Spark
1.📒 Spark(1)

📌 Spark 버클리 대학의 AMPLab에서 Apache OpenSource Project로 2013년에 시작하였다. Hadoop의 뒤를 잇는 2세대 빅데이터 기술이다. YARN등을 분산환경으로 사용한다. Scala로 작성된다. 1. Saprk 3.0의 구성 Spark Core Spark SQL Spark ML Spark MLlib Spark ...
2.📒 Spark(2)
📌 Spark 실행 옵션 1. Spark 프로그램 실행 환경 ◆ Spark 프로그램 실행 환경 ❖ 개발/테스트/학습 환경 (Interactive Clients) ● 노트북 (주피터, 제플린) ● Spark Shell ❖ 프로덕션 환경 (Submit Job) ● spark-submit (command-line utility): 가장 많이 사용됨 ● 데이...
3.📒 Spark(3)
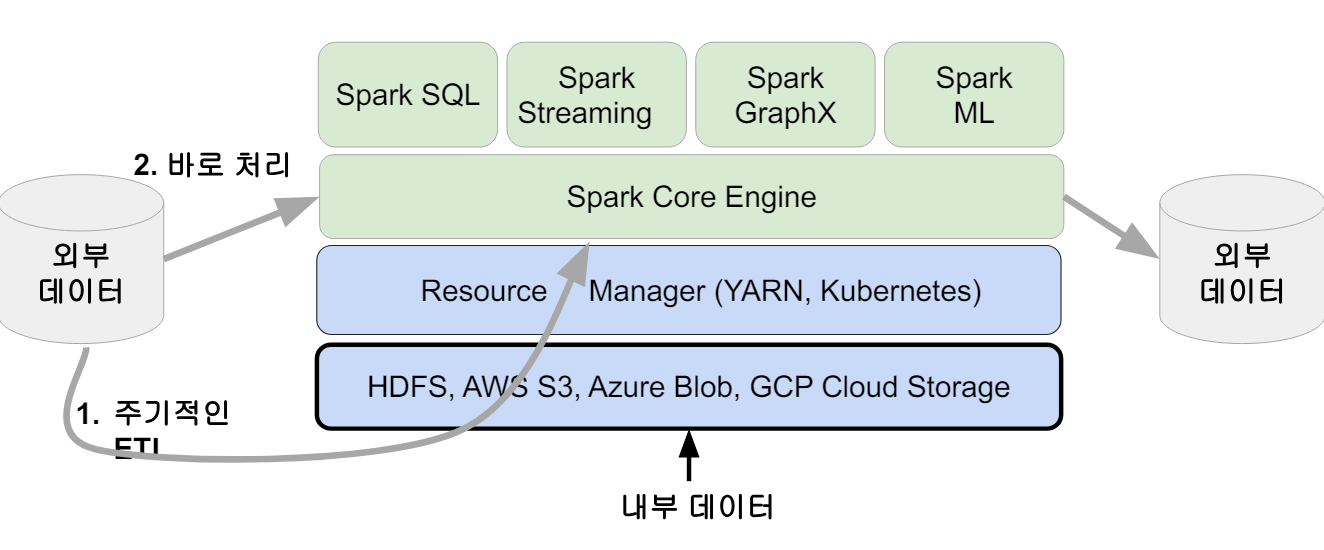
📌 Spark 데이터 시스템 아키텍처 📌 데이터 병렬처리의 조건 데이터가 먼저 분산되어야 한다. Hadoop Map의 데이터 처리 단위는 디스크에 있는 데이터 블록이다.(128MB) -> hdfs-site.xml에 있는 ㅇfs.block.size 프로퍼티가 결정한다. Spark에서는 이를 파티션(Partition)이라고 한다. (128MB...
4.📒 Spark(4)

📌 Spark 데이터 구조 RDD, DataFrame, Dataset (ummutable Distributed Data) -> 2016년에 DataFrame과 Dataset은 하나의 API로 통합디었다. -> 모두 파티션으로 나누어서 Spark에서 처리된다. ||RDD|DataFrame|Dataset| |:-:|:-:|:-:|:-:| |What?|Dis...
