[논문 리뷰] Attention - Neural Machine Translation by Jointly Learning to Align and Translate (2014)
[논문 리뷰]
Paper: Neural Machine Translation by Jointly Learning to Align and Translate
🔍1. Introduction
NMT(신경망 기계 번역, Neural Machine Translation)는 당시 최근 제안된 새로운 번역 방법임.
당시 기존 번역 시스템
: 구문 기반의 번역 시스템
= 개별의 작은 하위 요소로 구성됨.
신경망 기계 번역 시스템
: 단일 신경망으로, 크고 복합적인 신경망을 만들어, 문장을 읽고, 정확한 해석을 출력하고자 함.
신경망 기계 번역 모델의 대부분은 "인코더-디코더" 구조에 기반하고 있음.
인코더 신경망은 source sentence(소스 문장)를 fixed-length vector(고정 길이 벡터)로 인코딩함.
또한, 디코더는 인코더 벡터로부터 번역을 출력함.
이 인코더-디코더 시스템은 소스 문장이 주어졌을 때, 정확한 번역이 생성될 확률을 최대화하도록, 공동으로 학습됨.
단, 인코더-디코더 방식은 문제가 존재.
바로 신경망이 모든 소스 문장의 필수적인 정보들을 fixed-length vector(고정 길이 벡터)로 압축해야 한다는 것.
특히, 학습 과정의 말뭉치(corpus) 데이터보다 문장이 길면, 처리하기가 어려워질 수 있음.
실제 성능 측정 시, 입력 문장의 길이가 길어질수록, 성능이 더 나빠지는 것을 확인할 수 있었음.
해당 문제를 해결하기 위해...
인코더-디코더 모델을 확장한 방식을 제안하게 됨.
이는 동시에 align(정렬)과 translate(번역)을 학습할 수 있는 모델임.
번역 시에, 모델이 단어를 생성할 때, 소스 문장에서 가장 관련도가 높은 정보가 집중된 곳의 집합을 검색함. (=Attention!)
그 후 이러한 소스 문장의 위치와 연관된 context vector와 이전에 생성된 타겟 모든 타겟 단어들에 기반해서 타겟 단어를 예측함.
가장 중요한 것은, 이 방식의 경우, 입력 문장을 고정 길이 벡터로 인코딩하려고 하지 않는다는 것.
대신에, 입력 문장을 벡터들의 시퀀스로 인코딩을 하고, 번역 디코딩을 할 때, 이 벡터들의 부분 집합을 선택한다는 것.
이를 통해, 모델이 긴 문장들을 더 효율적으로 처리할 수 있음.
✅2. BACKGROUND: NEURAL MACHINE TRANSLATION
번역이라는 것은, 확률적 관점(probabilistic perspective)에서 타겟 문장 y를 찾는 것과 동일함. (p(y|x)-소스 문장 x가 주어졌을 때, 타겟 문장 y의 조건부 확률을 최대화 하는)
NMT(신경망 기계 번역, NEURAL MACHINE TRANSLATION) 방식은 병렬 훈련 말뭉치(parallel training corpus)를 사용해서 문장 쌍의 조건부 확률을 최대화하는 모델을 적용시킴.
이렇게 되면, 소스 문장이 주어졌을 때, 조건부 확률을 최대화하는 문장을 서칭해서 이에 대응하는 번역을 할 수 있음.
RNN ENCODER–DECODER
RNN Encoder-Decoder는 정렬과 번역을 동시에 학습하는 아키텍처를 만드는 것의 기반이 됨.
Encoder-Decoder 프레임워크에서,
인코더는 입력 문장을 벡터들의 시퀀스 x = (x1, •••, xTx)로 읽은 후, 벡터 c로 인코딩 함.
대표적인 접근 방식: RNN
- h = f(xt, ht-1): 시간 t에서 은닉 상태 ht는 입력 벡터 xt와 이전 은닉 상태 ht-1을 통해서 계산됨.
- c = q(h1, •••, hTx): 인코더의 은닉 상태 시퀀스 (h1, •••, hTx)에서 벡터 c 생성.
*f, q는 비선형 함수임
디코더는 context vector c와 이전에 예측된 단어 {y1, •••, yt'-1}를 기반으로 다음 단어인 yt'을 예측하도록 종종 학습됨.
다시 말해, 디코더는 y에 대한 확률을 조건부 확률의 순차적 분해를 통해서 정의한다는 것.
