
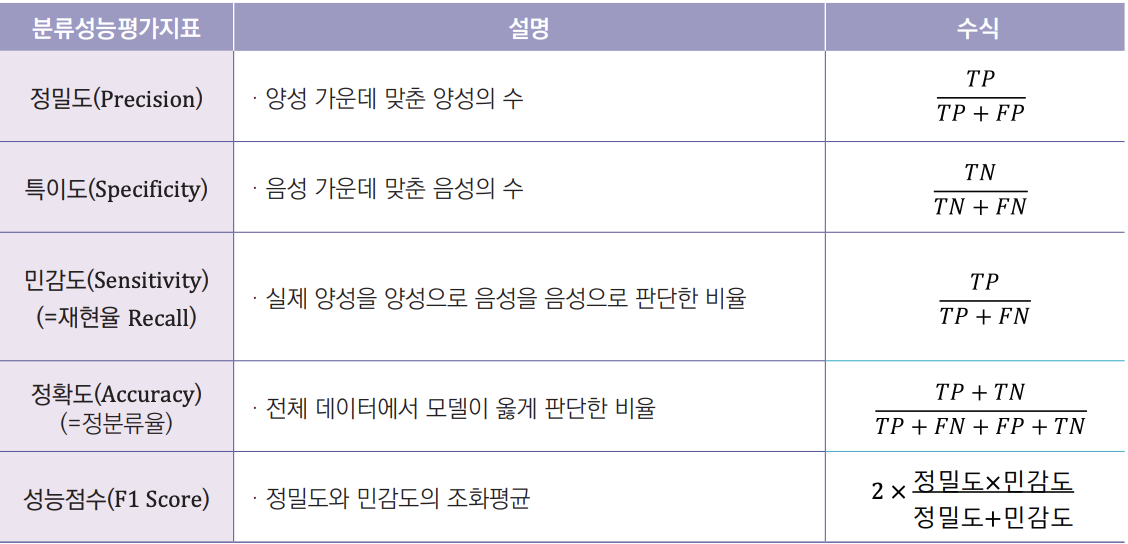
📌 분류성능평가지표
출처: https://www.hira.or.kr/ebooksc/ebook_659/ebook_659_202109300534201190.pdf
- Precision (예측값 기준): Positive로 예측한 모든 값 중에 True Positive의 비율
- Recall (실제값 기준)
- F1 score: 정밀도와 재현율의 조화평균
F1 점수는 정밀도와 재현율이 둘 다 높아야 높은 점수를 갖도록 되어 있다.
정밀도와 재현율을 둘 다 높이면(=예측 성능을 올리면) F1 score가 올라간다.
정밀도나 재현율 중 하나가 매우 높고 다른 하나가 매우 낮아도 평균적인 점수를 갖게 된다.
✅ Precision-Recall Tradeoff
예측한 것 중에서 거짓이었던 경우를 줄이려면, 더 확실한 경우에만 참으로 예측하면 된다.
- threshold를 올리면 더 확실한 경우에만 참으로 판단
- 이 경우에는 precision을 올릴 수 있지만 참으로 판단하는 경우가 줄어들게 되므로 recall은 내려간다.
- 반대로 threshold를 내리면 recall은 올라가고 precision은 내려가게 됩니다.
💡 precision이 더 중요한 경우에는 threshold를 올린다.
💡 recall이 더 중요한 경우에는 threshold를 내린다.
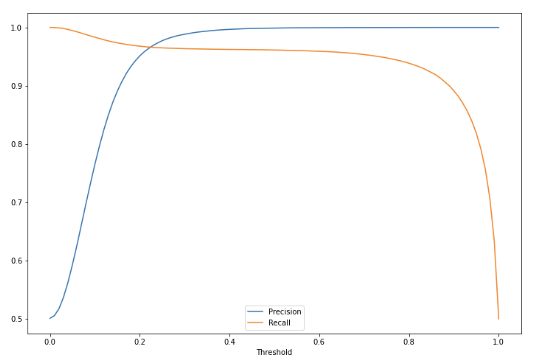
이 경우엔 precision과 recall이 교차하는 0.2~0.3 사이의 threshold가 적당
✅ ROC(receiver operating characteristic) curve
ROC는 예측값이 확률인 분류 문제에 사용된다.
