Paper: Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
🔍1. Introduction
CNN 기반 딥러닝 모델
: 이미지 분류, 객체 탐지, 세그멘테이션, 이미지 캡셔닝, VQA 등에서 성능 압도적.
But, 왜 어떻게 그렇게 예측을 했는지 설명할 수 X. 완전 Black Box!
=> 모델이 실수하면 그 이유를 알 수 X. -> AI에 대한 신뢰 저하.
따라서, 해석 가능성(Interpretability)이 중요함.
예측 결과를 사람이 납득할 수 있어야 함.
설명 가능한 모델이 필요한 이유
1) AI가 인간보다 약할 때 어디서 잘못됐는지 분석해야 연구 가능함
2) 인간이랑 비슷할 때: 사용자가 믿고 쓸 수 있어야 함
3) 인간보다 똑똑할 때: AI가 인간에게 설명해줄 수 있어야 함. (ex. 체스, 바둑)
+ 해석 가능성&정확도: 트레이드오프 관계.
ex. rule-based: 해석 Good, 성능 Bad / 딥러닝: 성능 Good. 해석 Bad
-
기존 해석법 CAM(Class Activation Mapping)
: CNN 마지막에 fully-connected layer 없는 구조에만 적용 가능함.
구조도 바꿔야 하고 성능도 좀 떨어짐 -
Grad-CAM 제안
: 구조 변경 없이 모든 CNN 모델에 시각적 설명 가능하게 해주는 방법임.
VGG 같은 Fully-connected layer 있는 모델, 캡셔닝 모델, VQA 같은 멀티모달 모델 다 지원함.
그리고 훈련 다시 안 해도 됨.
Grad-CAM
특정 클래스에 대한 gradient를 마지막 conv layer로 backprop 해서 어디가 중요한지 coarse heatmap으로 보여줌.
-> 이게 클래스 구분 확실하게 해줌 (class-discriminative)
근데 해상도는 낮음.
그래서 Guided Backprop 같은 고해상도 시각화 기법이랑 결합함.
Guided Grad-CAM 만듦
-> 고해상도 + 클래스 구분 둘 다 챙긴 시각화 가능
📌Grad-CAM은 구조 바꾸지 않고도 대부분의 CNN 모델에서 설명 가능한 heatmap을 제공함.
✅2. Related Work
Visualizing CNNs
1) 이전 연구들에서는 CNN의 예측을 해석하기 위해 ‘중요한 픽셀’을 강조하는 시각화 방법 많이 제안됨.
But, 클래스 구분(class-discriminative)이 안 됨. 어떤 클래스를 보든 시각화 결과 비슷함 (ex. 고양이나 개나 다 비슷하게 나옴)
뉴런을 최대로 활성화하는 이미지를 합성하거나 latent representation을 반대로 복원함.
-> 이건 클래스 구분은 되지만, 개별 이미지가 아니라 전체 모델의 일반적인 동작만 보여줌.
Assessing Model Trust
Grad-CAM은 사람 대상 실험 기반으로, 모델의 시각화가 사용자가 AI를 얼마나 신뢰할 수 있는지를 평가하는 데 도움이 된다는 점을 검증함.
Aligning Gradient-based Importances
Grad-CAM에서 나온 뉴런 중요도를 class domain knowledge와 매핑해서 새로운 클래스 학습하는 연구 진행함.
후속 연구에서는 이를 attention map과 정렬해서 멀티모달 모델(Vision + Language)을 해석하는 시도 O
Weakly-supervised localization
- 클래스 라벨만으로 객체 localization 찾는 방법 많이 제안됨
- 특히 CAM(Class Activation Mapping)은 FC layer 제거하고, conv + GAP(Global Average Pooling) 조합으로 class-specific feature map 생성
But, 구조 제한 O. Softmax 직전 layer에 conv + GAP 구조가 반드시 있어야 함
=> classification은 가능하지만, captioning이나 VQA 같은 task에는 적용 불가능
Grad-CAM은 구조 제한 X
- CAM과 달리 기존 모델 구조 그대로 적용 가능
- Fully-connected layer 있는 VGG 같은 모델에도 사용 가능하고, captioning이나 VQA 같은 복잡한 모델에도 쓸 수 있음
- 계산량도 적고
- 신뢰도 평가/편향 진단에도 활용할 수 있음
✅3. Grad-CAM
CNN 모델은 층이 깊어질수록 추상적인 정보를 학습함.
특히 convolutional layer는 이미지 내 위치 정보(spatial info)를 유지하는 특징이 있어서, 마지막 conv layer는 의미와 위치를 동시에 담고 있음.