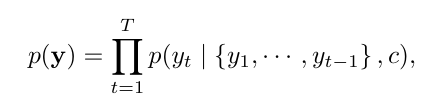 RNN 사용 시, 각 조건부 확률은 하단 식과 같음.
RNN 사용 시, 각 조건부 확률은 하단 식과 같음.
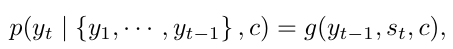
- g = yt의 확률을 출력하는 비선형, multi-layered(다층) 함수.
- st = RNN의 은닉 상태.
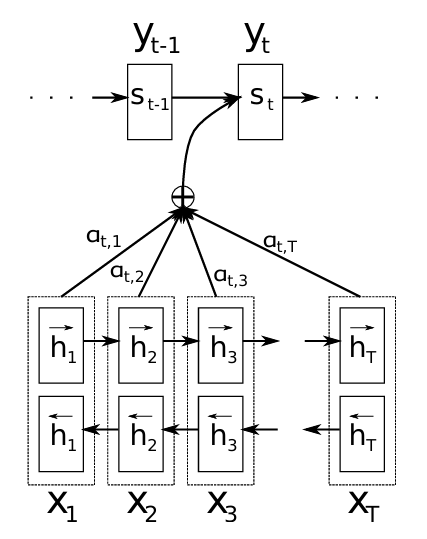
✅3. LEARNING TO ALIGN AND TRANSLATE
NMT를 위한 새로운 아키텍처.
인코더로 쌍방향 RNN을 사용하여, 입력 문장을 앞→뒤, 뒤→앞으로 둘 다 읽어서 문맥을 효과적으로 파악.
디코딩 과정에서, 소스 문장의 특정 위치를 선택적으로 활용함.
DECODER: GENERAL DESCRIPTION
새로운 모델 아키텍처에서,
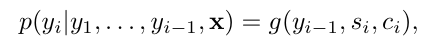
각 조건부 확률은 위와 같이 정의할 수 있음.
- si: 시간 i에서의 RNN 은닉 상태
- ci: 타겟 단어 yi에 해당하는 context vector
은닉 상태 si는
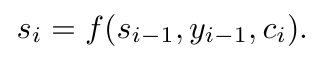 이렇게 정의되는데, 즉, si는
이렇게 정의되는데, 즉, si는
- si-1 = 이전의 은닉 승태
- yi-1 = 이전 타겟 단어
- ci = 컨텍스트 벡터
에 의해 결정된다는 것.
컨텍스트 벡터 ci는
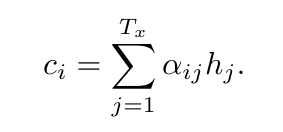 이렇게 주석 hj의 가중 합으로 계산 됨.
이렇게 주석 hj의 가중 합으로 계산 됨.
- hi = 각 주석(입력 시퀀스의 i번째 단어 주변 정보에 focus)
- aij = hj의 가중치(hj의 중요도를 확률적으로 나타내줌)
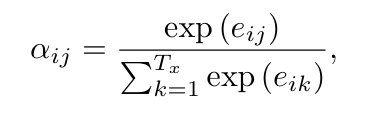
- eij = 정렬 모델(alignment model)을 통해 계산된 값. 입력 문장의 위치 j 주변 정보 & 출력 단어 yi 간의 일치도 평가
alignment(정렬) 모델 a는 피드포워드 신경망으로 매개변수화되고, 다른 요소들과 함께 공동 학습됨.
그리고 정렬 모델은 소프트 정렬을 직접 계산하는데, 이는 전체 모델의 학습에도 사용됨.
aij는 이전 은닉 상태인 si-1이 다음 상태인 si와 yi를 만들 때, 주석 hj의 중요성을 반영함.
이 요소가, 디코더에서 "attention mechanism"을 구현하는 것.
attention mechanism에서 디코더는 소스 문장의 특정 부분을 주의하며, 인코더가 소스 문장의 모든 정보를 고정된 길이 벡터로 압축해야 하는 부담을 줄여줌.
이를 통해 정보가 주석 시퀀스에 분산되고, 디코더가 선택적으로 이것을 검색하는 것.
ENCODER: BIDIRECTIONAL RNN FOR ANNOTATING SEQUENCES
입력 시퀀스 x를 x1부터 xTx까지 순서대로 읽는 일반적인 RNN 방식과 달리,
본 방식에서는 입력을 양방향(순방향 & 역방향)으로 처리해서 각 주변 단어에 대해 앞뒤 문맥 정보를 모두 포함하는 주석 hj를 생성함.
