Ziyi Li, Qinye Zhou, Xiaoyun Zhang, Ya Zhang, Yanfeng Wang, Weidi Xie
0. Abstract
이 논문의 목표는 pre-trained text-to-image diffusion model로부터 visual-language correspondence를 segmentation map 형식으로 추출하는 것이다. 즉, text prompt에 따라 생성된 image와 해당 visual entities의 segmentation masks를 동시에 생성하는 것을 목표로 한다. 이 논문에서는 다음과 같은 기여를 한다:
-
Stable Diffusion model과 새로운 grounding module의 결합: 기존 Stable Diffusion model에 새로운 grounding module을 추가하여 visual과 textual embedding space를 소수의 object categories만으로도 align할 수 있도록 학습할 수 있다.
-
automatic dataset construction pipeline 구축: 제안한 grounding module을 학습하기 위해 {image, segmentation mask, text prompt} triplets로 구성된 dataset을 자동으로 생성할 수 있는 pipeline을 설계했다.
-
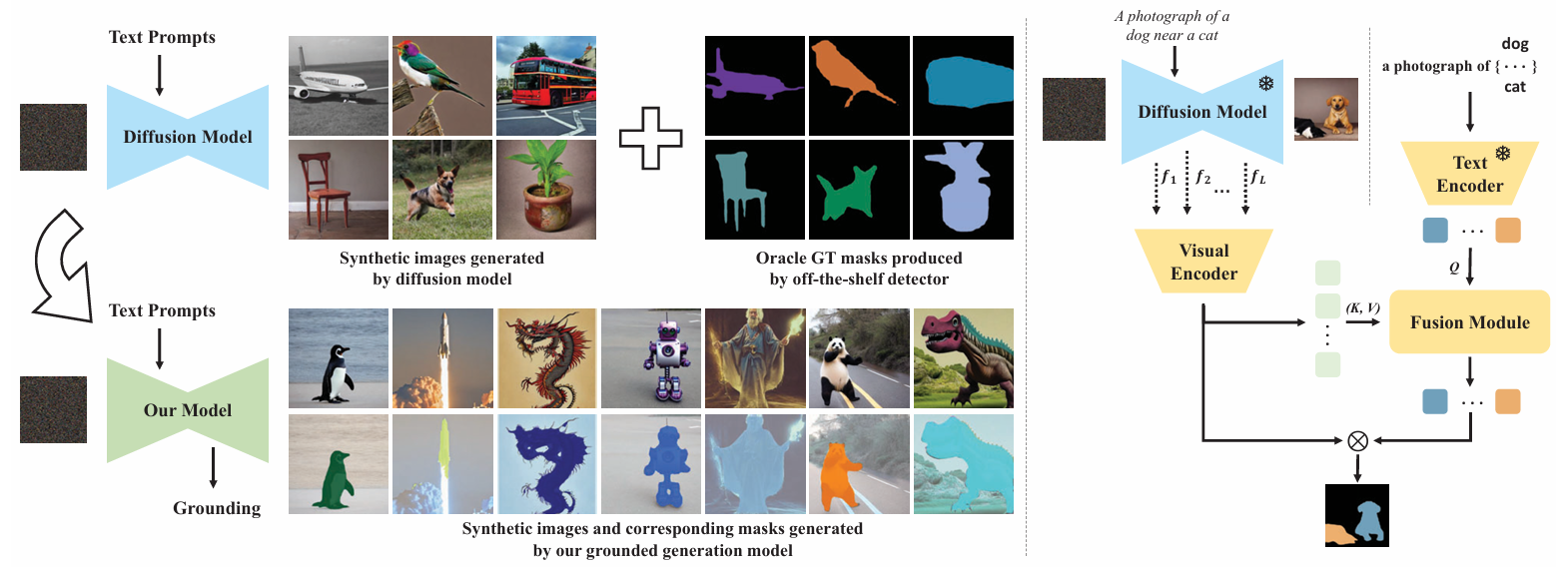
open-vocabulary grounding 성능 평가: text-to-image diffusion model로 생성된 image에 대해 open-vocabulary grounding 성능을 평가한 결과, training 시 보지 못한 categories의 objects까지 잘 segment할 수 있음을 확인했다(Fig. 1 참고).
