ZegFormer : Decoupling Zero-Shot Semantic Segmentation
https://arxiv.org/pdf/2112.07910
Inspired by the observation that humans often perform segment-level semantic labeling, we propose to decouple the ZS3 into two sub-tasks: 1) a class agnostic grouping task to group the pixels into segments. 2) a zero-shot classification task on segments.
zero-shot segmentation
- 기존 방법들은 주로 픽셀 수준에서 제로샷 분류 문제로 ZS3를 정의하고, 언어 모델을 활용하여 학습된 카테고리에서 보지 못한 카테고리로 지식을 전이하는 방식. 그러나 ZegFormer는 이러한 기존 방식의 문제점을 해결하기 위해 세그먼트 수준에서 접근하는 새로운 방법을 제안
- 사람의 시각적 인식 과정처럼, 픽셀들을 먼저 그룹화한 후 세그먼트 전체를 한 번에 분류하는 방식이다. 방식은 픽셀 단위의 분류 오류를 줄이고, 더 큰 맥락에서 객체를 분류하는 데 유리하다.
- 세그먼트 단위로 처리하기 때문에, 픽셀 단위로 모든 것을 계산하는 것보다 상대적으로 단순할 수 있다. 트랜스포머 기반 구조로 세그먼트를 임베딩하고, 세그먼트 수준에서 분류를 진행하기 때문에 확장성이 더 높다. 새로운 클래스가 등장할 때 재학습을 하지 않고도 유연하게 처리할 수 있는 장점이 있다.
1. Introduction
these works(ZS3Net, CaGNet) formulate zero-shot semantic segmentation as a pixel-level zero-shot classification problem.
Although these studies have reported promising results, two main issues still need to be addressed
- They usually transfer knowledge from seen to unseen classes by language models [7,27,54] pre-trained only by texts, which limit their performance on vision tasks. Although largescale pre-trained vision-language models (e.g. CLIP [46] and ALIGN [26]) have demonstrated potentials on imagelevel vision tasks, how to efficiently integrate them into the pixel-level ZS3 problem is still unknown.
보통 텍스트로만 사전 학습된 언어 모델을 통해 seen classes에서 unseen classes까지 지식을 transfer하는데, 이는 vision tasks에서 성능에 한계를 가져온다. largescale pre-trained vision-language models(CLIP, ALIGN 등)이 imagelevel의 vision tasks에서 가능성을 보여주었지만, 이를 pixel-level의 ZS3 문제에 효율적으로 통합하는 방법은 아직 알려지지 않았다. - They usually build correlations between pixel-level visual features and semantic features for knowledge transfer, which is not natural since we humans often use words or texts to describe objects/segments instead of pixels in images. As illustrated in Fig. 1, it is unsurprising to observe that the pixel-level classification has poor accuracy on unseen classes, which in turn degrades the final segmentation quality. This phenomenon is particularly obvious when the number of unseen categories is large (see Fig. 6).
이 연구들은 보통 knowledge transfer를 위해 pixel-level visual features과 semantic features 간의 상관관계를 형성하는데, 이는 자연스럽지 않다. 인간은 보통 이미지 속 픽셀이 아닌 objects/segments를 설명할 때 단어나 텍스트를 사용하기 때문이다. 그림 1에서 보듯이, pixel-level classification가 unseen classes에서 정확도가 낮은 것은 놀랍지 않으며, 이는 final segmentation quality을 저하시킨다. 이 현상은 특히 unseen categories의 수가 많을 때 뚜렷하게 나타난다(그림 6 참조).
직관적인 관찰에 따르면, 우리가 의미 분할을 위한 이미지를 주어졌을 때, 사람들은 먼저 픽셀을 세그먼트로 그룹화한 다음, 세그먼트 수준에서 의미적 레이블을 지정하는 과정을 수행한다. 예를 들어, 어린아이는 객체의 이름을 몰라도 픽셀을 쉽게 그룹화할 수 있다. 따라서 본 논문은 인간과 유사한 제로샷 의미 분할 절차가 두 가지 하위 작업으로 분리되어야 한다고 주장합니다:
- class-agnostic grouping(클래스에 구애받지 않는 그룹화): pixel을 segments로 그룹화하는 작업.