RNN이라는 것이 최근의 입력을 더 잘 표현하는 경향이 있으므로, 주석 hj는 특이 단어 xj 주변 단어들에 더 집중할 수 있게 되는 것. 그리고 이런 주석 시퀀스들은 디코더와 정렬 모델에서 context vector를 계산할 때 사용됨.
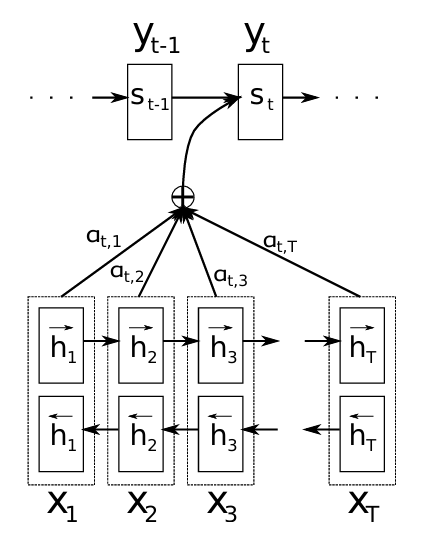 ↑ 어텐션 메커니즘을 적용한 RNN Encoder-Decoder 구조
↑ 어텐션 메커니즘을 적용한 RNN Encoder-Decoder 구조
✅4. EXPERIMENT
실험은 영어-프랑스어 번역 작업을 바탕으로 진행되었음.
또한, 비교를 위해서 RNN Encoder-Decoder의 성능도 같이 산출함.
당연히, 두 모델 모두 같은 학습 과정 및 데이터셋 사용.
ACL WMT'14 병렬 말뭉치(corpus) 데이터를 사용함.
RNN Encoder-Decoder 모델(기존 모델)과 RNNsearch 모델(본 논문에서 제안된 new 모델)을 학습하였고, 문장 길이가 최대 30/50 단어인 경우로 학습함.
RNN Encoder-Decoder 모델의 경우 인코더와 디코더가 각 1,000개의 hidden units으로 구성되고,
RNNsearch 모델의 경우 인코더는 각 1,000개의 hidden units를 가진 순방향 및 역방향 RNN으로, 디코더 또한 1,000개의 hidden units으로 구성됨.
또한, 각 모델은 SGD(미니배치 확률적 경사 하강법, minibatch Stochastic Gradient Descent)알고리즘과 Adadelta(2012)알고리즘을 함께 사용함.
모델 학습 이후, beam search(빔 서치)를 사용해서 조건부 확률을 최대화하는 번역을 찾고자 함.
✅5. RESULTS
QUANTITATIVE RESULTS(정량적)
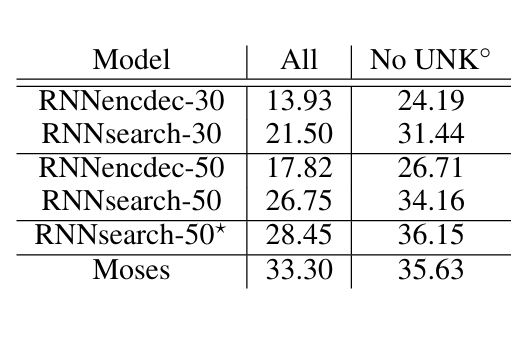 ↑ 테스트 세트에서 학습된 모델들의 BLEU 점수
↑ 테스트 세트에서 학습된 모델들의 BLEU 점수
(전체 문장과, UNK(알 수 없는 단어)가 없는 문장에 대해 각각 성능을 산출함)
RNNsearch가 RNN Encoder-Decoder보다 성능이 훨씬 더 좋게 나타남을 확인할 수 있음.
그리고, 기존 구문 기반 번역 시스템인 Moses의 성능과 비슷한 수준에 있다는 것.
Moses는 RNNsearch와 RNN Encoder-Decoder의 학습 과정에서 사용한 병렬 말뭉치(corpus) 이외에도 418M 단어로 이루어진 별도의 단일 corpus를 추가로 사용했기 때문.
즉, RNNsearch는 별도의 단일 언어 corpus 없이도, Moses와 비슷한 수준의 성능을 이뤄낸 것.
앞서, 본 RNNsearch 모델이 등장한 이유 중 하나가 기존 RNN Encoder-Decoder 접근 방식이 고정 길이 context vector를 사용한다는 문제였음.
그리고 이 문제가 긴 문장에서 성능 저하를 일으키는 것이라고 생각했음.