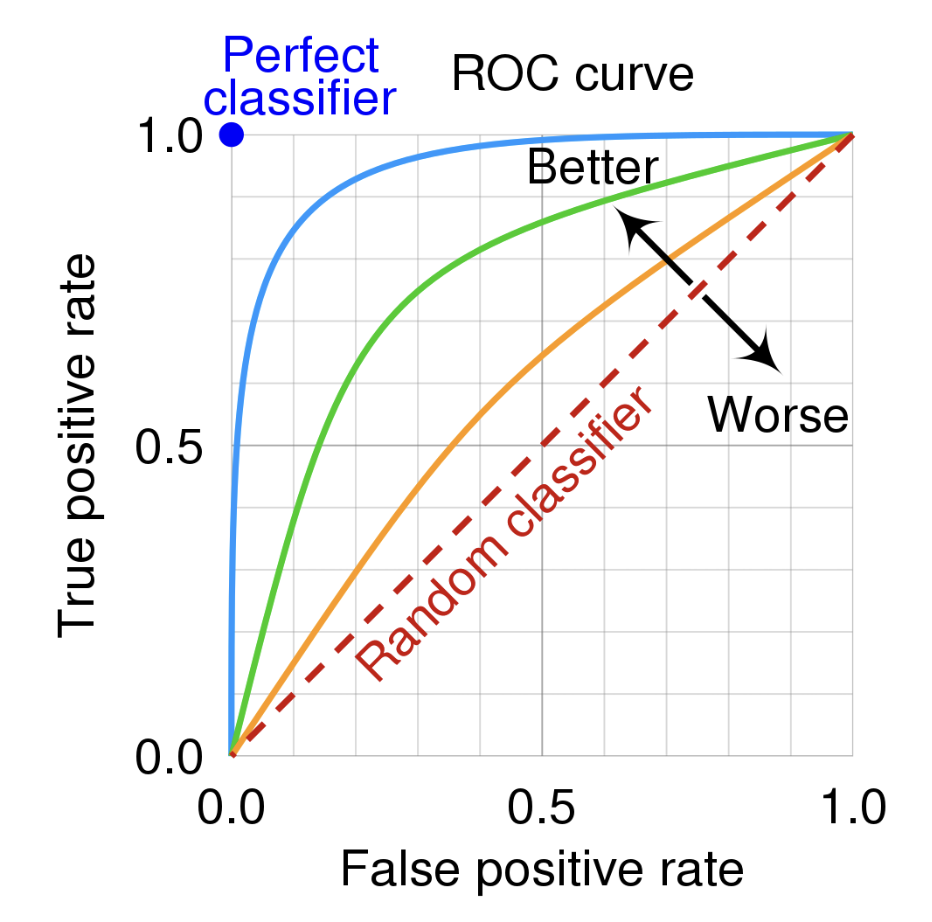
출처: https://en.wikipedia.org/wiki/Receiver_operating_characteristic
👉🏻 Threshold에 따라서 달라지는 TP rate와 FP rate를 표시한 그래프
- 이진 분류에서 완전히 랜덤하게 예측할 경우, FP rate가 올라갈수록 TP rate도 정비례하여 올라간다.
- 모두 참으로 예측할 경우, FP rate도 1, TP rate도 1이 되게 됩니다.
- FP rate를 0, TP rate를 1로 만들면 완벽한 분류기입니다.
💡 완벽한 분류기를 만드는 것은 현실적으로 불가능하기 때문에 FP rate를 최대한 적게, TP rate를 높이는 것이 목표입니다.