-
augmented diffusion model을 사용하여 synthetic semantic segmentation dataset 구축: 이러한 dataset으로 standard segmentation model을 훈련한 결과, zero-shot segmentation (ZS3) benchmark에서 경쟁력 있는 성능을 보였으며, 이는 powerful diffusion model을 discriminative tasks에 적용할 새로운 가능성을 열어준다.
1. Introduction
1. Introduction
최근 연구에서, text-to-image generative models는 연구 커뮤니티와 대중에게 많은 관심을 받고 있으며, 이러한 모델의 주요 장점 중 하나는 대규모 image-caption pairs 데이터로부터 학습된 visual pixels와 language 사이의 강력한 correspondence이다. 예를 들어, 이러한 correspondence를 통해 자유로운 형식의 text prompt로부터 사실적인 images를 생성할 수 있다 [26,27,30,41]. 본 논문에서는, 이러한 visual-language correspondence를 segmentation map 형태로 generative model에서 명시적으로 추출하고자 하며, 즉, 사실적인 images를 생성함과 동시에 text prompts에 기술된 시각적 objects의 segmentation masks를 추론하고자 한다. 이러한 visual-language correspondence를 generative model에서 추출하는 이점은 크다. 모델의 vocabulary 내에서 각 category에 대해 픽셀 단위 segmentation을 통해 무한한 images 샘플을 합성할 수 있으며, 이는 판별적 segmentation 또는 detection models의 성능을 향상시키기 위한 자유로운 자원으로 활용될 수 있다.
이를 달성하기 위해, 우리는 기존 Stable Diffusion [27] 모델과 새로운 grounding module을 결합하여, text prompt에 따라 생성된 image에서 해당 visual objects를 segment할 수 있도록 제안한다. 이는 원하는 entity의 text embedding space와 합성 images의 visual features, 즉 diffusion model의 중간 layers를 명시적으로 정렬하여 달성된다. 학습이 완료되면, 관심 objects는 학습 중 본 objects와 보지 못한 objects 모두에서 category names를 통해 segmented될 수 있으며, 이는 generative model에 대한 open-vocabulary object segmentation과 유사하다.
제안된 architecture를 제대로 학습시키기 위해, 우리는 {synthetic image, segmentation mask, text prompt}로 구성된 dataset을 자동으로 구축하는 pipeline을 설계한다. 특히, 우리는 사전 학습된 object detector를 사용하여 Stable Diffusion model로 생성된 images에 대한 inference를 수행함으로써 추가적인 수작업 레이블링 없이 dataset을 구성한다. 이 pipeline은 이론적으로 기존 object detector의 vocabulary 내 각 category에 대해 무한한 data samples를 생성할 수 있도록 한다. 예를 들어, 우리는 COCO에서 80개 categories로 학습된 Mask R-CNN [22]을 채택한다. 우리는 사전 정의된 object categories 세트에서 학습된 grounding module이 Stable Diffusion의 images를 어떤 off-the-shelf detector의 vocabulary를 초과하여 segment할 수 있음을 보여준다. 예를 들어, Pikachu, unicorn, phoenix와 같은 categories도 segmented가 가능하며, 이는 visual-language correspondence를 확립하기 위한 visual instruction tuning과 유사하다.
제안된 grounding module의 효과를 정량적으로 검증하기 위해 두 가지 평가 protocols를 시작한다. 첫째, 합성 images에서 강력한 object detector와 segmentation 결과를 비교한다. 둘째, Stable Diffusion과 우리의 grounding module을 사용하여 합성된 semantic segmentation dataset을 구축한 후, 이를 기반으로 segmentation model을 훈련한다. COCO와 PASCAL VOC에서 zero-shot segmentation (ZS3)을 평가하는 동안, 우리는 이전의 최신 모델들보다 미학습 categories에서 더 뛰어난 성능을 보였고, 학습된 categories에서도 경쟁력 있는 성능을 나타냈다. 더욱 중요한 점은, generative model로부터의 합성 data를 사용하여 discriminative models를 훈련하는 매력적인 응용 가능성을 제시했다는 것이다. 예를 들어, 기존 object detector가 다룰 수 있는 vocabulary를 초과하여 categories를 확장할 수 있다.
