
합성곱 신경망 (CNN, Convolution Neural Network)은 합성곱 연산을 통해서 이미지의 특징을 추출하며 크게 합성곱층과(Convolution layer)와 풀링층(Pooling layer)으로 구성
💡 Convolution Layer
Conv2D(filters=32, kernel_size=(5, 5), padding='valid',
input_shape=(28, 28, 1), activation='relu')📌 filters
: 필터는 가중치를 의미. 하나의 필터가 입력 이미지를 순회하면서 적용된 결과값을 모으면 출력 이미지가 생성.
- 하나의 필터로 입력 이미지를 순회하기 때문에 순회할 때 적용되는 가중치는 모두 동일
- 출력에 영향을 미치는 영역이 지역적으로 제한
✅ 필터의 개수
# 입력 이미지가 단채널의 3 x 3이고, 2 x 2인 필터가 하나인 모델
Conv2D(1, (2, 2), padding='same', input_shape=(3, 3, 1))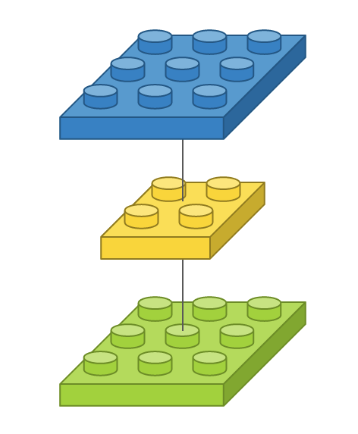
출처: https://tykimos.github.io/2017/01/27/CNN_Layer_Talk/
# 위 코드에서 사이즈가 2 x 2 필터를 3개 사용한 모델
# 특징
# 필터가 3개라서 출력 이미지도 필터 수에 따라 3개로 늘어남.
Conv2D(3, (2, 2), padding='same', input_shape=(3, 3, 1))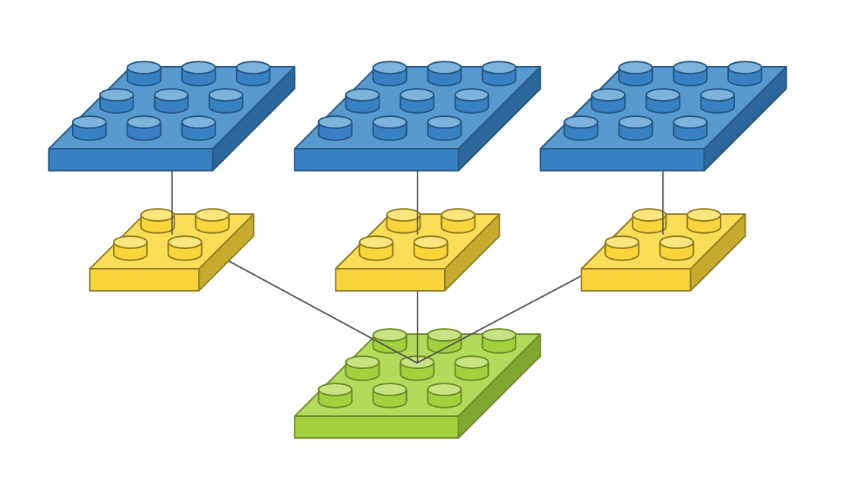
출처: https://tykimos.github.io/2017/01/27/CNN_Layer_Talk/
필터가 3개라서 출력 이미지도 필터 수에 따라 3개로 늘어남. 2 x 2 커널을 가진 필터가 3개 이므로 가중치는 총 12개.
필터마다 고유학 특징을 뽑아 고유한 출력 이미지를 만들기 필터의 출력값을 더해서 하나의 이미지로 만들지 않는다.
예, 스마트폰 카메라로 필터를 적용해서 사진을 찍을 때 적용되는 필터 수에 따라 다른 사진이 나오는 것과 같다.