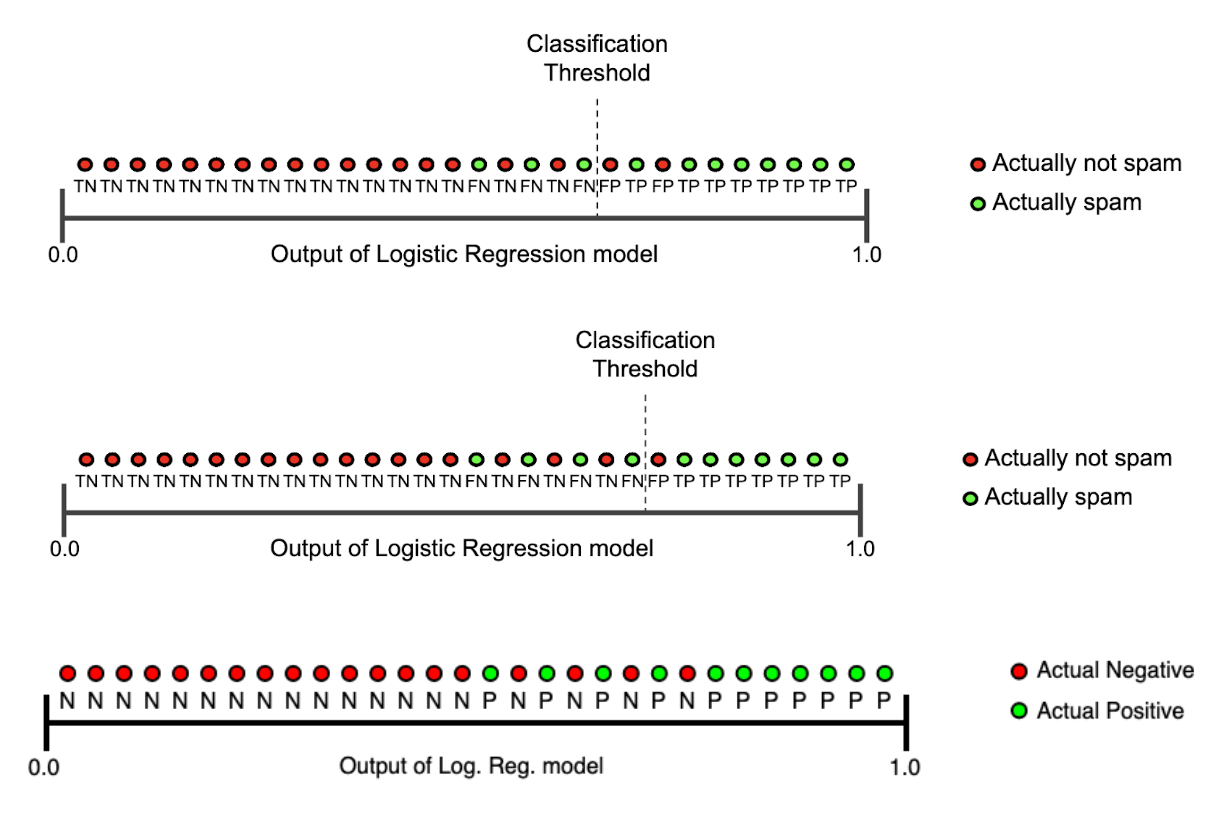
- 기존에는 예측을 할 때 주로 predict를 사용했지만 predict_proba를 하게 되면 0,1 등의 클래스 값이 아닌 확률값으로 반환
- 임계값(Threshold)을 직접 정해서 True, False를 결정하게 되는데 보통 0.5 로 하기도 하고 0.3, 0.7 등으로 정하기도 한다.
✅ AUC
AUC(area under curve)는 ROC 커브 아래의 곡면의 넓이를 의미
- AUC가 넓을수록 더 좋은 머신러닝 모델입니다.
- ROC 커브가 TP rate(TPR)이 1, FP rate(FPR)이 0에 가까워질수록 더 좋은 모델
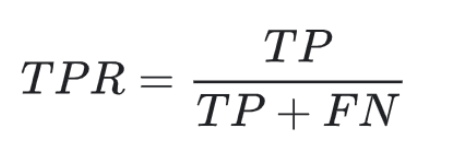
TPR: 실제 양성 샘플 중에 양성으로 예측된 것의 비율을 나타냄
- TP와 FN은 어떻게 예측되었든 상관없이 모두 실제로는 양성 샘플
- TP가 많고 FN이 적을수록 TPR은 1에 가까워짐
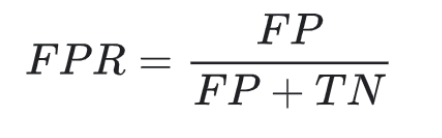
FPR: 실제 음성 샘플 중에 양성으로 잘못 예측된 것의 비율을 나타냄
- FP가 적고 TN이 많을수록 FPR은 0에 가까워짐
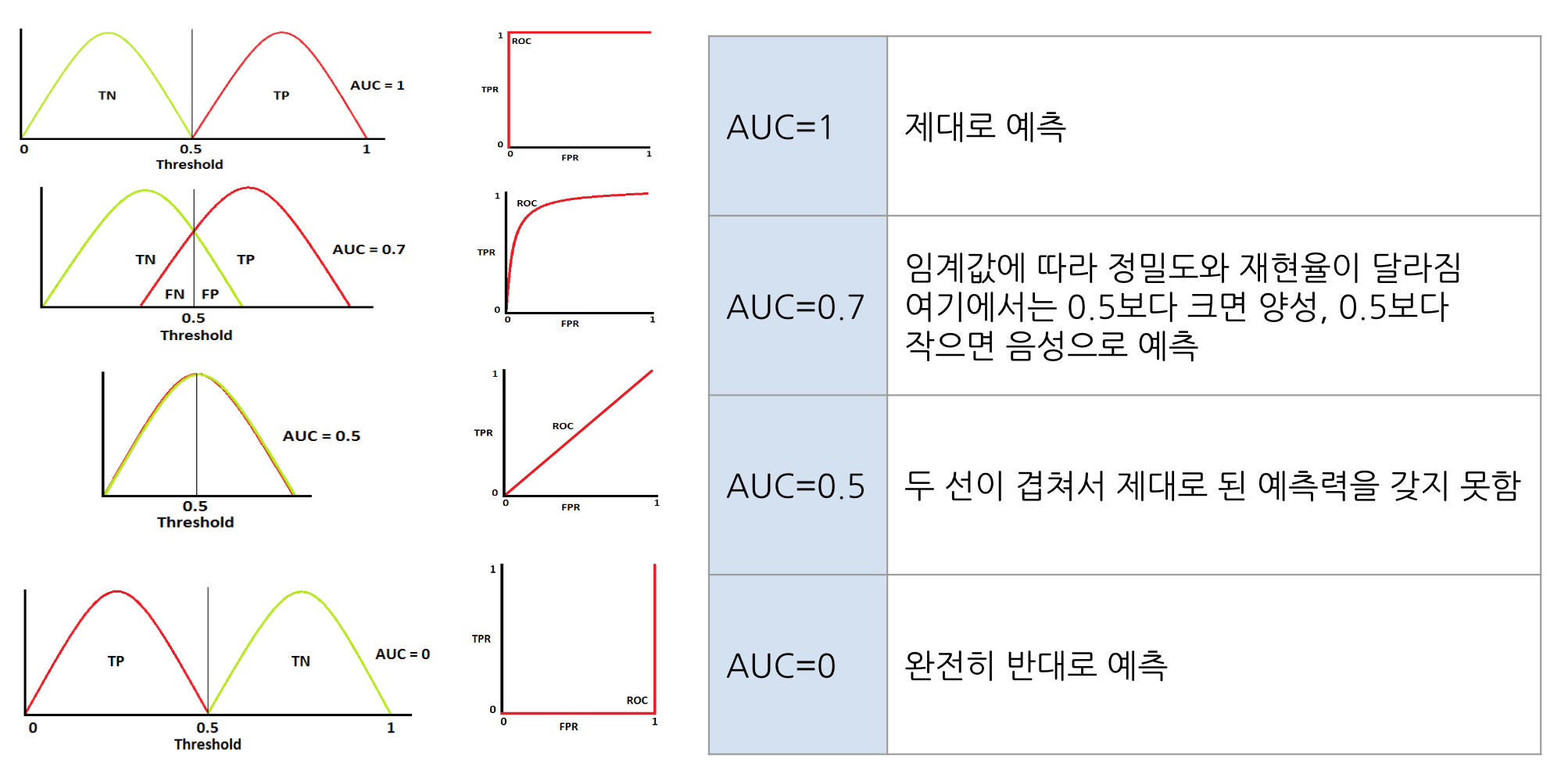
출처: 멋쟁이 사자처럼 AI SCHOOL 박조은 강사님 수업 자료 14번째 ppt, p.30
💡 참고할 만한 사이트: https://angeloyeo.github.io/2020/08/05/ROC.html
0804 실습
(해당 실습은 Colab으로 진행합니다.)
