[논문 리뷰]
1.[논문 리뷰] InceptionV2/3 - Rethinking the Inception Architecture for Computer Vision (2015)
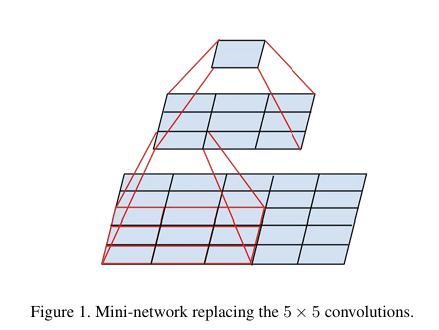
서론 (Introduction)딥러닝과 컴퓨터 비전에서의 Inception 아키텍처 소개논문의 목표 및 문제의식Inception v2: 개선된 아키텍처2.1 기존 모델의 한계2.2 주요 개선 사항Batch NormalizationFactorized Convolution
2.[논문 리뷰] SPPNet - Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition (2014)
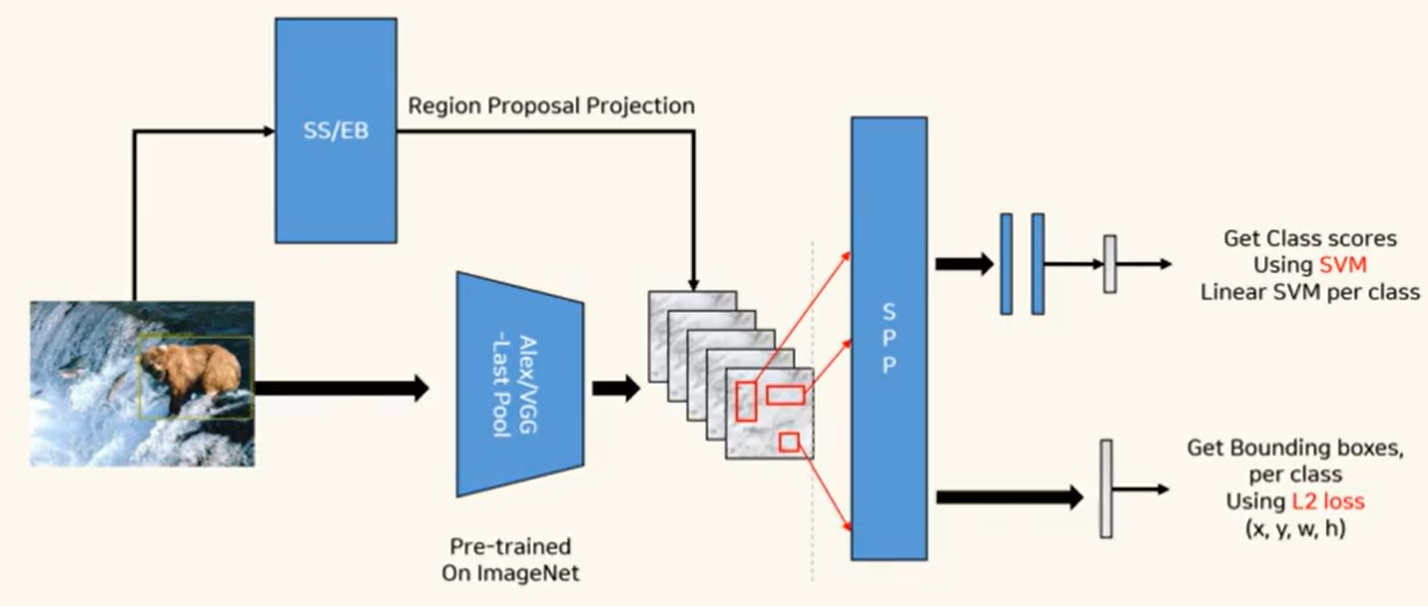
Paper: Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition : 기존 CNN은 고정된 입력 이미지 사이즈\* 가 필요했음. (ex. 224x224)하지만 이는, input 이미지
3.[논문 리뷰] MobileNets - MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications (2017)
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications 🔍1. Introduction 기존 CNN: 기술이 발전될 수록 더 깊고 더 복잡한 신경망을 만들어서 정확도(accu
