CLIP : Learning Transferable Visual Models From Natural Language Supervision (2021)
https://www.youtube.com/watch?v=dELmmuKBUtI
https://www.youtube.com/watch?v=T9XSU0pKX2E
이 동영상 내용 정리한 글임
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever
1. Introduction
limitation : fine-tuning 없이 새로운 downstream task에 적용하기 어려움 = 모델의 일반화 ↓
새로운 downstream task에 적합한 다량의 이미지와 레이블링 작업을 요함.
이미지 수집 및 정답 레이블 생성에 많은 인력과 비용이 요구된다.
벤치마크 데이터셋 성능과 실제 현실에서 수집한 데이터셋 성능과는 차이가 존재한다.
벤치마크 데이터셋에 최적화되어 그 외 데이터셋에서는 저조한 성능을 보인다. = 모델의 robustness 감소
pre-training 시,
1. fine-tuning이 필요없는 일반화된 모델
2. 이미지 수집 및 정답 레이블 생성에 적은 노력이 드는 모델
3. 벤치마크 데이터셋 외 여러 현실 데이터셋에서도 좋은 성능을 보이는 robust한 모델
=> CLIP (Contrastive Language-Image Pre-traing)
- CLIP
Web-based image-text pair를 기반으로 visual representation을 사전학습하는 방법론
using image-text pair
1. 기존 일반적인 분류 모델은 이미지의 의미론적 정보를 학습하지 못함
2. 반면, CLIP은 이미지와 이미지를 설명하는 텍스트를 결합한 image-text pair를 입력으로 사용
3. 이미지와 언어에 대한 representation을 함께 학습하여 일반화된 특징 학습 가능
creating a sufficiently large dataset
1. 인터넷으로부터 레이블링이 필요없는 약 4억개의 Image-Text pair 데이터를 수집
2. 다양한 분야의 텍스트 및 이미지를 수집하기 위해 총 50만건의 검색을 수행
3. 이미지의 균형을 대략적으로 맞추기 위해 각 검색어당 이미지는 최대 2만개로 조절
selecting an efficient pre-training method
1. image-text pair를 사용한 pre-training 기법은 이전부터 존재(ex.image captioning)
2. 그러나 모델 사이즈가 크며, 학습 및 예측 시간이 길어 비효율적임
3. 기존의 방식보다 효율적인 contrastive learning을 적용하여 pre-training 진행
4. zero-shot prediction에서도 상대적으로 가장 우수한 숭능을 보임
- zero-shot prediction = 한 번도 본 적 없는 특정 하위 문제의 데이터셋에 대해 예측 수행
contrastive learning = "데이터 내 positive & negative samples 간의 관계를 학습"
일반적인 contastive learning은 이미지만을 사용함. CLIP은 image-text pair를 사용하여 이미지에 적절한 문장을 연결한 문제이다.
overview
1. contrastive pre-training
배치 단위로 이루어진 N개의 이미지와 텍스트를 각각 인코더에 통과시켜 embedding vector를 산출한다.
image encoder : modified resnet/vision transformer
text encoder : transforemr
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)이미지와 텍스트 벡터 간의 내적을 통해 코사인 유사도 계산
pair에 해당하지 않는 이미지 혹은 텍스트는 서로 다르다는 관계하에 cross-entropy loss 계산
개의 쌍 중
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2- create dataset classifier from label text
적용하고자 하는 특정 하위 문제의 데이터셋 레이블을 텍스트로 변환
- 단순 언어가 아닌 "a photo of {}"에 해당하는 구로 변환
- 단어에서 구로 변환하여 인코더 입력 시 성능 향상되었다는 실험 결과
이후 학습된 텍스트 인코더에 통과시켜 텍스트 embedding 벡터값 산출
- use for a zero-shot classification
예측하고자 하는 이미지를 학습된 이미지 인코더에 통과시켜 이미지 임베딩 벡터값 산출
텍스트 임베딩 벡터와 코사인 유사도를 계산하여 상대적으로 높은 값을 갖는 텍스트 선택
fine-tuning 거치지 않고서도, 처음 보는 이미지에 대해 예측 가능
Experiments
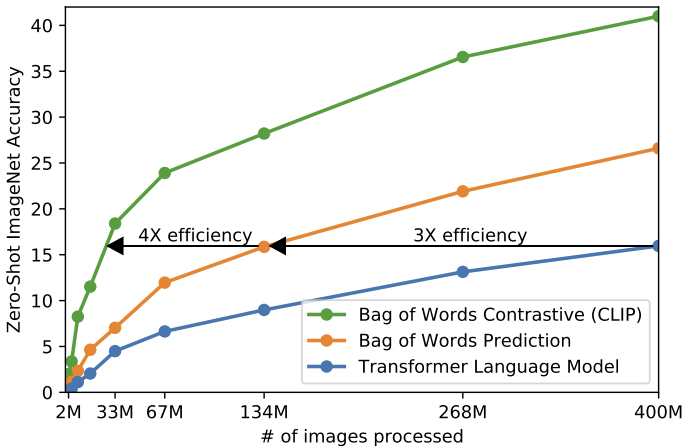 CLIP is much more efficient at zero-shot transfer
CLIP is much more efficient at zero-shot transfer
than our image caption baseline.
