[MongoDB] Aggregation 이용해서 컬렉션에 필드 추가하기(feat. lookup, addField)
게시물 스키마
const postSchema = new mongoose.Schema({
title: { type: String, required: true, trim: true },
content: { type: String, required: true, trim: true },
writer: { type: mongoose.Schema.Types.ObjectId, required: true, ref: 'User' },
commentCount: { type: Number, default: 0 },
fileUrl: { type: String },
createdAt: { type: Date, default: Date.now },
views: { type: Number, default: 0 }
});댓글 스키마
const commentSchema = new mongoose.Schema({
text: { type: String, required: true },
writer: { type: mongoose.Schema.Types.ObjectId, required: true, ref: 'User' },
post: { type: mongoose.Schema.Types.ObjectId, required: true, ref: 'Post' },
createdAt: { type: Date, required: true, default: Date.now },
});현재 게시글과 댓글의 스키마는 위와 같은데, 친구가 "글목록에서 글의 댓글 수가 보였으면 좋겠어"라고 요청했다.
일단
- 게시글 컬렉션에
commentCount: { type: Number, default: 0 }필드를 추가하고 - 댓글 생성/삭제에
게시글.commentCount의 수를 증가/감소 시키는 라인을 추가
했지만,
이미 존재하는 게시글들에 대해서는 commentCount가 0이 아닌 현재 댓글 수가 들어가야 한다는 문제가 있다.
이 일을 어찌할꼬..
post id로 조인을 해서 댓글 수를 확인하고.. 그걸 posts에 추가를 해야겠는데..
쿼리를 날려서 해결해야 한다는 생각은 들었지만 NoSQL인 몽고에서 그게 가능할까?
하지만 프로그래밍 세상에서는 내가 찾는 기능은 항상 존재했었기에..
aggregation이라는 것을 마주할 수 있었다.
공식 문서를 대충 둘러보고 나니
$lookup을 이용해서 다른 컬렉션과 join이 가능하고, $addfields로 필드를 추가할 수 있겠구나
감이 잡혔다.
이제 사용법을 알아보자.
영어는 모두 공식문서에서 긁어왔다.
MongoDB 문서
Aggregation?
In the
db.collection.aggregate()method anddb.aggregate()method, pipeline stages appear in an array. Documents pass through the stages in sequence.
두 메서드에서 파이프라인 스테이지가 배열로 존재하고, 문서는 순서대로 파이프라인을 통과한다는 말인 것 같다. (filter 같은 느낌인가?)
pipeline
aggregation 파이프라인은 문서를 처리하는 하나 이상의 스테이지로 구성된다. ($로 시작하는 것들을 스테이지라고 하는 듯)
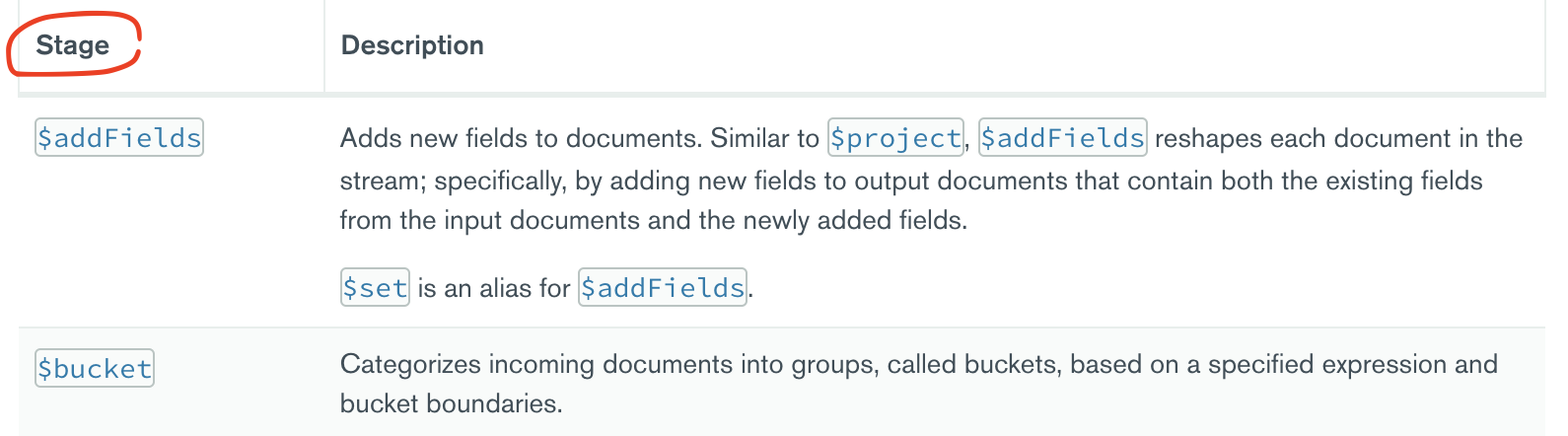
- Each stage performs an operation on the input documents. For example, a stage can filter documents, group documents, and calculate values.
- The documents that are output from a stage are passed to the next stage.
- An aggregation pipeline can return results for groups of documents. For example, return the total, average, maximum, and minimum values.
