Paper: Improving Language Understanding
by Generative Pre-Training
🔍1. Introduction
자연어 처리(NLP)에서 지도 학습에 대한 의존도를 줄이기 위해 raw text로부터 학습을 하는 것이 아주 중요함.
대부분의 딥러닝 방법에서는 labeled data를 필요로 하지만, 이는 도메인에 따라서 활용이 한정적임.
비지도 데이터에서 언어 정보를 활용하는 모델이 성능도 향상시키고, 시간과 비용을 줄여주는 방법이 됨.
다만, 비지도 데이터에서는 한계가 존재함.
1. 텍스트 표현을 학습하는 데에 어떤 optimization objectives(최적화 목표)가 가장 효과적인지 명확하지 않음.
2. 학습된 표현을 objectives 작업에 효과적으로 전이하는 방법에 대한 합의가 부족함.
기존 기술들은 작업별로 아키텍처 변경이 필요하고, 학습 방식이 복잡하다는 한계를 갖고 있음.
본 논문에서는 비지도 사전학습과 fine-tuning을 결합한 semi-supervised 방식을 제안함.
최소한의 adaptation으로 다양한 범위의 tasks에 전이할 수 있는 universal representation을 목표로 학습하고자 함.
또한, 비지도 데이터와 목표 task가 같은 domain이 아니어도 적용할 수 있게끔 함.
Transformer를 기반으로 하며, 텍스트의 long-term dependencies(장기 의존성)를 처리하기 위한 structured memory(구조화된 메모리)를 제공하여 다양한 task에서 높은 전이 성능을 보임.
transfer시에, task-specific input adaptations(작업별 입력 변환)를 사용하여 structured text를 하나의 연속적인 token sequence로 처리함.
해당 GPT-1 모델은 다양한 NLP 작업에서 높은 성능을 기록함.
✅2. Related Work
Semi-supervised learning for NLP
본 연구는 semi-supervised learning에 속하는데, sequence labeling이나 text classification 작업에 다수 응용되어 왔음.
초기에는 unlabeled data(비지도 데이터)에서 단어/구 정도 수준의 통계치를 활용해서 지도 학습의 feature로 사용했음.
이후 비지도 corpus에서 학습된 word embeddings가 다양한 task에서 높은 성능을 내는 데 유용한 방법이라고 연구되어 왔고,
최근 연구에서는 구/문장과 같은 좀 더 높은 수준의 의미적 표현을 학습하고자 함.
Unsupervised pre-training
비지도 사전 학습은 semi-supervised learning의 일종으로, supervised learning objective(지도 학습 목표)를 수정하지 않고, 모델 초기화를 개선하는 것이 목표임.
최근에는 이미지 분류/음성 인식 등 다양한 분야에서 성능을 높이는 데에 해당 방법이 사용되고 있음.
Auxiliary training objectives
Auxiliary training objectives(보조 학습 목표)를 추가하는 것 또한 semi-supervised learning의 일종임.
다양한 보조 NLP 작업을 통해 role labelling을 개선할 수 있었음.
본 논문에서도 auxiliary objective를 사용했지만, 비지도 사전 학습만으로도 target tasks에 필요한 여러 언어적 측면을 학습할 수 있었음.
✅3. Framework
학습 절차는 2단계로 구성되며 하단과 같음.
1단계: 대용량 text corpus를 통해서 high-capacity language model을 학습
2단계: labeled data를 사용해서 모델을 discriminative task(식별 가능한 작업)에 맞도록 fine-tuning 하는 것
Unsupervised pre-training
비지도 사전 학습
비지도 corpus인 U={u1, ..., un}이 주어졌을 때, standard language modeling objective(표준 언어 모델링 목표)를 사용해서 하단과 같이 likelihood를 최대화 함.
