Context-aware Feature Generation for Zero-shot Semantic Segmentation
CaGNet
https://arxiv.org/pdf/2008.06893
1. Introduction
Inspired by feature generation methods for zero-shot classification [7, 44], ZS3Net learns to generate pixel-wise features from semantic word embeddings. The generator is trained with seen categories and able to produce features for unseen categories, which are then used to fine-tune the last 1 × 1 convolutional (conv) layer in the segmentation network. Moreover, they extend ZS3Net to ZS3Net (GC) by using Graph Convolutional Network (GCN) [19] to capture spatial relationships among different objects. However, it still has two drawbacks:
-
ZS3Net simply appends random noise to one semantic word embedding to generate diverse features. However, the generator often ignores the random noise and can only produce limited diversity for each category-level semantic word embedding, known as the mode collapse problem [42, 51].
ZS3Net은 단순히 하나의 시맨틱 워드 임베딩에 랜덤 노이즈를 추가하여 다양한 특징을 생성합니다. 그러나 생성기는 종종 랜덤 노이즈를 무시하고, 각 카테고리 수준의 시맨틱 워드 임베딩에 대해 제한된 다양성만을 생성할 수 있습니다. 이는 모드 붕괴 문제(mode collapse problem) [42, 51]로 알려져 있습니다. -
Although ZS3Net (GC) utilizes relational graphs to encode spatial object arrangement, the contextual cues it considers are object-level and only limited to spatial object arrangement. Moreover, the relational graphs containing unseen categories are usually inaccessible when generating unseen features.
ZS3Net (GC)는 공간적 객체 배치를 인코딩하기 위해 관계 그래프를 활용하지만, 고려하는 맥락적 단서는 객체 수준에 국한되며, 공간적 객체 배치에만 제한되어 있습니다. 또한, 보이지 않는 카테고리를 포함하는 관계 그래프는 보이지 않는 특징을 생성할 때 일반적으로 접근할 수 없습니다.
2. Related Works
Our method is inspired by ZS3Net, but different from their method in mainly two ways: 1) we unify the segmentation network and feature generator; 2) we leverage pixel-wise contextual information to guide feature generation.
반면, ZS3Net은 보이는 카테고리로 편향된 분류기를 미세 조정하기 위해 픽셀 단위의 특징을 생성하는 것을 목표로 합니다. 우리의 방법은 ZS3Net에서 영감을 받았지만, 두 가지 주요 방식에서 다릅니다: 1) 우리는 세분화 네트워크와 특징 생성기를 통합했습니다; 2) 우리는 픽셀 단위의 맥락 정보를 활용하여 특징 생성을 안내합니다.
3. Methodology
the bridge between seen and unseen categories is the category-level semantic word embeddings , in which is the semantic word embedding of category c.
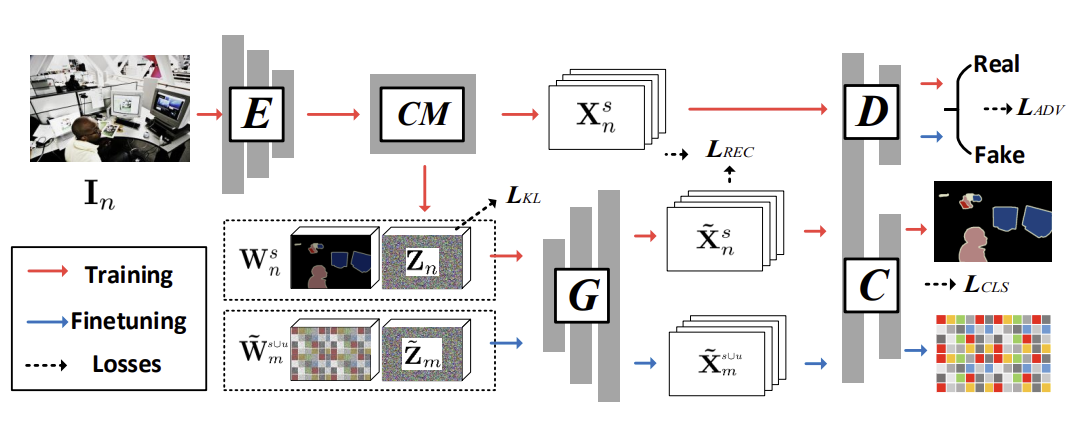
3.1 overview
Deeplabv2 : backbone E and classifier C (e.g., one or two 1×1 conv layers)
generator G
CaGNet 모델은 픽셀의 특징이 그 주변 픽셀로부터 얻은 문맥 정보에 크게 의존한다는 관찰에 기반한다. 따라서, 문맥 모듈(Contextual Module, CM) 을 통해 각 픽셀의 문맥 정보를 캡처하여, 더 다양하고 문맥에 기반한 특징을 생성할 수 있다.
이 문맥 정보는 공간적 배열뿐만 아니라 객체의 위치, 배경, 객체의 자세 등을 포함한 다양한 요소로 구성된다. 문맥 모듈은 이러한 정보를 활용하여 픽셀 단위로 보다 정확한 특징을 생성한다.
3.2 Contextual Module
Contextual Module (CM) after the backbone E of Deeplabv2
Multi-scale Context Maps
we use three serial dilated convs and refer to the output context maps of these layers as respectively.
세 개의 연속된 확장 컨볼루션(dilated convolution) 레이어를 사용하여 다른 스케일(크기)에서의 문맥 정보를 수집한다. 이러한 과정은 각 픽셀이 더 넓은 영역에서 문맥 정보를 수집하도록 돕는다.
Context Selector
Contextual Latent Code
3.3 Context-aware Feature Generator
3.4 Optimization