💡 실습 목적: SMOTE 적용 전과 후를 비교해보기 위해서 해당 실습을 진행
멀티 클래스일 때 predict_proba를 사용한다.
# predict_proba는 확률 값을 예측한다.
# 각 클래스마다의 확률을 예측한다.
# 0, 1일 때 각각의 확률을 의미한다.
y_pred_proba = model.predict_proba(X_test)
y_pred_proba[:5]
Output:
# 결과값이 소숫점으로 나오는 이유는 확률 값을 예측했기 때문이다.
array([[0., 1.], # 0일 확률 100퍼, 1일 확률 100퍼
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.]]) # np.argmax 값이 가장 큰 인덱스를 반환합니다.
import numpy as np
y_pred_proba_class = np.argmax(y_pred_proba, axis=1)
y_pred_proba_class📌 불균형 데이터 대처하기
✅ Resampling (Undersampling | Oversampling)
💡 목표: 정답 클래스가 불균형하면 학습을 제대로 하기 어렵기 때문에 정답 클래스의 비율을 비슷하게 맞춰주는 것
-
Undersampling: 더 값이 많은 쪽에서 일부만 샘플링하여 값이 적은 데이터에 비율을 맞춰주는 방법
: 구현이 쉽지만 전체 데이터가 줄어 머신러닝 모델 성능이 떨어질 우려가 있다. -
Oversampling: 더 값이 적은 쪽에서 값을 늘려 비율을 맞춰준 방법 (뻥튀기)
: 어떻게 없던 값을 만들어야 하는지에 대한 어려움이 있다.