5.📒 Spark(5)
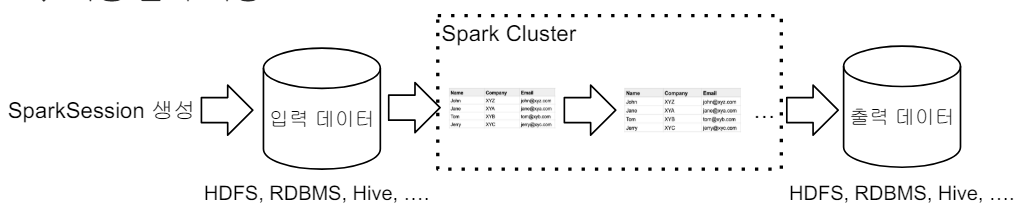
📌 Spark Session 생성 Spark 프로그램의 시작은 SparkSession을 만드는 것이다. 프로그램마다 하나를 만들어서 Spakr Cluster와 통신한다. -> Singleton 객체 Spark 2.0에서 처음 소개되었다. Spark Session을 통해 Spark이 제공해주는 다양한 기능을 사용한다. DataFrame, SQL...
6.📒 Spark(7)
📌 빅데이터에서의 SQL 데이터 분야에서 일하고자 하면 반드시 익혀야할 기본 기술 구조화된 데이터를 다루는 한 SQL은 데이터 규모와 상관없이 사용한다. 모든 대용량 데이터 웨어하우스는 SQL기반이다. Redshift, Snowflake, BigQuery Hive, Presto Spark도 예외는 아니다. -> Spark SQL이 지원된다. ...
7.📒 Spark(6)
📌 Spark 개발 환경 옵션 Local Standalone Spark + Spark Shell Python IDE – PyCharm, Visual Studio Databricks Cloud – 커뮤니티 에디션을 무료로 사용 다른 노트북 – 주피터 노트북, 구글 Colab, 아나콘다 등등 📌 Local Standalone Spark Spark Clus...
8.📒 Spark(8)
📌 Hive Meta Store Spark DB & Table 카탈로그 : 테이블과 뷰에 관한 메타 데이터 관리 기본으로 메모리 기반 카탈로그 제공 -> 세션이 끝나면 사라진다. Hive와 호환되는 카탈로그 제공 -> Persistent Table 관리 방식 테이블들은 DB라 부르는 폴더와 같은 구조로 관리(2단계) 메모리 기반 Table...
9.📒 Spark(9)
📌 Spark 파일포맷 Unstructured Text Semi-structured JSON XML CSV Structured PARQUET AVRO ORC SquenceFile |특징|CSV|JSON|PARQUET|AVRO| |:-:|:-:|:-:|:-:|:-:| |Column Storage|X|X|Y|X| |압축 기능...
10.📒 Spark(10) - ML(1)
📌 Spark ML Spark ML 소개 머신러닝 관련 다양한 알고리즘, 유틸리티로 구성된 라이브러리 Classification, Regression, Clustering, Collaborative Filtering, Dimensionality Reduction - 참고 아직 딥러닝의 대한 지원은 미약하다. RDD 기반과 DataFrame 기반의...
11.📒 Spark(11) - ML(2)
📌 Spark ML Pipeline 모델 빌딩과 관련된 흔한 문제 트레이닝 세트의 관리가 안된다. 모델 훈련 방법이 기록되지 않는다. 어떤 트레이닝 세트를 사용했는가? 어떤 피쳐들을 사용했는가? 하이퍼 파라미터는 무엇을 사용했는가? 모델 훈련에 많은 시간을 소요한다. 모델 훈련이 자동화가 안된 경우 매번 각 스템들을 노트북 등에서 일일히 수...
12.📒 Spark(12)
📌 AWS Spark 클러스터 론치 AWS에서 Spark을 실행하기위한 준비 EMR(Elastic MapReduce )위에서 실행하는 것이 일반적이다. EMR AWS의 Hadoop Service(On-demand Hadoop) ->Hadoop(YARN), Spark, Hive, Notebook 등등이 설치되어 제공되는 서비스이다. EC2...
13.📒 Spark(13) - ML(3)
📌 보스턴 주택가격 예측 - Regression 개요 1970년대 미국 인구조사 서비스(US Census Service)에서 Boston 지역의 주택 가격 데이터를 수집한 가격 데이터를 수집한 데이터를 기반으로 모델을 빌드한다. Training Set -> 개별 주택가격의 예측이 아니라 지역별 중간 주택가격 에측이다. Regression 알고리즘 사...