=> Grad-CAM은 이 마지막 conv layer에서 정보를 뽑아 시각화를 진행함.
<Grad-CAM 방식>
1. 특정 클래스 c에 대한 예측 점수 y^c 기준으로, 마지막 conv layer의 피처맵 A^k에 대한 gradient 계산.
2. 이 gradient를 공간적으로 평균을 내서 각 피처맵의 중요도 α 계산.
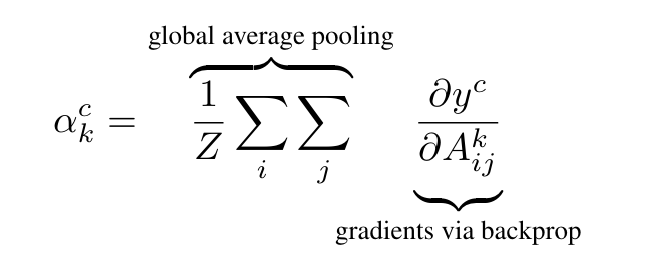
3. 이 α 값으로 피처맵을 가중합하고, 마지막에 ReLU 함수 적용.
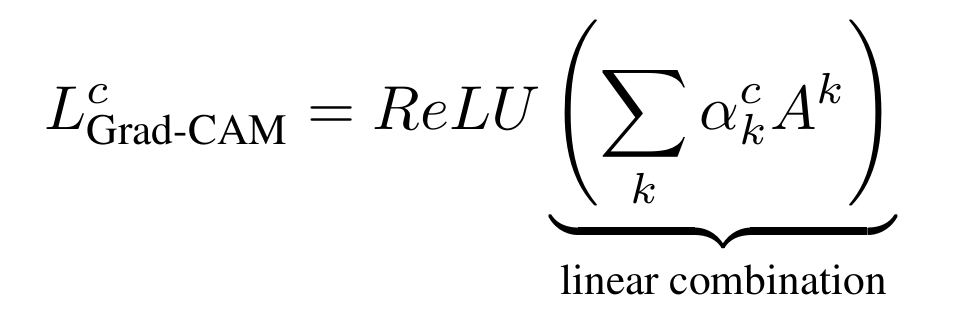
=> 모델이 해당 클래스 예측 시 중요하게 본 영역만 heatmap으로 표현 가능!
왜 ReLU를 쓰는가?
관심 있는 클래스에 양의 영향을 주는 부분만 보고 싶기 때문. 음의 gradient가 포함되면 다른 클래스를 설명할 수 있어서, 시각화가 흐려져서 정확한 localization이 안 됨.
Grad-CAM generalizes CAM
Grad-CAM은 CAM의 일반화된 버전.
CAM(Class Activation Mapping)은 이미지 분류 CNN에서 특정 구조를 가정해야만 적용 가능한 시각화 기법임.
[ Conv → GAP → Fully-connected(1x1 conv) → Softmax ]
- 마지막 conv layer의 feature map을 Global Average Pooling(GAP) 해서 클래스별 score 계산함.
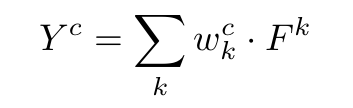
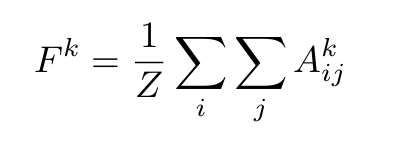
Grad-CAM은 w 없이도, gradient만으로 중요도를 계산!
결국 수식적으로 보면,
CAM의 weight w_k^c ≈ Grad-CAM의 a_k^c
(방식이 학습 기반 vs gradient 기반 차이)
Guided Grad-CAM
고해상도 시각화가 필요할 때
Grad-CAM은 클래스 구분(class-discriminative)은 잘하지만 heatmap 해상도가 낮음.
그래서 Guided Backpropagation과 결합해 [고해상도 + 클래스 구분력]을 동시에 만족하는 Guided Grad-CAM으로 확장 가능.
: Grad-CAM의 coarse한 영역에 Guided Backprop의 세부 경계를 곱해주는 방식
=> 결과적으로, 예측 클래스의 결정적인 디테일 특징(눈, 줄무늬 등)까지 강조됨.
✅4. Evaluating Localization Ability of Grad-CAM
Grad-CAM은 단순한 시각화 도구를 넘어, 실제로 모델이 어디를 보고 판단했는지를 정확히 집어내는 능력이 있음.