Oversampling은 SMOTE (Synthetic Minority Over-sampling Technique)라는 기법을 사용한다.
🤔 SMOTE란?
- 적은 값을 늘릴 때, k-근접 이웃의 값을 이용하여 합성된 새로운 값을 추가
- k-근접 이웃이란 가장 가까운 k개 이웃을 의미
- 새로 생성된 값은 좌표평면으로 나타냈을 때, k-근접 이웃의 중간에 위치
- 추천 시스템에서 사용하는 방법
# X, y를 학습하고 다시 샘플링합니다(fit_resample).
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=42)
X_resample, y_resample = sm.fit_resample(X,y)📌 딥러닝 기초
머신러닝과 딥러닝의 가장 큰 차이점은 인간의 개입 여부이다.
- 머신러닝: 인간이 직접 특징을 도출할 수 있게 설계해 예측값 출력
- 딥러닝: 인공지능 스스로 일정 범주의 데이터를 바탕으로 공통된 특징을 도출하고, 그 특징으로 예측값 출력
✅ Model architecture
(Boosting model과 비슷하다.)
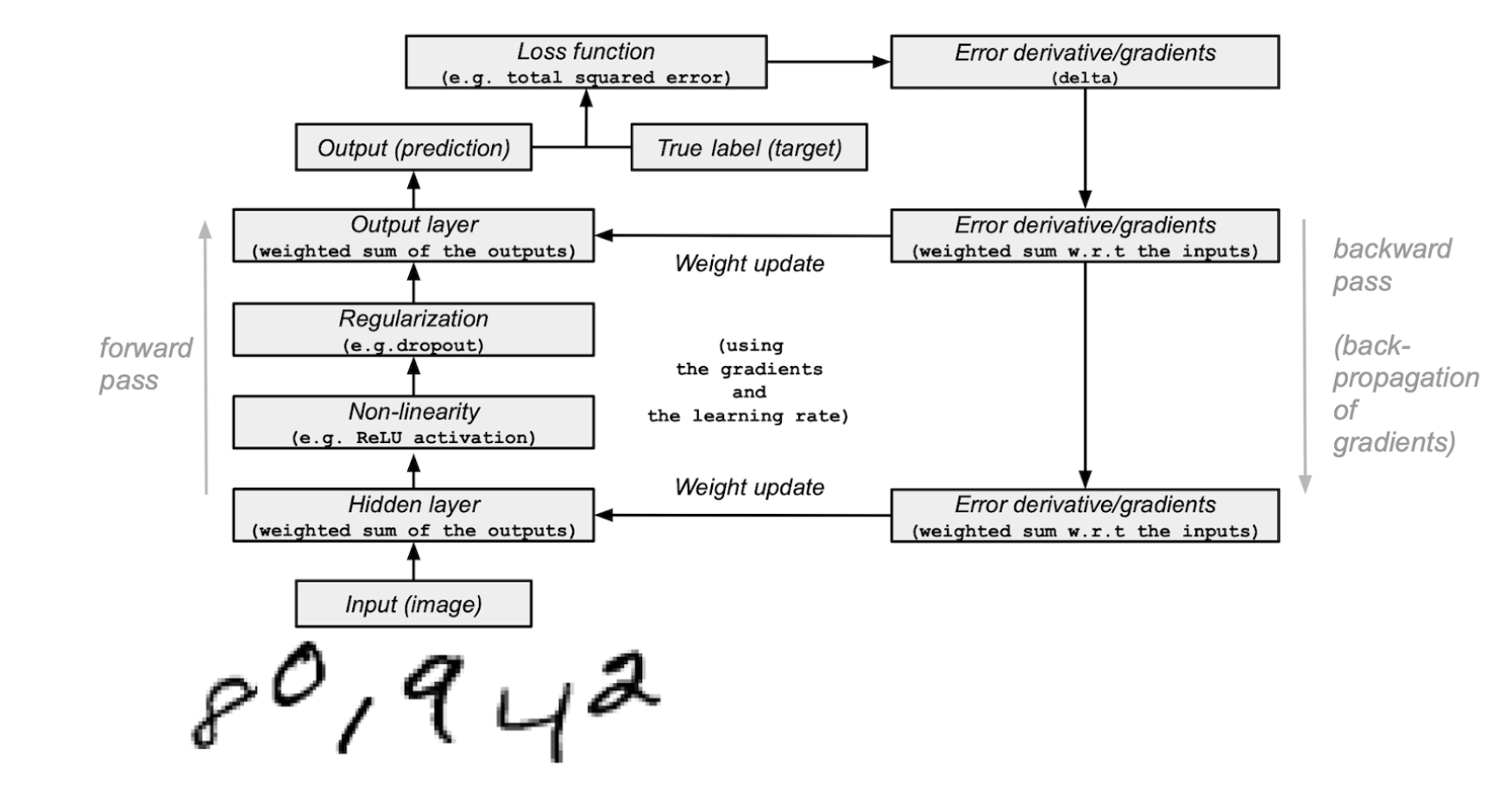
출처: https://numpy.org/numpy-tutorials/content/tutorial-deep-learning-on-mnist.html
📌 순전파와 역전파
순전파(forward propagation): 인공 신경망에서 입력층에서 출력층 방향으로 예측값의 연산이 진행되는 과정
역전파(back propagation): 순전파와 반대로 출력층에서 입력층 방향으로 계산하면서 가중치를 업데이트
- 다층 퍼셉트론 학습에 사용되는 통계적 기법