 Zero-shot CLIP is much more robust to distribution shift than standard ImageNet models.
Zero-shot CLIP is much more robust to distribution shift than standard ImageNet models.
why?
fine-tuning이 필요 없는 일반화된 모델
이미지 수집 및 정답 레이블 생성에 적은 노력이 드는 모델
벤치마크 데이터셋 외 여러 현실 데이터셋에서도 좋은 성능을 보이는 강건한 모델
how?
web-based image-text pair를 기반으로 visual representation 학습
대량의 레이블링이 필요없는 데이터셋을 기반으로 다양한 분야에 대해 학습 가능
contrastive learning 기반 pre-training을 통해 효율적이면서 domain shift에 강건한 학습 가능
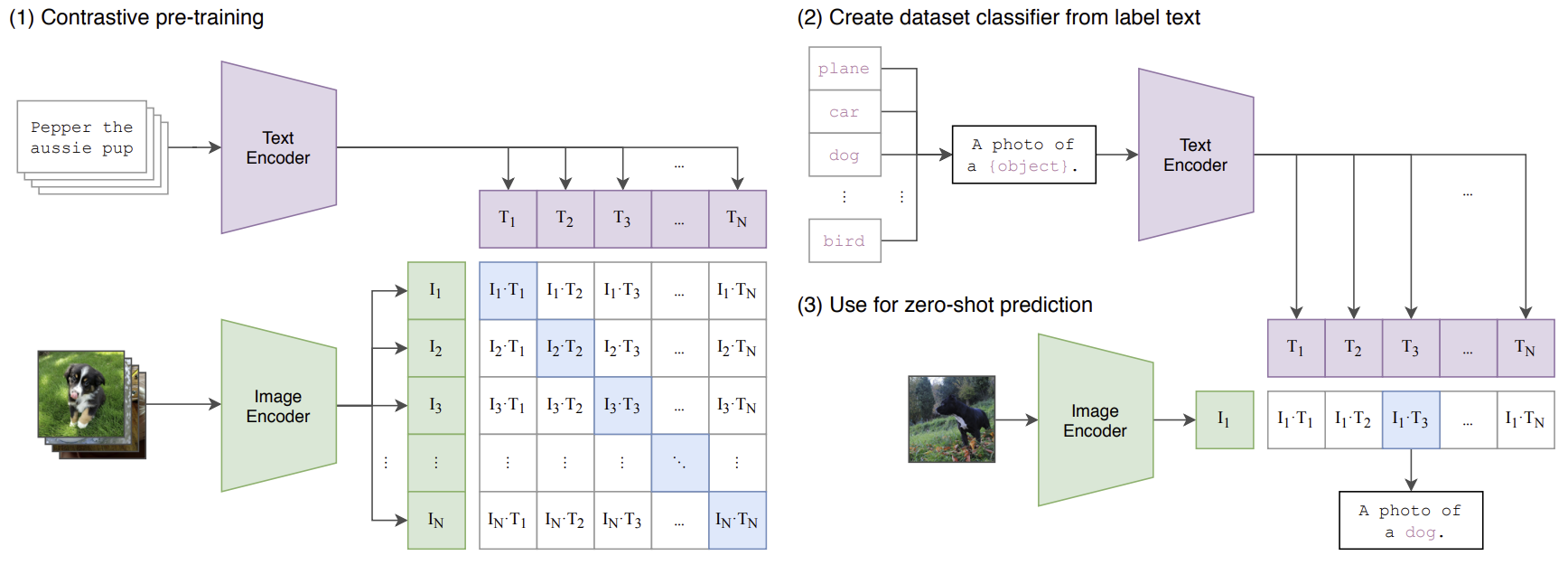
clip : 기존의 방식보다 효율적인 contrastive learning을 적용하여 pre-training을 진행
zero-shot prediction에서도 상대적으로 가장 우수한 성능을 보임.
-> zero-shot prediction : 한 번도 본 적 없는 특정 하위 문제의 데이터셋에 대한 예측 수행
