
0702 실습
왜도와 첨도
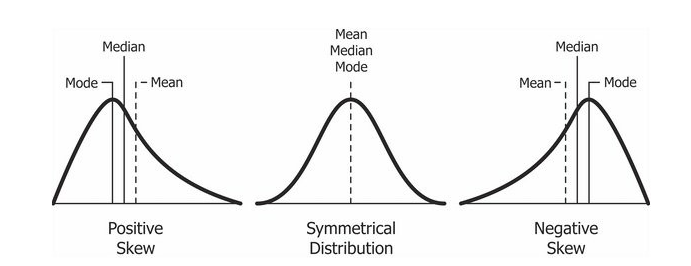
- 왜도와 첨도는 0에 가까울수록 정규분포 형태에 가깝다.
- Positive Skewness는 오른쪽 꼬리가 왼쪽보다 더 길 때를 의미하고 평균(Mean)과 중위수(Median)가 최빈값(Mode)보다 크는 것을 의미합니다.
- Negative Skewness 왼쪽 꼬리가 오른쪽보다 더 길 때를 의미하고 평균(Mean)과 중위수(Median)가 최빈값(Mode)보다 작는 것을 의미하게 됩니다.
🤔 결측치가 많으면 무조건 삭제해야할까?
- 결측치가 많다고 삭제하는게 무조건 나은 방법이 아닐 수도 있다.
- 이상치, 특잇값을 찾는다면 오히려 특정값이 신호가 될 수도 있다.
- 범주형 값이라면 결측치가 많더라도 채우지 않고 인코딩해주면 나중에 없는 값은 0으로 채워지게 된다.
- 그대신 희소한 행렬이 생성된다.
- 수치데이터인데 결측치라면 잘못 채웠을 때 오해할 수 있으니 주의가 필요하다.
수치형 변수 대체할 때 주의점
- 수치형 변수를 대체할 때는 원래의 값이 너무 왜곡되지 않는지도 주의가 필요하다.
- 중앙값(중간값), 평균값 등의 대표값으로 대체할 수도 있지만, 회귀로 예측해서 채우는 방법도 있다.
- 당뇨병 실습에서 했던 인슐린을 채울 때 당뇨병 여부에 따라 대표값을 구한 것처럼 여기서도 다른 변수를 참고해서 채워볼 수 있다.
0702 실습 지금까지의 진행 흐름
1. 다양한 변수의 타입을 확인해보고 hist를 활용해 카테고리형 변수와 연속형 변수를 구분해줍니다.
2. 분류해준 연속형 변수를 hist를 통해서 분포를 확인해봅니다.
3. 왜도와 첨도를 확인하여 분포가 치우쳐진 연속형 변수를 확인합니다.
(모델 학습 결과를 더 끌어올리기 위해서 입니다.)
4. 분포가 치우쳐진 변수를 확인 후 추출하여 로그 변환을 진행해줍니다.
모델에 사용할 범주형 변수 선택
- 범주형 변수 중에 결측치가 있는지 확인 해보고 어떤 범주형 변수를 선택해서 모델에 사용할지 의사결정을 하게된다.
- 정렬하고 결측치가 있는 데이터를 제거하기 위해 슬라이싱을 사용한다.
💡 범주형 데이터는 원핫인코딩 작업을 하기 때문에 결측치를 남겨두어도 상관없다.
왜? 없는 값은 변수로 생성하지 않기 때문
🤔 log를 취한 값을 정답값으로 지정한 이유?

According to the Kaggle House Price:

집값의 높고 낮음에 상관없이 예측에 모두 영향을 받게 하기 위해 log를 취한다.
원래 예측값은 RMSLE 인데 로그를 이미 적용해 주어서 RMSE로 계산한다.
1) 2억 => 4억으로 예측
2) 100억 => 110억으로 예측
- MAE : 1) 2억차이, 2)10억, 오차의 절대값
- MSE : 1) 4억차이, 2)100억차이, 오차가 크면 클수록 값은 더 벌어집니다.
- RMSLE : 1) np.log(2) => 0.69, 2) np.log(10) => 2.30
💡 로그값은 작은 값에서 더 패널티를 주고 값이 커짐에 따라 완만하게 증가합니다.
🤔 append()와 extend()의 차이점?

👀 ELI5 (내가 다섯살 아이인것 처럼 설명해줘)
과자의 봉지는 iterable 혹은 컨테이너라고 부릅니다.
list.append(x)는 리스트에 전달받은 요소(x)를 추가하는 메서드이며, list.extend(iterable)은 순환 가능한 요소(iterable)를 인자로 받으며, 해당 컨테이너 안에 있는 모든 요소들을 리스트에 추가합니다.
Cross Validation using KFold
💡 KFold는 cv와 같지만, 분할값을 (random_state=42)로 고정 할 수 있다는 점이 다르다.