2. Preliminary on Diffusion Model
Stable Diffusion
-
VAE
고차원 데이터를 저차원 공간으로 인코딩: 이미지와 같은 고차원 데이터를 Encoding을 통해 저차원의 Hidden Space(숨겨진 공간)로 표현한다. 이는 데이터를 압축하여 주요 특징만을 보존하는 방식이다.
Encoder 역할: Encoder는 입력 데이터를 Latent Space로 맵핑하는 역할을 한다. 이 과정은 PCA와 같은 성분 분해의 개념과 유사하다. Latent Space는 입력 데이터의 중요한 정보(특징)를 담은 저차원 공간을 의미한다. 이 공간에 있는 변수들은 Latent Variables라 불리며, 데이터의 본질적인 특성을 나타낸다.
Decoder 역할: Decoder는 Latent Space에서 얻어진 주요 요소들을 다시 원래 데이터 형태로 복원하는 역할을 한다.이를 통해 입력 데이터의 중요한 정보만을 유지하면서 원래 데이터와 유사한 출력을 생성할 수 있다. -
Diffusion
Stable Diffusion : VAE + Diffusion
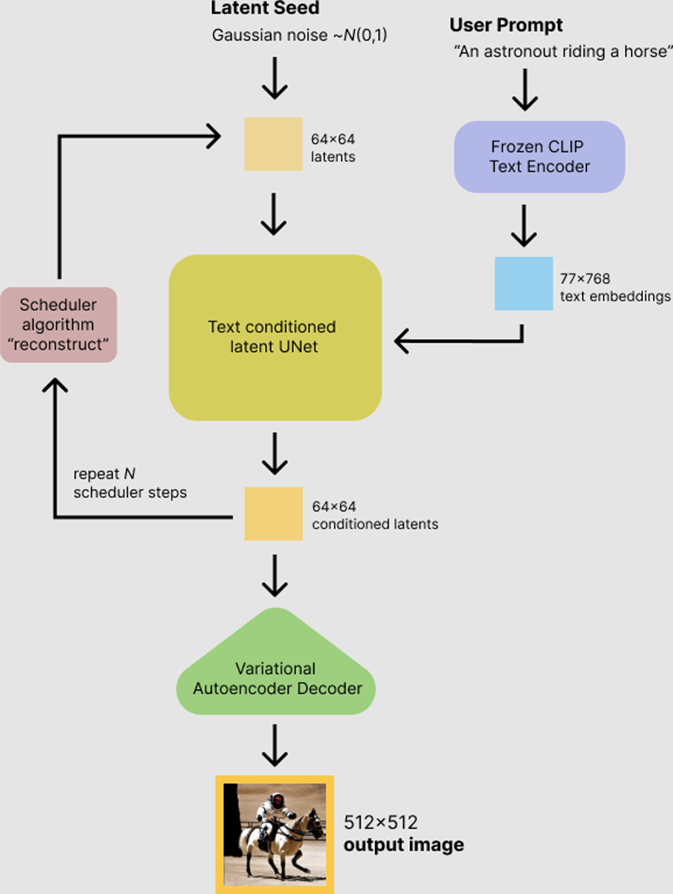
먼저, 텍스트 인코더 (Text Encoder)가 있습니다. 사용자가 입력한 텍스트 프롬프트를 기반으로, CLIP 모델을 활용하여 텍스트를 임베딩 벡터로 변환합니다.
그런 다음, Latent U-Net이 임의의 latent vector에서 노이즈를 제거합니다. 이 단계에서는 64x64 크기의 latent 벡터가 생성되며, U-Net이 해당 벡터의 노이즈를 반복적으로 줄여가며 이미지 정보를 형성합니다.
