
max_df: 문서 빈도가 주어진 임계값보다 높은 용어는 무시하여, 불용어 처리에 효과가 있다.
min_df: 문서 빈도가 주어진 임계값보다 낮은 용어는 무시하여, 희귀단어나 오타를 제거하는 효과가 있다.
TF(term frequency): 한 문장에서 등장하는 단어의 빈도수
DF(document fequency): 전체 문서에서 등장하는 단어의 빈도수
TF-IDF: TF와 IDF을 곱한 값. 중요한 단어에 가중치를 주는 것 (= 추천 시스템)
- 모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단
- 특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단
- TF-IDF값이 낮으면 중요도가 낮고, TF-IDF값이 높으면 중요도가 높다
- 불용어의 TF-IDF값은 다른 단어에 비해 낮다
- 이미지를 다룰 때는 돈을 쓰지 않고 모델을 내 컴퓨터에서 돌리기 위해 이미지 사이즈, 레이어 개수 등을 조정했습니다.
- 텍스트 데이터에서 내 컴퓨터가 힘들어 한다면 여러 방법을 사용할 수 있는데 가장 간단한 방법이 max_features 를 작게 조정하는 것입니다.
- 비지도학습의 차원축소를 사용하게 되면 데이터를 압축해서 사용할 수도 있습니다. 그런데 차원축소 과정에서도 메모리 오류가 발생할 수도 있는데 그럴 때 max_features 를 내 컴퓨터가 계산할 사이즈로 적당하게 조정해 주면 로컬 PC로도 어느정도 돌려볼 수 있습니다.
- 여기에서 조금 더 조정한다면 min_df, max_df, stop_words 등을 조정해 볼 수 있습니다.
불용어
: 문장에 자주 등장하지만 실제 의미 분석을 하는데 도움이 안 되는 단어
e.g.) 조사, 접미사, -은, -는, 이가, 하다, 합니다. 등
- 데이터에서 유의미한 단어 토큰만을 선별하기 위해서는 큰 의미가 없는 단어 토큰을 제거하는 작업 필요
- 영어나 다른 많이 사용되는 언어는 불용어가
NLTK,Spacy와 같은 도구에서 목록을 제공하고 있지만 한국어는 제공 X
1103 실습
[뉴스 토픽 분류 AI 경진대회 - DACON] https://dacon.io/competitions/official/235747/overview/description

📌 정규 표현식
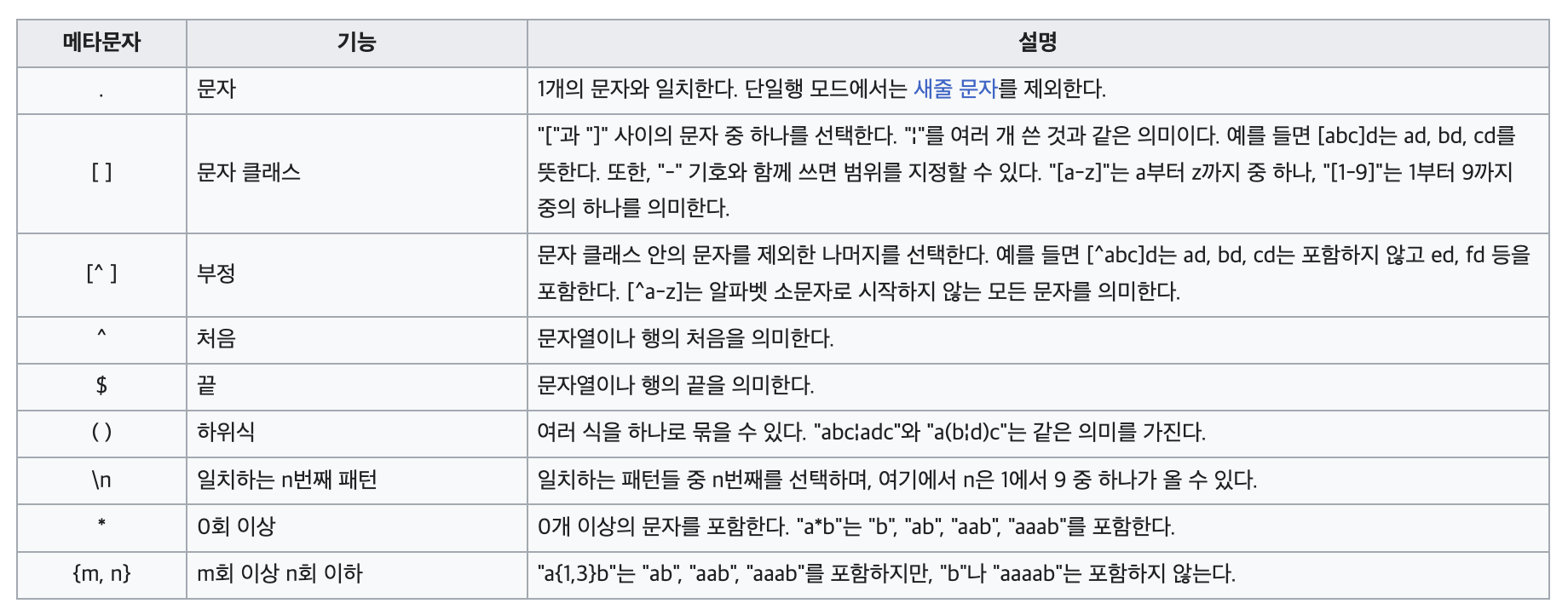