- 각 스테이지는 입력 문서에 대해 작업을 수행(필터링하고, 모으고, 값을 계산하는 등)
- 스테이지의 결과로 나온 문서는 다음 스테이지로 넘어감
- 통합 파이프라인은 문서 그룹에 대한 결과를 반환 가능(합계, 평균, 최대/최소값 등)
간단한 예시 하나만 봅시다.
orders라는 피자 주문 컬렉션이 있다고 치자.
medium 사이즈 피자의 종류별 판매량을 구하는 방법은 다음과 같다.
db.orders.aggregate( [
// Stage 1: Filter pizza order documents by pizza size
{
$match: { size: "medium" }
},
// Stage 2: Group remaining documents by pizza name and calculate total quantity
{
$group: { _id: "$name", totalQuantity: { $sum: "$quantity" } }
}
] )스테이지1에서 사이즈로 필터링한 후 매치되는 결과를 스테이지2로 넘긴다.
스테이지2에서는 종류별로 그룹을 묶고 각 그룹의 판매량 합계를 계산한다.
결과 예시:
[
{ _id: 'Cheese', totalQuantity: 50 },
{ _id: 'Vegan', totalQuantity: 10 },
{ _id: 'Pepperoni', totalQuantity: 20 }
]$lookup
자 이제 나에게 필요한 스테이지의 사용법을 알아보자.
Performs a left outer join to an unsharded collection in the same database to filter in documents from the "joined" collection for processing. To each input document, the
$lookupstage adds a new array field whose elements are the matching documents from the "joined" collection. The$lookupstage passes these reshaped documents to the next stage.
조인된 컬렉션에서 문서를 필터링하기 위해서, DB 내의 공유되지 않는 컬렉션에 대해 left outer join을 수행함
조인은 둘 이상의 테이블을 합치는 것이고, left outer join은 왼쪽 테이블(아래 예제에서 A 테이블)을 기준으로 자신에게 존재하는 것을 모두 가져온다고 생각하면 된다. B테이블과 연결이 없는 행은 B테이블의 필드를 모두 NULL로 표현한다.
FROM A LEFT OUTER JOIN B
syntax
{
$lookup:
{
from: <collection to join>,
localField: <field from the input documents>,
foreignField: <field from the documents of the "from" collection>,
as: <output array field>
}
}from: 조인될 컬렉션을 말한다. (나의 경우 댓글 컬렉션)
localField: 현재 컬렉션의 문서에서 검색에 사용할 필드 (나의 경우 Post._id), 없으면 null로 처리
foreignField: from 컬렉션의 문서에서 검색에 사용할 필드(나의 경우 Comment.post), 없으면 null로 처리
as: 해당 문서에 추가할 새 배열 필드의 이름. 이 필드에는 매칭된 문서(조인된 컬렉션)가 들어있다.
아래는 의사 SQL
SELECT *, <output array field>
FROM collection
WHERE <output array field> IN (
SELECT *
FROM <collection to join>
WHERE <foreignField> = <collection.localField>
);음.. join 컬렉션에서 foreignField와 localField가 일치하는 것들을 가져온 후 그것들을 배열로 리턴하는구나~
좋아 다음
$addFields
Adds new fields to documents. $addFields outputs documents that contain all existing fields from the input documents and newly added fields.
문서에 새로운 필드를 추가한다.
입력 문서와 새로 추가된 필드에 존재하는 모든 필드를 포함하는 문서를 출력한다.?
syntax
{ $addFields: { <newField>: <expression>, ... } }예시를 보자.
다음과 같은 scores 컬렉션이 있다.
{
_id: 1,
student: "Maya",
homework: [ 10, 5, 10 ]
}
{
_id: 2,
student: "Ryan",
homework: [ 5, 6, 5 ]
}homework의 합계 필드를 추가해보자.
db.scores.aggregate( [
{
$addFields: {
totalHomework: { $sum: "$homework" }
}
}
] )결과:
{
"_id" : 1,
"student" : "Maya",
"homework" : [ 10, 5, 10 ],
"totalHomework" : 25
}
{
"_id" : 2,
"student" : "Ryan",
"homework" : [ 5, 6, 5 ],
"totalHomework" : 16
}적용
좋아~ 나는 post id로 lookup을 수행한 다음, addFields에서 sum 대신 count를 이용하면 게시물 마다 댓글수를 구할 수 있겠다.
시간이 늦었으니 적용은 내일 해보자.
~다음날~
$count가 아닌 $size를 이용하면 배열의 크기를 구할 수 있다.
정리해보면
1. lookup을 통해 조인을 수행하여 댓글이 담긴 배열 필드를 생성한다.
2. addField에서 size를 이용하여 배열의 크기를 값으로 하는 필드를 생성한다.
3. unset을 이용하여 lookup에서 생성된 배열 필드는 지워준다.
4. out을 통해 변경 내용을 posts 컬렉션에 적용한다.
아래는 댓글 수 표시를 위해 작성한 aggregation 스테이지 입니다.
db.posts.aggregate([
{
'$lookup': {
'from': 'comments',
'localField': '_id',
'foreignField': 'post',
'as': 'tmp'
}
}, {
'$addFields': {
'commentCount': {
'$size': '$tmp'
}
}
}, {
'$unset': 'tmp'
}, {
'$out': 'posts'
}
])참고: aggregation은 DB 선택 후 Atlas -> Collections -> Aggregation으로 이동하면, 스테이지를 추가하면서 각 스테이지가 수행되었을 때의 프리뷰를 확인할 수 있다.