# 입력 이미지의 채널이 3개이고 사이즈가 3 x 3이고, 사이즈가 2 x 2 필터를 1개 사용한 모델
# 특징
# 필터 개수가 3개인 것처럼 보이지만 이는 입력 이미지에 따라 할당되는 커널이고,
# 각 커널의 계산 값이 결국 더해져서 출력 이미지 한 장을 만들어내므로 필터 개수는 1개입니다.
Conv2D(1, (2, 2), padding='same', input_shape=(3, 3, 3))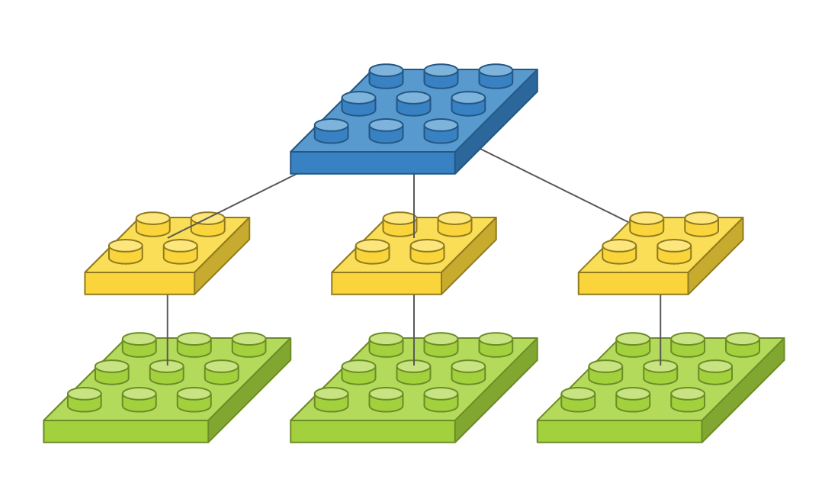
출처: https://tykimos.github.io/2017/01/27/CNN_Layer_Talk/
필터가 3개인 것처럼 보이지만 입력 이미지에 따라 할당되는 커널이고, 각 커널의 계산 값이 더해져 하나의 출력 이미지를 만들어 내기 때문에 필터의 개수는 1개이다.
📌 kernel_size
커널(kernel) 은 n×m 크기의 행렬로 높이너비 높이(height) × 너비(width) 크기의 이미지를 처음부터 끝까지 겹치며 훑으면서 n×m 크기의 겹쳐지는 부분의 각 이미지와 커널의 원소의 값을 곱해서 모두 더한 값을 출력으로 하는 것을 말합니다. 이때, 이미지의 가장 왼쪽 위부터 가장 오른쪽 아래까지 순차적으로 훑습니다.
💡 커널(kernel)은 일반적으로 3 × 3 또는 5 × 5를 사용합니다.
아래는 3×3 크기의 커널로 5×5의 이미지 행렬에 합성곱 연산을 수행하는 과정을 보여줍니다.