- A segment-level zero-shot classification: 그룹화된 segments에 seen 또는 unseen classes의 semantic labels을 할당.
2. Related Works
Zero-Shot Segmentation
- 학습 중 보지 못한 클래스를 분할하는 새로운 연구 분야
- SPNet: 각 픽셀을 semantic word embedding 공간에 매핑
- ZS3Net: word embedding을 사용해 unseen classes의 pixel-wise features을 생성하는 방식
하지만 pixel-level zero-shot classification problem는 text embedding이 주로 objects/segments를 설명하는 데 사용되므로 ZS3 문제에 적합하지 않을 수 있다. 이에 대한 다양한 해결책들이 제안되었으나, 새로운 클래스가 등장할 때마다 모델을 재학습해야 하는 한계가 있다.
이 문제를 해결하기 위해, 우리는 ZS3를 pixels-level class-agnostic(비의존적)learning과 segment-level zero-shot learning으로 분리한 새로운 방식을 제안하고, ZegFormer를 구현했다. 이 모델은 복잡한 학습 과정 없이 새로운 클래스에 유연하게 적용될 수 있다.
Class-Agnostic Segmentation
여러 연구들은 클래스-비의존적 분할 모델이 학습된 클래스로부터 보지 못한 클래스까지 잘 전이될 수 있음을 보여준다.
최근 엔터티 분할(Entity Segmentation, ES) 이라는 새로운 클래스-비의존적 분할 과제가 제안되었으며, 이를 통해 물체(thing)와 배경(stuff) 클래스 모두에 대한 세그먼트를 예측할 수 있다. 그러나 ES는 인스턴스 인식(instance-aware) 작업으로, 의미 분할(semantic segmentation)과는 다르다. 또한, ES는 보지 못한 클래스에 대한 세부 클래스 이름을 예측하지 않는다.
우리의 연구는 이러한 발견들에서 영감을 받았지만, 우리는 새로운 클래스의 의미 분할에 초점을 맞추며, 보지 못한 클래스의 세부 클래스 이름도 예측한다. 우리의 방법은 더 간단하고 유연하며, 견고한 성능을 보인다.
3. Method
3.1. Decoupling Formulation of ZS3
S as the category set of the annotated dataset D,
the seen classes, and E as those appearing in the testing process, we have three types of settings for semantic segmentation
• fully-supervised semantic segmentation: ,
• zero-shot semantic segmentation (ZS3):
• generalized ZS3 (GZS3) problem: .
Relations to Pixel-Level Zero-Shot Classification.
이전 연구들은 ZS3을 as a pixel-level zero-shot classification problem으로 정의한다. 여기서 학습된 클래스 𝑆 의 픽셀 수준 의미 레이블을 보지 못한 클래스 𝑈의 픽셀로 일반화하는 모델을 사용하는 것
The class-agnostic task has a strong generalization to unseen categories, as demonstrated in [43,45].
Open World Entity Segmentation(https://arxiv.org/pdf/2107.14228)
따라서, 우리의 방식은 𝑆에서 𝑈로 지식을 전이할 때 픽셀 수준 제로샷 분류보다 더 효율적입니다.
