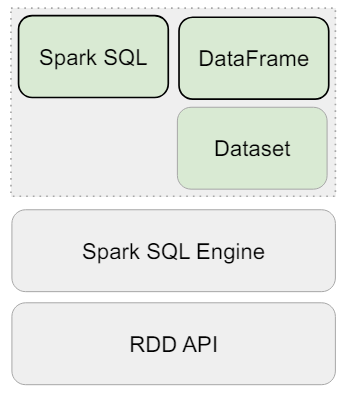
📌 Spark 데이터 구조
- RDD, DataFrame, Dataset (ummutable Distributed Data)
-> 2016년에 DataFrame과 Dataset은 하나의 API로 통합디었다.
-> 모두 파티션으로 나누어서 Spark에서 처리된다.
| RDD | DataFrame | Dataset | |
|---|---|---|---|
| What? | Distributed collection of records (structured & unstructured) | RDD organized into named column | Extension of data frame |
| When | 1.0 | 1.3 | 1.6 |
| Compile type Check | No | No | Yes |
| API | No | Yes | Yes |
| Base Spark SQL | No | Yes | Yes |
| Catalyst Optimizer | No | Yes | Yes |
1. RDD
-
로우레벨 데이터로 클러스터 내의 서버에 분산된 데이터를 지칭한다.
-
레코드별로 존재하지만 스키마가 존재하지 않는다.
- 구조화된 데이터나 비구조화된 데이터 모두 지원한다.
-
프로그래밍 생산성이 떨어진다.
2. DataFrame & Dataset
-
RDD와 달리 필드 정보를 가지고 있다 -> Table
-
Dataset은 Type 정보가 존재하며 컴파일 언어에서 사용가능핟.
-> Scala/Java에서 사용가능 -
PySpark에서는 DataFrame을 사용한다.
1. Code Analysis : 코드 분석 -> 에러 분출
-
Logical Optimization (Catalyst Optimizer) : 코드를 실행할 수 있는 방안을 찾는다.(비용 계산)
-
Physical Planning : 비용이 가장 저렴한 것을 찾아서 RDD 오퍼레이션으로 코드를 만든다.
-
Code Generation (Project Tungsten) : 코드 변환 -> 자바 바이코드
📌 RDD
- 변경이 불가능한 분산 저장된 데이터
- RDD는 다수의 파티션으로 구성되어있다.
- 로우레벨의 함수형 변환을 지원한다. (Map, Filter, FlatMap 등등)
- 일반 Python Data는 Parallelize 함수를 사용하여 RDD로 변환한다.
- 반대로 collect를 사용하여 Python Data로 변환 가능하다.
py_list = [
(1, 2, 3, 'a b c'),
(4, 5, 6, 'd e f'),
(7, 8, 9, 'g h i')
]
rdd = sc.parallelize(py_list)
print(rdd.collect())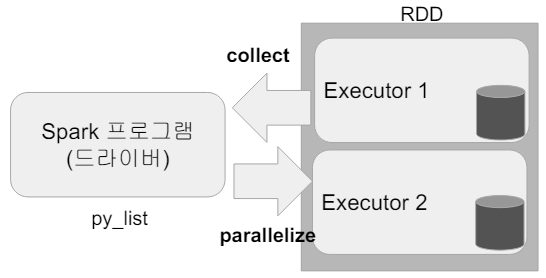
📌 DataFrame
-
변경이 불가능한 분산 저장된 데이터
-
RDD와는 다르게 관계형 DB Table처럼 Column으로 나누어서 저장한다.
- Padas의 DataFrame 혹은 관계형 DB의 Table과 거의 흡사하다.
- 다양한 데이터소스를 지원한다. : HDFS, Hive, 외부 DB, RDD 등등
-
Scala, Java, Python과 같은 언어에서 지원한다.