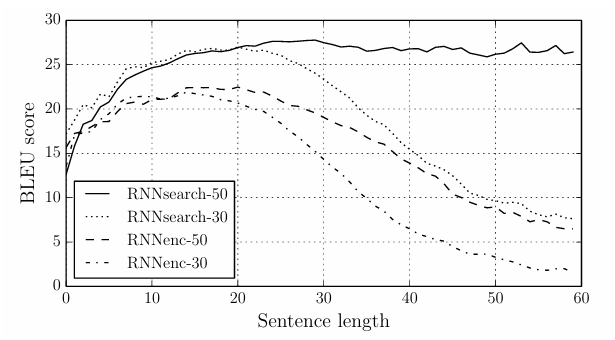 ↑ 문장 길이에 따른 성능 결과
↑ 문장 길이에 따른 성능 결과
성능 실험 결과, RNN Encoder-Decoder는 문장 길이가 길어질수록 성능이 급격하게 저하되는 것을 확인할 수 있음.
다만, RNNsearch 모델은 문장 길이가 길어져도, 성능 산출에 확실히 더 강한 것을 보임.
(RNNsearch-30이 위 그래프에서 급격히 성능이 떨어지는 것 같은데? → RNNsearch-30은 최대 30 단어의 문장으로 학습되었기 때문임. 따라서 30단어 초과하는 문장에서 성능 저하가 발생하는 것은 당연한 것. 따라서 문제 없음.)
QUALITATIVE ANALYSIS(정성적)
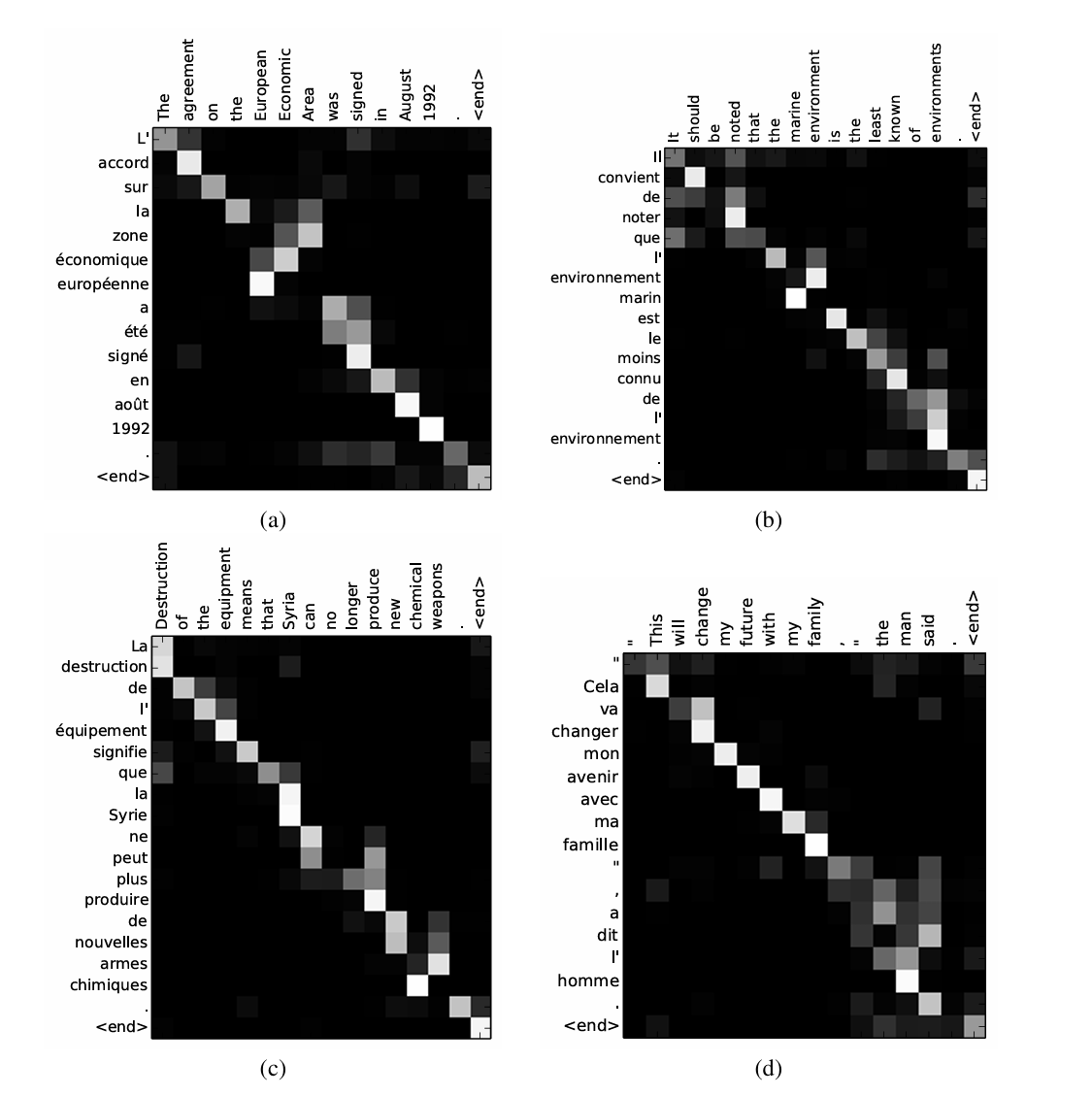 ↑ RNNsearch-50이 발견한 정렬 예시
↑ RNNsearch-50이 발견한 정렬 예시
- x축은 소스 문장(영어)의 단어, y축은 생성된 번역(프랑스어)의 단어
- 각 픽셀: 주석 가중치 aij(i번째 타겟 단어 & j번째 소스 단어 간 주석 가중치)
- 검정색: 0 (낮은 가중치)
- 흰색 : 1 (높은 가중치)
- (a) = 무작위로 선택된 문장 하나의 정렬
- (b)~(d) = 테스트 세트에서 UNK(알 수 없는 단어)가 없음과 동시에 문장 길이가 10~20 단어인 문장 중 무작위로 선택된 세 가지의 정렬
위 정렬을 통해, 영어와 프랑스어 간 단어 정렬이 monotonic(단조적)임을 확인할 수 있음.
각 행렬의 대각선에 가중치가 높게 나타남.
또한, 소프트 정렬 방식을 통해(하드 정렬과 달리)단어 간 관계를 고려해서 번역을 좀 더 정확히 구현해 낼 수 있음. 그리고, 소스와 타겟 구문의 길이가 서로 달라도(일부 단어를 NULL(빈 상태)로 매핑해야 하는 비직관적인 방식과 달리) 직관적인 방식으로 처리 가능함.