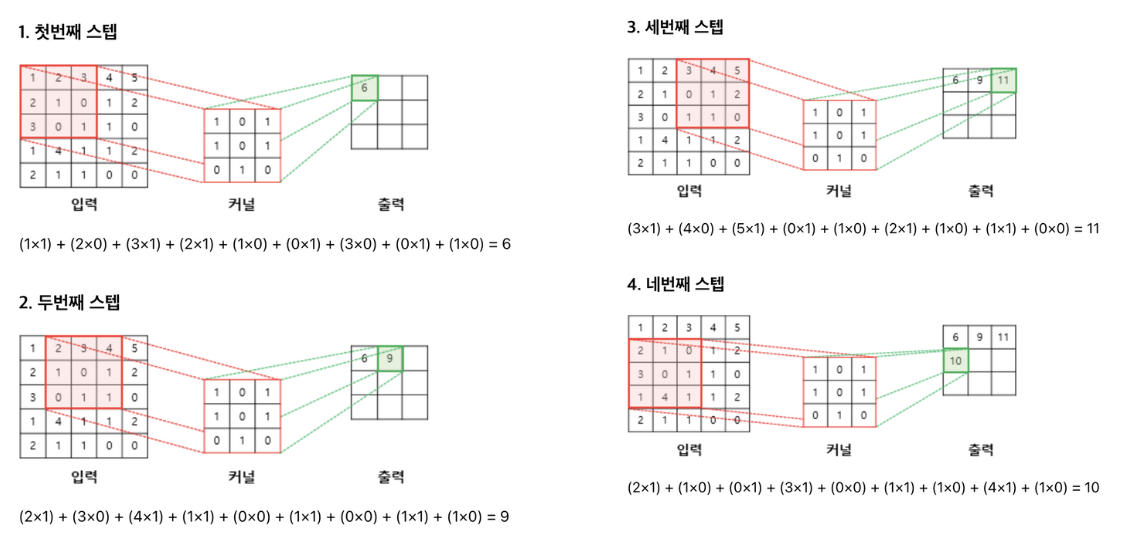
출처: https://wikidocs.net/64066
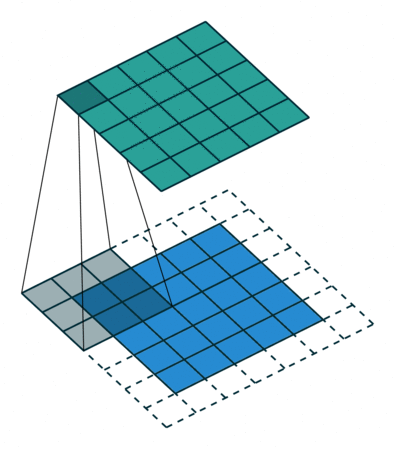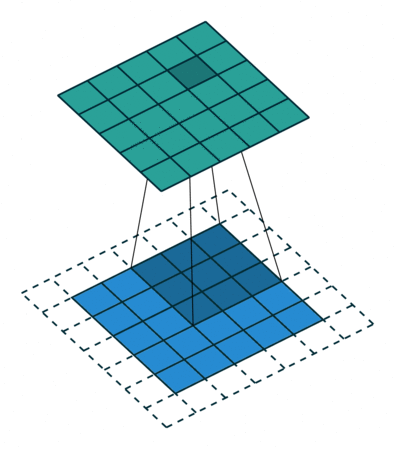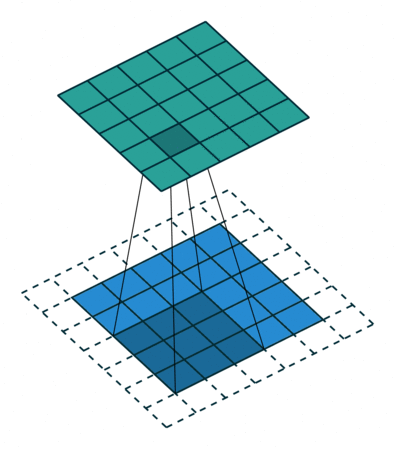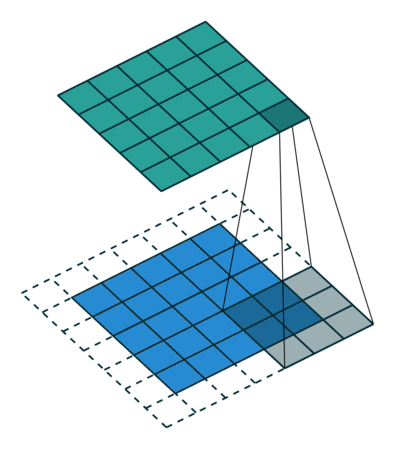
위 연산을 총 9번의 스텝까지 마쳤다고 가정하였을 때, 최종 결과는 아래와 같습니다.
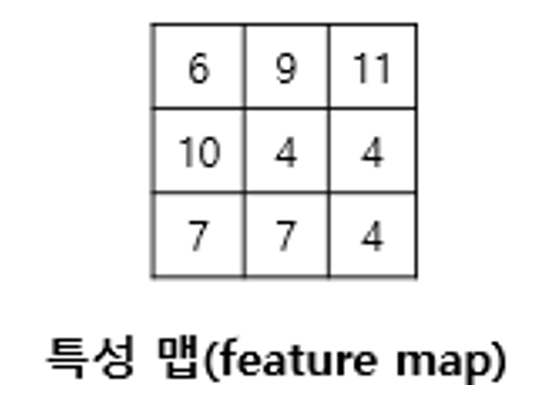
출처: https://wikidocs.net/64066
입력으로부터 커널을 사용하여 합성곱 연산을 통해 나온 결과를 특성 맵(feature map)이라고 합니다.
📌 Strides
위의 예제에서는 커널의 크기가 3 × 3이었지만, 커널의 크기는 사용자가 정할 수 있습니다. 또한 커널의 이동 범위가 위의 예제에서는 한 칸이었지만, 이 또한 사용자가 정할 수 있습니다. 이러한 이동 범위를 스트라이드(stride)라고 합니다.
아래의 예제는 스트라이드가 2일 경우에 5 × 5 이미지에 합성곱 연산을 수행하는 3 × 3 커널의 움직임을 보여줍니다. 최종적으로 2 × 2의 크기의 특성 맵을 얻습니다.