마지막으로, Decoder가 64x64 잠재 벡터에서 고해상도의 이미지를 복원합니다. 여기서 VAE가 잠재 벡터를 512x512 크기의 최종 이미지로 디코딩하게 됩니다
U-Net은 픽셀이 아닌 latent 벡터를 처리하며, VAE가 이를 고해상도 이미지로 변환합니다. 이는 모델이 직접 픽셀을 처리하지 않고, 잠재 공간에서 압축된 데이터를 활용하여 더 효율적으로 고품질 이미지를 생성할 수 있도록 하여 효율이 diffusion 보다 높습니다.
-
Denoising 과정에서 AutoEncoder 사용:
- 이미지 노이즈를 제거하는 Denoising 과정에서 AutoEncoder를 사용한다. 이는 이미지의 주요 특징을 압축하고 복원하는 과정을 통해 노이즈를 줄이고 고해상도 이미지를 생성하는 데 기여한다.
-
Latent Space에서 Denoising 수행:
- Pixel 공간이 아닌 Latent Space에서 Denoising을 수행함으로써, 수많은 GPU가 필요했던 픽셀 기반 계산의 컴퓨팅 비용을 절감할 수 있다. 이는 Latent Space에서 저차원 데이터로 작업하기 때문에 연산이 훨씬 효율적이다.
-
모델의 복잡성 감소 및 표현력 증가:
- Latent Space에서 작업함으로써 모델의 복잡성이 줄어들고, 대신 이미지의 세부적인 표현력을 높일 수 있다. 이는 고해상도 이미지를 생성할 때 더 효율적이다.
-
Cross-Attention 사용:
- 모델 아키텍처에 Cross-Attention을 포함시킴으로써, 다른 도메인(예: 텍스트, 오디오 등)에서 입력을 받아들여 다중 모달 모델로 사용할 수 있다. 이는 텍스트-이미지 합성이나 오디오-비디오 변환 등 다양한 응용 분야에서 유용하게 사용될 수 있다.
3. Problem Formulation
이 논문에서는 기존의 text-to-image diffusion model에 open-vocabulary segmentation 기능을 추가하는 것을 목표로 합니다. 이를 위해 visual-language correspondence를 활용하여, 텍스트 프롬프트에 기술된 객체의 segmentation masks를 이미지와 함께 동시에 생성할 수 있도록 한다.
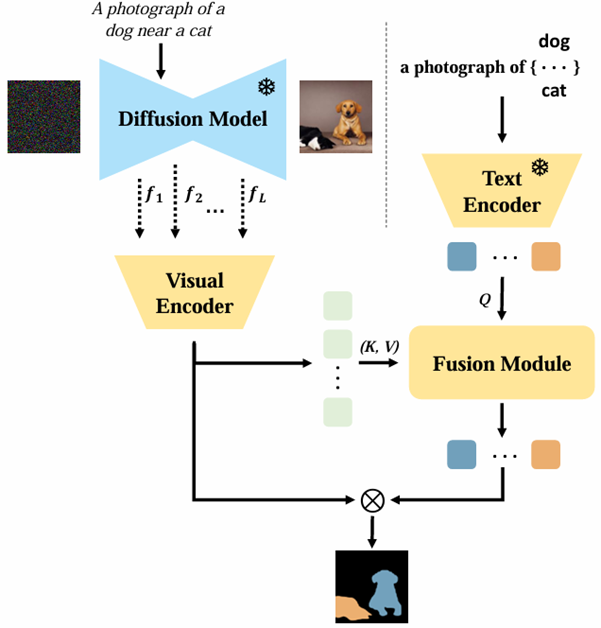
는 사전 학습된 text-to-image diffusion model에 grounding module을 추가한 것을 의미합니다. 이 모델은 샘플링된 노이즈 𝜖∼𝑁(0,𝐼) 와 언어 설명 y를 입력으로 받아 이미지 와 해당 객체의 segmentation masks 을 생성합니다. 여기서 는 관심 있는 객체의 총 개수입니다.
특히, 이 모델은 open-vocabulary를 지향하여, semantic categories의 제한 없이 diffusion model이 생성할 수 있는 모든 객체에 대해 해당하는 segmentation mask를 출력할 수 있어야 한다.