3.2. ZegFormer
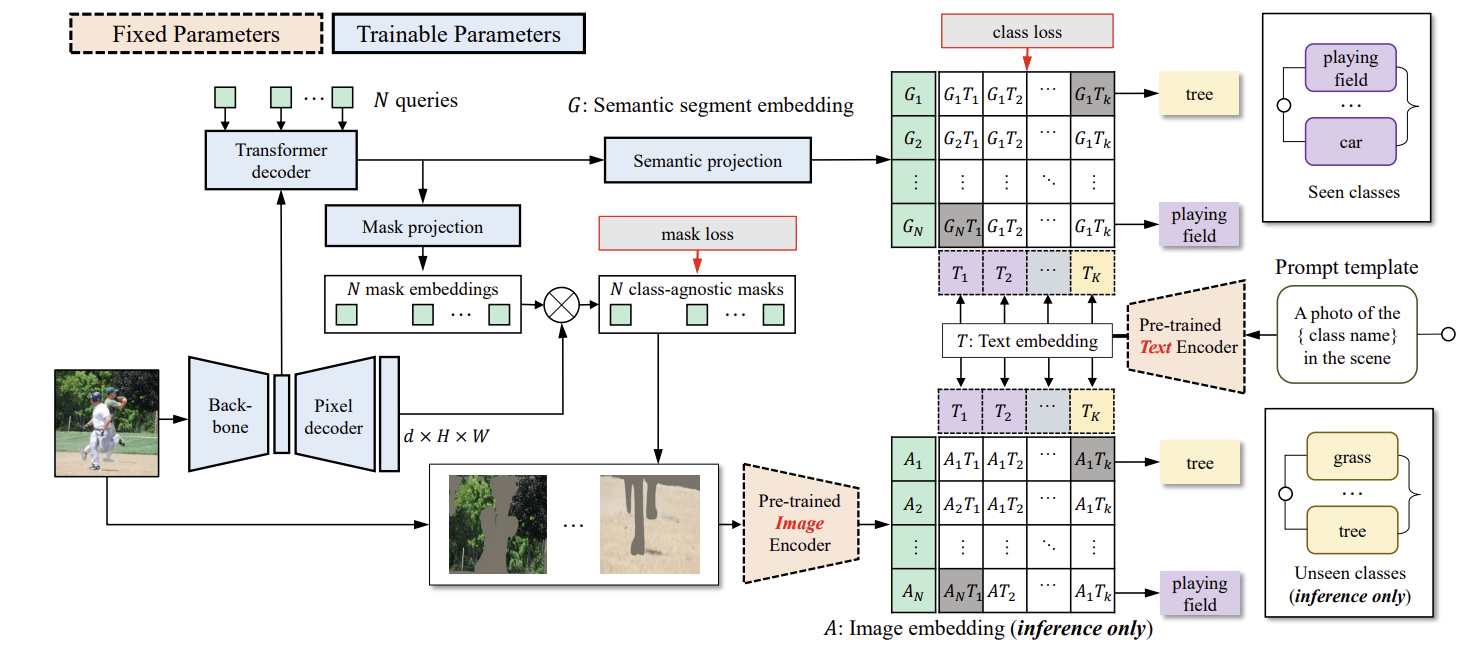
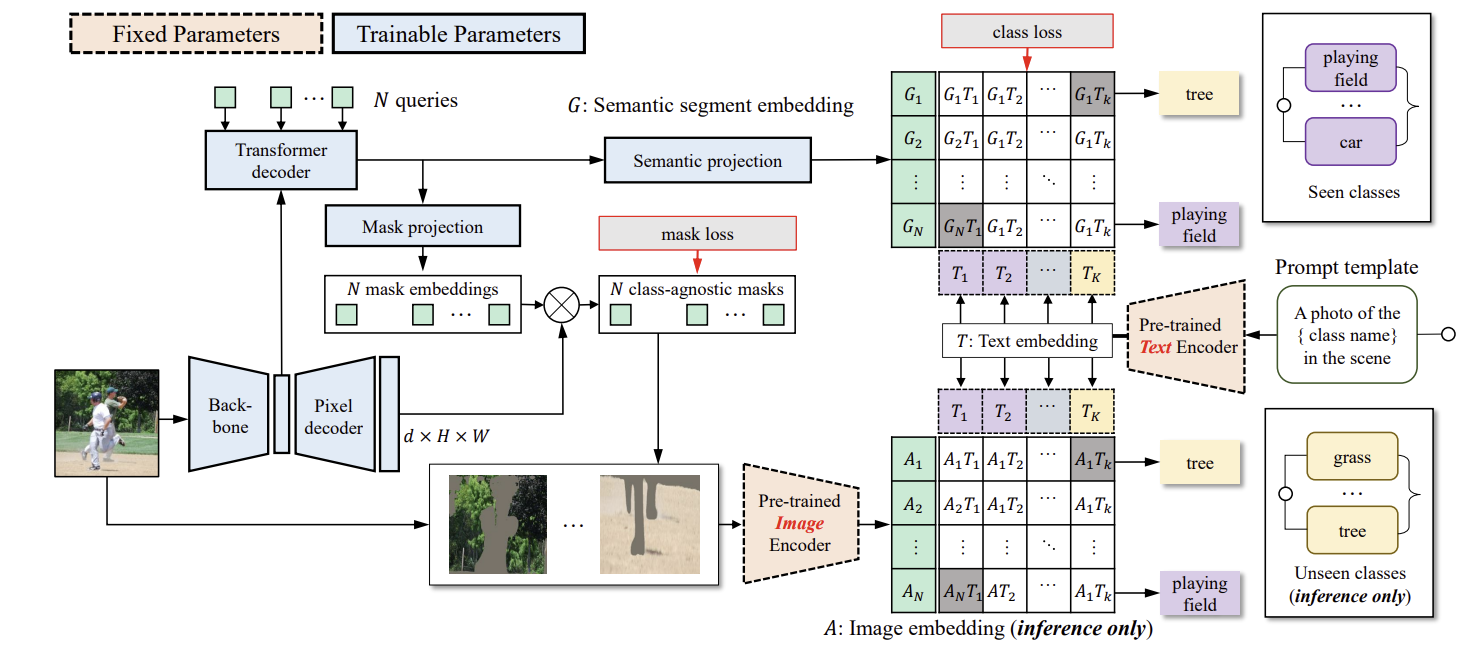
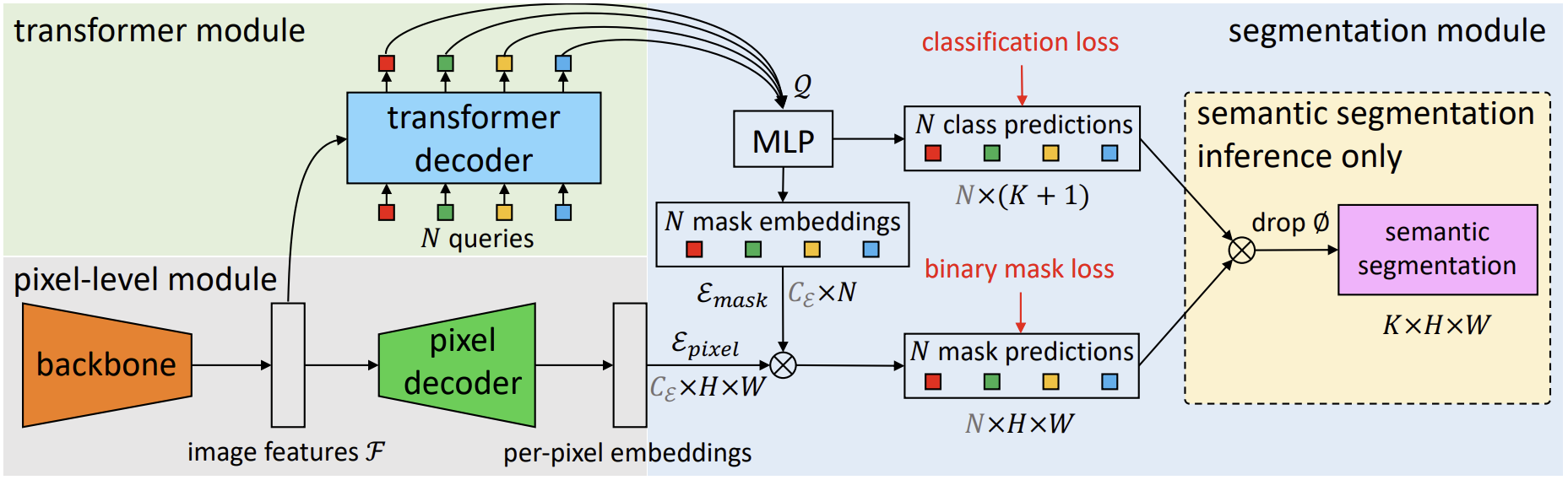
그림 2는 제안된 ZegFormer 모델의 파이프라인을 보여준다. 먼저 segment level embedding을 생성하고, 이를 두 개의 병렬 레이어를 통해 class-agnostic grouping와 segment-level zero-shot classification를 수행한다. 또한, pre-trained image encoder를 사용하여 segment classification를 수행한다. 두 세그먼트 수준의 분류 점수를 최종적으로 결합하여 결과를 도출한다.
