
1104 실습
💡 실습 목적: KoNLPy로 한국어 형태소 분석기를 사용해 보기
정규화: 일관되게 전처리 해서 불필요하게 토큰을 생성하지 않고 같은 의미를 부여하게 됩니다.
📌 KoNLPy
대표적인 자연어처리 도구인 NLTK, Spacy는 한국어를 지원하지 않습니다. 영어를 사용한다면 해당도구를 사용해도 됩니다. 하지만 한국어 형태소 분석 등의 기능을 제공하지 않기 때문에 KoNLPy로 실습합니다.
KoNLPy는 설치가 까다롭습니다. Java, C, C++로 작성된 도구를 파이썬으로 사용할 수 있도록 연결해 주는 도구이기 때문에 여러 환경 의존성이 있습니다. 환경 의존성을 만족해야 동작하는 도구가 있습니다.
형태소 분석 및 품사 태깅 — KoNLPy 0.6.0 documentation
형태소 분석기마다 품사를 태깅하는 방법이 다 다릅니다.
🤔 품사태깅할때 명사에는 어떤 공통점이 있을까요?
N로 시작
🤔 동사에는 어떤 공통점이 있을까요?
V로 시작
💡 전처리는 속도가 오래 걸리기 때문에 전처리한 것만 파일을 따로 저장해서 사용하기도 함
💡 Pecab : Pecab is a pure python Korean morpheme analyzer based on Mecab.
📌 Stemming (어간 추출)
- 어간 추출은 원형을 잃을 수 있으나 표제어 표기법은 원형을 보존할 수 있어서 모델 학습에 성능이 더 좋은 것은 표제어 표기법라고 할 수 있다.
- 어간 추출은 단어 형식을 의미가 있거나 무의미할 수 있는 줄기로 축소하고, 표제어 표기법은 단어 형식을 언어학적으로 유효한 의미로 축소한다.
- 'creating'이라는 단어를 어간 추출로 표현하면 'creat'가 되고, 표제어 표기법으로 표현하면 'create'가 된다.
💡 Okt: stemming 기능을 제공
from konlpy.tag import Okt
okt = Okt()
okt.pos("버스의 운행시간을 문의했었습니다. 어?!", stem=True)
>>>
[('버스', 'Noun'),
('의', 'Josa'),
('운행', 'Noun'),
('시간', 'Noun'),
('을', 'Josa'),
('문의', 'Noun'),
('하다', 'Verb'), # 했었습니다 => 하다
('.', 'Punctuation'),
('어', 'Eomi'),
('?!', 'Punctuation')]
okt.pos("버스의 운행시간을 문의했다. 어?!", stem=True)
>>>
[('버스', 'Noun'),
('의', 'Josa'),
('운행', 'Noun'),
('시간', 'Noun'),
('을', 'Josa'),
('문의', 'Noun'),
('하다', 'Verb'), # 했다 => 하다
('.', 'Punctuation'),
('어', 'Eomi'),
('?!', 'Punctuation')]💡 품사 태깅할 때 시간이 너무 오래 걸리는데 속도를 개선하고자 한다면 멀티스레드를 만들어서 처리하는 방법이 있다.