해당 내용은 멋쟁이사자처럼 AI School 오늘코드 박조은 강사의 자료입니다.
# KFold 를 사용해서 분할을 나눈다.
# 분할에 random_state를 사용할 수 있기 때문에 분할 때문에 값이 변경되지 않게 고정할 수 있다.
from sklearn.model_selection import KFold
kf = KFold(n_splits=5, shuffle=True, random_state=42)
from sklearn.model_selection import cross_val_predict
y_valid_predict = cross_val_predict(model, X_train, y_train, cv=kf, n_jobs=-1)
y_valid_predictRMSE값 구하기
RMSE => 원래는 RMSLE 인데 로그를 이미 적용해 주어서 RMSE로 계산
from sklearn.metrics import mean_squared_error
rmse = mean_squared_error(y_train, y_valid_predict) ** 0.5
rmse❗️ log를 적용한 값 제출 시 주의할 점
# 리더보드에 있는 점수와 동일한 스케일 점수를 미리 계산해 보기 위해서는 로그 적용한 값으로
# 계산해 주지만 제출할 때는 지수함수를 적용해서 원래 스케일로 복원하여 제출합니다.
# 주의! 내부에서 평가할 때는 제출받은 값에 로그를 취해서 점수를 평가하는데
# 제출할 때는 지수함수를 적용해서 제출해야 한다.
submit["SalePrice"] = np.expm1(y_predict)
💡 수치형 vs 범주형 데이터에 할 수 있는 전처리 방법
1) 수치형
- 결측치 대체 (Imputation)
- 스케일링 : Standard, Min-Max, Robust
- 변환 (log transformation)
- 이상치 (너무 크거나 작은 범위를 벗어나는 값) 제거 혹은 대체
- 오류값 (잘못된 값) 제거 혹은 대체
- 이산화 (cut, qcut)
2) 범주형
- 결측치 대체 (Imputation)
- 인코딩 : label, ordinal, one-hot-encoding
- 범주 중에 빈도가 적은 값 대체
👀 수치형과 범주형 데이터에서 전처리할 수 있는 방법이 다르기 때문에 EDA 과정에서 데이터를 꼼꼼히 탐색하는 것이 중요!
0801 실습 : Benz
Mercedes-Benz Greener Manufacturing
선형회귀 (Linear Regression)
: 종속 변수 y와 한 개 이상의 독립 변수 X와의 선형 상관 관꼐를 모델링하는 회귀분석 기법
🤔 선형회귀 특징
1) 다른 모델들에 비해 간단한 작동 원리를 가지고 있다.
2) 학습 속도가 매우 빠르다.
3) 조정해줄 파라미터가 적다.
4) 이상치에 민감하다.
5) 데이터가 수치형 변수로만 이루어져 있을 경우, 데이터의 경향성이 뚜렷할 경우 사용하기 좋다.

🤔 값이 1인 피처들은 어떻게 할까?
변수를 살펴보고 변별력이 없는 변수(단일한 값만 가지고 있는 변수)는 삭제.
피처 엔지니어링에서 train을 기준으로 했던 것 처럼 test값 삭제할 때도 train 기준으로 삭제한다.
# handle_unknown="ignore": test에는 등장하지만 train에는 없다면 무시해
# train으로 피처의 기준을 만드는데 test에 train에 없는 값이 있다면 그 값은 피처로 만들지 마
ohe = OneHotEncoder(handle_unknown="ignore")💡 get_dummies()와 OneHotEncoder()의 차이
OneHotEncoder는 전체 데이터를 변환하기 때문에 범주가 아닌 수치 데이터도 모두 인코딩한다.
그래서 범주값 데이터만 따로 넣어 인코딩해야한다.
pd.get_dummies()의 장점은 이런 전처리 없이 범주 데이터만 one-hot-encoding한다는 점이다.
🖇 JD
- SQL 용량이 너무 크다면 데이터 파일형태로 추출해서 파이썬으로 분석하는 형태로 진행하기도 합니다.
- GCP, AWS, MS Azure 클라우드. JD에 이런 용어가 있다면 해당 제품군을 사용하는 회사라고 보면 됩니다.
- 기본적인 SQL, Python 과 같은 취업을 위한 스킬에 필요한 것을 먼저 익히고 제품군은 실제로 취업해서 사용해 보면 더 잘 사용할 수 있습니다.
- 보통은 free-tier 라고 무료로 사용할 수 있는 쿠폰 등을 제공해 주기도 하지만 배우는데 비용이 들어가기도 합니다.
- 클라우드에 데이터가 DB 혹은 파일 형태로 적재되어 있습니다.
- ELK 와 같은 제품군을 사용하기도 하는데 ELK 는 엘라스틱서치 관련 제품군 명칭입니다.
- 데이터엔지니어직군에는 클라우드 제품군 이름이 들어가는 경우가 더 많습니다. 클라우드에 실제로 적재하는 업무를 하기 때문.
