 수 있습니다.
예측 모델을 위한 타겟을 올바르게 선택하고 그 분포를 확인할 수 있다.
테스트/학습 데이터 사이 or 타겟과 특성들간 일어나는 정보의 누출(leakage)을 피할 수 있다.
상황에 맞는 검증지표(metrics)를 사용할 수 있다.
- 데이터 누수는...
- 답안지를 보고 시험공부를 한 것.
- 타겟의 정보를 학습에 사용한 것.
- 훈련데이터와 검증데이터가 분리가 안 된 경우.
- 검증 정확도가 1인 경우 검증데이터가 훈련데이터에 섞였을 수 있다.
1.3 문제에 적합한 평가지표를 선택
1.3.1 평가지표
분류와 회귀 모델의 평가지표는 완전히 다름. 분류문제에서 타겟 클래스비율이 70% 이상 차이날 경우에는 정확도만 사용하면 판단을 정확히 할 수 있음. 정밀도, 재현율, ROC, AUC 등을 같이 사용해야 함. 회귀문제에서는 MAE, MSE, RMSE, R^2.
- AUC의 의미: 1을 예측하는 점수가 0을 예측하는 점수보다 얼마나 높은가? 이를 수치화 한 것.
1.3.2 불균형 클래스
분류문제에서 예측하고자 하는 값의 실제 분포가 균형적이지 않은 경우.
이를 처리하는 방법은 오버 샘플링, 언더 샘플링, 클래스 웨이트를 주는 것.
- 오버샘플링: 대표적으로 SMOTE(Synthetic Minority Over-Sampling Technique)라고 상대적으로 부족한 데이터 레이블에 대해서 비슷한 것을 인공적으로 데이터를 만듬. 오버샘플링의 문제점은 테스트 데이터에 SMOTE를 쓸 수 있나? 그러면 안 된다. 검증 데이터나 테스트 데이터가 아닌 훈련 데이터에 써야 한다.
1.4 회귀 문제에서는 타겟의 분포를 주의 깊게 살펴보기
타겟의 분포를 살펴보기
회귀분석에서는 타겟 분포가 비대칭 형태인지 확인해 보세요.
- 선형 회귀 모델은...
- 일반적으로 특성과 타겟간에 선형관계를 가정합니다.
- 그리고 특성 변수들과 타겟변수의 분포가 정규분포 형태일때 좋은 성능을 보입니다.
특히 타겟변수가 왜곡된 형태의 분포(skewed)일 경우 예측 성능에 부정적인 영향을 미칩니다.
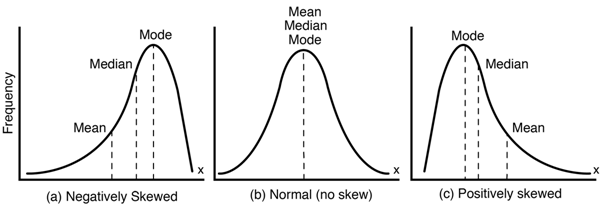
- 타겟의 분포
타겟 변수가 왜곡된 형태의 분포. 꼬리가 왼쪽이나 오른쪽으로 치우쳐 진 분포. 오른쪽으로 치우쳐 진 분포는 로그변환(Log-Transform)을 사용한다. 왼쪽으로 치우쳐 진 분포는 루트를 씌운다. 이럴 경우 정규분포처럼 맞춰지게 된다. 실무에서는 오른쪽으로 치우친 데이터가 더 많다. 횟수나 갯수 데이터나 뭐 이런 것들은 오른쪽으로 치우쳐 있다.
Q & A
1. claass weight를 쓰면 오버샘플링과 다운 샘플링과 같은 효과라고 생각하면 되나요? 그렇다면 굳이 오버샘플링과 다운샘플링을 사용하지 않아도 되지 않을까요?
→ 맞음. 그런데 실제로 해보면 뭐가 명확하게 좋은 지는... 그냥 잘 나오면 장땡. 적은 데이터로 잘 나오면 좋다.
2. 데이터가 범주형인지 수치형인지 타겟을 보고 확인하는 것인가요?
→ 맞음. 타겟을 보고 확인을 함. 분류문제의 불균형은 값의 갯수가 클래스별로 엄청나게 차이가 나는 것. 회귀문제의 불균형은 타겟분포가 치우친 것.
3. 이상치를 제거 하는 방법은?
→ 타겟 보고 상위 하위 몇 프로를 빼는 방식으로 진행이 됨.