# 형태소 분석기(Okt) 불러오기
# ['Josa', 'Eomi', 'Punctuation'] 조사, 어미, 구두점 제거
# 전체 텍스트에 적용해 주기 위해 함수를 만듭니다.
# 1) 텍스트를 입력받습니다.
# 2) 품사태깅을 합니다. [('문의', 'Noun'), ('하다', 'Verb'), ('?!', 'Punctuation')]
# 3) 태깅 결과를 받아서 순회 합니다.
# 4) 하나씩 순회 했을 때 튜플 형태로 가져오게 됩니다. ('을', 'Josa')
# 5) 튜플에서 1번 인덱스에 있는 품사를 가져옵니다.
# 6) 해당 품사가 조사, 어미, 구두점이면 제외하고 append 로 인덱스 0번 값만 다시 리스트에 담아줍니다.
# 7) " ".join() 으로 공백문자로 연결해 주면 다시 문장이 됩니다.
# 8) 전처리 후 완성된 문장을 반환합니다.
def okt_clean(text):
clean_text = []
# 품사태깅을 합니다. [('문의', 'Noun'), ('하다', 'Verb'), ('?!', 'Punctuation')]
# 태깅 결과를 받아서 순회 합니다.
for word in okt.pos(text, norm=True, stem=True):
# 해당 품사가 조사, 어미, 구두점이면 제외하고 append 로 인덱스 0번 값만 다시 리스트에 담아줍니다.
if word[1] not in ['Josa', 'Eomi', 'Punctuation']:
clean_text.append(word[0])
# " ".join() 으로 공백문자로 연결해 주면 다시 문장이 됩니다.
return " ".join(clean_text)
okt_clean("달달한거 먹고 싶은데 넌 어때?")
>>>
'달달 한 거 먹다 싶다 넌 어떻다'1105 실습
💡 실습 목적: 시퀀스 방식의 인코딩을 사용해 보고, Bag of Words 와 TF-IDF 방식과 시퀀스 방식이 어떤 차이가 있는지 알아보기
💡 실습 흐름
1) Tokenizer 인스턴스를 생성
2) fit_on_texts와 word_index를 사용하여 key value로 이루어진 딕셔너리를 생성
3) texts_to_sequences를 이용하여 text 문장을 숫자로 이루어진 리스트로 변경
4) 마지막으로 pad_sequences를 이용하여 리스트의 길이를 통일화
📌 Tokenizer
tf.keras.preprocessing.text.Tokenizer(
num_words=None,
filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',
lower=True,
split=' ',
char_level=False,
oov_token=None,
analyzer=None,
**kwargs
)-
이 클래스를 사용하면 각 텍스트를 일련의 정수(각 정수는 사전에 있는 토큰의 인덱스임) 또는 단어 수에 따라 각 토큰의 계수가 이진일 수 있는 벡터로 변환하여 텍스트 말뭉치를 벡터화할 수 있습니다.(TF-IDF기반)
-
매개변수
num_words: 단어 빈도에 따라 유지할 최대 단어 수입니다. 가장 일반적인 단어 만 유지됩니다.
filters: 각 요소가 텍스트에서 필터링될 문자인 문자열입니다. 기본값은 문자를 제외한 모든 구두점과 탭 및 줄 바꿈 '입니다.
lower: 부울. 텍스트를 소문자로 변환할지 여부입니다.
split: str. 단어 분할을 위한 구분 기호입니다.
char_level: True이면 모든 문자가 토큰으로 처리됩니다.
oov_token: 주어진 경우, 그것은 word_index에 추가되고 text_to_sequence 호출 중에 어휘 밖의 단어를 대체하는 데 사용됩니다.
💡 num_words=vocab_size를 지정하면 해당 문장의 단어 수가 지정한 vocab_size를 넘으면 빈도수가 적은 단어는 제외하고 출력한다. (= 빈도수가 높은 단어만 vocab_size - 1 만큼 출력)
단어 수를 너무 많이 지정하면 나중에 학습을 할 때 너무 오래 걸릴 수 있고 문장 길이가 다 제각각입니다. 단어 수를 제한하면 어휘에 없는 단어가 등장했을 때 시퀀스에 누락이 되기 때문에 이런 값을 처리하는 방법이 있습니다.
oov_token(out-of-vocabulary)을 사용하면 없는 어휘는 없는 어휘라고 표현해 줍니다.
🤔 oov_token 값으로 넣어줄 수 있는 값은 어떤것들이 있나요?
마스크값, 종결, 패딩 등으로 사용하기도 합니다.
"<oov>" 를 사용하지 않고 다른 문자를 사용해도 상관은 없습니다.