1) Weakly-supervised Localization
Grad-CAM은 학습 과정에서 위치 정보(bounding box)를 전혀 사용하지 않았기 때문에, 이 실험은 weakly-supervised(약지도) 평가.
모델의 top-5 예측 결과 각각에 대해 Grad-CAM heatmap 생성
heatmap을 최댓값의 15% 이상만 남기고 이진화
가장 큰 연결 영역(connected component)을 찾아 bounding box로 묶음
=> 이걸 ground-truth box와 비교해 top-1 / top-5 localization 정확도 측정
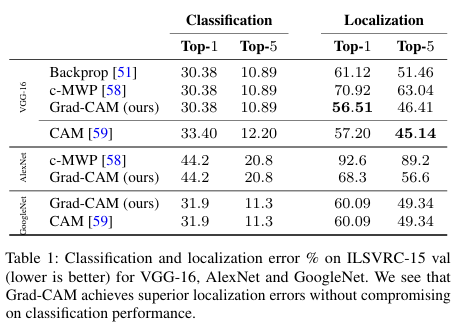
결과
: Grad-CAM이 기존 방법들보다 localization 성능 우수
구조 변경 없이 이 정도 성능 나오는 건 매우 긍정적!
=> Grad-CAM은 분류 성능을 떨어뜨리지 않으면서도 위치 추정(localization)까지 가능
2) Weakly-supervised Segmentation
세그멘테이션(Semantic Segmentation)은 이미지에 있는 모든 픽셀에 물체 클래스를 할당하는 작업.
예를 들면, “이 픽셀은 고양이의 귀, 저 픽셀은 배경” 이런 식으로 픽셀 단위로 분류하는 것.
근데 문제는…
이걸 제대로 하려면 픽셀 하나하나에 정답(label)을 달아줘야 되는데,
이게 진짜 돈도 많이 들고 사람 손도 엄청 가는 일.
그래서 최근에는 약지도(weakly-supervised) 방식으로 segmentation 시도함.
-> 이미지에 “고양이가 있다” 정도의 정보만 갖고 분할 학습하는 방식.
최근 연구(Kolesnikov et al.)에서는
“약한 시드(seed)만 잘 주면, 모델이 나머지는 학습하면서 확장하겠지”라는 가정하에 새로운 segmentation loss 함수를 제안함.
이 loss는 하단과 같이 구성됨.
1) 초기 seed로 localization cue를 줌
2) 그걸 reasonable한 크기까지 확장
3) 경계선(물체 테두리) 정밀하게 맞추도록제약 걸기
이렇게 하면 잘 되긴 함.
근데 문제는 seed의 품질에 매우 민감함.
이 연구에서는 CAM으로 seed를 만들었는데, CAM은 구조 제한도 있고 성능이 좀 부족함.
그래서!!
=> CAM 대신 Grad-CAM으로 seed를 바꿔봄
실험은 PASCAL VOC 2012 데이터셋 기준으로 했고,
CAM seed 썼을 때는 IoU 44.6
Grad-CAM seed 썼을 때는 IoU 49.6
: 큰 성능 향상!

결과 이미지 봐도 Grad-CAM 쓴 쪽이 훨씬 더 자연스럽고 잘 나옴.
Grad-CAM은 분류할 때 어디를 봤는지를 잘 보여줄 뿐만 아니라,
픽셀 단위의 segmentation에서도 더 정밀하게 seed를 잡아줄 수 있음!!
3) Pointing Game
Grad-CAM이 heatmap 보여주는 것 ? OK.
단, 진짜로 정확하게 물체 위치를 찍었는지 평가하려면?
=> Pointing Game 실험 !
: Ground-truth 라벨(예: 고양이)을 기준으로,
각 시각화 기법이 만들어낸 heatmap에서 가장 activation이 강한 점을 뽑고, 그 점이 실제 라벨 박스 안에 있으면 hit, 아니면 miss.
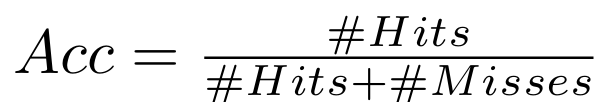
[ACCURACY 계산식]
<실험 구성>
모델의 top-5 예측 클래스 각각에 대해 Grad-CAM heatmap 생성.
heatmap의 가장 강한 점(max point)이 실제 물체 안에 있으면 hit
근데 아예 관련 없는 예측(class)일 경우에는,
-> heatmap이 별로 안 뜨면 그걸 잘못된 예측이라고 판단하고 pass할 수 있음
-> 이것도 잘 판단한 거니까 hit로 처리함
즉, "정확한 데 잘 찍거나, 틀린 예측은 깔끔하게 무시하거나" 둘 다 잘하면 Good.