4.[논문 리뷰] Seq2Seq - Sequence to Sequence Learning with Neural Networks (2014)
🔍1. Introduction DNN DNN: 음성 인식이나 visual 객체 인식과 같은 어려운 문제에서도 훌륭한 성능을 보이는 매우 강력한 머신 러닝 모델. 특징: DNN은 적은 단계로 임의의 병렬 연산을 수행할 수 있을 만큼 유연하고 강력함. 다만, 고정된 크기
5.[논문 리뷰] Attention - Neural Machine Translation by Jointly Learning to Align and Translate (2014)
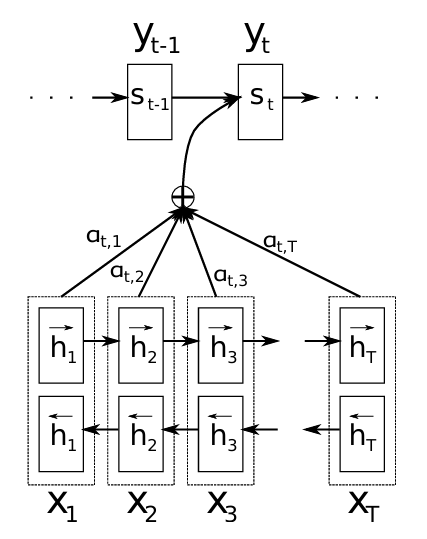
Paper: Neural Machine Translation by Jointly Learning to Align and TranslateNMT(신경망 기계 번역, Neural Machine Translation)는 당시 최근 제안된 새로운 번역 방법임.당시 기존 번역
6.[논문 리뷰] Transformer - Attention Is All You Need (2017)
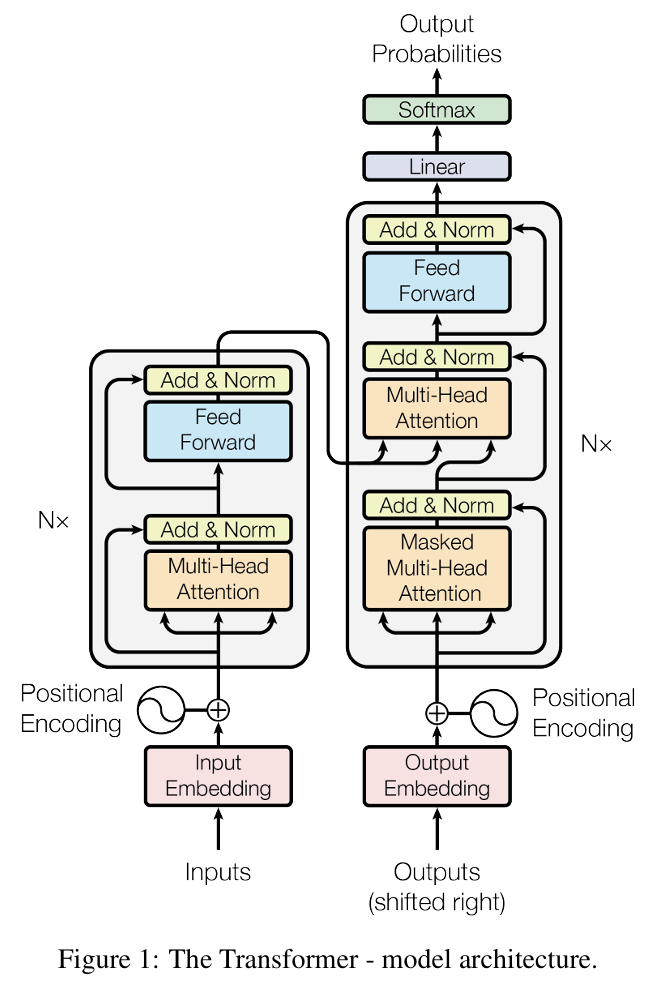
Paper: Attention Is All You NeedRNN(순환 신경망, Recurrent Neural Networks), LSTM(Long Short-Term Memory), GRU(게이트 순환 신경망, Gated Recurrent Neural Network)은