[UNK]: unknown의 의미로 많이 사용하긴 합니다
💡 인덱스가 0부터 시작하지 않고 1부터 시작한다.

tokenizer = Tokenizer(num_words=10, oov_token="<oov>")
tokenizer.fit_on_texts(corpus)
print(tokenizer.word_index)
print(corpus)
corpus_sequences = tokenizer.texts_to_sequences(corpus)
corpus_sequences
>>>
{'<oov>': 1, '문의입니다': 2, '운행시간': 3, 'seoul': 4, '서울': 5, '코로나': 6, '상생지원금': 7, '인천': 8, '지하철': 9, 'bus': 10, '버스': 11}
['SEOUL 서울 코로나 상생지원금 문의입니다.?', '인천 지하철 운행시간 문의입니다.!', 'Bus 버스 운행시간 문의입니다.#']
[[4, 5, 6, 7, 2], [8, 9, 3, 2], [1, 1, 3, 2]]길이가 맞지 않아서 제대로 numpy array가 만들어지지 않는데, 이럴 때는 Padding 기법을 사용해 길이를 맞춰주면 된다.
📌 Encoding: Padding
기본적으로 가장 길이가 가장 긴 sequence에 맞춰 인코딩
✅ 예제
pad_sequences(sequences, maxlen=None, dtype='int32',
padding='pre', truncating='pre', value=0.0)
>>> sequence = [[1], [2, 3], [4, 5, 6]]
>>> tf.keras.preprocessing.sequence.pad_sequences(sequence)
array([[0, 0, 1],
[0, 2, 3],
[4, 5, 6]], dtype=int32)
>>> tf.keras.preprocessing.sequence.pad_sequences(sequence, value=-1)
# 0대신 -1로 채움
array([[-1, -1, 1],
[-1, 2, 3],
[ 4, 5, 6]], dtype=int32)
>>> tf.keras.preprocessing.sequence.pad_sequences(sequence, padding='post')
# 0을 뒤에 추가
array([[1, 0, 0],
[2, 3, 0],
[4, 5, 6]], dtype=int32)
>>> tf.keras.preprocessing.sequence.pad_sequences(sequence, maxlen=2)
array([[0, 1],
[2, 3],
[5, 6]], dtype=int32)💡 sequence 방식의 인코딩은 순서를 보존하기 때문에 RNN(순서를 고려하는 알고리즘)에서 나은 성능을 낸다.
머신러닝에서는 sequence 방식 보다 TF-IDF를 사용하는 것이 더 나은 성능을 낸다.
📌 1105 실습 Summary
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
"""
1) tokenizer 불러오기
2) fit_on_text
3) sequence 만들기
4) padding
"""
tokenizer = Tokenizer(num_words=7, oov_token="[UNK]")
tokenizer.fit_on_texts(corpus2)
print(tokenizer.word_index)
print(corpus2)
corpus_sequences = tokenizer.texts_to_sequences(corpus2)
pads = pad_sequences(corpus_sequences, maxlen=10, padding="pre")
print(corpus2)
print(word_to_index)
print(pads)
np.array(pads)
>>>
{'[UNK]': 1, '문의입니다': 2, '코로나': 3, '지하철': 4, '승강장': 5, 'bus': 6, '안내입니다': 7, 'covid19': 8, '거리두기와': 9, '상생지원금': 10, '운행시간과': 11, '요금': 12, '선별진료소': 13, '운행시간': 14, '터미널': 15, '위치': 16, '거리두기': 17, 'taxi': 18}
['COVID19 거리두기와 코로나 상생지원금 문의입니다.', '지하철 운행시간과 지하철 요금 문의입니다.', '지하철 승강장 문의입니다.', '코로나 선별진료소 문의입니다.', 'Bus 운행시간 문의입니다.', 'BUS 터미널 위치 안내입니다.', '코로나 거리두기 안내입니다.', 'taxi 승강장 문의입니다.']