실험 결과, Grad-CAM이 확실히 어디를 봐야 하는지 더 잘 잡아냄.
✅5. Evaluating Visualizations
1) Evaluating Class Discrimination
Grad-CAM이 클래스별로 구분이 잘 되는지 실험
즉, heatmap만 보고도 클래스 차이를 구별할 수 있어야 함.
<실험 구성>
사용한 데이터셋: PASCAL VOC 2007 validation set
(여기엔 2개의 클래스가 동시에 나오는 이미지 多)
비교 모델: VGG-16 / AlexNet (둘 다 PASCAL에서 finetune한 버전)
총 4가지 시각화 방식 테스트함:
- Deconvolution
- Guided Backpropagation
- Deconv + Grad-CAM
- Guided Backprop + Grad-CAM (= Guided Grad-CAM)

결과적으로 Guided Grad-CAM이 가장 클래스 구분 잘 됨.
Guided Backprop은 보기엔 예쁘지만, 클래스 구분은 제일 안 되고, Deconv는 좀 덜 예쁘지만, 클래스 구분은 더 잘 됨.
Grad-CAM 조합 버전들은 둘 다 성능 향상에 기여!
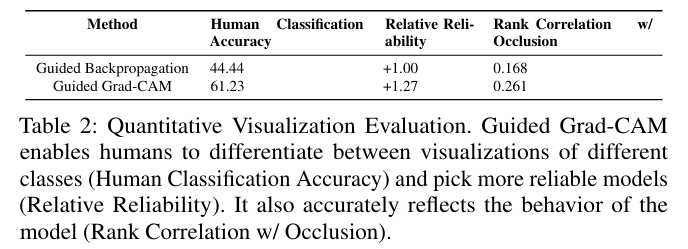
2) Evaluating Trust
같은 예측을 했을 때, 어떤 모델이 더 믿을만해 보이는지를 사람한테 물어봄.
<실험 구성>
비교 모델:
- VGG-16 (정확도 높음, mAP 79.09)
- AlexNet (정확도 낮음, mAP 69.20)
중요 조건:
두 모델이 동일한 예측을 했을 때만 시각화를 보여줌
(그래야 단순히 "정답을 맞췄냐"가 아니라, “왜 그렇게 예측했는지”에 대한 시각화만으로 판단 가능)
두 모델(AlexNet, VGG-16)의 시각화를 나란히 보여주고, 사람이 보고 어떤 모델이 더 신뢰 가는지 느낌 평가.
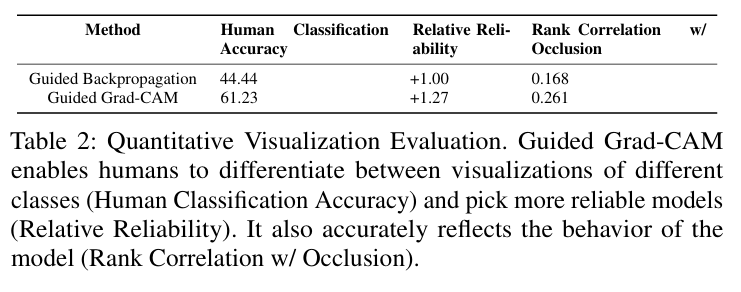
결과적으로, 둘 다 정답을 맞췄지만, Guided Grad-CAM을 보고 사람들이 VGG가 더 믿음 간다고 판단함.
즉, Grad-CAM 시각화 하나만 보고도 어떤 모델이 더 일반화 잘 되고, 믿을 만한지 파악 가능하구나!
3) Faithfulness vs. Interpretability
Grad-CAM 시각화가 보기엔 이해 잘 되는데, 진짜 모델의 판단 근거랑 일치하는지는 따로 따져봐야 함.
이걸 faithfulness (충실도) 라고 하는데, 이 시각화가 모델이 실제로 어떻게 생각했는지를 정확하게 반영하고 있는지 확인하는 것임.
<실험 구성>
기준 시각화로는 이미지 occlusion 사용.
이미지에서 일부분을 가리면 예측 score가 어떻게 변하는지 측정.
score가 크게 변하는 영역이 실제로 모델이 중요하게 본 부분이라고 가정.