4. Open Vocabulary Grounding
- grounding의 의미
논문에서 "grounding"은 텍스트 프롬프트와 시각적 객체 간의 정확한 대응 관계를 확립하는 과정을 의미한다. 구체적으로, 이 논문에서 grounding은 text-to-image diffusion model에서 생성된 이미지와 텍스트 지시어 간의 의미적 연결을 강화하여, 텍스트에 기술된 객체가 이미지 내에서 정확하게 분할될 수 있도록 하는 역할을 한다.
논문에서는 이를 위해 grounding module을 제안하고 있으며, 이 모듈은 텍스트와 시각적 임베딩 공간을 명시적으로 정렬(explicitly align)하여 open-vocabulary grounding 능력을 제공한다. 이 과정에서 grounding module은 텍스트 프롬프트에 포함된 특정 객체의 이름과 시각적 특징을 연결하여, 모델이 학습한 범위를 넘어서서 다양한 객체들을 효과적으로 분할할 수 있게 한다.
따라서, grounding의 핵심 의미는 텍스트와 시각적 정보 사이의 일관된 매핑을 통해 다양한 객체를 이해하고 정확하게 분할하는 능력이라고 볼 수 있다. 이를 통해 diffusion model이 생성한 이미지에서도 텍스트에 기술된 객체들을 잘 인식하고 분할할 수 있도록 하는 것이 목적이다.
4.1 Data Construction
 Open-vocabulary Grounding을 위한 데이터셋 구성 방법은 다음과 같다.
Open-vocabulary Grounding을 위한 데이터셋 구성 방법은 다음과 같다.
먼저, 다양한 텍스트 프롬프트를 생성하여 학습 데이터셋을 구성한다. 이를 통해 visual feature, segmentation map, 텍스트 프롬프트로 이루어진 트리플릿이 형성되며, 이 과정에서 무한히 많은 이미지-텍스트 쌍을 생성할 수 있다. 이를 통해 모델이 다양한 객체와 상황을 학습하게 된다.
그다음, off-the-shelf 객체 탐지기를 사용하여 각 이미지에 대한 세그멘테이션 마스크를 생성한다. 이 단계에서는 사전 학습된 Mask R-CNN을 사용하여 생성된 이미지 에 대해 ground truth 세그멘테이션 마스크
를 얻는다.
이와 같은 방법으로 실제 데이터에 대한 수작업 없이도 합성된 데이터만으로 모델을 훈련시킬 수 있다. 또한 다양한 텍스트 프롬프트와 이미지 조합을 통해 폭넓은 카테고리를 학습하는 것이 가능하다.
4.2 Architecture
Visual Encoder
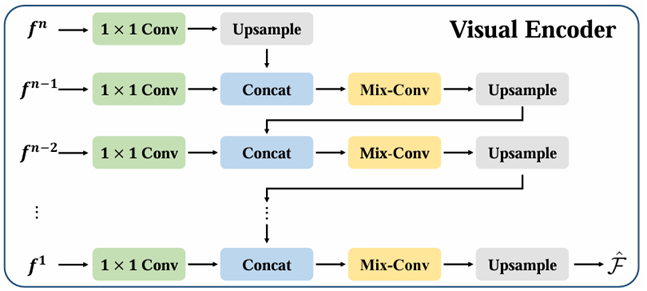 먼저, U-Net의 여러 레이어에서 추출된 잠재 특징들 을 결합한다. 이 잠재 특징들은 다양한 해상도를 가지고 있으며, 이를 결합하여 Visual Encoder로 입력한다.
먼저, U-Net의 여러 레이어에서 추출된 잠재 특징들 을 결합한다. 이 잠재 특징들은 다양한 해상도를 가지고 있으며, 이를 결합하여 Visual Encoder로 입력한다.
Visual Encoder의 주요 구성 요소는 다음과 같다:
1x1 Conv: 특징의 차원을 줄여 계산 효율성을 높인다.
Upsample: 특징의 공간 해상도를 증가시켜 더 세밀한 정보를 확보한다.
Concat: 여러 특징을 결합하여 다양한 정보를 하나의 특징으로 모은다.
Mix-Conv: 서로 다른 공간 해상도를 가진 특징들을 혼합하여 다양한 스케일의 정보를 융합한다.