출처: https://ko.wikipedia.org/wiki/%EC%A0%95%EA%B7%9C_%ED%91%9C%ED%98%84%EC%8B%9D
✅ map(), re,sub()와 str.replace() 사용하기
# map, 정규표현식의 re.sub 을 통해 숫자제거
# re.sub(pattern, repl, string, count=0, flags=0)
import re
re.sub("[0-9]", "", "12월 13일 눈이 내립니다.") # 숫자를 제외하고 출력
>> 월 일 눈이 내립니다.
# map 기능을 통해 제거
df["title"].map(lambda x : re.sub("[0-9]", "", x))
# str.replace 기능을 통해 제거
df["title"] = df["title"].str.replace("[0-9]", "", regex=True)
# map과 str.replace는 같은 결과를 출력
>>
0 인천→핀란드 항공기 결항…휴가철 여행객 분통
1 실리콘밸리 넘어서겠다…구글 조원 들여 美전역 거점화
2 이란 외무 긴장완화 해결책은 미국이 경제전쟁 멈추는 것
3 NYT 클린턴 측근韓기업 특수관계 조명…공과 사 맞물려종합
4 시진핑 트럼프에 중미 무역협상 조속 타결 희망
...
54780 인천 오후 시분 대설주의보…눈 .cm 쌓여
54781 노래방에서 지인 성추행 외교부 사무관 불구속 입건종합
54782 년 전 부마항쟁 부산 시위 사진 점 최초 공개
54783 게시판 아리랑TV 아프리카개발은행 총회 개회식 생중계
54784 유영민 과기장관 강소특구는 지역 혁신의 중심…지원책 강구✅ 특수문자 제거
# 특수 문자 사용시 정규표현식에서 메타 문자로 특별한 의미를 갖기 때문에 역슬래시를 통해 예외처리를 해주어야 합니다.
💡 [!\"\$\*] 일부 특수문자 제거 연습
df["title"] = df["title"].str.replace("[!\"\$\*]", "", regex=True)
df["title"]
>>
0 인천→핀란드 항공기 결항…휴가철 여행객 분통
1 실리콘밸리 넘어서겠다…구글 조원 들여 美전역 거점화
2 이란 외무 긴장완화 해결책은 미국이 경제전쟁 멈추는 것
3 NYT 클린턴 측근韓기업 특수관계 조명…공과 사 맞물려종합
4 시진핑 트럼프에 중미 무역협상 조속 타결 희망
...