ZegFormer의 pipeline
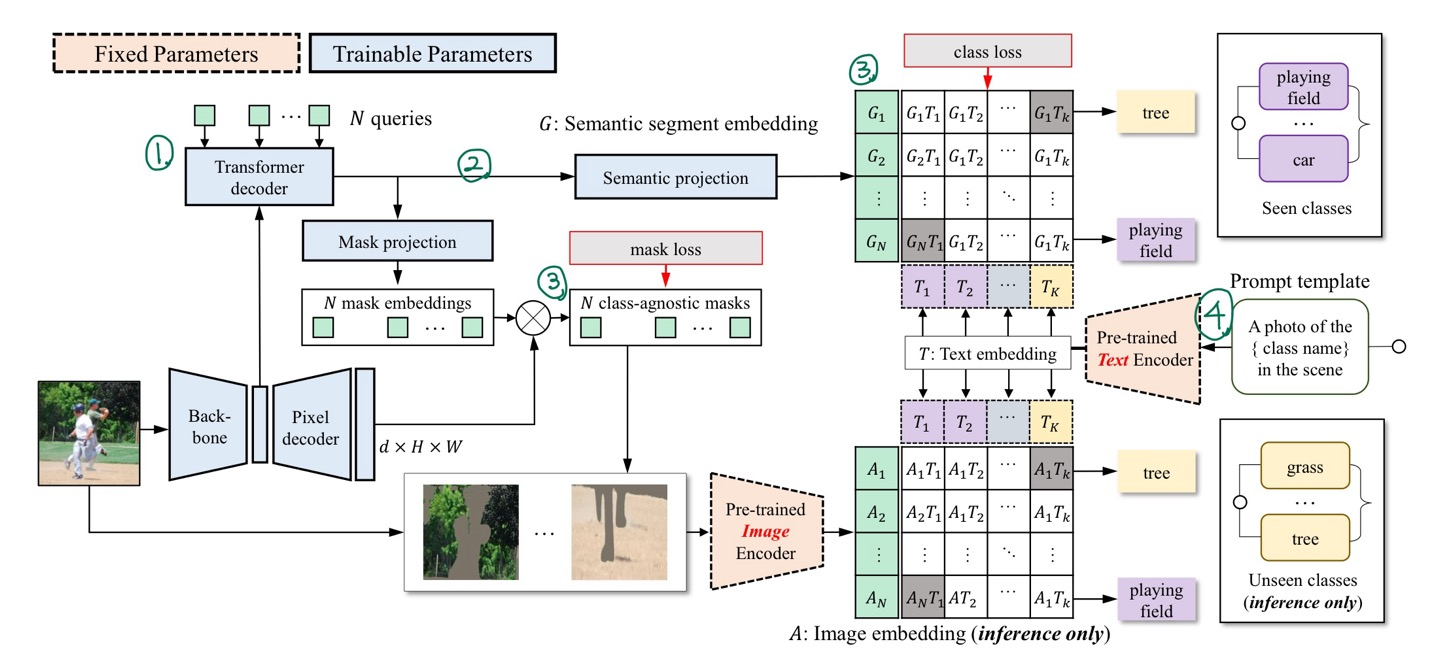
1. N queries와 feature maps을 transformer decoder에 입력하여 N segment embeddings을 생성
2. 각 segment embedding을 mask projection layer와 semantic projection layer에 입력하여 mask embedding과 semantic embedding을 얻는다.
3. Mask embedding은 pixel decoder의 출력과 곱해져 class-agnostic binary mask를 생성하고, semantic embedding은 text embeddings을 통해 분류된다.
4. Text embeddings은 class names을 prompt template에 넣고 vision-language model의 text encoder에 입력하여 생성된다.
5. 학습 중에는 학습된 클래스만을 사용해 segment-level classification head를 학습하며, 추론 시에는 학습된 클래스와 보지 못한 클래스 모두의 text embeddings을 사용해 segment-level classification을 수행한다.
6. semantic segment embeddings과 image embeddings을 사용해 두 가지 segment-level classification scores를 얻을 수 있다. 이 두 classification scores를 결합하여 segments의 최종 class prediction을 도출한다.