- 오차 역전법은 동일 입력층에 대해 원하는 값이 출력되도록 각각의 가중치를 조정하는 방법으로 속도는 느리지만 안정적인 결과를 얻을 수 있어 기계학습에 많이 사용된다.
- 순전파 -> Input을 받고 다수의 hidden layer에서 활성화함수 적용을 통하여 output을 출력하는 과정
- 역전파 -> 순전파 과정에서 출력한 결과와 정답값의 오차를 측정하여 그 오차의 값을 최소화하기 위한 과정
📌 활성화 함수 (Activation function)
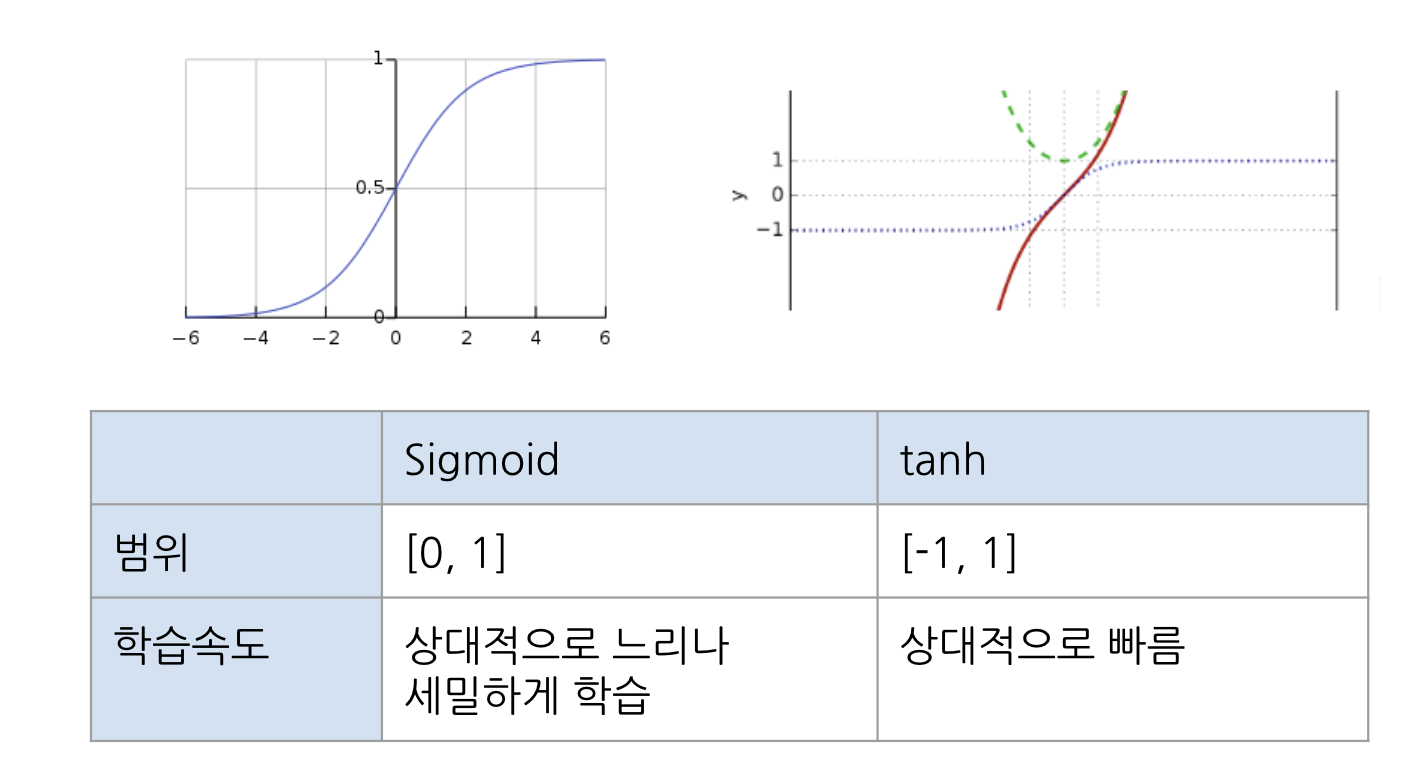
✅ Sigmoid
- 로지스틱 함수
- 이진분류에 사용
- 모델 제작에 필요한 시간을 줄임
- 미분 범위가 짧아 정보 손실 (Gradient Vanishing)
✅ tanh - 하이퍼볼릭탄젠트 함수 (tangent를 가로로 기울여 놓은 모양)
- Sigmoid 대체로 사용할 수 있는 활성화 함수
- 데이터 중심을 0으로 위치시키기 때문에 다음층의 학습이 쉽다.
- 미분 범위가 짧아 정보 손실 (Gradient Vanishing)
🤔 기울기 소실 (Gradient Vanishing)이란?
깊은 인공 신경망을 학습할 때 역전차 과정에서 입력층으로 갈수록 기울기가 점차 작아지는 현상
- 기울기 소실은 역전파 과정에서 발생하는 문제입니다. 역전파도 딥러닝 학습과정 중 일부입니다. 역전파 과정은 검산과정이라고 생각하시면 됩니다! 순전파 때 적용한 활성화함수의 결과를 검산하여 오차를 줄여주는 과정이기 때문에 역전파 과정에서는 따로 활성화함수를 사용하지 않습니다.
- 오차를 최소화하기 위한 역전파 과정에서 미분 기법을 이용하게 됩니다. 하지만 활성화함수를 sigmoid와 tanh 함수로 설정하게 되면 이 미분과정에서 기울기가 0으로 수렴하게 됩니다. 따라서 점점 기울기가 사라지고 이에 따른 가중치와 편향 도출이 어려워지는 문제가 발생합니다.