7.[논문 리뷰] ELMo - Deep contextualized word representations (2018)
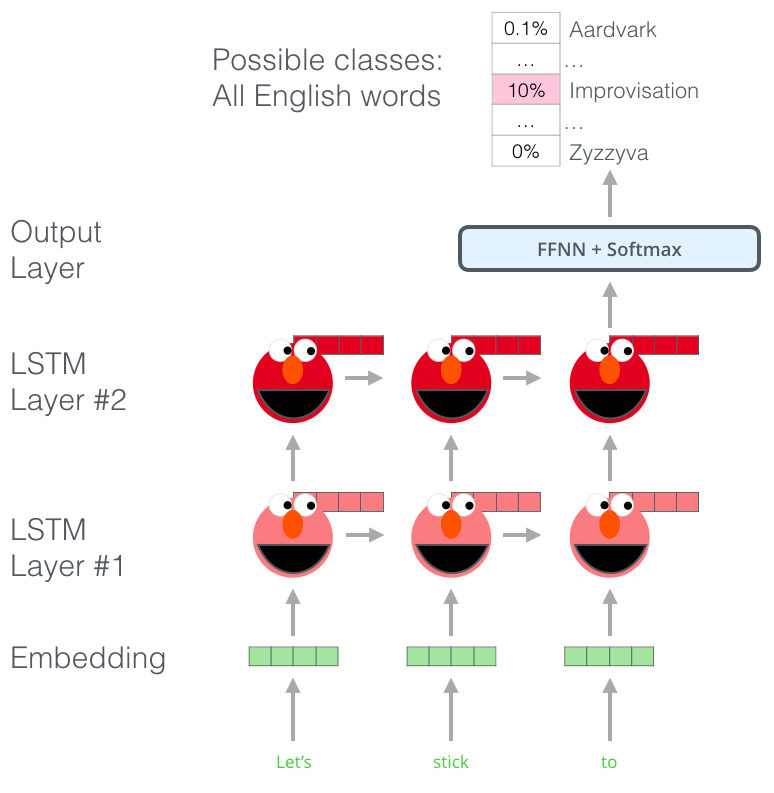
Paper: Deep contextualized word representationsPre-trained word representations은 많은 neural language 이해 모델에서 중요한 부분임.단, 이는 high quality 표현을 학습하는 데에는 좀
8.[논문 리뷰] Faster R-CNN - Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (2015)
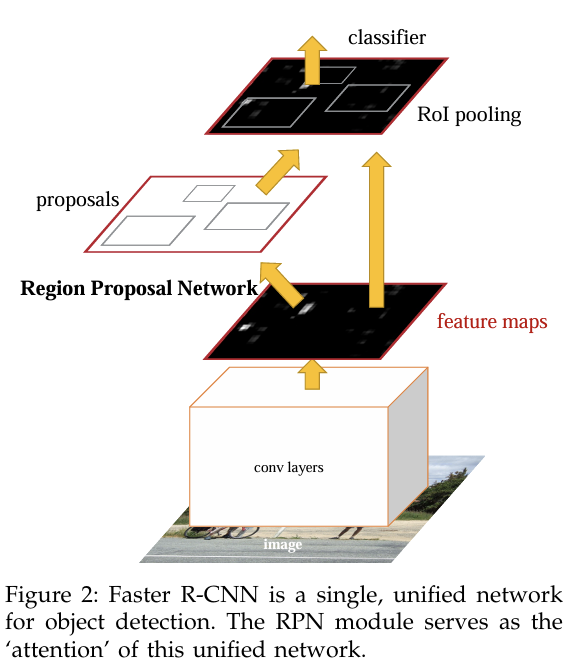
Paper: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks최근의 객체 탐지 분야의 발전은 Region Proposal Methods와 Region-based convoluti
9.[논문 리뷰] U-Net - U-Net: Convolutional Networks for Biomedical Image Segmentation (2015)

Paper: U-Net: Convolutional Networks for Biomedical Image Segmentation 🔍1. Introduction Deep convolution networks는 최근 많은 visual recognition task에서 높
