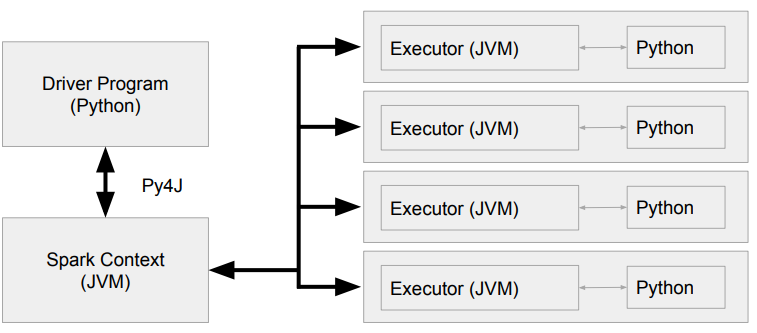
📌 JVM과 Python 간의 통신
PySpark Driver
- Python 프로세스 + JVM 프로세스
- 실제 SparkContext는 JVM쪽에서 생성한다.
PySpark Memory
-
Spark은 JVM Application이지만 PySpark은 Python 프로세스이다.
-> JVM에서 바로 동작하지 못하기 때문에 JVM 메모리를 사용할 수 없다. -
Spark.executor.pyspark.memory(Python프로세스)
-
Spark.python.worker.memory(Py4J)

-
Executor안에 2개의 프로세스가 존재한다.
- JVM 프로세서
- Python Worker
-
이 둘간에 오브젝트 Serialization/deserialization을 하는 것이 Py4J의 역할이다.
-
spark.executor.pyspark.memory
- PySpark은 기본적으로 overhead memory를 사용한다. 이 환경변수가 사용되면 PySpark이 사용할 수 있는 메모리는 이 환경변수의 값으로 고정된다.
- 이는 사실 PySpark이 외부 파이썬 함수를 쓰는 경우에만 필요하다.(기본적으로는 세팅되지 않는다.)
-
spark.python.worker.memory
- default 값은 512MB이다.
- JVM과 Python 프로세스간의 통신을 담당하는 Py4J가 사용할 수 있는 메모리의 양
- 이 크기를 넘어가면 디스크로 Spill이 발생한다.
-
spark.executor.pyspark.memory는 파이썬 프로세스의 사용 메모리크기를 결정한다.
-
spark.python.worker.memory는 JVM에서 사용되는 Python 오브젝트들의 최대 메모리를 결정한다.
Spark과 Python간의 통신
-
Py4J : Python과 JVM간의 데이터 교환을 통해 둘간의 연동을 도와주는 프레임워크
-
DataFrame/RDD 연산중에 Python 코드가 사용된다면?
-> 이는 별도의 Python 프로세스를 통해 실행되며 이 경우 파티션 데이터가 모두 넘어간다.
df.select("foo", "bar").where(df["foo" > 100).count()vs.
from operator import add
t = spark.sparkContext.parallelize(range(len))
a = t.reduce(add)- 드라이버에서 위의 Python프로세스에서 실행할 코드와 기타 데이터를 serialize해서 Executor에 전송한다.
- JVM executor는 Python 프로세스를 실행한다.(PySpark Script)
- Executor는 이것과 Partition을 Serialize하고 위에서 받은 코드와 함께 Python 프로세스로 전송한다.
- Python 프로세스에서 계산이 끝나면 결과가 다시 Executor로 Serialize되어서 전송된다.