Text Encoder
Text Encoder는 Stable Diffusion에서 사용하는 언어 모델로, CLIP 모델의 텍스트 인코더를 그대로 사용한다. 이 텍스트 인코더는 이미 사전 학습된 모델로, 텍스트 프롬프트를 통해 visual feature에 대한 정보를 효과적으로 인코딩할 수 있다.
Text Encoder는 모든 visual feature에 대한 임베딩을 생성하는 역할을 한다. 여기서 는 주어진 텍스트 프롬프트 에 따라 객체의 카테고리를 포함하는 임베딩을 생성하는 과정을 나타낸다.
Fusion module
Fusion Module은 visual 임베딩과 text 임베딩 간의 상호작용을 계산하여 두 정보가 합쳐진 임베딩을 생성한다. 각 객체에 대한 세그멘테이션 임베딩은 다음과 같은 수식을 통해 생성된다:
최종 세그멘테이션 마스크 는 이 임베딩을 기반으로 계산된다. 이를 통해 최종적으로 grounding module이 예측한 세그멘테이션 맵이 생성된다.
4.3 Training
Open-vocabulary Grounding 모델의 학습 과정에 대해 설명하면 다음과 같다. 먼저, Ground truth로 사용되는 오라클 세그멘테이션 마스크 는 별도의 학습 없이 사용할 수 있는 신뢰할 수 있는 객체 탐지 모델인 off-the-shelf detector에서 생성된다. 이 마스크는 모델이 예측한 세그멘테이션 마스크 와 비교된다.
모델의 학습 손실 함수는 Binary Cross-Entropy Loss를 기반으로 하며, 다음과 같은 수식으로 표현된다:
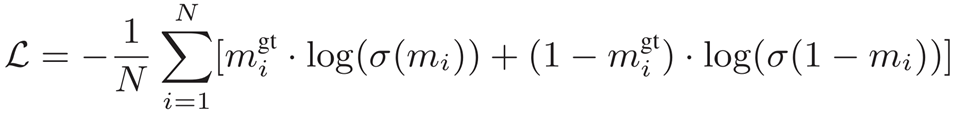 Ground truth의 정확도는 모델의 성능에 매우 중요하다.
Ground truth의 정확도는 모델의 성능에 매우 중요하다.
그러나 off-the-shelf detector는 두 가지 경우에 세그멘테이션 마스크를 생성하지 못할 수 있다. 첫 번째는 Diffusion Model이 저품질의 이미지를 생성하는 경우이며, 두 번째는 특정 객체를 탐지하지 못하는 경우다.
이 문제를 해결하기 위해 두 가지 학습 전략을 사용한다:
Normal training: 오라클로 제공되는 모든 탐지 결과를 그대로 신뢰하여 학습하는 방식이다.
Training without zero masks: 탐지 실패로 인해 생성된 모든 0 마스크를 제외하고 학습하여 false negative를 줄이는 방식이다.
이러한 다양한 학습 전략을 통해 모델의 성능을 최적화하고, 특히 unseen 카테고리에 대한 세그멘테이션 성능을 향상시키고자 한다.