['COVID19 거리두기와 코로나 상생지원금 문의입니다.', '지하철 운행시간과 지하철 요금 문의입니다.', '지하철 승강장 문의입니다.', '코로나 선별진료소 문의입니다.', 'Bus 운행시간 문의입니다.', 'BUS 터미널 위치 안내입니다.', '코로나 거리두기 안내입니다.', 'taxi 승강장 문의입니다.']
{'문의입니다': 1, '운행시간': 2, 'seoul': 3, '서울': 4, '코로나': 5, '상생지원금': 6, '인천': 7, '지하철': 8, 'bus': 9, '버스': 10}
[[0 0 0 0 0 1 1 3 1 2]
[0 0 0 0 0 4 1 4 1 2]
[0 0 0 0 0 0 0 4 5 2]
[0 0 0 0 0 0 0 3 1 2]
[0 0 0 0 0 0 0 6 1 2]
[0 0 0 0 0 0 6 1 1 1]
[0 0 0 0 0 0 0 3 1 1]
[0 0 0 0 0 0 0 1 5 2]]
array([[0, 0, 0, 0, 0, 1, 1, 3, 1, 2],
[0, 0, 0, 0, 0, 4, 1, 4, 1, 2],
[0, 0, 0, 0, 0, 0, 0, 4, 5, 2],
[0, 0, 0, 0, 0, 0, 0, 3, 1, 2],
[0, 0, 0, 0, 0, 0, 0, 6, 1, 2],
[0, 0, 0, 0, 0, 0, 6, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 3, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 1, 5, 2]], dtype=int32)💡 대문자는 자동으로 소문자로 변환됨.
💡 num_words를 문장 길이에 비해 너무 작게 설정하면 oov가 너무 많이 생기게 되어 성능이 안 좋아진다. 문장이 너무 길면 num_words를 설정하지 않는 것도 방법.
- tokenizer의 word_index 속성은 단어와 숫자의 키-값 쌍을 포함하는 딕셔너리를 반환한다.
- fit_on_texts() 메서드는 문자 데이터를 입력받아서 빈도수를 기준으로 단어 집합을 생성한다.
- Tokenizer는 정수 인코딩을 수행하는 방법입니다.
to_categoricla()는 정수 인코딩 결과를 입력으로 받아 바로 원-핫 인코딩 과정을 수행하는 방법이다.- texts_to_sequences() 메서드는 텍스트 안의 단어들을 숫자의 시퀀스의 형태로 변환한다.
[4,1,2]
1106 실습
🤔 순서, 맥락, 시퀀스 가 중요한 데이터는 어떤 데이터가 있을까요?
시계열데이터, 주식, 날씨, 악보
순서가 중요한 시계열 데이터(주가 데이터 등)는 섞지 않고 순서대로 나누기도 한다.
📌 RNN
RNN (Recurrent Neural Network)은 시계열 또는 자연어와 같은 시퀀스 데이터를 모델링하는 데 강력한 신경망 클래스입니다.
