
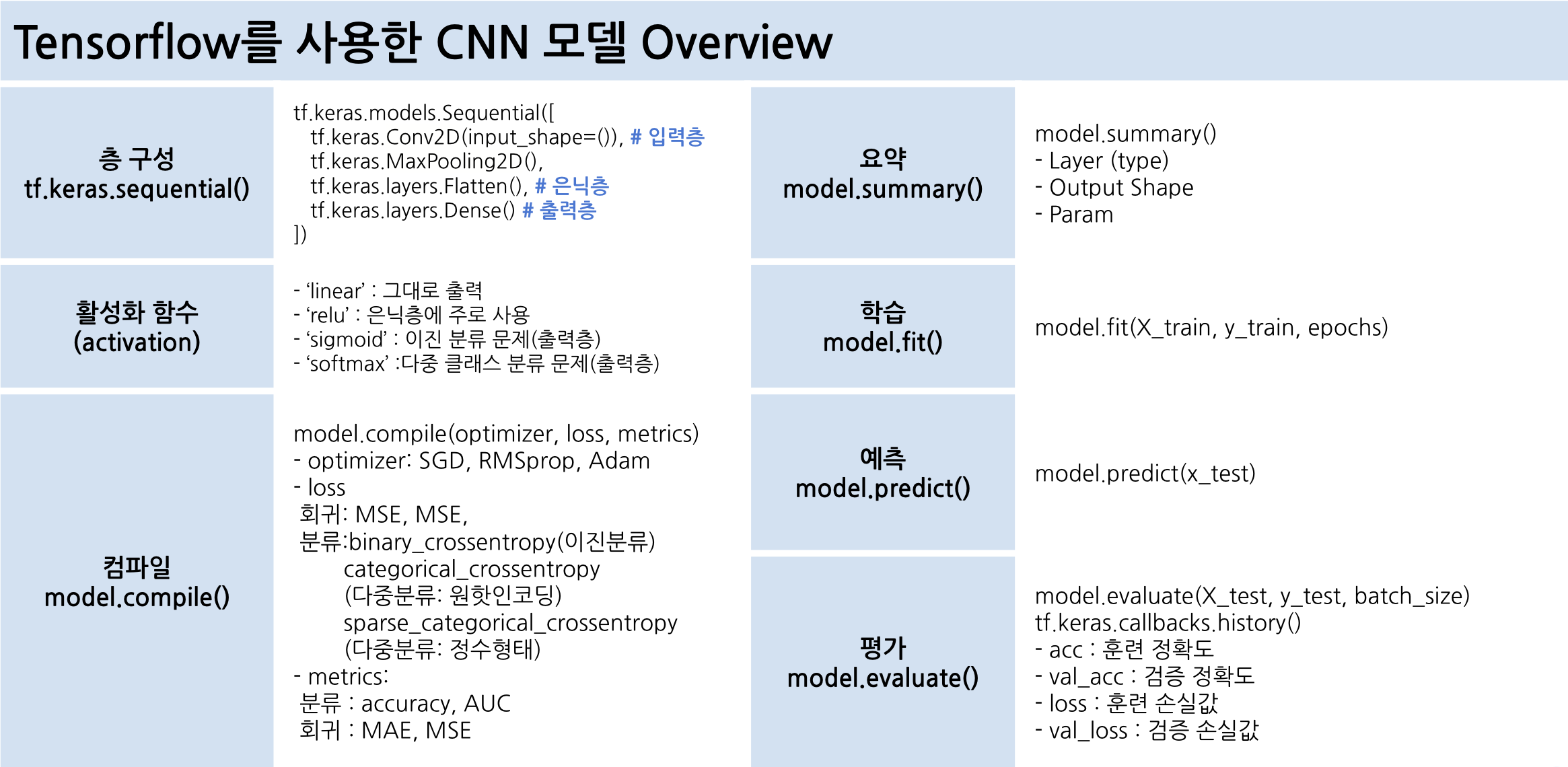
출처: 멋쟁이 사자처럼 AI SCHOOL 박조은 강사님 수업 자료 16번째 ppt, p.5
🤔 Conv, pooling을 하는 이유?
이미지를 바로 flatten 해서 넣으면 이미지의 지역적 특성 정보를 소실하게되고, 추상화를 하지 않고 바로 계산을 하기 때문에 비효율적인 학습 시간과 능률을 초래
=> 이미지를 이해하고 추상화된 정보 추출하여 특징(feature)의 패턴을 파악하는 CNN 도입
- Con2D(합성곱층)와 MaxPooling2D(풀링층)는 CNN의 특징 추출 영역이다.