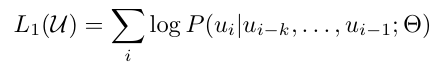
- k: context window의 크기
- P: 조건부 확률. 신경망 파라미터 Θ로 모델링 됨
- u_i: 현재 예측하려고 하는 단어
- u_i-k, ..., u_i-1: 이전 k개의 단어(context)
해당 파라미터들은 SGD(stochastic gradient descent, 확률적 경사 하강법)을 사용해서 학습됨.
실험에서는 Transformer의 변형 버전인 multi-layer Transformer decoder를 언어 모델로 사용함.
이는 input context tokens에 대해 multi-headed self-attention operation(다중 헤드 셀프 어텐션 연산)을 적용하고,
그 후 position-wise feedforward layers(위치별 피드포워드 레이어)를 통해 target tokens에 대한 출력 분포를 생성함.
head는 self-attention을 독립적으로 계산할 수 있는 하나의 unit. 다중 헤드, 즉 헤드를 여러 개 만들어서 동시에 계산하여 모델이 문맥의 다양한 측면을 효과적으로 학습할 수 있게 함.
수식은 하단과 같음.
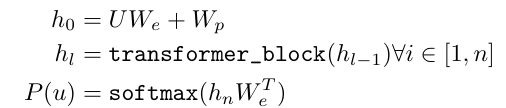
- h_o=UW_e+W_p: 입력 토큰 임베딩 W_e와 위치 임베딩 W_p를 더해서 만들어진 초기 벡터
- h_l: n개의 Transformer layer를 반복해서 업데이트 되는 은닉 상태
- P(u)=softmax(h_nW_e_T): 최종 출력 확률 분포를 계산하는 것
- U=(u-k,..., u-1): context vector of tokens를 의미
- n: 전체 transformer layer 수
- W_e: 토큰 임베딩 행렬
- W_p: 위치 임베딩 행렬
Supervised fine-tuning
사전 학습된 모델을 지도 학습 task에 적용하는 과정.
labeled dataset C를 가정하게 되는데,
우선
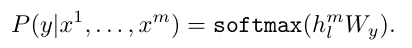
- x1, x2, ..., xm: 입력 토큰 시퀀스
- y: label
입력 토큰 시퀀스를 pre-trained model에 통과시키고, 마지막 Transformer 블록의 활성화 값인 h_l_m을 W_y(선형 출력층)에 전달해서 최종적으로 y를 예측함.
최적화할 objective function은 하단과 같음.
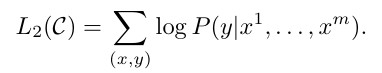
입력 x값이 주어졌을 때, 실제 정답인 y를 예측하는 확률을 maximize하도록 하는 구조로 학습을 진행함.
또한, Fine-tuning 과정에서 Auxiliary training objective(보조 학습 목표)를 추가하는 것이 학습에 도움이 된다는 것을 확인함.
Auxiliary objective의 장점은 하단과 같음.
(1) supervised model의 일반화 성능을 향상시킴
(2) 수렴(convergence) 속도를 향상시킴.
따라서, 최종 objective는 다음과 같음.
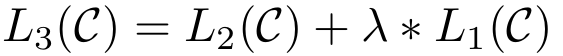
- L_3(C): Fine-tuning 시 최종적으로 최적화하는 손실 함수(반지도 학습)
- L_2(C): Fine-tuning
- L_1(C): 비지도 사전 학습
- λ: L_1(C)의 가중치
Task-specific input transformations
텍스트 분류와 같은 작업에서는 direct하게 fine-tuning이 가능하지만, 일부 질문 응답/텍스트 함축 같은 작업에는 structured inputs(구조화된 input)이라 변환이 필요함.
본 논문에서는 traversal-style approach를 통해 구조화된 inputs를 ordered sequence (연결된 시퀀스-사전학습된 모델이 처리 가능)로 변환하고자 함.