10.[논문 리뷰] YOLO - You Only Look Once: Unified, Real-Time Object Detection (2015)

Paper:You Only Look Once: Unified, Real-Time Object Detection
11.[논문 리뷰] GPT-1 - Improving Language Understanding by Generative Pre-Training (2018)
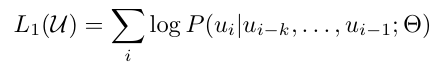
Paper: Improving Language Understanding by Generative Pre-Training
12.[논문 리뷰] BERT - BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(2018)
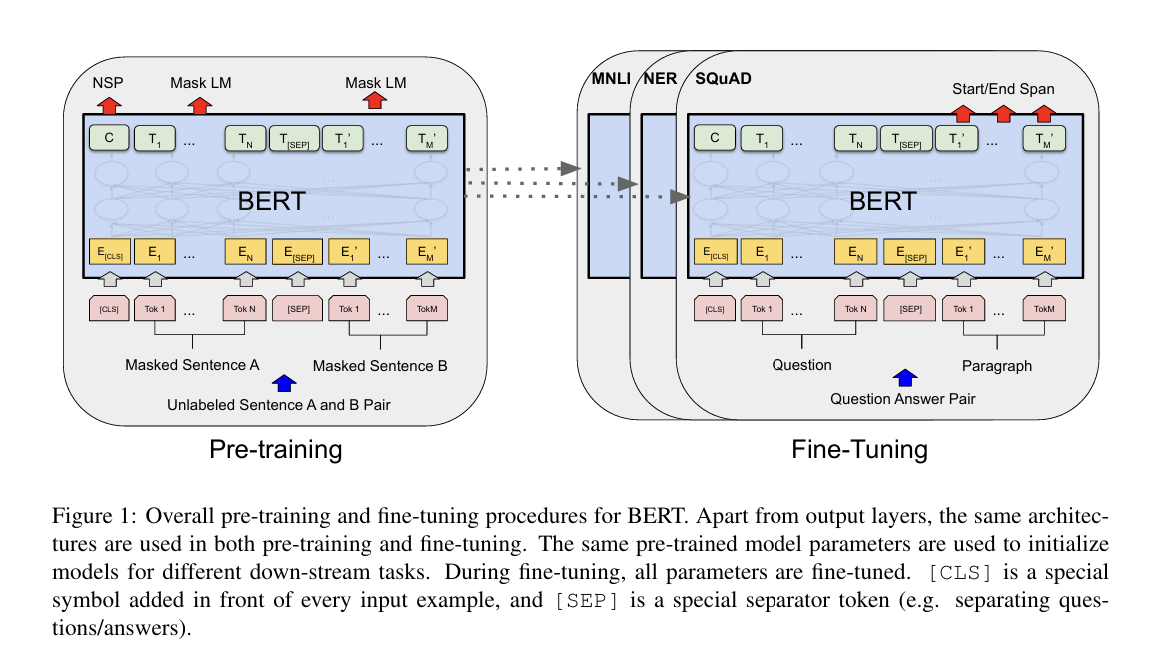
Paper: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding🔍1. Introduction
13.[논문 리뷰] RoBERTa - RoBERTa: ARobustly Optimized BERT Pretraining Approach(2019)
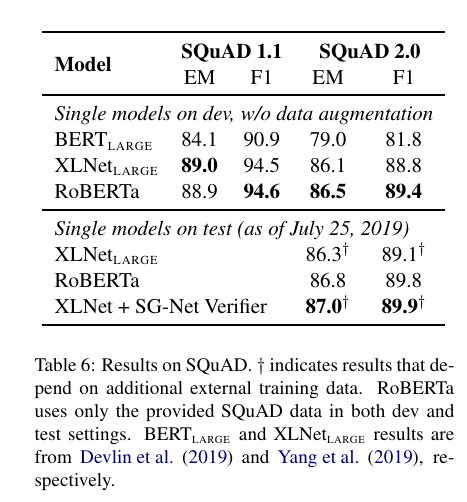