📌 RNN 유형
입력 갯수 출력 갯수에 따라서 one to many, many to one, many to many 로 나눠지지만 핵심은 타임스텝으로 이전 hidden state 의 아웃풋과 현시점의 인
풋이 함께 연산
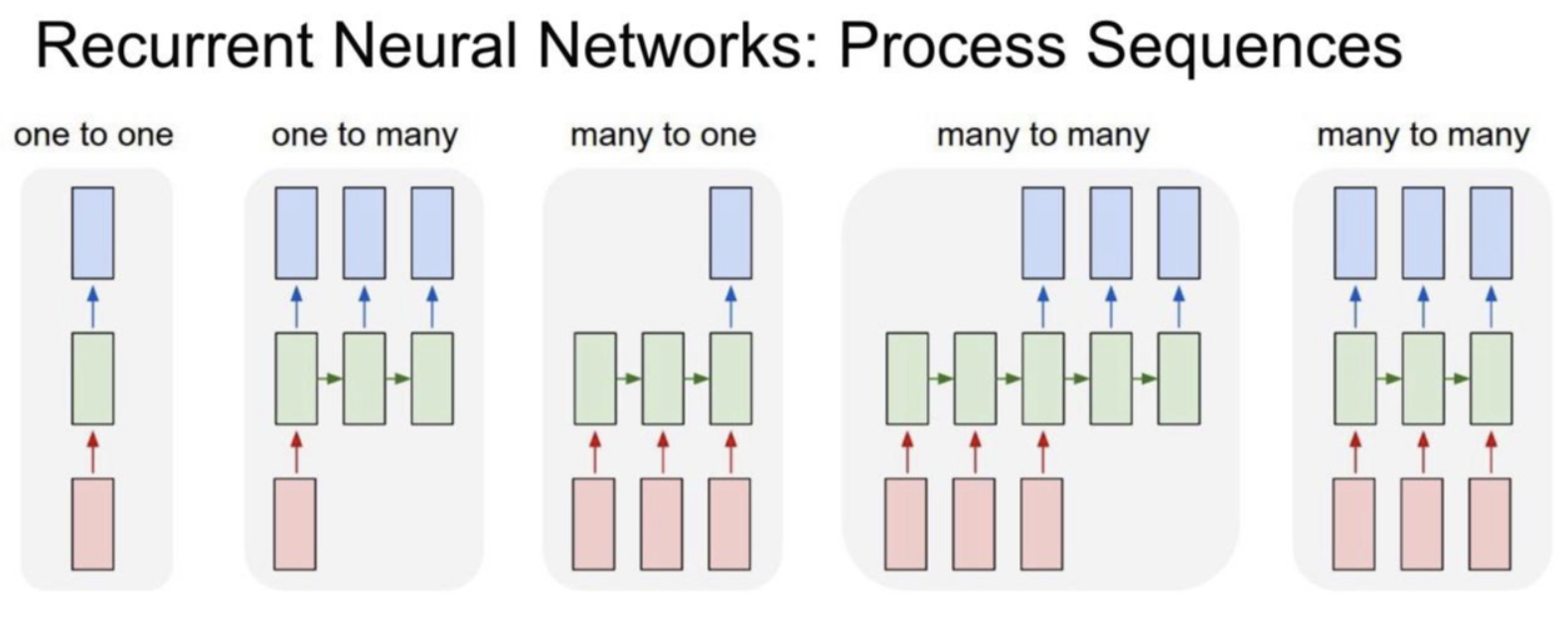
출처 : http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture10.pdf
- One to one - 가장 기본적인 모델
- One to many - 하나의 이미지를 통해 문장으로 표현할 수 있음
- Many to one - 영화 리뷰를 통해 긍정 또는 부정으로 감정을 분류 가능
- Many to many - 여러 개의 단어를 입력받아 여러 개의 단어로 구성된 문장을 반환하는 번역기, 동영상의 경우 여러 개의 이미지 프레임에 대해 여러 개의 설명이나 번역 형태로 출력
🤔 RNN 모델을 만들 예정이며 출력층은 기존에 만들었던 것처럼 만들 예정입니다. "행정", "경제", "복지" label을 one-hot-encoding 을 해주는 이유?
분류 모델의 출력층을 softmax로 사용하기 위해서.
softmax 는 각 클래스의 확률값을 반환하며 각각의 클래스의 합계를 구했을 때 1이 됩니다.
🙋🏻♀️ 질문
Q: tqdm 의 사용목적은 무엇일까요?
A: 오래 걸리는 작업을 할 때 진행상태를 표시해줍니다.
✏️ TIL
- 사실(Fact): RNN에 대해 배웠다.
- 느낌(Feeling): 갑자기 어려워졌다.
- 교훈(Finding): 복습하자 복습!