→ 아키텍처 변경 크게 안 해도 여러 task 적용 가능
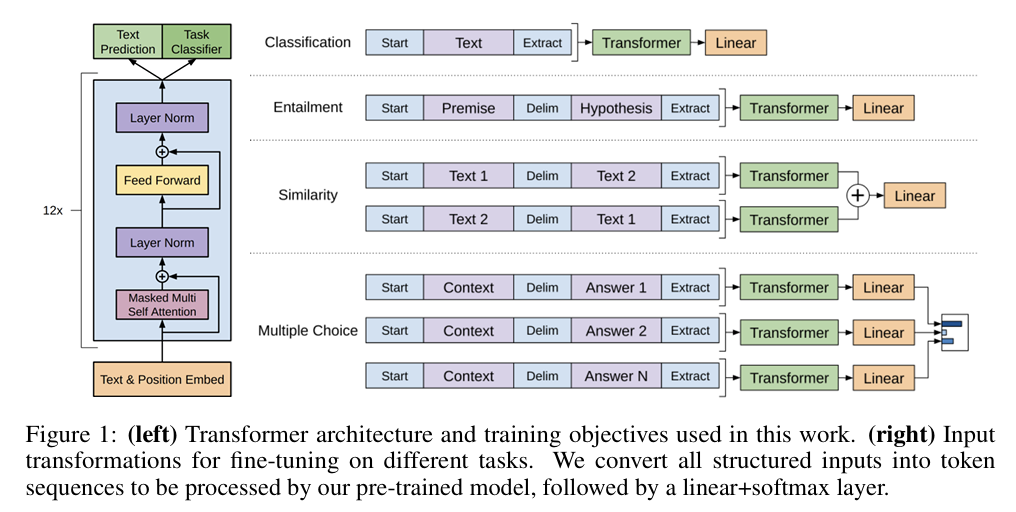
- 좌측: 본 연구에서 사용된 Transformer 아키텍처와 training objectives
- 우측: 다양한 task에 대한 Fine-tuning을 위한 input transformations
모든 structured inputs를 token sequences로 변환해서 사전 학습된 모델이 처리할 수 있도록 하고, 최종적으로 선형 레이어와 소프트맥스 레이어를 통해 출력.
또한, 모든 변환 과정에서 랜덤으로 초기화된 start token< s >와 end token< e >를 추가하여 구성함.
Textual entailment
텍스트 함축 task에서는 전제(premise)와 가설(hypothesis)의 토큰 시퀀스를 하나로 연결함. 이때, 둘 사이에 구분자 토큰(delimiter token($))을 넣음.
Similarity
유사도 task에서는 입력 순서가 바뀌어도 결과가 같아야 하기 때문에, 두 개의 문장 순서를 바꿔서 각각 입력으로 넣음.
각 시퀀스를 독립적으로 처리하여 두 개의 벡터를 생성하고 이를 요소별 덧셈을 통해 선형 output layer로 전달함.
Question Answering and Commonsense Reasoning
질문 응답 및 추론 task에서는 문맥z, 질문q, 정답 a_k를 조합해서 입력을 구성함.
각 정답 후보들을 독립적으로 모델에 넣고, 최종적으로 softmax를 사용해서 정답 확률을 계산함.
✅4. Experiments
Setup
Unsupervised pre-training
BooksCorpus 데이터셋을 학습에 사용하였고, 이는 7,000개 이상의 unpublished book임.
특히, 길이가 긴 연속적인 text로 이루어져 있기에, 모델이 long-range information을 학습하는 데에 좋음.
Model specifications
- Transformer 아키텍처를 따름
- 12개의 디코더 전용 레이어 사용
- 768차원의 은닉 상태
- Adam 옵티마이저 사용
- Layer Normalization, dropout, L2정규화 진행
- GELU 활성화 함수
Supervised fine-tuning
다양한 task에서 실험을 수행함
Natural Language Inference
두 개의 문장을 읽고, 이 두 개의 관계를 함축/모순/중립 중 하나로 판단하는 작업임.