↑ 문장 길이에 따른 성능 결과
위에서 다시 확인할 수 있듯, RNNsearch는 긴 문장 번역에도 우수한 성능을 보임.
특히 RNNsearch가 긴 문장을 모두 고정 길이 벡터로 인코딩하지 않고, 특정 단어의 주변 입력 문장 부분만 잘 인코딩하면 되기 때문임.
 ↑ (1)
↑ (1)
 ↑ (2)
↑ (2)
위 문장(1), (2)를
RNN Encoder-Decoder는 하단과 같이 번역함.
 ↑ (1)
↑ (1)
 ↑ (2)
↑ (2)
밑줄 친 부분부터는 해석을 잘못한 것을 확인할 수 있음.
단, RNNsearch-50은 입력 문장을 정확히 번역해낸 것을 확인할 수 있음. (하단 참조)
 ↑ (1)
↑ (1)
 ↑ (2)
↑ (2)
이렇게, RNNsearch 모델이 긴 문장 번역에 있어서 기존 모델보다 훨씬 더 좋은 성능을 구현할 수 있음을 확인할 수 있음.
🔚6. CONCLUSION
기존 NMT(신경망 기계 번역) 방식인 Encoder-Decoder는 입력 문장 전체를 고정 길이 벡터로 인코딩하고, 이걸 바탕으로 디코딩함.
→ 긴 문장 번역 시 어려움 존재
따라서, 새로운 아키텍처인 RNNsearch 제안.
기본 RNN Encoder-Decoder 방식을 확장해서, 소프트 정렬 방식을 통해 입력 단어 집합을 검색할 수 있도록 함.
→ 소스 문장 전체를 고정 길이 벡터로 압축해야하는 문제를 없애고, 타겟 단어를 만들기 위해 관련 정보에만 집중할 수 있게 됨.
→ 긴 문장에서도 좋은 성능을 보임.
또한, 기존 기계 번역 시스템과 달리, 정렬 구조를 포함한 번역 시스템의 모든 요소가 정확한 번역을 만들 수 있도록 하는 로그 확률을 최대화할 수 있도록 학습됨.
본 논문 진행된 실험에서도 RNNsearch는 우수한 성능을 보였으며, 기존 구문 기반 번역 시스템과 유사한 수준의 성능 또한 구현해 내는 성과를 보임.