- Flatten 층은 추출된 주요 특징을 전결합층에 전달하기 위해 1차원배열 형태로 변경한다.
- CNN 마지막 부분의 Dense 층은 이미지 분류를 위한 완전 연결 계층(FC) 추가한 것이다.
- Max-pooling은 합성곱 과정에서 만들어진 특징(feature)들의 가장 큰 값들만 가져와 사이즈를 감소합니다.
- Dropout(0.2)는 과대적합을 피하기 위해 드롭아웃을 레이어에 적용하여 20%를 무작위로 드롭아웃합니다.
🤔 스트라이드를 크게 설정해 여러 칸을 이동하면 결과는?
용량이 줄어들고 학습 속도는 빠릅니다. 하지만 자세히 학습하지 못 하기 때문에 언더피팅이 될 수 있다.
🤔 이미지 증강을 할 때 주의사항?
1) 크롭이나 확대 => 노이즈를 확대하거나 크롭하면 더 문제가 될 수 있다.
2) 회전, 반전 => 6을 180도 돌리면 완전히 다른 의미인 9가 되기 때문에 이런 숫자 이미지는 돌리지 않습니다.
3) 색상 변경 => 만약 장미꽃이라면 다양한 색상이 있기 때문에 색상을 변경해도 상관이 없지만, 신호등이라면 안전과 직결되기 때문에 변경하면 안 됩니다.
3) 데이터셋 => 증강할 때 train 에만 해줍니다. test에는 해주지 않습니다. 왜냐하면 현실세계 문제를 푼다고 가정했을 때 현실세계 이미지가 들어왔을 때 증강해주지는 않고 들어온 이미지로 판단하기 때문에 train에만 사용합니다.
4) 결론 => 증강을 할 때는 현실세계 문제와 연관해서 고민해 봐야 합니다.
1003 실습
💡 실습 목표: 전이학습 (Transfer Learning) 해보기
🤔 전이학습이란?
pre-trained 된 모델을 가져다 사용하는 것
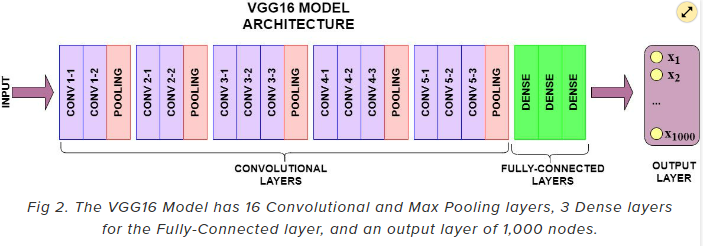
📌 VGGNet
VGG16 API 소개문서: https://www.tensorflow.org/api_docs/python/tf/keras/applications/vgg16/VGG16
케라스 문서의 전이학습 가이드:
https://keras.io/guides/transfer_learning/
✅ TF Keras 예제 코드
# 이미지넷 데이터셋 기준 => 1000 개의 분류를 하는 예제
# classes=1000 예측할 이미지의 종류가 1000개다. (= 1000개의 이미지 분류 X)
# classifier_activation='softmax' 출력층의 output
# 1000 개 종류의 확률값을 반환
# 이미지넷의 가중치만 사용할 것이지 그대로 분류할게 아니기 때문에 해당 옵션이 필요 없습니다.
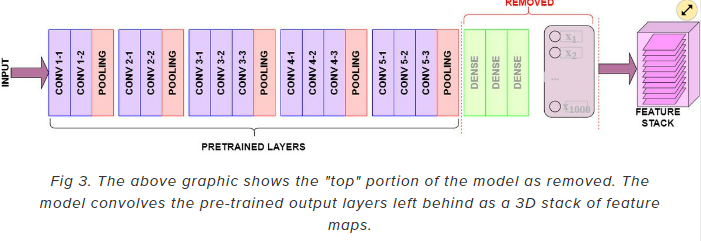
# 이 미리 구현된 pre-trained model 을 사용해서 혈액도말이미지로 말라리아 감염여부를 예측할 것이기 때문에 클래스 수도 다르고, 출력층 activation 도 따로 구현해 줄 것이기 때문에 include_top=False 로 나머지도 별도의 레이어로 구성해 주었습니다.
tf.keras.applications.vgg16.VGG16(
include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
classifier_activation='softmax'
)🤔 어떻게 16–19개 layer와 같이 깊은 신경망 모델의 학습을 성공했을까?