그리고 Grad-CAM heatmap이랑 이 occlusion 결과를 비교해서 순위 상관 관계(rank correlation) 측정함
=> 값이 높을수록 시각화가 모델 판단과 잘 일치한다는 뜻
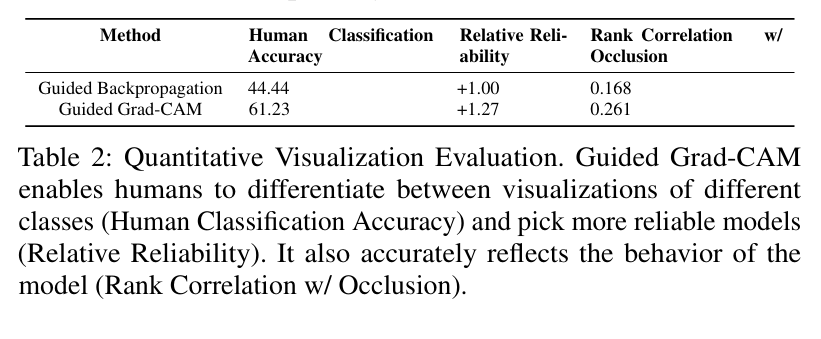
결과적으로, Grad-CAM 계열이 압도적으로 충실도가 높은 걸 확인할 수 있음. Guided Grad-CAM은 해석성도 높은데 faithfulness까지 좋음!
✅6. Diagnosing image classification CNNs with Grad-CAM
모델이 정답 맞추는 것을 넘어, 오답 시에는 왜 틀렸는지, 어디를 잘못 봤는지, 데이터가 편향됐는지 분석!
1) Analyzing failure modes for VGG-16
VGG-16이 틀린 이미지들 모아서 리스트 만듦.
그 후, 그 이미지에 대해서
- 예측한 클래스 기준으로 Guided Grad-CAM 시각화
- 실제 정답 클래스 기준으로도 Guided Grad-CAM 시각화
이때, 둘 다 비교해보면, 종종 틀렸는데 그럴 만한 경우가 꽤 있음.

위 예시 사진을 보면 알겠듯이, 사람 눈에도 ambiguous한 상황이 있었던 거임
근데 heatmap 보면, 모델이 진짜로 해당 오답처럼 보이는 부위를 보고 예측한 걸 알 수 있음.
=> Grad-CAM은 틀린 이유까지 설명해주는 시각화 도구.
실패한 예측도 합리적인 이유가 있었음을 보여주며, 모델을 이해하고 개선하는 데 큰 도움 줌.
2) Effect of adversarial noise on VGG-16
요즘 CNN들은 Adversarial Attack에 잘 속는 걸로 유명함.
: 아주 미세하게 이미지를 건드렸는데, 모델이 완전히 다른 클래스를 고르게 되는 현상.
따라서, Grad-CAM이 위와 같은 상황에서도 제 역할을 하는지 실험해봄.
<실험 구조>
VGG-16 (ImageNet pretrained) 모델 사용
입력 이미지를 adversarial noise로 살짝 건드림.
(ex.: 원래는 "고양이 + 강아지"가 있는 이미지였는데, airliner(비행기) 같은 전혀 다른 클래스를 99.99% 확률로 예측하게 만듦)
그 후 이 잘못된 예측 상태에서 Grad-CAM을 원래 정답 클래스("tiger cat", "boxer(dog)") 기준으로 시각화해봄.

결과적으로 Grad-CAM은 softmax output보다 내부 gradient 흐름을 기반으로 작동하기 때문에 모델이 속아 넘어가도, 진짜 중요했던 부분은 여전히 잘 보여줌!
3) Identifying bias in dataset
본 실험에서는 Grad-CAM을 활용해서 모델이 데이터에 학습된 성별 편향을 시각적으로 드러내고, 그걸 줄이는 실험임.
<실험 구성>
실험 내용
- 이진 분류(task): '의사(doctor)' vs '간호사(nurse)'
VGG-16 (ImageNet pretrained) 모델 fine-tune.
데이터 구성
- train/val: 이미지 검색 엔진에서 각 클래스당 250장씩 수집
- test set: 성비 균형 맞춰서 따로 구성함 (남녀 비슷하게)
기존 모델은 학습 정확도 잘 나왔음 (val 기준 OK)
근데 test에서 성능 떨어짐 (accuracy 82%)
뭔가 일반화가 안 되고 있는 것...

Grad-CAM으로 시각화해보니...
모델이 사람 얼굴이나 머리 스타일만 보고 판단하는 경향 O
즉, 여성이면 간호사, 남성이면 의사로 분류하려고 함.
실제로 여자 의사 → 간호사로 잘못 분류, 남자 간호사 → 의사로 잘못 분류.
근데 데이터 자체가 편향되어 있었따는 것을 확인했음.