54780 인천 오후 시분 대설주의보…눈 .cm 쌓여
54781 노래방에서 지인 성추행 외교부 사무관 불구속 입건종합
54782 년 전 부마항쟁 부산 시위 사진 점 최초 공개
54783 게시판 아리랑TV 아프리카개발은행 총회 개회식 생중계
54784 유영민 과기장관 강소특구는 지역 혁신의 중심…지원책 강구
Name: title, Length: 54785, dtype: object
💡 한글, 영문과 공백만 남기고 모두 제거
# 정규표현식 [^ㄱ-ㅎㅏ-ㅣ가-힣 ] 을 사용하면 한글과 공백만 남기고 제거하게 됩니다.
# [^ㄱ-ㅎㅏ-ㅣ가-힣 a-zA-Z] 한글, 영문과 공백만 남기고 모두 제거
df["title"] = df["title"].str.replace(
"[^ㄱ-ㅎㅏ-ㅣ가-힣 a-zA-Z]", "", regex=True)
df["title"]
>>
0 인천핀란드 항공기 결항휴가철 여행객 분통
1 실리콘밸리 넘어서겠다구글 조원 들여 전역 거점화
2 이란 외무 긴장완화 해결책은 미국이 경제전쟁 멈추는 것
3 nyt 클린턴 측근기업 특수관계 조명공과 사 맞물려종합
4 시진핑 트럼프에 중미 무역협상 조속 타결 희망
...
54780 인천 오후 시분 대설주의보눈 cm 쌓여
54781 노래방에서 지인 성추행 외교부 사무관 불구속 입건종합
54782 년 전 부마항쟁 부산 시위 사진 점 최초 공개
54783 게시판 아리랑tv 아프리카개발은행 총회 개회식 생중계
54784 유영민 과기장관 강소특구는 지역 혁신의 중심지원책 강구✅ 공백 여러개 하나로 치환하기
# ㅋㅋㅋㅋㅋㅋㅋㅋㅋ를 ㅋ로 변경하기
# "+" : ㅋ이 1개 이상일 경우, 1번으로 변경
re.sub("[ㅋ]+", "ㅋ", "ㅋㅋㅋㅋㅋㅋㅋㅋㅋ")
>> 'ㅋ'
# 여러 개의 공백을 하나의 공백으로 치환해 줍니다.
df["title"] = df["title"].str.replace("[\s]+", " ", regex=True)
>>
0 인천핀란드 항공기 결항휴가철 여행객 분통
1 실리콘밸리 넘어서겠다구글 조원 들여 전역 거점화
2 이란 외무 긴장완화 해결책은 미국이 경제전쟁 멈추는 것
3 nyt 클린턴 측근기업 특수관계 조명공과 사 맞물려종합
4 시진핑 트럼프에 중미 무역협상 조속 타결 희망
...
54780 인천 오후 시분 대설주의보눈 cm 쌓여
54781 노래방에서 지인 성추행 외교부 사무관 불구속 입건종합
54782 년 전 부마항쟁 부산 시위 사진 점 최초 공개
54783 게시판 아리랑tv 아프리카개발은행 총회 개회식 생중계
54784 유영민 과기장관 강소특구는 지역 혁신의 중심지원책 강구🤔 벡터의 shape가 (3, 15)인 데이터를 max_features=10으로 적용후 벡터의 shape를 확인하면 ( 10, 15 )으로 나타날까?
벡터의 shape가 (3, 15)인 데이터를 max_features=10으로 적용후 벡터의 shape를 확인하면 (3, 10)으로 나타납니다. 처음 벡터의 shape인 (3,15)의 뜻은 3줄의 텍스트와 15 종류의 단어가 사용되었다는 뜻입니다. 그러므로 feature값은 15가 할당됩니다. max_features로 feature값을 수정하였으므로 feature값은 10으로 할당됩니다.
🙋🏻♀️ 질문
Q: 왜 fit은 train에만 해줄까요?
A: 기준을 train으로 해주어야 test도 같은 방법으로 전처리 할 수 있습니다. train, test 각각 fit을 하게 되면 다른 기준으로 전처리 하게 됩니다.
텍스트 데이터를 각각 fit을 하게 되면 다른 단어사전으로 전처리 되어 기준이 다르게 됩니다.
✏️ TIL
- 사실(Fact): 자연어 전처리에 대해 배웠다.
- 느낌(Feeling): 이제까지 배웠던 내용을 복습하는 것 같았다.
- 교훈(Finding): 정규표현식 마스터하기
