Towards Open Vocabulary Learning: A Survey
https://arxiv.org/pdf/2307.09220
Zero-Shot
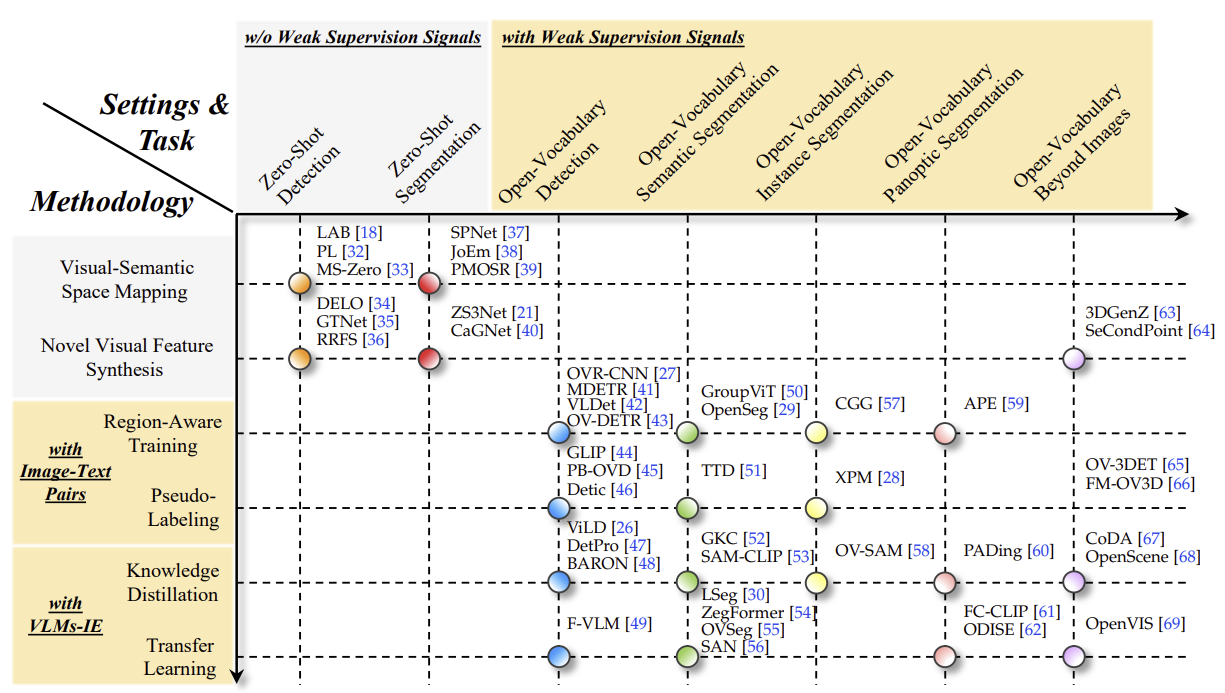
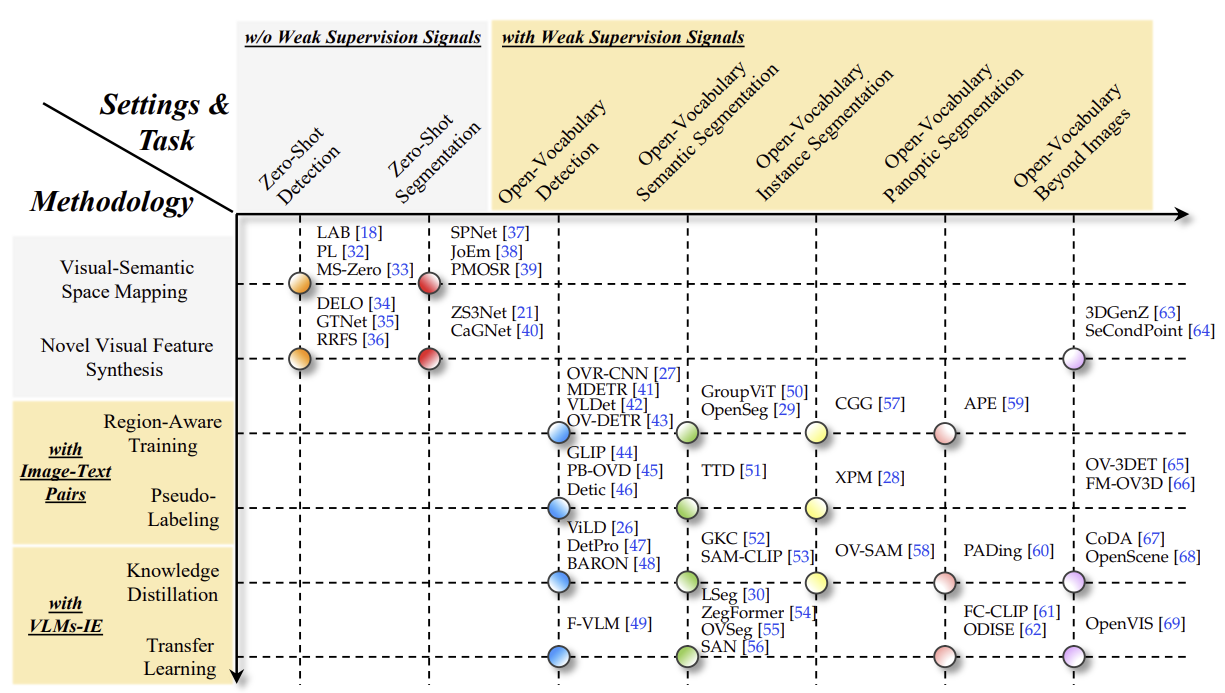
초기 단계에서는 Zero-Shot Detection(ZSD)와 Zero-Shot Segmentation(ZSS)이 처음 제안되었습니다. 이 방법들은 주석되지 않은 미지의 시각적 객체에 대한 접근 없이 시도된 것입니다. 전형적인 방법은 학습 가능한 분류기(완전 연결층)를 고정된 시맨틱 임베딩(예: Word2Vec, GloVe, BERT)으로 대체합니다. 시맨틱 임베딩은 이미 본(base) 범주에서 보지 못한(novel) 범주로 지식을 전이할 수 있게 합니다. 하지만 시맨틱 임베딩은 텍스트 코퍼스만을 바탕으로 비지도 학습되기 때문에 시각적 모달리티와의 정렬이 부족하며, 이는 시맨틱 임베딩이 시각적 공간을 보정하는 기준점으로서 작동하기에 부정확하고 성능 향상을 방해합니다.
Open-Vocabulary
Open-Vocabulary Detection(OVD)와 Open-Vocabulary Segmentation(OVS)은 미지의 객체가 주석되지 않은 이미지로 모델을 학습할 수 있도록 합니다. 