따라서 여자 의사 이미지 / 남자 간호사 이미지를 추가함.
단, 각 클래스당 이미지 수는 그대로 유지함. (성비만 균형 맞춰줌 (데이터 편향 줄임))
수정된 데이터로 다시 학습했더니
test 정확도 90%로 상승함!
그리고 Grad-CAM 시각화 결과도 달라짐.
이번엔 의사 가운, 청진기 같은 진짜 class-relevant 부분에 집중함.
✅7. Textual Explanations with Grad-CAM
Grad-CAM이 왜 이 클래스라고 판단했는지를 text로도 설명할 수 있음!
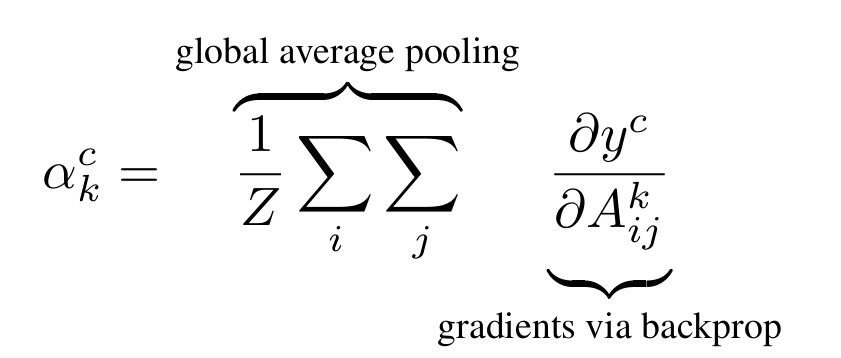
앞서, Grad-CAM에서 클래스별로 각 뉴런의 중요도(a_k^c)를 구하는 공식에서...
이 값이 높으면: 그 뉴런이 해당 클래스 예측에 긍정적인 영향 줬다는 뜻
이 값이 낮으면: 해당 클래스 점수를 떨어뜨리는 역할 했다는 뜻
기존 연구들에선 CNN의 뉴런들이 "개념 단위의 감지기" 역할을 한다고 봤는데, 그러면 이 각 뉴런에 사람이 이해할 수 있는 label을 붙이자는 아이디어.
(ex. 이 뉴런은 @@, 저 뉴런은 &&)
그 후, Grad-CAM을 이용해 해당 클래스에 중요한 상위/하위 5개 뉴런을 찾음(예측에 기여한 개념(top-5), 방해한 개념(bottom-5)).
마지막으로 그 뉴런 label을 텍스트 설명으로 출력!
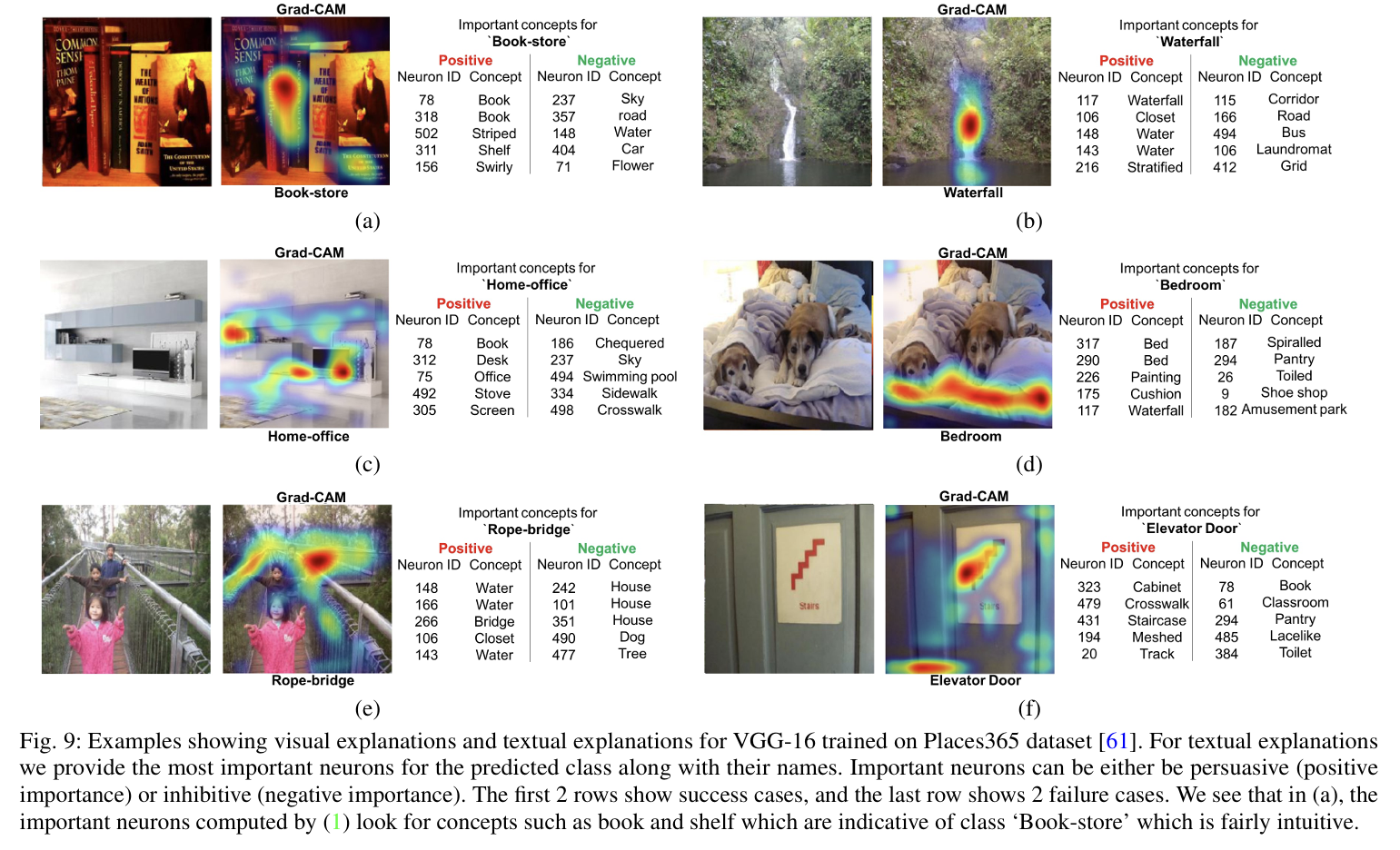