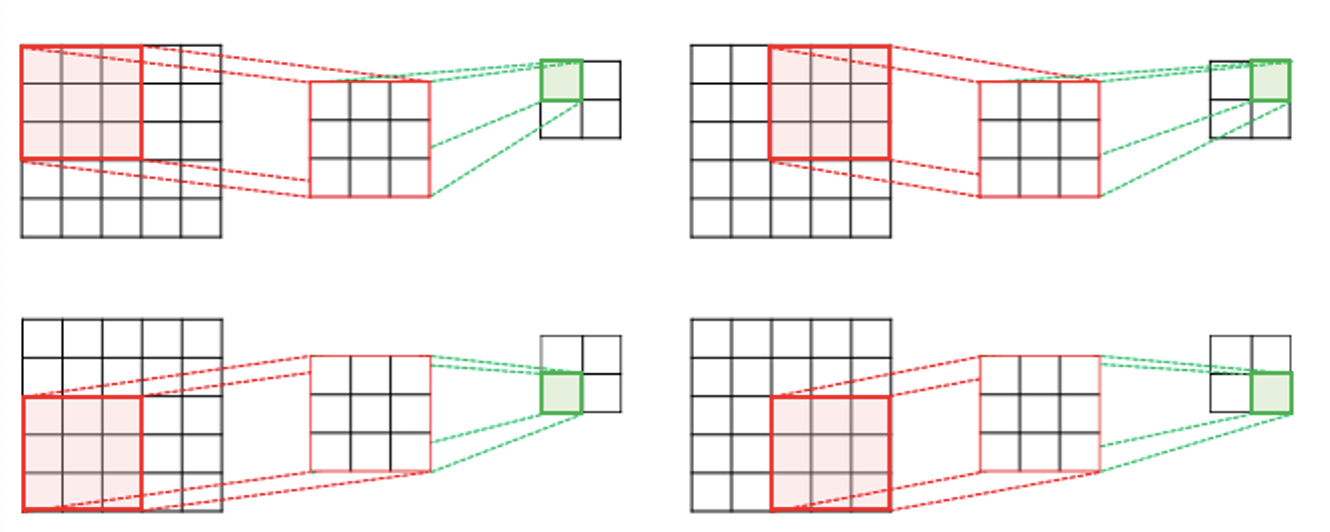
출처: https://wikidocs.net/64066
📌 Padding
: 경계 처리 방법을 정의. 입력의 가장자리에 지정된 개수의 폭만큼 행과 열을 추가하는 과정입니다.
valid : 유효한 영역만 출력이 됩니다. 따라서 출력 이미지 사이즈는 입력 사이즈보다 작습니다.
same : 출력 이미지 사이즈가 입력 이미지 사이즈와 동일합니다.
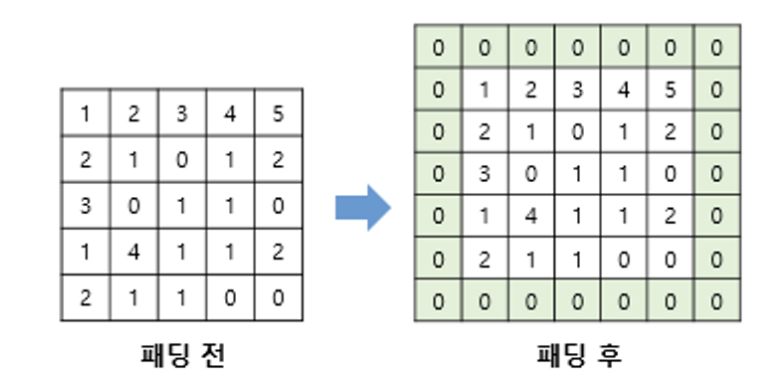
출처: https://wikidocs.net/64066
✅ 사용 목적
1) 이미지 데이터의 축소 방지
- CNN 과정에서 아래와 같은 계산을 여러 번 진행하는데 초반부터 이미지가 너무 작아져 버리면 깊게 학습할 데이터가 부족해지고 성능에 악영향
input data: (n x n)pixel image ▶ (f x f) filter ▶ (n – f + 1) x (n – f + 1) pixel image로 축소
2) 가장자리 학습
- 중요 정보가 가장자리에 있을 경우 성능이 떨어질 수 있기 때문에 padding을 이용해 가장자리를 0으로 둘러주면 성능을 높일 수 있음
💡 Pooling
풀링은 2차원 데이터의 세로 및 가로 방향의 공간을 줄이는 연산이다.
