
- 예측한 값이 실제 값을 맞추면 정답, 예측이 실제 값과 다르면 정답이 아닌 것
- 정답 == label == target (scikit-learn에서 주로 사용하는 단어)
- 값이 없으면 (NaN 혹은 Null 이면) 정답이 없는 것
머신러닝 파이프라인
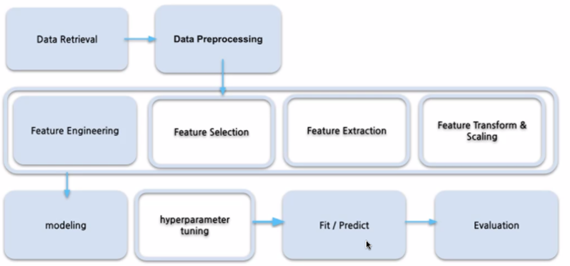
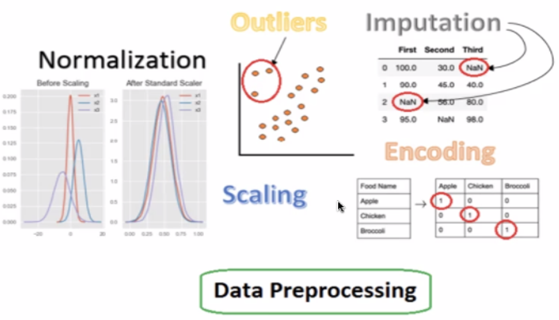
데이터 전처리 방법
❗ 머신러닝 과정 – 지도학습 (학습 👉 예측 👉 채점)
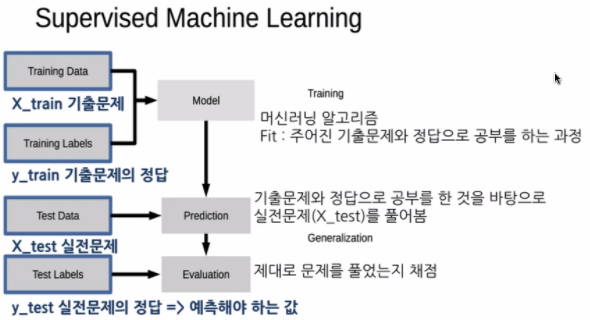
운전면허 시험으로 예를 들면,
1. 정답이 있는 기출문제로 공부를 하고(fit)
2. 공부한 것을 바탕으로 실전 필기시험을 치고(predict)
3. 실전 필기시험 정답을 가지고 채점(evaluate)
머신러닝 과정 – 분류

공식문서에서 X는 대문자, y는 소문자로 사용하기 때문에 그대로 사용 하는 것을 권장; X: 행렬, y: 백터

Fit, Predict는 지도학습에서 사용하고, Fit, transform은 비지도 학습에서 사용하는 용어
비지도 학습
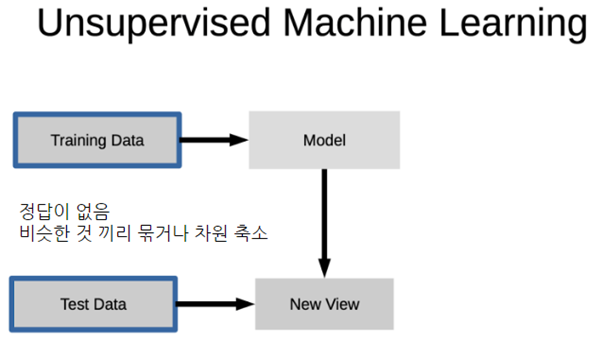
비지도 학습 - 차원축소: 주성분 분석

앞으로 많이 사용할 예정 결정 트리 학습법 (Decision tree learning): 스무고개와 같은 개념
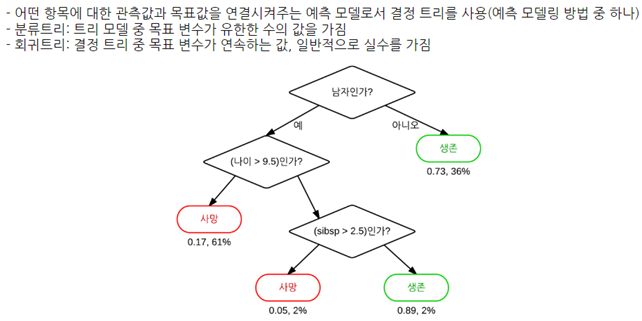
CART: Classification And Regression Tree (분류와 회귀에 사용하는 트리)