5. Experiments
Protocol-I: Open-vocabulary Grounding
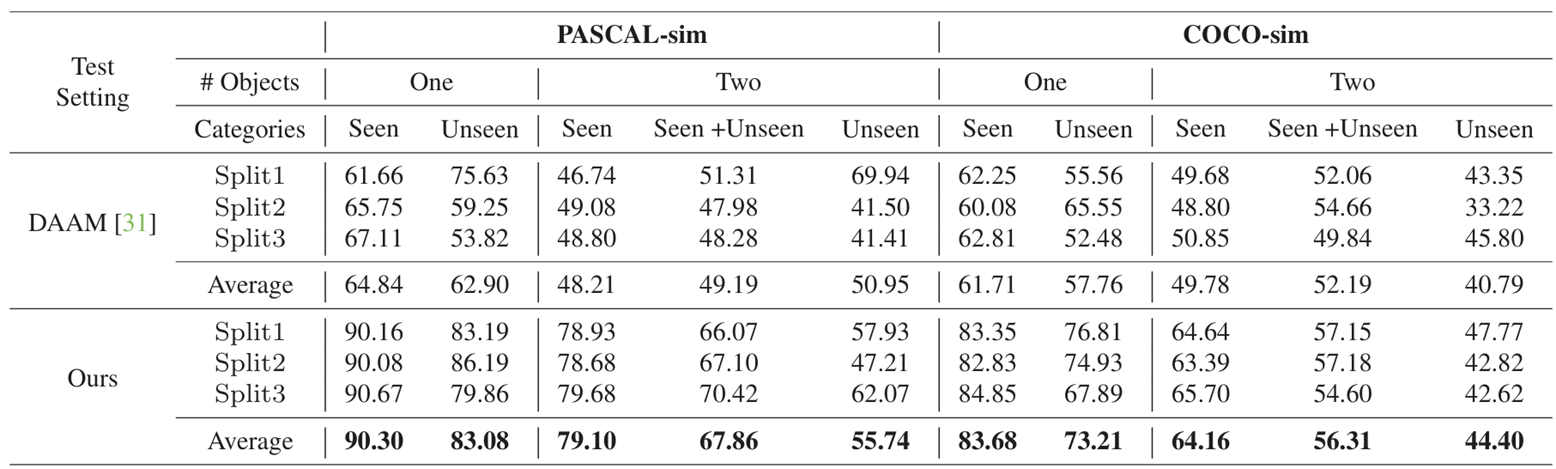 이 논문에서는 두 가지 실험 결과를 다룬다. 첫 번째 실험의 목표는 Grounding 모듈이 학습되지 않은 카테고리에 대해 얼마나 잘 일반화할 수 있는지를 평가하는 것이다. 즉, 모델의 open vocabulary 능력을 확인하는 데 중점을 두고 있다.
이 논문에서는 두 가지 실험 결과를 다룬다. 첫 번째 실험의 목표는 Grounding 모듈이 학습되지 않은 카테고리에 대해 얼마나 잘 일반화할 수 있는지를 평가하는 것이다. 즉, 모델의 open vocabulary 능력을 확인하는 데 중점을 두고 있다.
학습 데이터는 합성된 이미지와 세그멘테이션 마스크로 구성되어 있으며, 학습된 seen 카테고리의 객체만 포함한다. 반면, 테스트 데이터는 학습된 카테고리뿐만 아니라 학습되지 않은 unseen 카테고리의 객체를 포함하여 모델을 평가한다.
결과 표를 보면, 본 논문의 모델은 대부분의 설정에서 DAAM[31]보다 높은 성능을 보여주며, 특히 PASCAL-sim과 COCO-sim 데이터셋에서 unseen 카테고리에 대한 성능 향상이 두드러진다. 이는 우리 모델이 다양한 객체를 잘 일반화할 수 있음을 입증한다.
Protocol-II: Open-vocabulary Segmentation

두 번째 실험의 목표는 Protocol-I에서 검증된 grounding 모듈의 성능을 판별적 작업, 특히 semantic 세그멘테이션에 활용할 수 있는지를 확인하는 것이다.
방법: Stable Diffusion과 grounding 모듈을 사용해 합성 이미지-세그멘테이션 데이터셋을 생성하고, 이를 통해 표준 semantic 세그멘테이션 모델인 MaskFormer와 같은 모델을 학습시킨다.