Paper: RoBERTa: ARobustly Optimized BERT Pretraining Approach 🔍1. Introduction ELMo, GPT, BERT, XLM, XLNet과 같은 기존 Self-training methods는 성능 향상을 크게 이
14.[논문 리뷰] RetinaNet - Focal Loss for Dense Object Detection(2017)
Paper: Focal Loss for Dense Object Detection현재 최고의 객체 탐지(Object Detection) 모델들은 two-stage 기반의 방식으로 구성됨.(ex. R-CNN)stage 1: 객체의 후보 영역을 생성함stage 2: 후보 영
15.[논문 리뷰] EfficientNet - EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (2019)
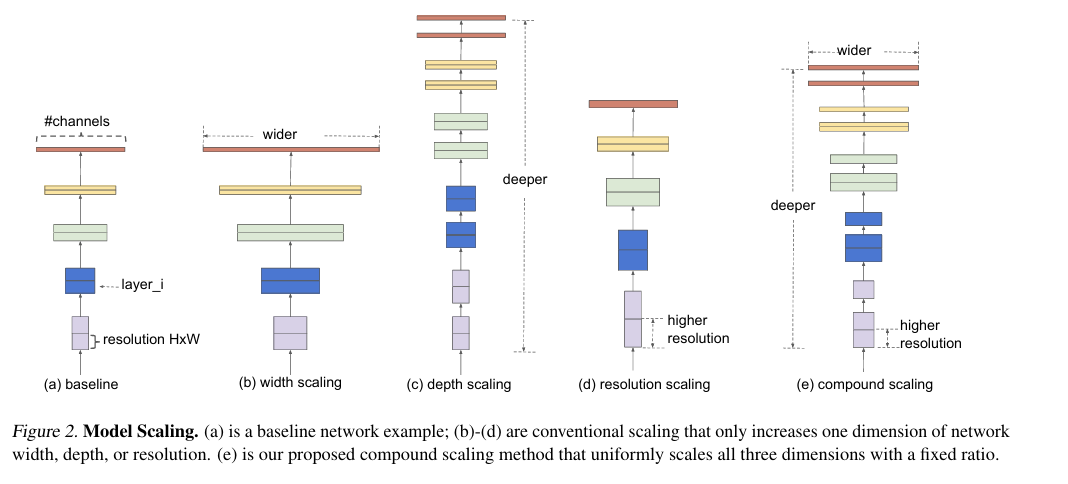
Paper: EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
16.[논문 리뷰] XLNet - XLNet: Generalized Autoregressive Pretraining for Language Understanding (2019)
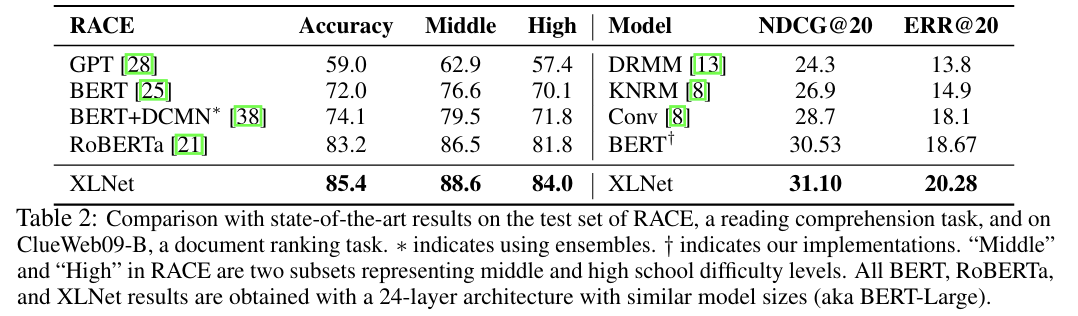
Paper: XLNet: Generalized Autoregressive Pretraining for Language Understanding