14.📒 Spark(14)

📌 Spark Streaming 실시간 데이터 스트림 처리를 위한 Spark API Kafka, Kinesis, Flume, TCP 소켓 등의 다양한 소스에서 발생하는 데이터를 처리할 수있다. Join, Map, Reduce, Window와 같은 고급 함수 사용 가능 Spark Streaming 동작 방식 데이터를 Micro Batch로 처리 계속해...
15.📒 Spark(15)
📌 Broadcast Variable Broadcast Variable이란 룩업 테이블등을 Broadcasting하여 Shuffling을 막는 방식으로 사용한다. Broadcast Join에서 사용되는 것과 동일한 테크닉이다. 대부분 룩업 테이블(혹은 디멘션 테이블 - 10~20MB)을 Executor로 전송하는데 사용한다. -> 많은 DB에...
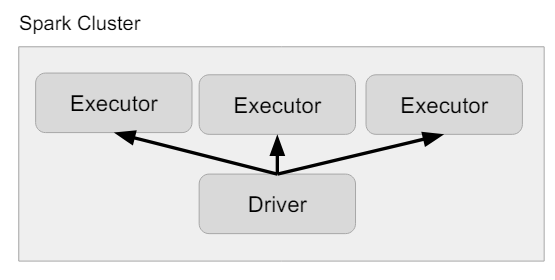
16.📒 Spark(16)
📌 Driver & Executor Driver의 역할 Spark Application = (1 Driver) + (1 + Executor) Driver는 다음 역할을 수행한다. main 함수를 실행하고 SparkSession/SparkContext를 생성한다. 코드를 Task로 변환하여 DAG를 생성한다. 이를 execution/logical...
17.📒 Spark(17)
📌 JVM과 Python 간의 통신 PySpark Driver Python 프로세스 + JVM 프로세스 실제 SparkContext는 JVM쪽에서 생성한다. PySpark Memory Spark은 JVM Application이지만 PySpark은 Python 프로세스이다. -> JVM에서 바로 동작하지 못하기 때문에 JVM 메모리를 사용할 수 없다. ...
18.📒 Spark(18)
📌 Caching과 Persist Caching 자주 사용되는 데이터프레임을 메모리에 유지하여 처리속도가 증가한다. 단 그 데이터프레임이 정말 메모리에 있는지 확인이 필요하다. 어떤 경우에는 다시 계산하는 것이 빠를 수도 있다. 단 메모리 소비를 늘리므로 불필요하게 모든걸 캐싱할 필요는 없다. 어떻게 DataFrame을 Caching하는가 두 ...
19.📒 Spark(19)
📌 Repartition and Coalesce Repartition을 하는 이유 전체적으로 Partition의 수를 늘려 병렬성을 증가시키기 위해서이다. 굉장히 큰 파티션이나 Skew 파티션의 크기를 조절하기 위해서이다. 파티션을 분석 패턴에 맞게 재분배하기 위해서이다. -> Write once, Read many 어떤 DataFrame을 특정 컬럼...
20.📒 Spark(20)
📌 Dynamically optimizing skew joins Dynamically optimizing skew joins란 왜 필요한가? Skew 파티션으로 인한 성능 문제를 해결하기 위해서 필요하다. 한 두개의 오래 걸리는 Task들로 인한 전체 Job/Stage 종료 지연 이 때 disk spill이 발생한다면 더 느려지게 된다....
21.📒 Spark(21)
📌 All about Partitions 세 종류의 Partition(Life cycle of Partitions) 입력 데이터를 로드할 때 파티션 수와 크기 셔플링 후 만들어지는 파티션 수와 크기 데이터를 최종적으로 저장할 때 파티션 수와 크기 파티션의 크기는 128MB - 1GM가 좋다. 1. 입력 데이터를 로드할 때 파티션 수와 크기 기본적으로는 ...
22.📒 Spark(22) - ML(4)
📌 Spark ML 모델 튜닝 Spark ML Tunning 최적의 하이퍼 파라미터 선택 최적의 모델 혹은 모델의 파라미터를 찾는 것이 아주 중요하다. 하나씩 테스트해보는 것 vs. 다수를 동시에 테스트 하는 것 모델 선택의 중요한 부분은 "테스트 방법"이다. -> 교차 검증(Cross Validation)과 홀드 아웃(Train-Validation Sp...