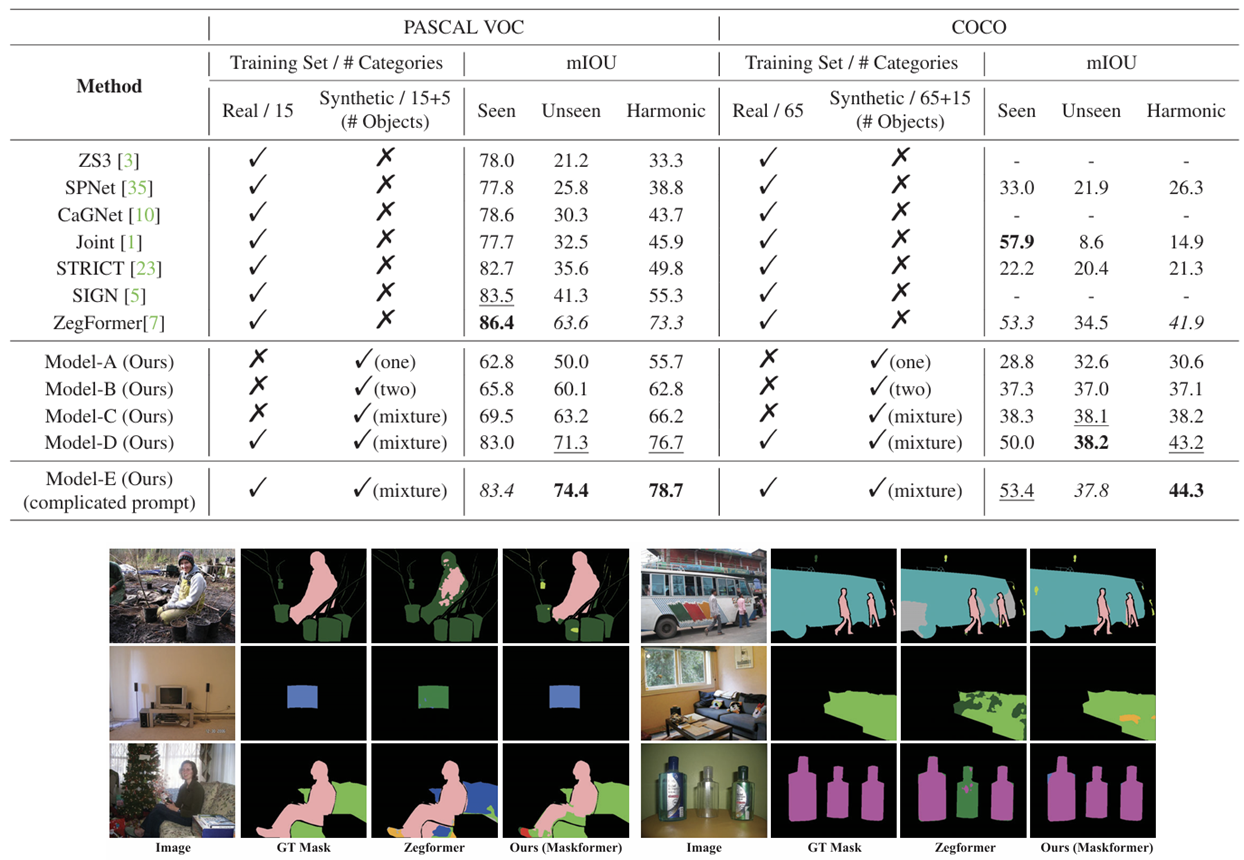
평가 항목: 학습된 세그멘테이션 모델의 제로샷 세그멘테이션 성능을 실제 데이터셋에서 평가하며, unseen 카테고리뿐만 아니라 seen 카테고리에서도 얼마나 잘 작동하는지를 측정한다. 이 모델은 이전 연구인 ZegFormer보다 unseen 카테고리에서 더 높은 성능을 보였으며, 특히 'Model-E'는 PASCAL VOC에서 74.4%, COCO에서 44.3%의 harmonic mIoU 점수를 기록하였다. Ground Truth 마스크와 ZegFormer의 결과, 그리고 본 연구 모델의 세그멘테이션 결과를 비교한 결과, 본 모델이 더 정확하게 객체를 분할하고 높은 품질의 세그멘테이션 마스크를 생성하는 것을 확인할 수 있었다.
이 실험을 통해, 생성된 데이터셋을 활용한 모델이 판별적 작업에서도 강력한 성능을 발휘하며, 다양한 unseen 카테고리에서도 높은 정확도를 유지할 수 있음을 입증하였다.
생각
-
데이터셋을 늘리니까 성능이 높아졌다.??
-
Stable diffusion model의 성능에 좌우된다.
-
Stable Diffusion Model의 계산 비용 → stable diffusion이 diffusion에 비해 계산 비용이 낮아졌지만 zegformer와 비교 부재??