모든 합성곱 레이어에서 3x3 필터를 사용했기 때문
=> 이전 방식들과는 다르게 비교적 작은 크기인 3x3 convolution filter를 이용하여 layer를 깊게 쌓는다는 것이 VGG의 핵심
🤔 왜 모든 합성곱층(Convolutional layer)에서 3x3 필터만 사용했을까?
2개의 3x3 합성곱을 중첩하면, 1개의 5x5 합성곱의 수용 영역과 동일
- 층마다 활성화 함수를 사용할 수 있어서 결정 함수의 비선형성 증가(특징 식별성 증가)
- 파라미터 수도 줄어드는 효과(3x3x2 = 18 < 5x5 = 25)로 학습 속도 향상
# 이미지 사이즈 설정
width = 32
height = 32
# tensorflow.keras.applications.vgg16에서 16개의 층을 사용하는 VGG16 모델을 불러오자.
from tensorflow.keras.applications.vgg16 import VGG16
vgg = VGG16(weights="imagenet",
# whether to include the 3 fully-connected layers at the top of the network.
include_top=False,
input_shape=(height, width, 3))
model = Sequential()
model.add(vgg)
model.add(Flatten())
model.add(Dense(1, activation="sigmoid"))💡 이미지의 최소 사이즈는 32 x 32이다.
include_top=True
include_top=False
1004 실습 (날씨 이미지 분류)
https://www.kaggle.com/datasets/vijaygiitk/multiclass-weather-dataset
💡 실습 목표:
1) tf.keras의 전처리 기능 대신 이미지 파일을 array로 직접 만들기
2) 데이터셋 (train, valid, test) 직접 나누기
3) CNN 네트워크 구성 응용, 학습과 예측하기
📌 train, valid, test set 에 대한 X, y값 만들기
1) label 별로 각 폴더의 파일의 목록을 읽어옵니다.
2) 이미지와 label 리스트를 만들어서 넣어줄 예정이에요.
3) test는 폴더가 따로 있어요. 이미지를 불러올 때 test 여부를 체크해서
train, test 를 먼저 만듭니다.
4) np.array 형태로 변환해 주었습니다.
5) train 으로 train, valid 를 나누어 줍니다.
6) train, valid, test 를 만들어 줍니다.🤔 append 와 extend 의 차이?
append는 통째로 넣고 extend는 풀어서 넣습니다.
🍬 사탕을 다른 봉지에 담을 때
append: 봉지째 담는다
extend: 낱개로 풀어서 담는다
🙋🏻♀️ 질문
Q: CNN 모델을 학습시키는데 내 컴퓨터로 돌렸더니 메모리 오류가 났어요! 일단 성능과 관계 없이 돌리고 싶어요! 어떻게 해결하면 좋을까요? 돈을 쓰지 않고 해결하는 방법에 대해 얘기해 보겠습니다!
A: 1) 이미지 사이즈를 줄인다. 2) 레이어를 줄인다. 필터수를 줄인다. 3) 배치(한번에 다 불러오지 않고 나눠서 불러오게) 사이즈를 줄인다.
🦁 질문
Q: 레이어 몇 개를 써야할지는 어떻게 알 수 있나요?
A: 하이퍼파라미터로 레이어를 어떻게 구성하느냐에 따라 성능이 달라집니다.
Q: 배치 사이즈를 줄여도 결국 모든 사진을 다 학습하나요?
A: 나눠서 조금씩 다 학습하기 때문에 모든 사진을 학습하는데 너무 오래걸린다면 epoch 수를 줄여주는 것도 방법입니다.
Q: 255는 어디서 나온 숫자일까요?
A: RGB 형태의 컬러 디스플레이 방법은 가산혼합 => 다 합치면 흰색이 됩니다.
CMYK 형태의 인쇄 방법은 감산혼합 => 다 합치면 검은색이 됩니다.
RGB는 0~255 로 3개의 R, G, B 빨초파로 표현합니다.
💡 i.e. 빨강색 == 빨강색만 255
현대의 대부분 모니터의 최대 지원 색 심도는 24비트입니다. (물론 더 많이 지원하는 모니터 들도 많이 나왔습니다). 즉, 각 픽셀은 2^24(~16.7M)의 색상을 표시할 수 있게 되어있고 24비트 값을 각각 R G B 세개의 색상으로 나누자면 24비트 / 3이므로 각 채널의 폭은 8비트를 가지게 되게 되었습니다.
