
용어 정리
- Labeller: 정답이 없는 문제에 정답을 정해주는 사람
- Labelling: 처음에 입력받지 않은 값들(결측치)에 대해 설문이나, 값을 입력하면 포인트를 더 주는 이벤트를 여는 등 다양한 방법으로 값(정답)을 입력 받는 일
- Encoding: 범주화
- 머신 러닝에서는 변수를 "feature"라고 칭함 (변수 == 컬럼 == 피처)
0402 파일 실습: Feature Engineering using RandomForest
Decision Tree 는 baseline으로 피처의 중요도를 확인 하는 데에 가장 먼저 사용.
Feature Engineer 는 많이 사용하면 할수록 더 좋은 성능을 낼것 같지만 현실은 아님.
결측치를 채울 때, 기존의 값에 덮어쓰기 하면 결측치가 잘 채워졌는지 비교해보기 어려우니 파생변수 생성해서 비교
- Insulin: raw data
- Insulin_nan: Insulin에서 0을 NaN로 바꾼 컬럼
- Insulin_fill: Insulin_nan에서 NaN값을 평균으로 채운 값 => 분석에 사용할 컬럼
이상치는 Insulin_nan에서 찾고 제거는 Insulin_fill에서
👉 Insulin_fill은 한번 조작된 값들이라 Insulin_nan에서 이상치를 찾는다.
Decision Tree의 장점:
1. 그래프를 하나만 그려 빠르다
2. 트리의 깊이 (max_depth)를 제한해 Overfitting / Underfitting 방지
Decision Tree의 단점:
1. 랜덤성에 따라 매우 다르기 때문에 일반화하여 사용하기 어렵다.
2. 결과 또는 성능의 변동 폭이 크다.
3. 계층적 접근 방식이기 때문에 중간에 에러가 발생한다면 다름 단계로 에러가 계속 전파된다.
4. 과적합 가능성이 높다.
DecisionTree 에 단점이 있음에도 불구하고 사용하는 이유
1. 쓰기가 쉽다.
2. 빠르고 단순해서 데이터 피처의 중요도 파악에 용이하다.
3. 직관적이다.
Random Forest - Decision Tree의 단점을 보완한 알고리즘
1. 월등히 높은 정확성 (Decision Tree를 여러개 그림)
2. 간편하고 빠른 학습 및 테스트 알고리즘
3. 변수소거 없이 수천 개의 입력 변수들을 다루는 것이 가능
4. 임의화를 통한 좋은 일반화 성능
-임의화: randomization (트리를 랜덤하게 여러개 그림)
5. 다중 클래스 알고리즘 특성
Bagging (배깅)
: bootstrap aggregating의 약자. 표본 추출해서 랜덤하게 트리를 그리고 그 결과를 집계한다.
- 중요 매개변수
포레스트의 크기 (트리의 개수) T
최대 허용 깊이 D
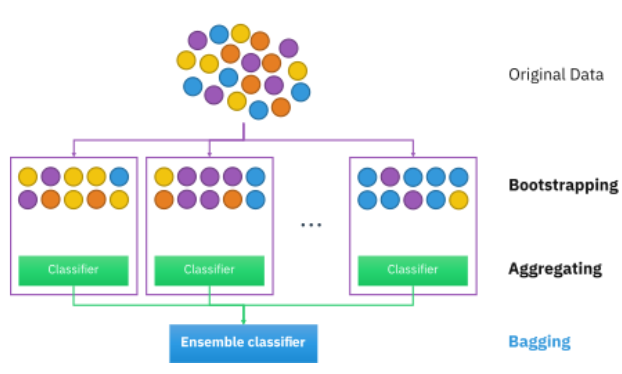
앙상블 방법
- 앙상블은 개선된 분류기를 생성하기 위해 일련의 저성능 분류기를 결합한 복합 모델
- 배깅 접근법을 사용하여 분산을 줄이고, 부스팅 접근법을 사용하여 편향을 사용 또는 스태킹 접근법으로 예측 개선
0403 파일 실습: Regression으로 Insulin 예측하기 (수치형 데이터)

- n_estimators = 100 은 defalut 값
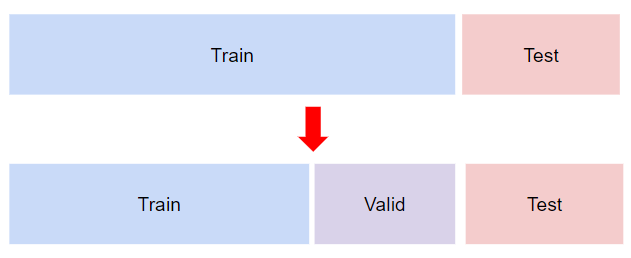
Hold-out Validation
👉 한 번만 나누기 때문에 빠르게 결과를 볼 수 있다는 장점이 있지만 신뢰도가 떨어진다.