17.[논문 리뷰] Mask R-CNN - Mask R-CNN (2017)

Paper: Mask R-CNN
18.[논문 리뷰] BART - BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension (2019)
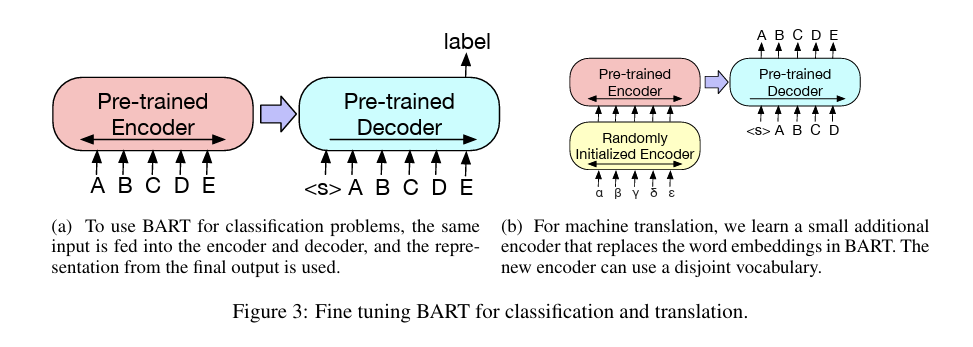
Paper: BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
19.[논문 리뷰] Grad-CAM - Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization (2017)
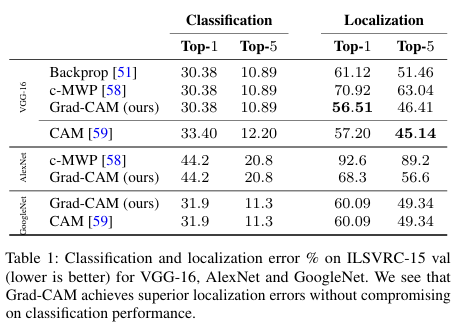
Paper: Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization 🔍1. Introduction CNN 기반 딥러닝 모델 : 이미지 분류, 객체 탐지, 세그멘테이션, 이미지
20.[논문 리뷰] ViT - An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (2021)
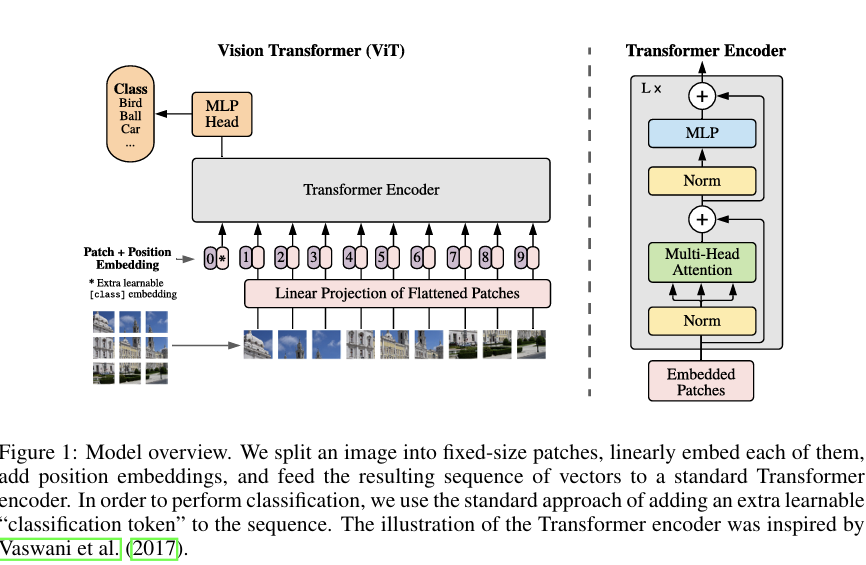
Paper: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