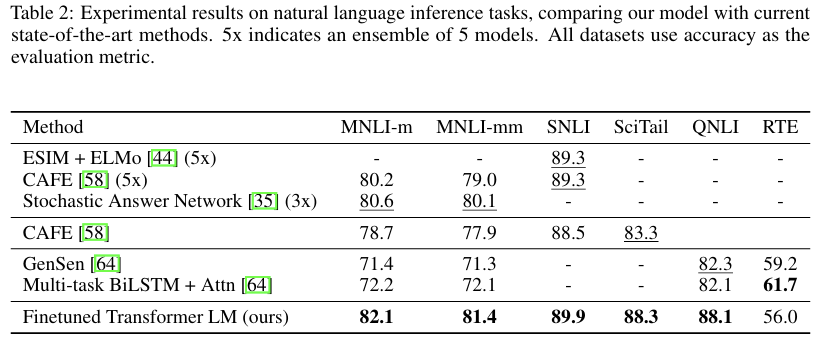
NLI(Natural Language Inference, 자연어 추론) 작업에서 5개 데이터셋 중 4개(MNLI, SciTail, QNLI, SNLI)에서 최고 성능을 달성함.
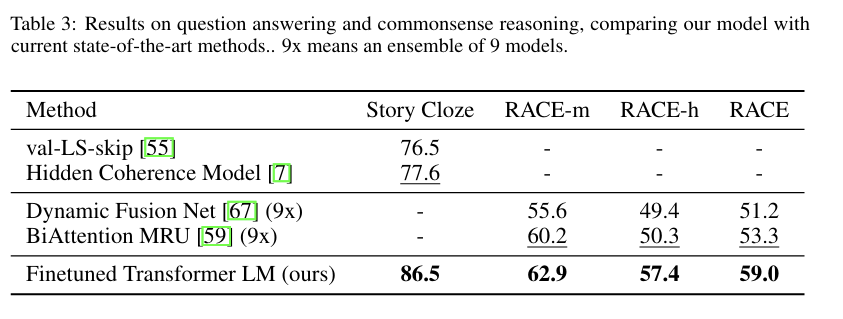
Question answering and commonsense reasoning
영어 지문 관련 질문들로 구성된 RACE 데이터셋을 사용하였고, Story Cloze Test 또한 평가에 포함했음.
결과적으로 Story Cloze에서 8.9%, RACE에서 5.7%의 성능 향상을 이뤄냄.
이를 통해 long-range contexts의 처리 능력이 우수함을 보여줌.
Semantic Similarity
두 문장이 의미적으로 동일한지 예측하는 task.
데이터셋으로 MRPC, QQP, STS-B를 사용했고,
STS-B에서는 1%, QQP에서는 4.2% 절대 성능 향상을 이뤄냄.
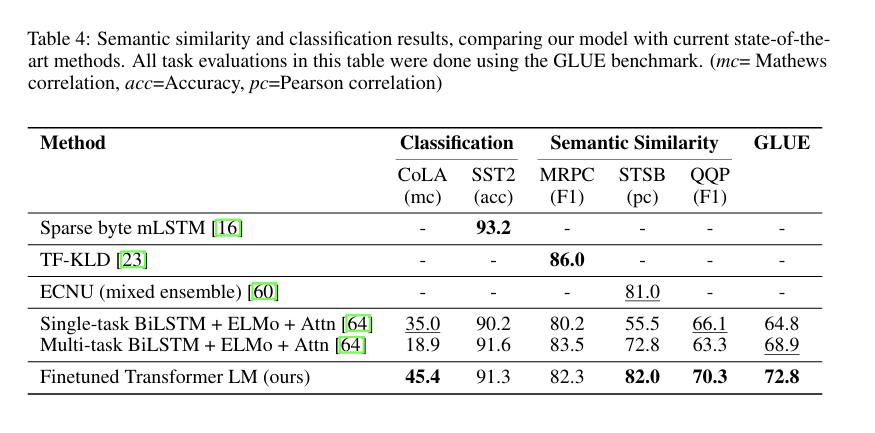
Classification
텍스트 분류 taks에서는 CoLA와 SST-2를 통해 문법 판단과 감정 판단을 진행하였고.
CoLA에서는 45.4점, SST-2에서는 91.3%로 높은 성능을 보임.