💡 기울기 소실을 완화하는 가장 간단한 방법은 은닉층의 활성화 함수로 ReLU나 Leaky ReLU를 사용하는 것
✅ 렐루(ReLU)
- 선형 함수를 개선한 버전
장점: 기울기 소실 문제 해결. 미분 계산이 훨씬 간편해져 학습 속도가 빠름
단점: Dying Relu(x가 0보다 작거나 같으면 항상 동일한 값인 0을 출력)
✅ 리키렐루(Leaky ReLU)
- ReLU의 Dying ReLU 현상을 해결하기 위한 ReLU의 변형 함수
- Leaky ReLU는 입력값이 음수일 경우에 0이 아닌 0.001과 같은 매우 작은 수를 반환 (아주 미세한 기울기를 주는 것) // 값이 0 이상이면 값을 그대로 반환
- x가 0보다 작아도 정보가 손실되지 않아 Dying ReLU 현상 해결
📌 딥러닝의 학습과정
💡 딥러닝의 목표: 출력값과 실제값을 비교하여 그 차이를 최소화하는 가중치와 편향의 조합 찾기
- 가중치는 오차를 최소화하는 방향으로 모델이 스스로 탐색(역전파)
- 오차 계산은 실제 데이터를 비교하며, 손실함수를 최소화하는 값 탐색
Colab 실습 파일에 데이터 파일 업로드 시 시간이 오래 걸린다면 mounting하는 방법이 있다.
💡 Mounting 하는 법
- Google Drive에 새로운 폴더를 생성하고 ("data") 실습할 데이터 파일 업로드
- Colab 실습 파일로 돌아와 코드 스니펫 (<>) 클릭
- 우측에 코드 스니펫 창이 생성되면 mount 검색
- 파일 불러올 코드 위에 새로운 코드창 생성 한 후 오른쪽 삽입 버튼 클릭
(아래 코드가 실습 파일에 삽입된다).