주요 파라미터
- criterion: 가지의 분할의 품질을 측정하는 기능입니다.
- max_depth: 트리의 최대 깊이입니다.
- min_samples_split:내부 노드를 분할하는 데 필요한 최소 샘플 수입니다.
- min_samples_leaf: 리프 노드에 있어야 하는 최소 샘플 수입니다.
- max_leaf_nodes: 리프 노드 숫자의 제한치입니다.
- random_state: 추정기의 무작위성을 제어합니다. 실행했을 때 같은 결과가 나오도록 합니다.
Decision tree의 장점:
트리를 하나만 그리기 때문에 다른 라이브러리보다 확인하기 용이하다.
- CART: Classification And Regression Tree (분류와 회귀에 사용하는 트리)
- 자료를 가공할 필요가 거의 없다.
🙋🏻♀️ 질문
Q: nvida는 어떤 일을 하는 회사일까요?
A: 그래픽 카드 제조사
Q: 그래픽 카드로 할 수 있는일?
A: GPU 코어 연산 및 처리 속도에 관여
Q: 분류로 할 수 있는일? (범주형)
A: 고객이 자주하는 질문 분류 / 제품의 성능판단 시, 합격 불합격 분류 / 이상 유저 분류 등
Q: 회귀로 할 수 있는 일? (수치형)
A: 주가 예측 / 어떤 사람의 교육 수준, 나이, 주거지를 바탕으로 연간 소득 예측 / 수요 예측
Q: 회귀 알고리즘 중에 분류에 사용할 수 있는 알고리즘?
A: 로지스틱 회귀
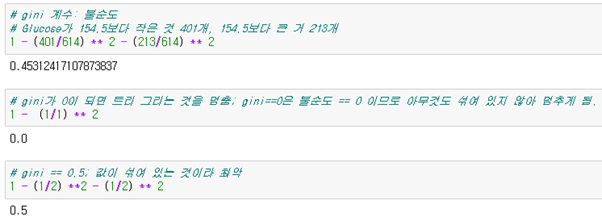
Q: Gini 계수란?

A: 불순도를 나타냄. 최고는 gini == 0; 값이 섞여있지 않음 , 최악은 gini == 0.5 (값이 반반 섞여 있음)
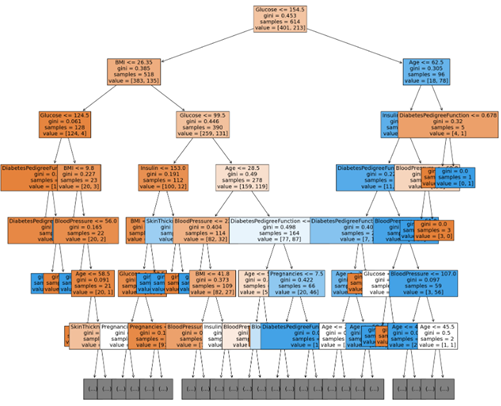
Q: 분류 및 회귀 트리(Classification And Regression Tree, CART) 왜 이 트리가 오버피팅 == 과대적합 == 과적합 일까요?
A: 과적합은 학습 데이터를 너무 학습해서 나중에 테스트 데이터는 분류를 못합니다
Q: 결과와 무관하게 현실세계에서 어떤 수치가 가장 중요하게 당뇨병을 예측하는데 사용될 것 같나요?
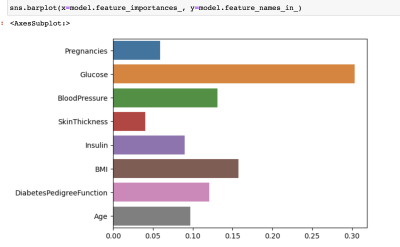
A: 인슐린
Q: 현실 세계에서는 인슐린이 중요한 역할을 할 텐데 이 결과를 보고 우리는 어떤 액션을 취할 수 있을까요?
A: 왜 인슐린이 중요도가 낮은지 분석해 본다.
Q: 학습을 적게 해서 점수가 낮게 나오는 것을 무엇이라고 할까요?
A: 과소적합 == 언더피팅
Q: 문득 궁금해졌는데 최소한의 데이터로 최상의 예측결과를 낼 수 있는것도 좋은 모델인가?
A: 모델 자체는 좋다고 할 수 있지만 데이터가 적기 때문에 신뢰도 측면에서 평가가 떨어질 수는 있습니다. => 좋은 데이터가 많을수록 좋다.
Q: 수치형 변수를 그대로 안 쓰고 범주형 변수로 만들어 주었을까요?
A: 머신러닝 알고리즘에 힌트를 줄 수도 있고 오버피팅을 방지할 수도 있습니다.
- EDA를 통해 알게된 사실로 세분화된 조건을 주어 오버피팅 방지
Q: 인슐린의 결측치는 왜 채울까요?
A: 결측치가 있는 데이터는 인공지능 모델에 학습 시킬 수 없고, 중요한 데이터인데 누락될 가능성이 있기 때문.
Q: Insulin_nan에서 nan값을 교체해주지 않고 Insulin_fill라는 새로운 컬럼을 만드는 이유?
A: 결과 값을 비교해 보기 위해서 새로운 컬럼을 만들었습니다. 결과값을 비교해 보지 않아도 된다면 새로운 컬럼을 만들지 않아도 됩니다.
✍🏻 TIL
사실(Fact): 지도학습과 의사결정트리에 대해 배우고 직접 모델을 만들 그 모델이 얼마나 잘 예측 했는지를 확인했다.
느낌(Feeling): 처음 접해보는 영역이라 어렵다. 어려운데 재밌다.
교훈(Finding): 이해하지 못하고 넘어갔던 부분 다시 복습 해야겠다.