🤔 ELT, ETL?
- ETL : 데이터 웨어하우스에서 작동하며 데이터를 추출하고 (E) -> 변환하여 (T) -> 데이터를 적재하는 (L) 순서로 데이터를 처리하는 프로세스
- ELT : 데이터 레이크에서 작동하며 데이터를 추출하고 (E) -> 적재한 다음 (L) -> 데이터를 변환하는 (T) 순서로 데이터를 처리하는 프로세스이다.
👀 기본 소양을 갖추기 위해 읽어봐야할 목록: 클라우드 머신러닝 플랫폼 선택 기준 12가지
🙋🏻♀️ 질문
Q: 현실세계에서 수치데이터의 결측치를 0으로 채우면 안 되는 값?
A: 키, 몸무게.
화장실 수, 2층면적, 지하면적, 주차장면적 은 해당 시설이 없다면 0이 될 수 있다. 그래서 전처리를 할 때 현실세계에서 해당 값이 0이 될 수 있는지 없는지를 고민해 보고 전처리 하면 된다.
Q: 이전에도 피자에 치즈가 적절히 뿌려졌는지를 확인하는 머신 비전 시스템을 설치했지만, 이는 여러 개의 토핑이 있는 피자의 결함은 감지하지 못했다. 머신러닝 용어로 어떻게 해석할 수 있을까요?
A: 기존 피자치즈가 적절히 뿌려졌는지 확인하는 데이터에만 과대적합(오버피팅)이 되어 새로운 데이터가 들어왔을 때 일반화 하지 못하는 문제가 있다.
🦁 질문
Q: 왜도와 첨도의 정확한 수치까지 알아야할 필요가 있나요?
A: 정확한 수치까지 모르더라도 시각화를 해보면 알 수 있다. 그런데 변수가 100개 그 이상이라면 물론 비교해 볼 수 있지만 시간이 많이 필요하다. Anscombe's Quartet에 따르면 요약된 기술 통계는 데이터를 자세히 설명하지 못하는 부분도 있다. 그래서 왜도와 첨도는 변수가 수백개 될 때 전체적으로 왜도와 첨도가 높은 값을 추출해서 전처리 할 수 있다. pandas, numpy 등으로 기술통계를 구해보면 왜도, 첨도(기본 값 피셔의 정의 일 때) 0에 가까울 때 정규분포에 가까운 모습이다.
데이터 시각화가 우리에게 데이터 인사이트를 더 쉽게 찾을 수 있도록 도와주지만, 반대로 우리는 데이터 시각화에 의해 데이터를 잘못 해석 하기도하고 의도적으로 데이터를 왜곡하거나 의도가 아닌 시각화 자체의 한계로 인해 해석상 오류가 나타나는 방향으로 시각화가 이루어 질 수도 있기 때문에 항상 주의해야합니다!
Q: plt.show()를 안쓰면 그래프가 안뜨고 쓰면 가끔 그래프가 두개씩 나오는데 왜 그런지 알 수 있을까요?
A: plt.show()는 그래프를 보여주는 역할을 합니다. 기존 주피터 에서는 그래프를 보여주는게 기본값이 아니었어요. 그런데 마지막 줄에 그래프를 그리는 코드가 있다면 보여주는 것이 기본 값으로 변경이 되었습니다. 그래서 plt.show()를 했을 때 주피터 버전에 따라 중복 출력이 될 수도 있는데 이때는 plt.show()를 지워주시면 됩니다.
Q: 하나의 값에 너무 몰려있는 변수도 예측에 필요한 경우가 있을까요?
A: 다른 데이터에서도 같은 값이 들어있는 변수가 있을 때도 있습니다. 이런 값은 사용, 제거 둘 다 해보고 점수차이가 없다면 제외하는게 낫습니다. 만약 희소하게 등장하는 값이 중요한 역할을 한다면 예를들어 이상치 탐지라든지 특정 징후를 표현한다면 두는게 나을 수도 있습니다. 시각화했을 때도 다른 변수와 함께 보는게 좋습니다. pairplot을 볼 때도 수치 변수끼리의 상관을 보여주듯이 일단 비교해 보고 사용여부를 결정하는게 낫습니다.
Q: 원핫인코딩할 때, 사이킷런을 사용하지 않는 이유는 df로 전처리를 해서 그런가요?
A: train, test 가 concat 되어 있는 상태라면 get_dummies() 를 사용하는 것이 가장 간단합니다. 사이킷런을 사용해도 되는데 사이킷런을 활용해서 원핫인코딩을 하면 array를 반환하기 때문에 추가 전처리가 필요합니다!
✏️ TIL
- 사실(Fact): 피처스케일링을 통해 예측모델을 만들고 kaggle에 제출해보았고, 선형회귀의 특징에 대해 배웠다.
- 느낌(Feeling): 회귀분석에 대해 더 알아봐야겠다.
- 교훈(Finding): 복습..!