Cross Validation(교차 검증); Hold-out Validation 보완
- 병렬적으로 학습을 하기 때문에 학습이 누적되지 않는다.
- 여러 개로 쪼갤 수록 시간이 오래 걸리지만 신뢰도를 높이기 위해 쪼개준다.
- 각 fold의 평균을 구한다.
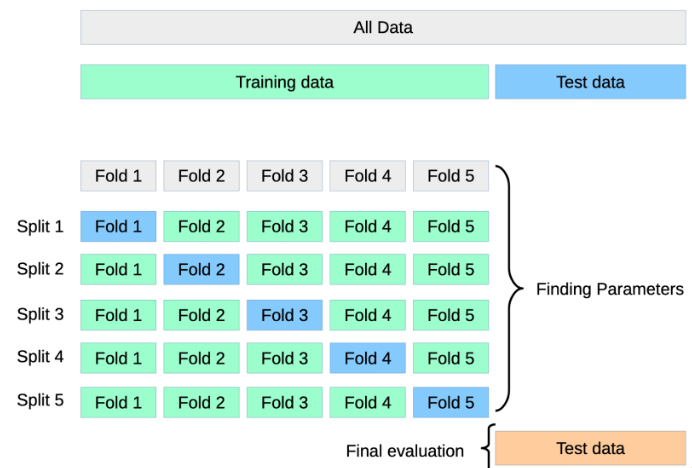
- Fold(조각) == 모의고사
- 파란색 == 최종모의고사
- 연두색 == 공부용 모의고사
- 조각의 수 == fit(학습) 수
- Test == 수능
👉 4개의 초록색으로 train을 하고 1개의 파랑색으로 검증

- cv: fold 조각의 수
- verbose=0 : 로그 출력 X
- verbose=1 : 로그 출력 O
- verbose=2 : 조금 더 자세한 로그 출력O
# 정답을 정확하게 맞춘 갯수
(y_train == y_predict).mean()
Outcome:
0.0 # accuracy가 0; 예측이 하나도 맞지 않았다. 👉 실제값과 예측값의 차이 시각화 해서 차이를 확인 한다.
r2_score (회귀계수)
상관계수와 같이 예측값과 실제값이 같으면 1
오차 구하기
마이너스 값이 있을 수 있으니 abs(절대값)을 구해준다.
회귀 모델에선 오차를 보는 것이 정말 중요!!
🙋🏻♀️질문
Q. 피처 엔지니어링 전에 스코어를 올리기 위해 실습했던 것?
A. 하이퍼 파라미터 조정 - 스코어가 드라마틱하게 올라감 (보통은 마지막에 조정함)
Q. model.score()의 값과 accuracy_score() 값의 결과는 같이 나오는데 y_predict를 따로 만드는 이유?
A. y_predict로 여러가지 계산을 해볼 수 있고, 직접 공식을 통해 예측을 잘 했는지 비교하기 위해서
Q. bootstrap은 언제 사용할까?
A. 표본 추출. 현실세계의 선거에 비유한다면 출구조사
Q. aggregating이 뭘까?
A. 집계
Q. bootstrap + aggregating?
A. 표본 추출 집계
Q. 랜덤 부트스트래핑을 할 때 중복을 허용할까?
A. 중복을 허용한다.
Q. n_estimators 값을 늘리면 왜 학습시간이 오래 걸릴까?
A. 생성할 tree의 개수가 많기 때문
Q. n_jobs 는 어떤 역할을 할까?
A. 사용할 CPU의 코어 수
Q. n_jobs = -1 에서 -1 은 무슨 의미일까?
A. 모든 코어를 사용하기 위해
Q. 왜 코어의 수를 지정하지 않고 -1을 사용할까요?
A. 사용중인 코어 수를 모를 경우를 대비하기 위해
Q. 랜덤포레스트에서는 왜 tree를 시각화 할 수 없을까?
A. 트리의 개수가 너무 많아 모두 시각화 할 수 없기 때문
- 사이킷런에서는 제공하고 있지 않지만 TreeInterpreter 로 시각화 할 수 있습니다.