결과적으로 각 뉴런 label을 직관적으로 확인할 수 있음!
(잘못 분류된 경우도 있지만, 이 경우 heatmap이랑 단어 설명 보면 이해는 됨.)
✅8. Grad-CAM for Image Captioning and VQA
좀 더 나아가서 이미지 캡셔닝과 VQA에도 적용.
1) Image Captioning
Image Captionaing: 이미지를 보면, 그걸 문장으로 설명하는 모델
<실험 구조>
- 적용 모델: neuraltalk2
- 이미지 인코더: VGG-16 (conv5_3까지 사용)
- 언어 모델: LSTM
- 특징: attention 없음 (요즘 captioning 모델과 달리 “어디를 보면서 말하라” 같은 구조는 아님)
생성된 caption의 log-prob에 대해 CNN의 마지막 conv layer에 대한 gradient 계산하고, Grad-CAM 방식으로 heatmap 생성
=> 결과적으로 “이 문장을 만들기 위해 이미지의 어디를 봤는지” 시각화 가능

kites랑 people이 caption에 들어가면, 이 둘을 정확히 로컬라이징함.
이때, 언급되지 않은 단어가 나오지 않았으면 Grad-CAM도 신경 안 씀

Dense Captioning과의 비교했는데, DenseCap 모델은 bounding box 단위로 caption을 다는 모델임.
다만, Grad-CAM은 box 정보 없이, 전체 이미지에 대해 생성된 caption이 어떤 구역에 대응되는지를 heatmap으로 되살려냄.