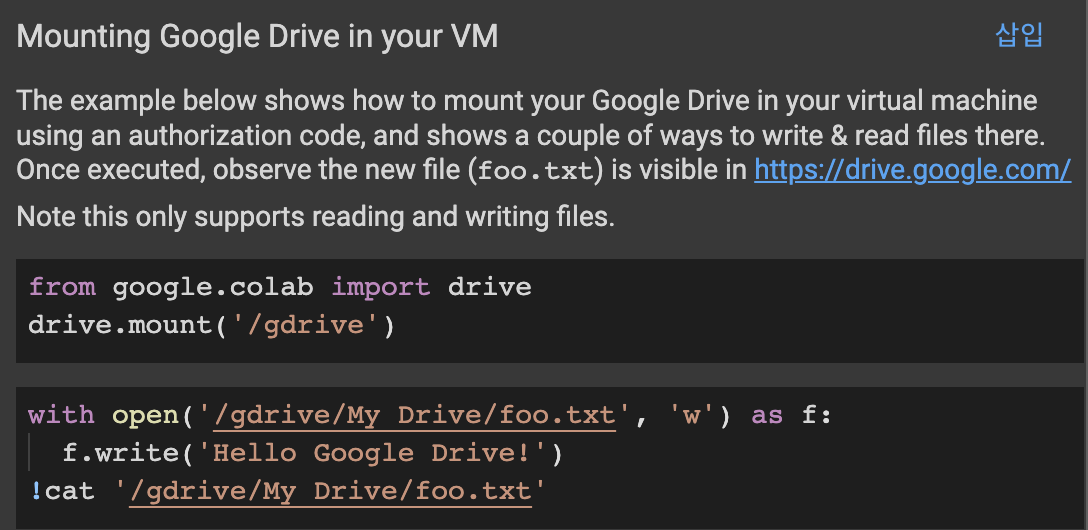
- 삽입된 코드를 수정한다.
(google drive에 데이터 파일을 업로드한 파일명 ("data")을 넣어준다.)
with open('/gdrive/My Drive/data/foo.txt', 'w') as f:
f.write('Hello Google Drive!')
!cat '/gdrive/My Drive/foo.txt'
# 데이터 불러오기
df = pd.read_csv("/gdrive/My Drive/data/creditcard.csv")🙋🏻♀️ 질문
Q: 정확도로 제대로 된 모델의 성능을 측정을 하기 어려운 사례는 어떤게 있을까요?
A: 클래스가 불균형한 데이터일 때, 제대로된 평가를 내리기 어렵다.
- 금융: 은행 대출 사기, 신용카드 사기, 상장폐지종목 여부
- 제조업: 양불(양품, 불량품) 여부
- 헬스케어: 희귀질병(암 진단여부)
- IT관련: 게임 어뷰저, 광고 어뷰저, 그외 어뷰저
이런 사례는 Accuracy로 측정해서 99.99%가 나온다면 제대로 측정하기가 어렵기 때문에 오차행렬을 사용한다.
Q: 1종 오류(거짓 양성)의 사례 무엇이 있으며 어떤 측정 지표를 사용해야 할까요?
A: Precision, 중고차 성능 판별, 스팸메일
Q: 2종 오류(거짓 음성)의 사례는 무엇이 있고 어떤 측정 지표를 사용해야 할까요?
A: recall, 지진이 났는데도 대피방송을 하지 않는 경우
Q: 신용카드 사기에서는 precision, recall 중에 어떤 측정 지표를 사용하는게 적절할까요?
A: recall. 주택담보 대출에도 적용할 수 있다.
게임에서도 어뷰저가 아닌데 어뷰저로 처리하는 경우가 있다.
어뷰저로 억울하게 지명당한 유저는
1) 기분이 나빠서 탈퇴하거나 == 유저가 탈퇴하는 것까지 감수해야함.
2) 계정 복구 해달라고 항의
어뷰저를 발견하지 못한 피해가 더 클 수도 있으니 어느쪽이 더 피해가 클지 생각해 보는 것이 중요! 비즈니스에서 어느쪽으로 평가를 해야 유리한지를 판단하는 것이 필요!
✏️ TIL
- 사실(Fact): 캐글의 신용카드사기 데이터셋을 이용해 SMOTE를 적용 전과 후를 비교해 보았고, 딥러닝 기초에 대해 배웠다.
- 느낌(Feeling): 딥러닝 이론만 잠깐 배웠는데 만만치 않다.
- 교훈(Finding): 복습만이 살 길이다.