- 합성곱 층(합성곱 연산 + 활성화 함수) 다음에는 풀링 층을 추가하는 것이 일반적.
- 풀링 층에서는 특성 맵을 다운샘플링하여 특성 맵의 크기를 줄이는 풀링 연산이 이루어진다.
📌 Pooling의 목적
1) input size를 줄임(Down Sampling)
- 텐서의 크기를 줄이는 역할을 한다.
2) overfitting을 조절
- input size가 줄어드는 것은 그만큼 쓸데없는 parameter의 수가 줄어드는 것이라고 생각할 수 있다. 훈련데이터에만 높은 성능을 보이는 과적합(overfitting)을 줄일 수 있다.
3) 특징을 잘 뽑아냄.
- pooling을 했을 때, 특정한 모양을 더 잘 인식할 수 있음.
4) 지역적 이동에 노이즈를 줌으로써 일반화 성능을 올려준다.
- maxpooling의 경우 주어진 픽셀중 큰것만 뽑기때문에 모양이 조금 달라지는 특성을 가지고 있다.
📌 Maxpooling
인접한 유닛들 중 가장 큰 값을 뽑아내는 방법이다.
- 계산양이 감소하기 때문에 연산부하가 줄어든다.
- size를 줄이는 것이기 때문에 필연적으로 오차가 발생하므로 오버피팅을 약간 줄여준다.
- back propagation 시 복원이 힘들다. 따라서 너무 많이 넣으면 안된다.
🔎 예시
4x4 Activation map에서 2x2 맥스 풀링 필터를 stride를 2로 하여 2칸씩 이동하면서 맥스 풀링
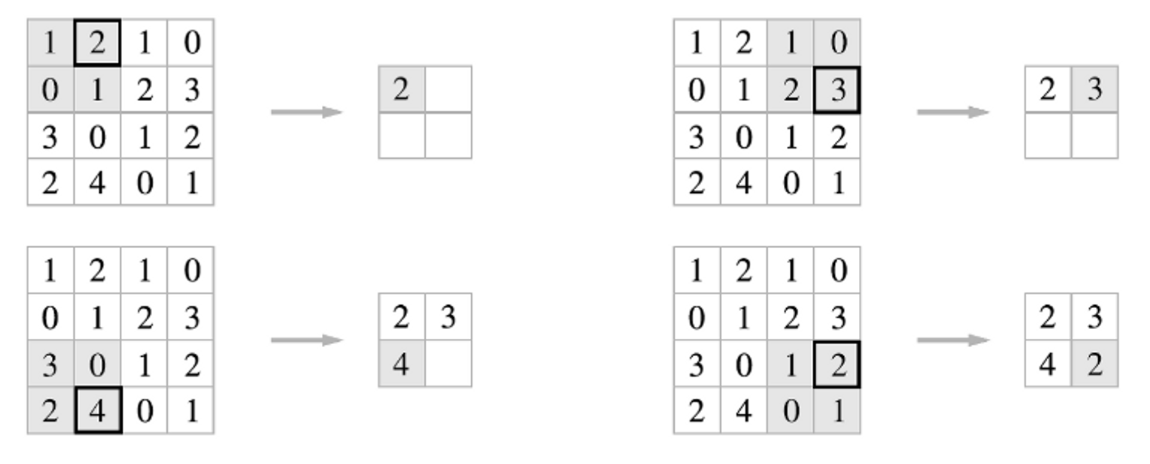
좌측 상단에서는2이 가장 큰 값이기 때문에 2을 뽑아내고, 우측 상단에는 1,0,2,3 중 3 이 가장 크기 때문에 3을 뽑아 내었다.
tf.keras.layers.MaxPooling2D(
pool_size=(2, 2),
strides=None,
padding="valid",
data_format=None,
)pool_size 정수 혹은 2개 정수의 튜플, 축소 인수 (가로, 세로). (2, 2)는 인풋을 두 공간 차원에 대해 반으로 축소합니다. 한 정수만 특정된 경우, 동일한 윈도우 길이가 두 차원 모두에 대해 적용된다.