Segment Embeddings
- Maskformer(https://arxiv.org/pdf/2107.06278, 2021) : basic segmentation model
Maskformer: Per-Pixel Classification is Not All You Need for Semantic Segmentation
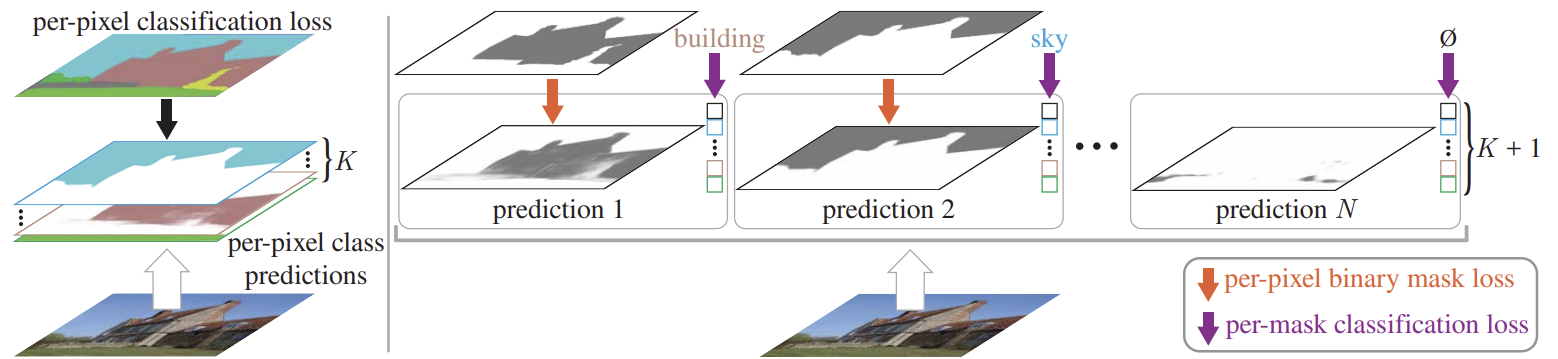
 1.1 predicts a set of binary masks and assigns a single class to each mask. Each prediction is supervised with a per-pixel binary mask loss and a classification loss.
1.1 predicts a set of binary masks and assigns a single class to each mask. Each prediction is supervised with a per-pixel binary mask loss and a classification loss.
1.2 Matching between the set of predictions and ground truth segments can be done either via bipartite matching similarly to DETR.
1.3 N queries : N classes into embedding vector
Transformer decoder에서 이 queries는 이미지 feature map과 함께 입력되어, 각각의 segment에 대한 전역 정보를 인코딩하는 N개의 세그먼트 임베딩을 생성하는 역할을 한다. 간단히 말해, queries는 트랜스포머 구조에서 각 segment를 나타내는 embedding vector를 만드는 데 필요한 입력으로 사용된다. - N segment quries and feature map to transformer decoder -> semantic projection -> semantic embedding
N segment quries and feature map to transformer decoder -> mask projection -> mask embedding - segment-level semantic embedding (SSE) :
segment-level mask embedding :
Class-Agnostic Grouping
- feature maps out from pixel decoder :
- binary mask prediction for each query :
- N is usually smaller than the number of classes.
Segment Classification with SSE
학습과 추론을 위해, class names 집합 내의 각 class name을 프롬프트 템플릿에 넣는다.(예: "A photo of a {class name} in the scene") 그런 다음 이를 text encoder에 전달한다. 이렇게 하면 |C| text embeddings을 얻을 수 있으며, 이를 로 나타낸다. 여기서 C는 학습 중에는 S에 해당하고, 추론 중에는 가 된다. (학습된 클래스 𝑆, 보지 못한 클래스 𝑈) 우리의 파이프라인에서 "no object" 카테고리도 필요하다. 이는 세그먼트와 실제 값 간의 IoU가 낮을 때 해당된다. "no object" 카테고리는 단일 class name으로 표현하는 것이 부적절하므로, 추가적인 학습 가능한 embedding 을 추가한다.
segment query에 대해 seen classes들과 "no object"에 대한 예측 확률 분포는 다음과 같이 계산된다.