2) Visual Question Answering
Visual Question Answering: 이미지를 보여주고, 질문을 하면 답하는 모델
<기존 VQA 실험 구성>
CNN: 이미지 피처 추출 (ex: VGG, ResNet)
RNN or Transformer: 질문 이해 (ex: LSTM)
Fusion: 둘을 합쳐서 답 예측
=> 보통 1000개 클래스 중에서 분류하는 구조 (classification 문제임)
여기에 Grad-CAM 적용
예측된 답변 클래스의 score에 대해 기존 Grad-CAM 방식으로 이미지에 heatmap 생성함
=> 그 결과, 이 질문에 ~~ 한 답을 한 이유는 이미지의 ~~~ 를 봤기 때문이라고 시각화를 해줌
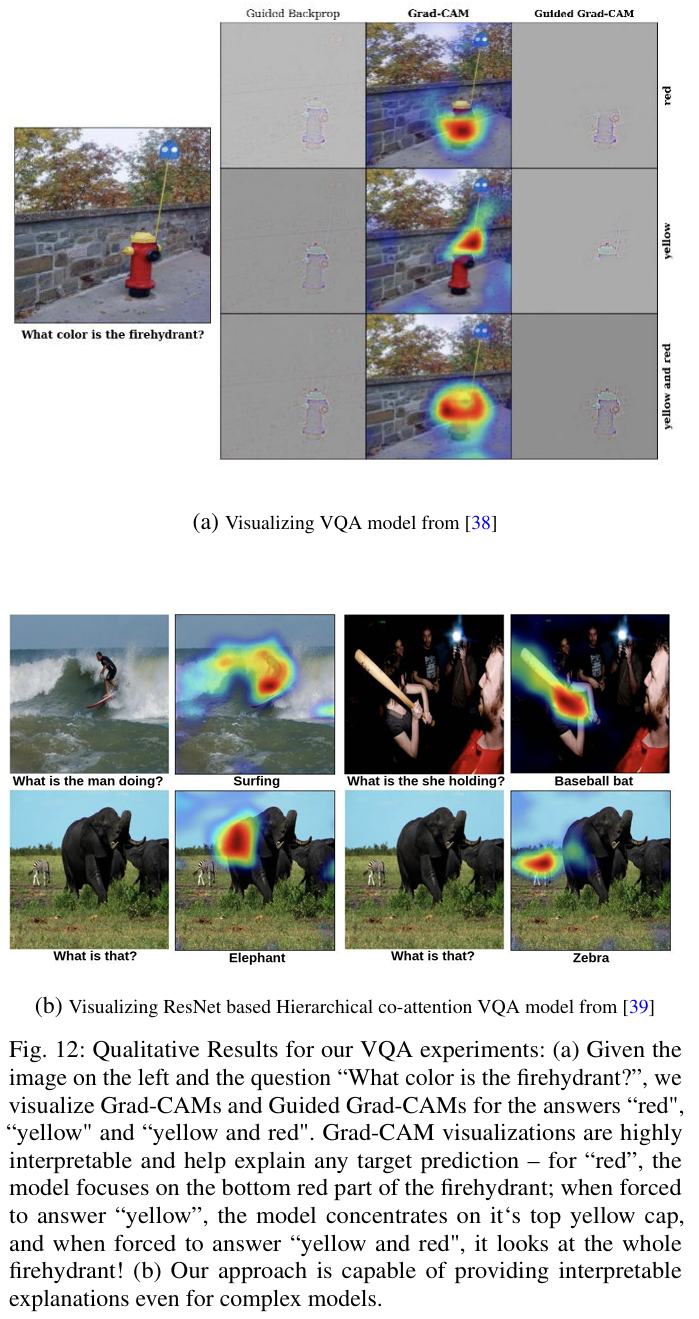
(a): 답변이 바뀔 때마다 Grad-CAM이 소화전의 해당 색상 부위에 집중하며, 모델이 선택한 답의 근거를 명확히 보여줌.
(b): 복잡한 ResNet 기반 VQA 모델에서도 Grad-CAM은 층별로 일관되고 해석 가능한 시각화를 제공.
결과적으로, VQA는 이미지+질문에 대해 답 하나를 예측하는 것.
이때 Grad-CAM은 그 답을 예측한 시각적 근거를 heatmap으로 제공!
=> 사람이 보는 영역과도 일부 일치함 (attention 없이도!), 모델 구조가 깊거나 복잡해도 Grad-CAM은 적용 가능했음.
🔚9. Conclusions
Grad-CAM은 CNN 기반 모델의 판단 근거를 시각적으로 보여주는 class-discriminative한 시각화 기법임
Guided Backprop 같은 고해상도 기법과 결합해, 고해상도 + 클래스 구분력을 동시에 갖춘 Guided Grad-CAM도 제안했음.
기존 방법보다 해석력(interpretablity)과 모델 충실도(faithfulness) 모두 더 우수함!
- 사람 실험에서 클래스 구분 명확히 설명 가능함
- 신뢰도 판단에도 도움 줌 (좋은 모델 vs 나쁜 모델 구분 가능)
- 데이터셋의 편향 같은 문제를 heatmap으로 찾아낼 수 있음
- 중요한 뉴런을 뽑아내어 텍스트 기반 설명도 가능
- 분류 모델뿐만 아니라 이미지 캡셔닝, VQA 같은 복잡한 태스크에도 적용 가능
AI라는 것은 똑똑한 것 뿐 아니라, 판단의 근거를 설명할 수 있어야 사람들이 신뢰하고 쓸 수 있음!
🔖10. Reference
https://www.youtube.com/watch?v=uA5rIr79I0o
https://www.youtube.com/watch?v=U4Aq9GPH6Iw