이는 닫힌 집합(closed-set)의 한계를 약한 지도 신호(예: 이미지-텍스트 쌍, 이미지 캡션 쌍, 이미지 수준 레이블)나 대규모 사전 학습된 비전-언어 모델(VLMs), 예를 들어 CLIP과 같은 모델을 통해 해결합니다. VLM의 텍스트 인코더(VLMs-TE)는 클래스 이름으로 채워진 템플릿 프롬프트를 텍스트 임베딩으로 인코딩하는데, 이 텍스트 임베딩은 고정된 분류기로 간주됩니다. VLMs는 이미지-텍스트 대조 학습을 통해 시각적 모달리티와 잘 정렬되어 있으므로, OVD와 OVS는 ZSD와 ZSS에 비해 큰 성능 향상을 이루게 됩니다.
FreeSeg: Unified, Universal and Open-Vocabulary Image Segmentation
https://arxiv.org/pdf/2303.17225
https://github.com/bytedance/FreeSeg
Open-vocabulary Object Segmentation with Diffusion Models
https://openaccess.thecvf.com/content/ICCV2023/papers/Li_Open-vocabulary_Object_Segmentation_with_Diffusion_Models_ICCV_2023_paper.pdf
https://github.com/Lipurple/Grounded-Diffusion
DreamLIP: Language-Image Pre-training with Long Captions
https://arxiv.org/pdf/2403.17007
https://github.com/zyf0619sjtu/DreamLIP