Segment Classification with Image Embedding
위에서 설명한 단계들은 이미 ZS3를 위한 standalone approach를 형성할 수 있지만, pre-trained vision-language model(예: CLIP [46])의 image encoder를 사용하여 세그먼트의 분류 정확도를 향상시키는 것도 가능하다. 이는 decoupling formulation의 유연성 덕분이다. 이 모듈에서는 세그먼트에 적합한 sub-image를 생성한다. 이 과정은 mask prediction 가 주어진 쿼리 q와 입력 이미지 I를 이용해, sub-image 를 생성하는 것으로 공식화할 수 있다. 여기서 f는 전처리 함수(예: 마스크된 이미지 또는 에 따라 잘린 이미지)이다. Sec. 4.5에서는 이에 대한 ablation studies를 제공합니다. 우리는 를 pre-trained image encoder에 전달하여 image embedding 를 얻습니다. Eq. 1과 유사하게, 우리는 확률 분포를 계산할 수 있으며, 이는 로 표기된다.
Training
ZegFormer의 학습 과정에서는 S에 속하는 픽셀 레이블만 사용된다. 학습 손실을 계산하기 위해 이분 매칭(bipartite matching) 이 예측된 마스크와 ground-truth masks 사이에서 수행된다. 각 세그먼트 쿼리에 대한 분류 손실은 다음과 같이 계산된다:
여기서 는 해당 segment가 ground-truth mask와 일치하는 경우 S에 속하며, 일치하는 ground-truth segment가 없는 경우에는 "no object"로 설정된다. ground-truth segment 와 일치하는 세그먼트에 대해서는 mask 손실 가 있습니다. 구체적으로, 우리는 dice 손실과 focal 손실의 조합을 사용한다.