채널당 8비트라는것을 고려할때 0 ~ 255 (256개)의 숫자 값만 인코딩 할 수 있게 되는 것이 이치에 맞습니다. (= 2에 8승 == 256이지만 연산은 0부터 시작하니 0~255가 된다).
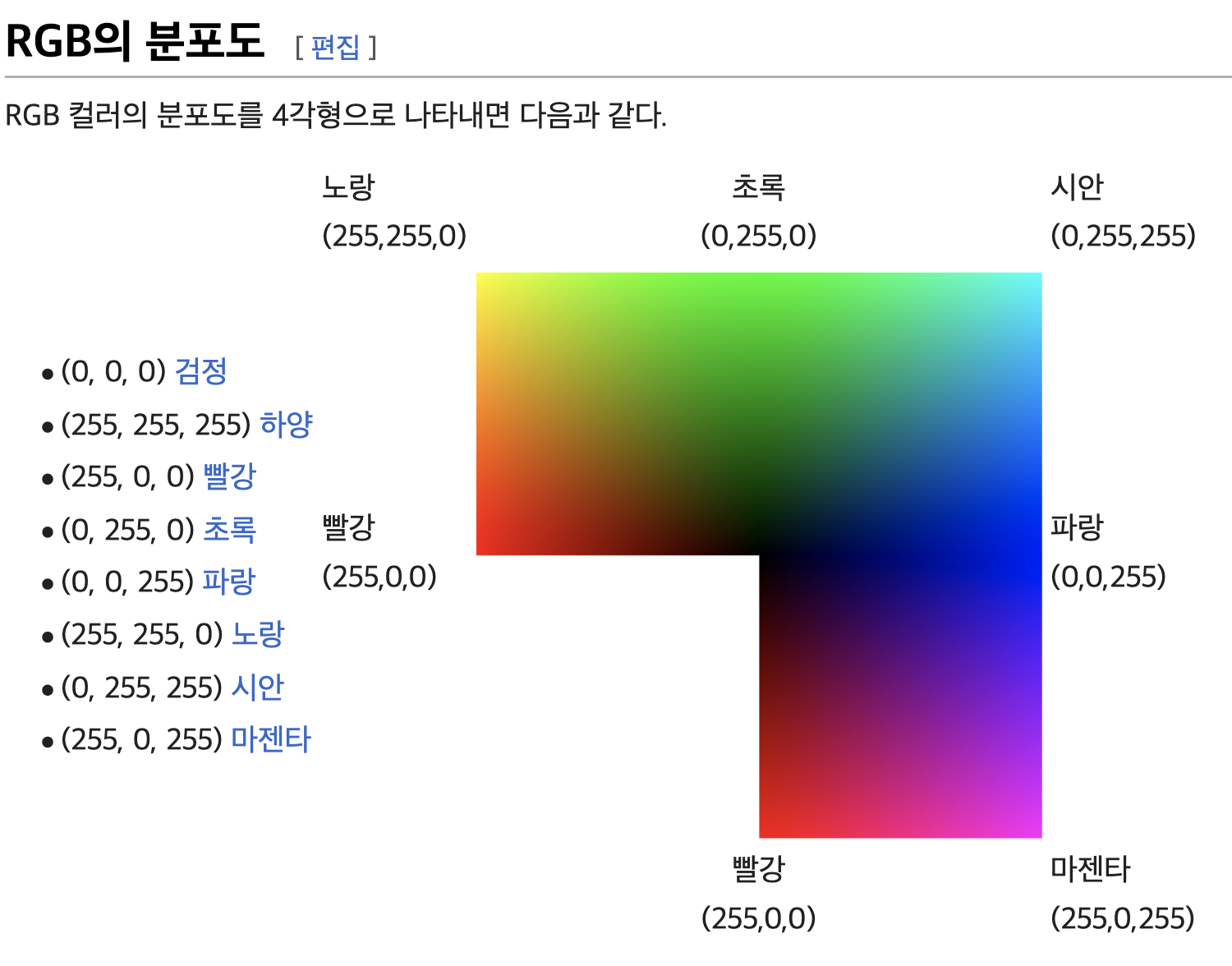
출처: https://ko.wikipedia.org/wiki/RGB
✏️ TIL
- 사실(Fact): tf.keras의 전처리 기능을 사용하는 대신 이미지 파일을 array로 직접 만들고 데이터 셋도 직접 만드는 실습을 했다.
- 느낌(Feeling): 만들어진 메서드를 사용하는게 심신에 좋을것 같다.
- 교훈(Finding): 복습하자.