21.[논문 리뷰] DETR - End-to-End Object Detection with Transformers (2020)
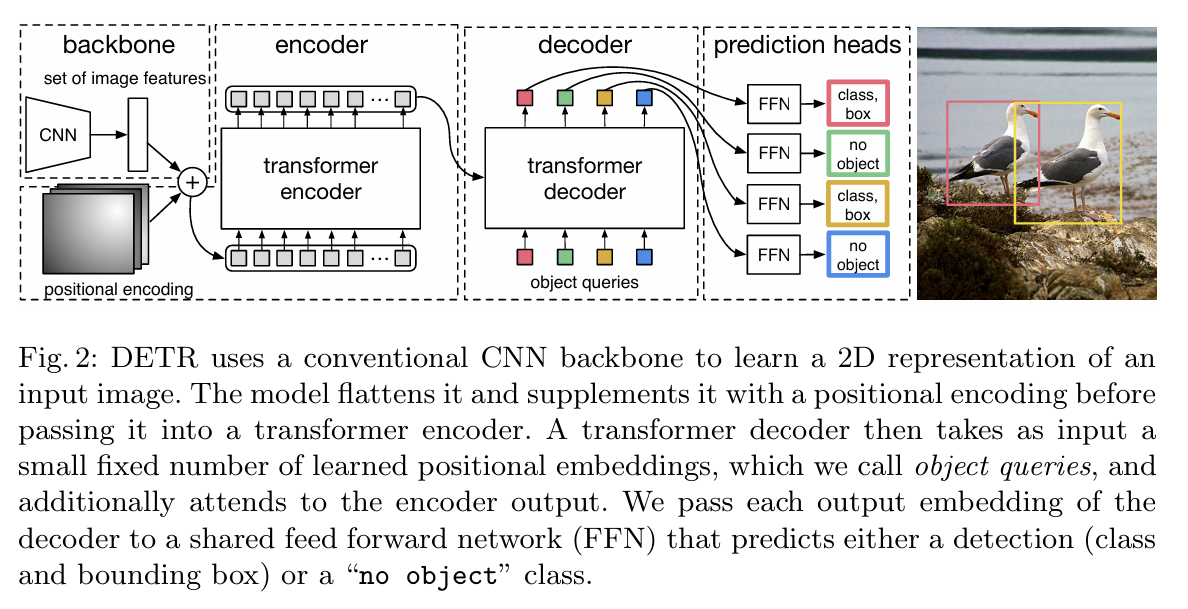
Paper: End-to-End Object Detection with Transformers
22.[논문 리뷰] DINO - Emerging Properties in Self-Supervised Vision Transformers (2021)

Paper: [Emerging Properties in Self-Supervised Vision Transformers ](https://arxiv.org/abs/2104.14294)
23.[논문 리뷰] Stable Diffusion - High-Resolution Image Synthesis with Latent Diffusion Models(2022)

Paper: High-Resolution Image Synthesis with Latent Diffusion Models
24.[논문 리뷰] 자율주행 시스템의 SOTIF 확보를 위한 STPA 안전 분석 및 V & V 방법론
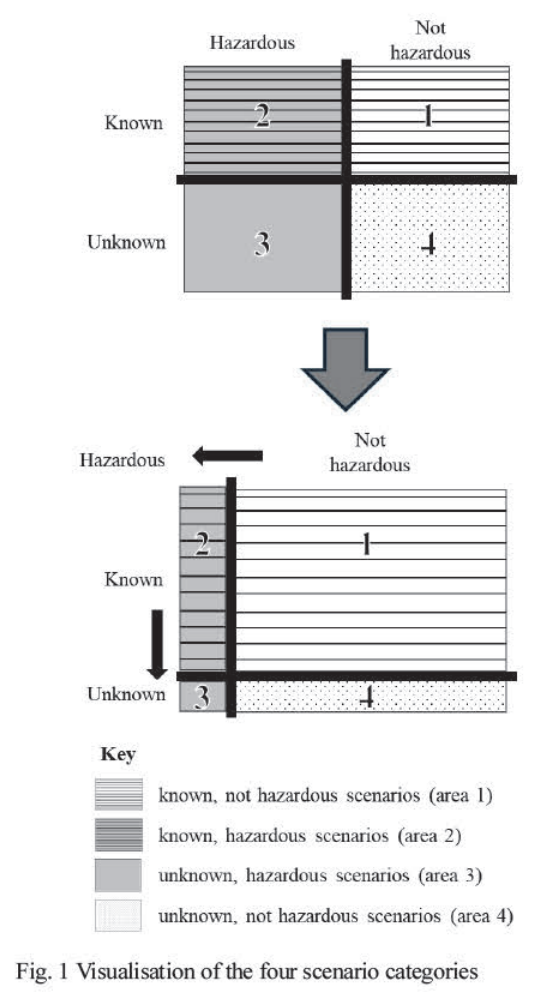
Paper: 자율주행 시스템의 SOTIF 확보를 위한 STPA 안전 분석 및 V & V 방법론(한승재, 변진규, 안수민, 유진우. (2025). 자율주행 시스템의 SOTIF 확보를 위한 STPA 안전 분석 및 V & V 방법론. 한국자동차공학회논문집, 33(1), 61