전반적으로, 본 연구에서 12개의 데이터셋 중 9개에서 최고 성능을 구현해냄.
그리고 앙상블 모델의 성능까지 능가해버림.
✅5. Analysis
Impact of number of layers transferred
비지도 사전 학습된 모델에서 지도 학습된 target task로 전이되는 레이어 수의 영향을 분석하였고, 전이되는 레이어 수가 많을수록 성능이 향상된다는 것을 나타냄.
Zero-shot Behaviors
Transformer 기반 언어 모델의 비지도 학습이 효과적인 이유에 대해서 분석하였고,
generative model이 언어 모델링 능력을 학습하는 과정에서 다양한 작업을 수행하는 능력도 함께 습득했기 때문이라고 분석하였음.
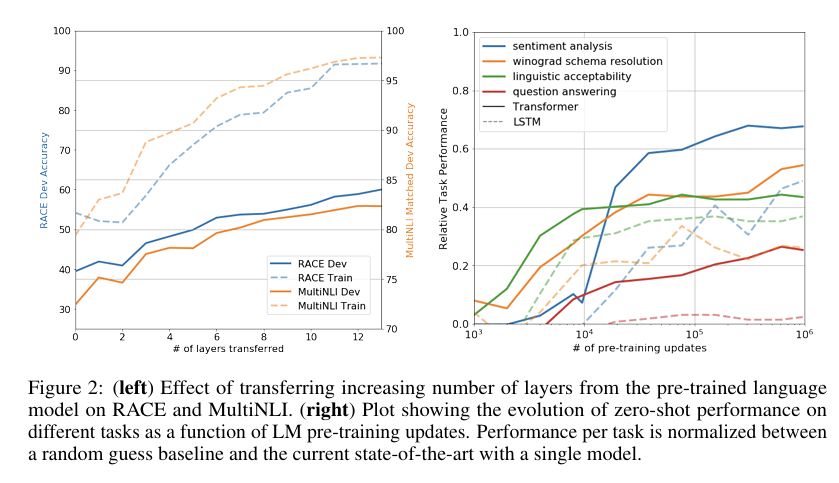 ↑
↑
좌측에서는 전이되는 레이어 수에 따른 성능 변화를 보여주고, 우측에서는 사전 학습 업데이터 수에 따른 Zero-shot 성능 변화를 보여줌.
Ablation studies
모델 성능에 영향을 주는 요소를 확인하고자 함.
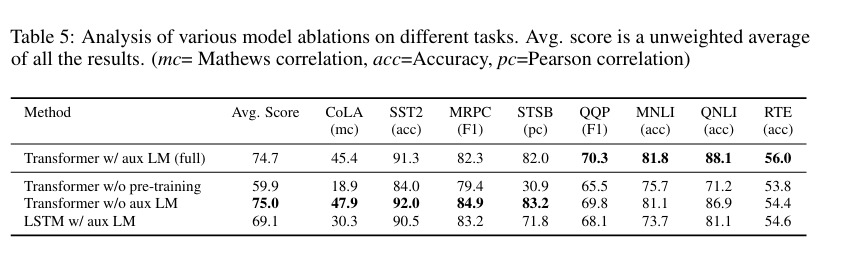
위 표를 통해 성능 차이를 확인할 수 있음.
보조 LM이 작은 데이터셋에서는 효과가 없음을, 대부분의 task에서 transformer가 lstm보다 높은 성능을 냄을, 사전학습이 필수적임을 확인할 수 있었음.
🔚6. Conclusion
generative pre-training과 discriminative fine-tuning을 결합한 프레임워크를 통해서 뛰어난 자연어 이해 모델을 개발함.
다양한 연속 text로 구성된 대규모 corpus에서 사전 학습을 통해, 모델이 world knowledge와 long-range dependencies(장기 의존성)를 처리할 수 있게 학습되었고,
이는 다양한 NLP task에서 성공적인 결과를 냄.
비지도 학습을 통해서 discriminative task의 성능을 높일 수 있음을 입증함.