- Github: TreeInterpreter
Q. 회귀로 예측해 볼 수 있는 피처는 무엇이 있을까요?
A. 인슐린 (수치형 데이터)
Q. 분류를 할때 결측치를 평균이나 중앙값이 아니라 회귀로 예측한 값을 채우는 경우도 있나?
A. 피처 엔지니어링 기법 중 하나이다.
Q. 학습과 예측을 해도 정답이 없기 때문에 채점을 할 수 없다. 그럼 어떻게 하면 좋을까?
A. 모의고사용 문제를 따로 모아둔다.
Q. 모의고사를 한 번만 봤을 때 문제점?
A. 공부 안 한게 test 에 나올 수 있고 신뢰도에 문제가 생긴다.
Q. 어떻게 하면 모의고사를 여러 번 볼까?
A. Hold-out Validation
Q. Hold-out Validation의 장점?
A. 빠른 평가가 가능하다.
Q. 어떨 때 높은 신뢰도가 필요할까?
A. 의료용 데이터 예측 / 자율주행 소프트웨어 만들 때
Q. accuracy 가 0 이면 어떻게 하면 좋을까?
A. 실제값과 예측값의 차이를 보면 된다.
Q. remove() 는 왜 할당은 안해도 되는가?
A. remove는 원본 데이터에서 매개변수로 들어온 값과 똑같은 값을 찾아서 삭제해 주는 함수이기 때문에 재할당 해주지 않아도 원본 데이터가 변경되기 때문
Q. model.score()에 predict기능이 있는건가요?
A. model.score()는 미리 스코어를 확인해 보기 위한 용도. 현실세계에서 미래를 예측할 때 y_test가 없다면 사용할 수 없는 기능
Q. 중요도 시각화 그래프가 다 다르게 그려지는 이유는 뭔가요?
A. 하이퍼파라미터 조건이 다르기 때문
Q. 스코어가 높으면 무조건 좋은 모델인가?
A. 일반적으로 성능이 좋다고 생각할 수 있지만 train-validation-test의 점수 차이가 크지 않게 모델을 만드는게 가장 좋음
Q. max_feature 파라미터는 지정 값에 따라 최적의 feature들만 사용하는 것인가?
A. 랜덤하게 특정 개수 혹은 비율로 추출해서 사용함. 적당하게 추출하지 않으면 오히려 성능이 낮아질 수도 (Underfitting) 있다.
Q. 지금은 파라미터를 어떻게 고쳐야할지 잘 모르겠는데 나중에 모델을 이해하고 공부하면 더 잘 고려해볼 수 있는건가요?
A. EDA를 통해 어떤 정보가 도움이 되고 안되고를 고려해보는 것이 좋다. 수업에서 다루지는 않지만, wandb 같이 튜닝을 하고 기록을 해주는 라이브러리도 있으니 공부해 보는것 추천
Q. 중복을 허용한다는게 중복을 따로 제거하지 않는다는 뜻인가?
A. 같은 샘플이 다른 트리에도 포함 될 수 있다.
Q. Split 1의 Fold 1과 Split 2~5의 Fold 1은 모두 같은건가?
A. 폴드 번호가 같으면 같은 모의고사
Q. 여러개로 쪼개면 속도에는 문제가 없나?
A. 오래 걸린다. 만약 랜덤 포레스트로 학습한다면 트리의 수 * 폴드의 수 만큼 오래 걸린다.
✍🏻 TIL
사실(Fact): 머신러닝의 분류와 회귀에 대해 배웠다.
느낌(Feeling): 오늘 배운 양이 꽤 많아 한 번에 모든걸 이해하기엔 무리가 있지만 다시 찬찬히 읽어보면 이해할 수 있을 것 같다.
교훈(Finding): 복습을 꾸준히 하자!
