알고리즘
1.📒 탐색 알고리즘

첫번째 Index부터 순차적으로 탐색하는 알고리즘리스트의 길이에 비례하는 시간을 소요한다.최악의 경우 모든 원소를 비교해야할 수 있다.장점a. 구현이 쉽다.b. Target Value가 리스트의 앞부분에 있을 경우 효율적이다.단점a. 소요 시간이 리스트의 크기에 따라
2.📒 재귀 알고리즘(Recursive Algorithm)
하나의 함수에서 자신을 다시 호출하여 작업을 수행하는 것많은 종류의 문제를 재귀적으로 해결 가능하다.ex) 이진 트리(Binary Tree)📙 실습 1 - 자연수의 합 구하기(1~n까지 모든 자연수의 합)📙 실습 2 - Factorial(1~n까지 모든 자연수의 곱
3.📒 스택(Stack)
자료를 보관할 수 있는 선형 구조단 넣을 때는 한 쪽 끝에서 밀어 넣어야 하고 -> push 연산꺼낼 때는 같은 쪽에서 뽑아 꺼내야 하는 제약이 존재 -> Pop 연산후입 선출(LIFO) 특징을 가지는 선형 자료 구조스택 언더플로우(stack underflow)\->
4.📒 트리 - 순회
📌 깊이 우선 순회 📙 구현 중위 순회(in-order traversal) : 왼쪽 오른쪽 사이의 자기자신을 순회하는 것 Left subtree 자기 자신 Right subtree 전위 순회(pre-order traversal) : 자기자신을 먼저 순회하는 것 자기 자신 Left subtre...
5. 📒 탐욕법(Greedy)
알고리즘의 각 단계에서 최적이라고 생각되는 것을 선택하는 알고리즘사용 가능 문제\-> 현재의 선택이 마지막 해답의 최적성을 해치지 않을 경우
6.📒 동적계획법(Dynamic Programming)
📌 정의 주어진 최적화 문제를 재귀적인 방식으로 보다 작은 부분 문제로 나누어 부분 문제를 풀어 이 해를 조합하여 전체 문제의 해받에 이르는 방식 즉 하나의 문제를 여러 부분 문제로 바꾸어 푸는 방식인 것이다. 알고리즘의 진행에 따라 탐색해야 할 범위를 동적으로
7.📒 깊이/너비 우선 탐색(DFS/BFS)
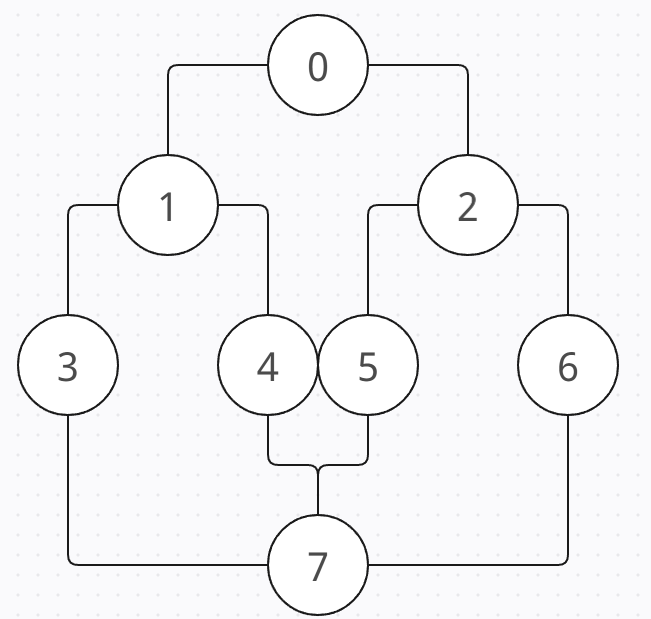
그래프(graphs)정점(vertex, node)과 간선(edge, link)유향(directed)그래프와 무향(undirected)그래프스택(stack)큐(queue)한 정점에서 인접한 모든(방문하지 않은) 정점을 방문하되, 각 인접 정점을 기준으로깊이 우선 탐색을
8.📒 ML
📌 데이터 셋 확인 CSV 📌 결측치 처리 결측치의 범위가 겹치는 부분이 많지 않으며 대부분 평균치를 내기도 어려운 부분인 관계로 모두 삭제하는것으로 결론을 내렸다. 결측치를 채우는 방식도 진행해 보았지만 큰 변화가 없기도 하였다. 📌 전처리 actualdeliverytime에서 createdat를 60으로 나눈 값을 빼준 deliverydura...