Inference
4. Experiments
4.1 Datasets and Evaluation Metric
ADE20k-Full Dataset
annotated in an open-vocabulary setting with more than 3,000 categories.
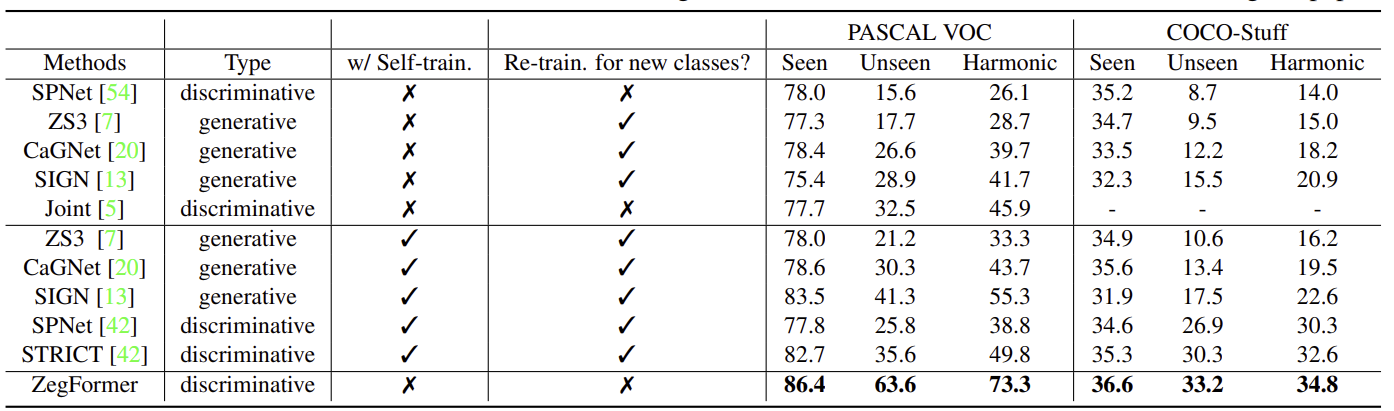
4.6 Comparision with the SOTA
5. Visualization
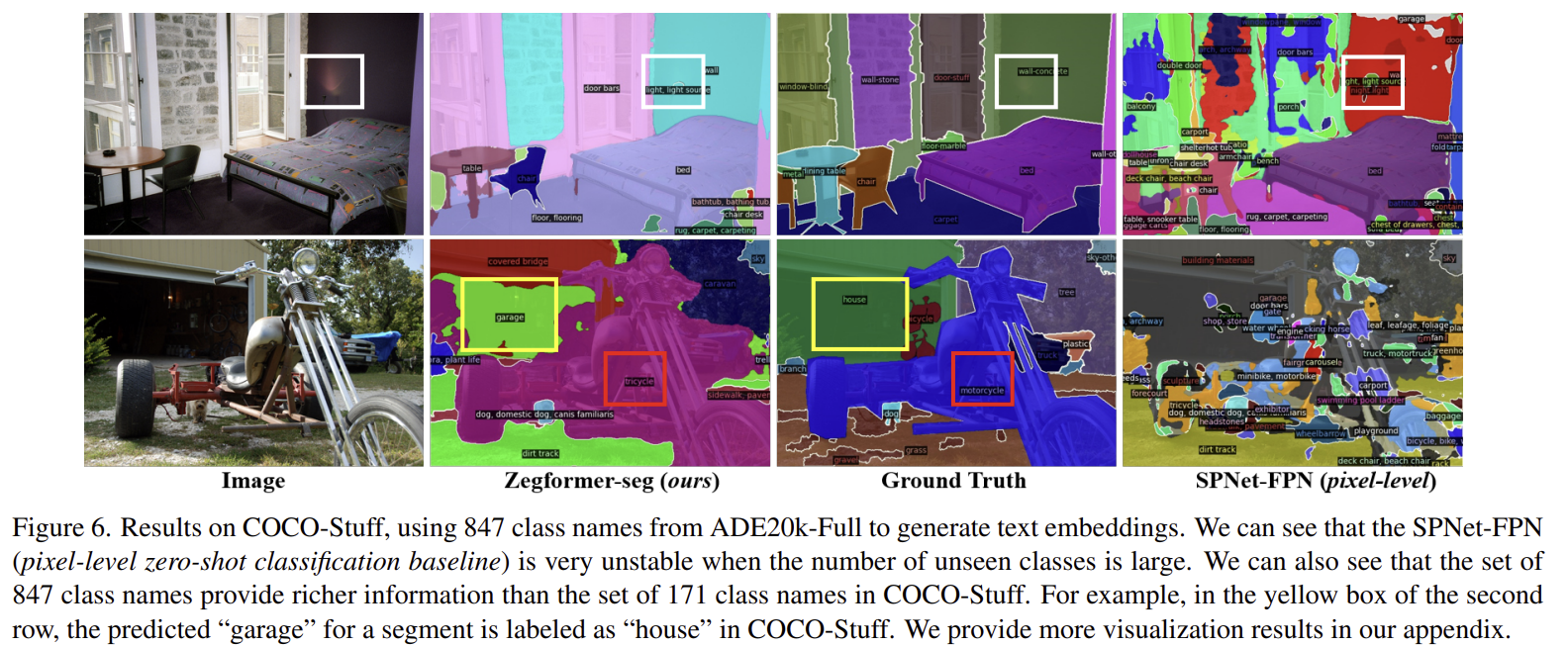
Results with 847 classes from ADE20k-Full
 SPNet-FPN(픽셀 수준 제로샷 분류 기준선)이 보지 못한 클래스의 수가 많을 때 매우 불안정하다는 것을 확인할 수 있다. 또한 847개 클래스 이름이 COCO-Stuff의 171개 클래스 이름보다 더 풍부한 정보를 제공한다는 것을 알 수 있다. 예를 들어, 두 번째 행의 노란색 상자에서 세그먼트에 대해 예측된 "garage"가 COCO-Stuff에서는 "house"로 레이블링되었다.
SPNet-FPN(픽셀 수준 제로샷 분류 기준선)이 보지 못한 클래스의 수가 많을 때 매우 불안정하다는 것을 확인할 수 있다. 또한 847개 클래스 이름이 COCO-Stuff의 171개 클래스 이름보다 더 풍부한 정보를 제공한다는 것을 알 수 있다. 예를 들어, 두 번째 행의 노란색 상자에서 세그먼트에 대해 예측된 "garage"가 COCO-Stuff에서는 "house"로 레이블링되었다.
